一种基于深度学习的物流快递驿站异常行为识别方法
2020-09-15陈松乐孙知信CHENSongleSUNZhixin
陈松乐,孙知信 CHEN Songle, SUN Zhixin
(1. 南京邮电大学 江苏省邮政大数据技术与应用工程研究中心,江苏 南京 210003;2. 南京邮电大学 国家邮政局邮政行业技术研发中心(物联网技术),江苏 南京 210003)
(1. Engineering Research Center of Post Big Data Technology and Application of Jiangsu Province, Nanjing University of Posts and Telecommunications, Nanjing 210003, China; 2. Research and Development Center of Post Industry Technology of the State Posts Bureau (Internet of Things Technology), Nanjing University of Posts and Telecommunications, Nanjing 210003, China)
0 引 言
近年来,在电子商务的强力推动下,我国物流快递行业呈现出高速发展的态势,在推动流通方式转型、促进消费升级中发挥着越来越重要的作用[1]。在物流快递的末端服务中,快递网点、自助快递柜和快递驿站是较为常见的服务方式[2]。物流快递驿站不仅为用户提供了代收、保管、到付、派件等收件服务,而且提供了验视、称重、包装计费等寄件服务。在功能上,物流快递驿站相比于主要提供代收功能的自助快递柜具有明显的优势,而相比于快递网点,物流快递驿站更加接近消费者,且能够为不同品牌的物流快递公司提供服务。由于上述特点和优势,物流快递驿站在人口密集的社区、校园越来越普及[3]。据统计,目前圆通旗下的妈妈驿站和阿里集团的菜鸟驿站已超过了5.6 万个站点。
物流快递驿站往往采用自助管理方式,需要取件人自己到取件区域找到包裹,工作人员只在出口通道对其包裹进行扫码。而在取件区域,为了减少人力成本,一般并不设置监管人员,因此货架上的包裹实际上处于一种无监管的状态。一些素质不高的取件人不仅会随意摆放他人的包裹,而且还可能会施加抛、掷、踩、踢等暴力动作,甚至会私自打开他人的包裹。这不仅造成了包裹在货架上的错放乱放,甚至会导致包裹的破损和丢失,不可避免地对物流快递驿站自身以及驿站运营品牌造成非常负面的影响。
