基于QAR-EGARCH模型组合预测的气温研究
——以合肥市为例
2020-09-15汪子琦苏静文
汪子琦,苏静文,韩 情
(安徽大学 经济学院,安徽 合肥 230601)
气温预测在社会科学和自然科学领域越来越被重视,并被应用。而现代预测气温的手段则是需要搜集大量的历史数据,然后应用一系列科学知识来对未来温度进行预判,流程越来越系统化。
受上述文献启发,本文先将分位数回归与AR-EGARCH模型进行结合,建立QAR -EGARCH 模型,在不同分位点上进行预测,然后再对相应分位点上的预测进行组合,并与单一模型的预测误差进行相比。结果表明,本文建立的组合预测模型有着更好的预测效果,也具备更好的应用价值。
1 QAR-EGARCH模型的构建
首先回顾AR-EGARCH模型,在此基础上,提出QAR -EGARCH模型,接着针对每个分位点下的预测情况进行加权组合,将组合预测模型与AR-EGARCH模型进行对比,以期得到精度最高的气温预测模型。
崔海蓉等全面考查了温度波动特征的季节性、波动集聚性和非对称性,建立了如下的AR-EGARCH模型[5]:
(1)
(2)
当模型残差不服从正态分布,出现尖峰或者厚尾或者离群点情况时,均值意义下的模型估计将不再有效。但分位数回归对异常点较为稳健,刘亭和赵月旭(2018)对沪深股票对数收益率建立了如下的QR-GARCH模型[8]:
(3)
(4)
其中,z′t为均值方程中的自变量和方差方程拟合的标准差和方差构成的行向量,
ρτ(u)=(τ-I(u<0))u。
成联方:当下书坛已经不是“新帖学”一统天下了。大概从2000年至2010年之间的10年左右,的确是“新帖学”一家独大的局面。我们70后书家,都热衷于帖学。80后的书家,风格取向就多元一些了。60后以前的书家,能深入帖学的非常少。所以,“新帖学”实际上反映了一代人的审美“彷徨”。那么80后书家为什么出现多元现象呢?因为70后至80初的帖学高手太多太多,后来的人不得不寻找新的突破口,这样,“新碑学”就应运而生了。“新碑学”是对“新帖学”的反叛。最近这四、五年,又开始出现上个世纪八、九十年代,以王镛、沃兴华为代表的那批“乡土书风”,这也许又是对“新碑学”的批判。
基于崔海蓉建立的AR-EGARCH模型,本文建立如下QAR-EGARCH模型:
(5)
这里,为EGARCH模型所拟合出的标准差,该模型既考虑到方差波动的不对称性,又考虑到因变量在不同分位点上受自变量不同程度的影响。
2 实证分析
2.1 数据来源和描述
本文数据选自天气后报(http://www.tianqihoubao.com/lishi/hefei.html)中合肥市2011年1月1日至2019年9月25日的气温数据,本文使用的软件有Eviews和MATLAB。选取其中的最高气温作为研究对象,样本个数为3188个,其气温变动趋势如图1所示。由图1可知,合肥市气温变动呈现较明显的周期性和季节性,全年气温均存在波动集聚特征,且冬季气温波动较夏季更为剧烈。

图1 合肥市气温变动趋势图
相应的描述性统计情况如表1所示:

表1 温度的描述性统计量
由表1可知,合肥市平均最高气温为21.37610;标准差为9.623575;偏度为-0.292131,小于0,具有左偏性;峰度为1.965826,小于标准正态分布的峰度,说明该序列具有平峰特性;J-B统计量的值为187.4115,P值近似为0,拒绝服从正态分布的假设。
2.2 模型估计和检验
下面以2011年1月1日至2019年9月15日为训练样本构建模型,2019年9月16日至2019年9月25日为检验样本来用以预测,将AR-EGARCH模型和QAR-EGARCH模型的预测情况进行对比。
先对AR-EGARCH模型进行估计发现I=10,K=L=1的疏系数模型是最合适的模型,模型结果如表2所示。发现残差服从St(偏t)分布的EGARCH模型效果最好,其标准残差不存在异方差性,可以用来预测。