事实上,物流快递过程中的安全问题已经引起了人们越来越多的重视[4]。物流快递场所一般都安装了摄像机系统,其具有覆盖范围大、对环境和用户透明、以及非侵入的优点。针对物流快递过程中的操作规范性问题,尚淑玲[5]提出了一种基于机器视觉的物流暴力分解方法,其利用小波包分析提取采集的物流分拣图像特征,从而为物流暴力分拣识别提供相似性判断依据。然而,该方法仅仅针对分拣操作人员,且只是对单张图片进行判断。刘稳[6]提出了一种基于高斯混合模型和马尔科夫链的目标检测和跟踪方法,然而其并不能实现对异常动作的分类。近年来,由于深度学习能够有效解决传统手工提取特征表达能力不足以及浅层机器学习方法泛化能力不足等问题,研究者提出了一些基于深度学习的人体行为识别方法[7],如RGB 和光流双路卷积网络[8]、三维卷积神经网络[9]、自动编码器网络[10]等。这些方法主要面向固定视角下的动作识别,也就是训练过程和实际应用的视频数据都是来自于相同的摄像机。然而不同物流快递驿站场所的摄像机位置不可能是完全相同的,从而导致这些方法的实际应用效果会受到很大的影响。
针对上述问题,本文提出了一种基于深度学习的物流快递驿站异常行为识别方法。该方法采用卷积神经网络提取视频每一帧的图像特征,通过递归神经网络对帧与帧之间的时序关系进行建模,并采用多路分支网络架构以适应不同物流快递驿站的摄像机视角变化。在实际物流快递驿站场景下的实验结果验证了本文方法的有效性。
1 基于深度学习的物流快递驿站异常行为识别
1.1 方法总览。基于深度学习的物流快递驿站异常行为识别方法的网络结构如图1 所示,其由多个分支网络构成,每个分支网络对应训练场景中的特定摄像机视角,分别由卷积网络、递归网络、融合网络和分类网络构成。其中卷积网络用来提取视频中每一帧图片的特征,递归网络用来对帧与帧之间的时序关系进行建模。卷积网络和递归网络学习该视角相关的区分性特征,而融合网络则对来自其他分支的特征数据进行融合,以利用不同分支提取特征的互补性,分类网络最终输出每一视频帧属于各个动作的概率。由于实际应用时物流快递驿站的摄像机视角和训练场景并不相同,因此单独训练一个视角分类网络,用于给出输入视频属于各个分支的概率。在应用阶段,物流快递驿站的每路视频输入到各个分支网络,并使用视角分类网络获得的分支概率作为权重来集成各个分支上获得的动作分类结果。
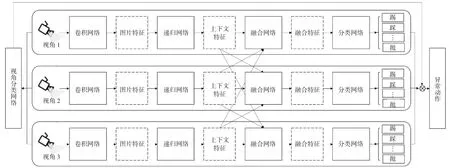
图1 基于深度学习的物流快递驿站异常行为识别网络结构
1.2 基于卷积网络的视频帧图像特征提取。物流快递驿站摄像机拍摄的视频流每一帧对应一张图像,由于图像是一种非结构化数据,需要从图像中提取其特征描述。当前,卷积神经网络已经成为实现图像特征提取的主要手段,其通常由卷积层、池化层、全连接层构成。卷积神经网络的输入,即RGB 图像,通常采用3 通道的矩阵来表示,其输出为固定长度的特征向量。对于i路分支网络t时刻输入的图像xt,i,卷积神经网络特征提取用函数形式定义为:

其中:vt,i为提取的特征表示,θv,i为卷积神经网络fv,i的可调参数。AlexNet[11]、VGG[12]、ResNet[13]是已经获得成功的卷积神经网络架构。由于ResNet 在众多的实验数据集上都取得了比AlexNet 和VGG 更好的性能,因此本文采用ResNet 网络来实现视频流每一帧图像特征的提取。
在神经网络设计中,浅层网络由于表达能力有限,往往无法获得满意的效果,因此人们通常通过加深网络来提升训练效果。然而过深的神经网络又很容易过拟合,导致模型收敛于局部最优解。针对该问题,ResNet 引入了残差网络结构,通过分解来降低拟合函数的复杂度,而损失函数又是拟合函数的函数,所以降低拟合函数的复杂度也就等同于降低损失函数的复杂度。ResNet 残差网络结构如图2 所示。
相比于重复地堆叠网络,ResNet 在输出和输入之间引入了短路连接,从而可以有效地解决网络层数过深出现的梯度消失问题。本文采用在ImageNet 11K 图像集上预训练的152层ResNet 网络[14]提取视频帧的图像特征,输入图像的大小为224×224,输出为ResNet152 网络的flatten0_output 层,其维度为2 048 维,即vt,i∈R2048。
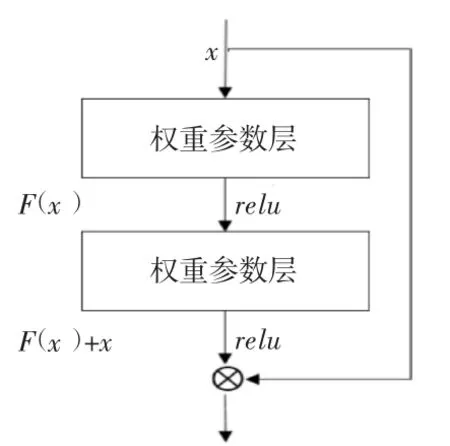
图2 ResNet 残差网络基本结构
1.3 基于递归网络的视频帧与帧时序关系建模。从视频帧中提取图像特征的ResNet 卷积神经网络是前馈神经网络,整个网络没有反馈,因此也没有时序上的记忆功能。实际上,物流快递驿站摄像机拍摄的视频流数据是时序数据,视频帧与帧之间并非独立的,其内部存在特定的逻辑关系。递归神经网络带有环结构,可以记住序列前面的信息,因此具有一定的记忆功能,本文采用递归神经网络对视频帧与帧之间的时序关系进行建模,其函数形式定义为:

其中:vt,i为ResNet 卷积网络对视频帧提取的图片特征,ht-1,i为递归神经网络fr,i的上一个时间步t-1 的输出,θr,i为fr,i的可调参数。当前时间步t的输出为ht,i,其融合了当前图片以及前后关联帧的信息,即当前视频帧的上下文特征。普通的递归神经网络无法较好地解决长时依赖问题,即网络无法学习到距离较远的关联信息。针对该问题,长短时记忆单元网络(Long-Short-Term Memory, LSTM)[15]将传统递归神经网络的隐含层替换为长短时结构单元,从而能够有效地捕获时序数据之间的动态依赖与长时依赖。此外,LSTM 能够方便地扩展为多层结构和双向结构以进一步提高模型的性能[16]。因此,本文采用LSTM 作为递归神经网络来对视频帧之间的时序关系进行建模。LSTM 包含遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate) 和一个记忆单元(Cel)l,其网络结构如图3 所示。