表2 基于St分布的EGARCH模型参数估计
在AR-EGARCH模型的基础上,可拟合预测出每个时点的标准差和方差,再根据QAR-EGARCH模型在训练样本中基于2011年1月1日至2019年8月31日的数据分别在每个分位点上建立QAR-EGARCH模型,接着在所选分位点对2019年9月1日至2019年9月15日的气温进行预测。最后在每个预测时点上求出每个分位点下的2019年9月16日至2019年9月25日的气温预测值。
再对每个分位点上的标准差和方差对应的系数的显著性情况进行分析,各分位点上的情况如表3所示。
下面对其他变量对应的系数的显著性进行分析,情况如表4所示:
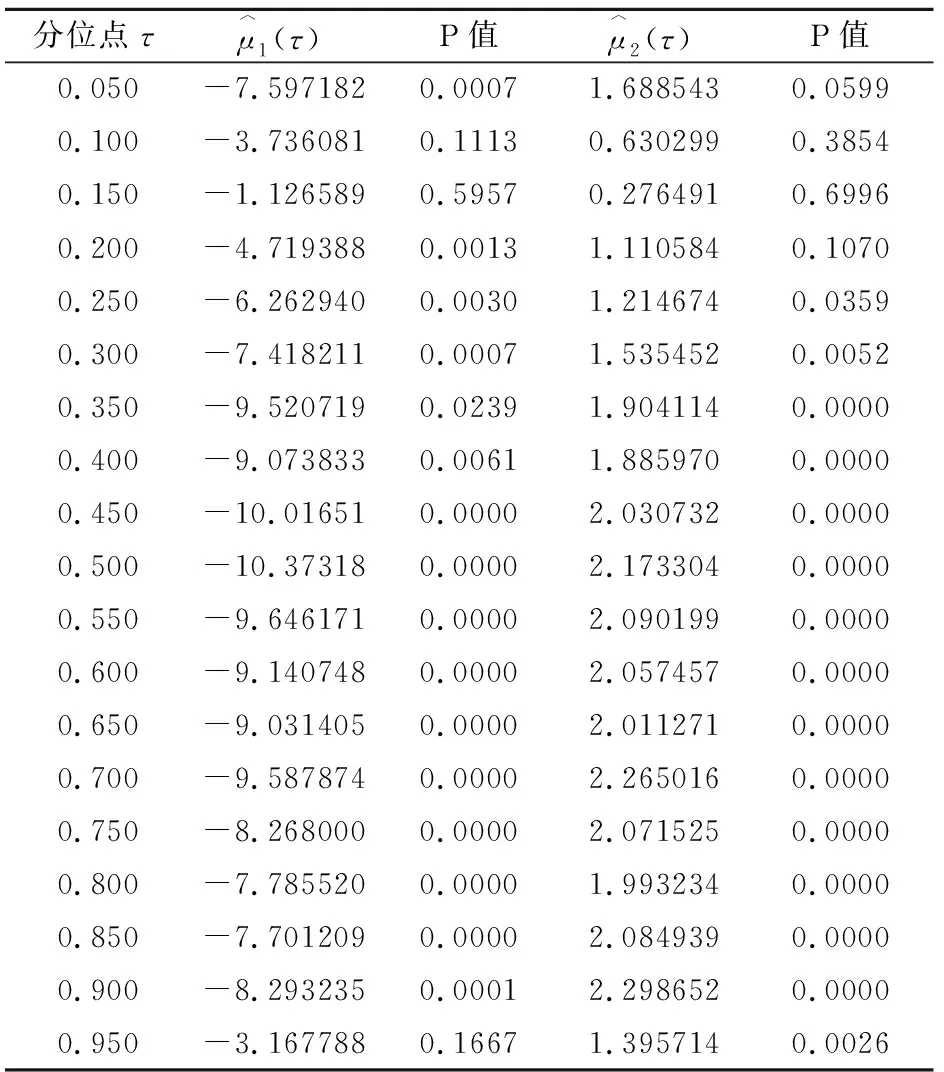
表3 不同分位点下标准差和残差前系数对应的分位数回归结果

表4 其他变量前系数的显著性情况汇总

以上情况说明,在5%的显著性水平下,每个分位点上未必任何变量前的系数都显著,所以下面将在所选取的每个分位点上剔除系数不显著的变量,再根据公式(5)建立模型。
通过不断实验,选取3个分位点(0.35、0.47和0.68),其中0.35和0.68分位点是预测9月1日至15日误差比不上AR-EGARCH模型的预测误差,而0.47分位点的预测误差是众多分位点中最小的,选取系数显著的变量,这三个分位点的参数估计结果如表5所示。

表5 各分位点上显著变量前系数的参数估计
表5中三个模型的残差的LB检验统计量对应的P值均小于0.05,所以需要提取残差,对其进行自回归,直至残差变为白噪声序列[9]。
残差自回归可解决模型提取信息不充分的问题,能使得模型的预测精度更高,对以上三个分位点下的模型残差进行自回归的结果如表6所示。

表6 三个分位点下自回归结果
对以上三个残差自回归模型的残差再进行LB检验,得到表7的结果。
由表7可知,对残差进行自回归后的模型在5%的显著性水平下通过白噪声检验,可以结合每个分位数下的预测情况进行预测。

表7 三个分位点下的LB检验
2.3 预测
本节先对以上三个分位点上的预测情况进行加权组合,首先在这三个分位点上通过对2011年1月1日至2019年8月31日建立模型预测出2019年9月1日至9月15日的气温情况,选取基于最小绝对误差和作为准则,eit是每个分位点下在每个时刻的预测残差。模型有如下形式[10]:
(6)
通过MATLAB的计算,其组合权重向量w=(0.4232,0.0018,0.5750)′,表8是各模型在9月1日至9月15日的气温预测的对比。

表8 各模型气温(9月1日至9月15日)预测情况对比
由表8可知,组合预测模型的预测精度大于AR-EGARCH模型拟合精度和各分位点的预测精度,因而可以考虑用这个模型预测9月16日至9月25日的气温。其中,MSE,MAE和MAPE分别为平均误差平方根,平均绝对误差和平均绝对百分误差。
下面对9月16日至9月25日的气温情况进行预测对比,表9是每个模型的预测性能指标对比。

表9 各模型气温(9月16日至9月25日)预测情况对比
由表9可知,各个预测模型中组合预测模型仍然在三个预测精度指标上均优于AR-EGARCH模型,说明在三个分位点的预测值通过加权组合,可以对模型的预测有一定的优化。
3 总结
以上研究发现,通过对每个分位点的预测情况进行组合加权后,模型的预测精度有明显的提高,这种模型具有一定的应用价值。参考上述研究,气象部门可让不同的人根据自己不同的知识和经验对于未来气温做出不同预测,并通过加权组合,能使得气温预测得更为精准。