其中:it、ft和ot分别为输入门、输出门和遗忘门的输出,~ct为输入调和模块的输出。输入调和模块和输入门的输入相同,但是其使用tanh激活函数。在图3 中,σ 为sigmoid激活函数,φ 为tanh激活函数。在实现中使用了2 层LSTM,每层各包含1 024 个单元。
1.4 基于融合网络的分支特征融合。与特定视角相对应的分支通过ResNet 网络和LSTM 网络获得了当前视频帧的上下文特征。通过训练,这些分支上下文特征从不同的视角提取了用于对动作进行分类的区分性描述。然而不同分支之间的上下文特征之间存在着很大的相关性和互补性,可以进一步对其进行融合以提高行为识别的性能。对于每一个分支,本文采用的融合网络定义为:
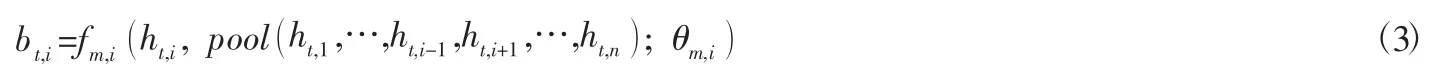
其中:ht,i表示分支i在时刻t经过ResNet 网络和LSTM 网络获得的上下文特征,pool表示池化层函数,分支i在时刻t经过融合函数fm,i处理后获得的融合特征表示为bt,i,θm,i为fm,i的可调参数。以分支1 为例,融合网络结构如图4 所示,其任务是从其他的分支中提取与分支1 相互补的特征。本文采用池化层来提取分支2 到分支n的上下文彷射不变特征并有效降低特征的维度。池化层可以选择均匀池化或者最大化池化,通过实验发现最大化池化相比于均匀池化能够取得更好的性能,因此用最大化池化。在将池化层的输出与分支1 的上下文特征进行合并后,采用1 层全连接层对合并的特征进行非线性变换。全连接层的输出为2 048 维,采用relu激活函数,最终得到2 048 维的分支1 融合特征bt,1。
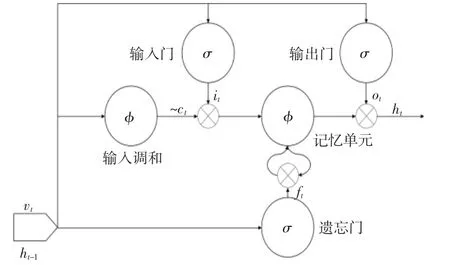
图3 LSTM 网络结构
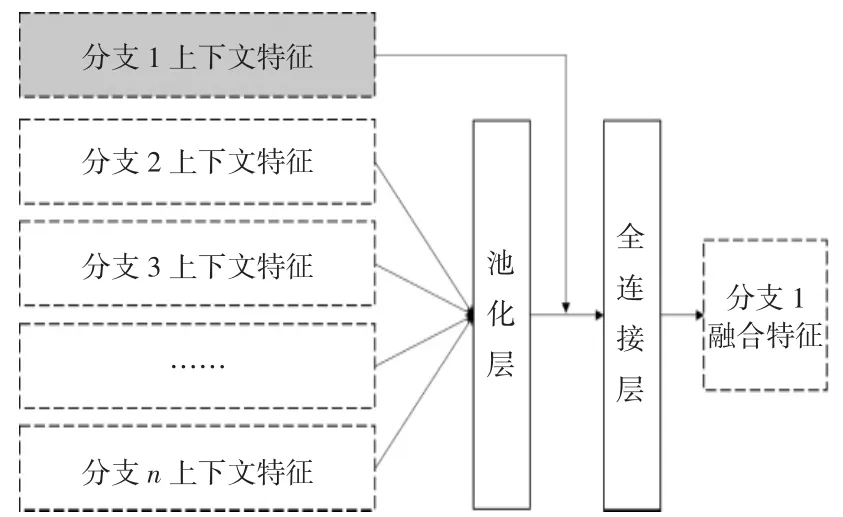
图4 以分支1 为例的融合网络结构
1.5 动作分类网络。分支融合网络的输出bt,i融合了分支i的上下文特征以及其他分支的互补特征,将作为分支动作分类网络的输入。动作分类网络首先使用全连接线性变换层将其映射到等同于动作类别数的维度,最后采用SoftMax 进行归一化,最终给出当前t时刻摄像机采集的视频帧xt,i属于每个动作类别的概率p(yc,i),即:

其中:θc,i为分类网络函数fc,i的可调参数。
1.6 视角分类网络与预测集成。在训练阶段,将各个视角的视频数据和各个分支一一对应,从而完成分支网络模型参数的更新。然而当实际应用到不同的物流快递驿站时,并不能预先确定各路视频和分支网络的对应关系,并且各路视频和分支网络对应的视角也很难完全一致。为了提高训练模型的泛化能力,本文采用视角分类网络对输入的视频进行分类,从而得到输入的视频数据属于各个分支网络的概率。视角分类网络结构如图5 所示。
对于视角分类网络,采用1.2 节描述的ResNet152 卷积网络提取视频帧图像特征,使用1.3 节描述的LSTM 递归网络获得融合时序信息的上下文特征,然后使用全连接层对提取的上下文特征进行非线性变换,全连接层的输出为2 048 维,采用relu激活函数,最后通过SoftMax 层得到输入的视频帧属于各个分支对应视角的概率p(yi)。视角分类网络可以定义为:

其中:xt为各个视角的视频帧图像,θb为视角分类网络fb的可调参数。实际应用时,对于物流快递驿站监控区域的每一路摄像机视频数据,将其输入到训练的每个分支模型中,得到每个分支模型i预测的动作分类结果p(yc,i),然后根据视角分类网络预测的结果对分支预测的动作分类结果进行集成,最终的动作分类结果为:
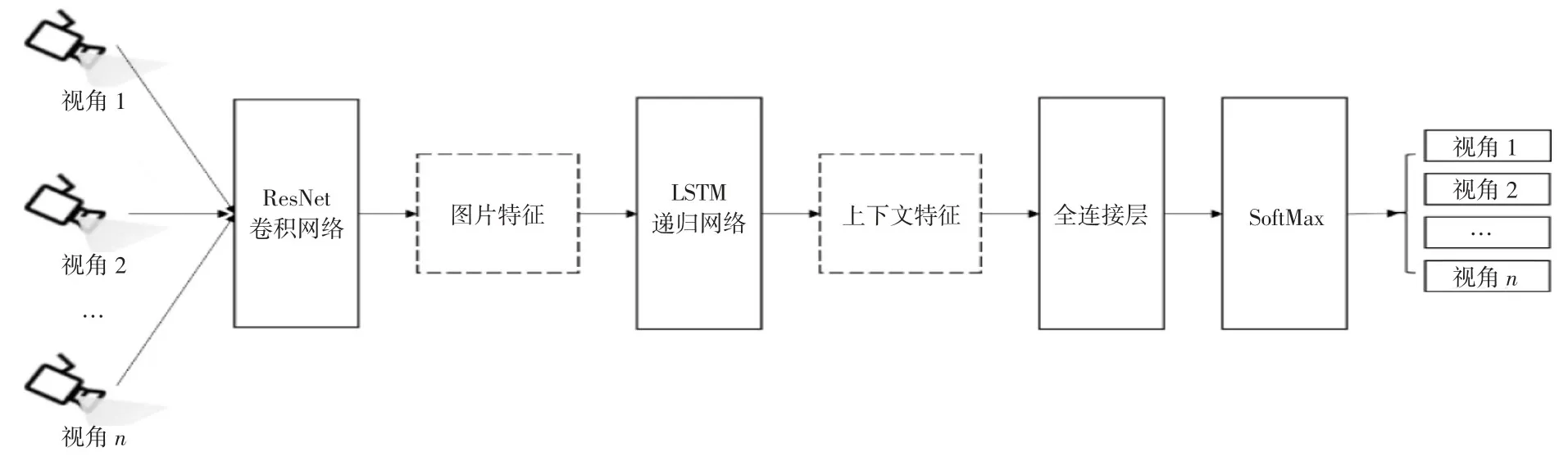
图5 视角分类网络结构

1.7 模型训练
每个分支网络对应的网络参数是非共享的,其损失函数为交叉熵损失,即:

其中:S为样本数,K为动作类别数,当k为样本s的实际类别时,ys,k=1,否则ys,k=0,ps,k为模型对样本s预测为k类的概率。对于每个分支网络,首先使用该分支对应视角的样本单独训练出融合网络之外的网络参数,在每个分支网络训练收敛后,再逐步训练融合网络的参数以及微调其他网络模块的参数。
视角预测网络的网络参数对于所有的分支是共享的,同样采用交叉熵损失函数,即:

其中S为所有视角的样本数,n为分支数,当i为样本s的实际分支对应的视角时,ys,i=1,否则ys,i=0,ps,i为视角预测网络模型对样本s预测为第i个分支对应的视角的概率。在预测出每一帧对应的动作后,使用前后各7 帧的预测结果进行平滑处理。
2 实验结果与分析
为了对本文提出的方法进行验证,在实际物流快递驿站采集了取件过程中的异常动作。在训练时,由于每一个分支网络需要和特定的视角相对应,因此在物流快递驿站共使用5 个摄像机来采集视频数据。对于同一个动作,4 个互相正交的摄像机的数据作为训练数据,余下的1 个摄像机采集的数据作为测试数据。本次实验共设计了踩、踢、拖、扔、抛5 类异常动作,如图6 所示。每类动作采集了500 个样本,共有20 个人参与了本次样本采集,其中16 个人的执行动作被作为训练样本,其余4 个人的执行动作被作为测试样本。此外,还从日常快递驿站的视频中截取了4 000 个正常的取件动作。正常动作和踩、踢、拖、扔、抛5 类异常动作的样本总数为6 500 个,每个动作的持续时间为2~5 秒,对每个动作的视频向下采样,帧率为30 帧/秒。

图6 5 类异常行为动作示例
本文以TensorFlow 为深度学习框架,在GPU Tesla P100 平台上采用SGD 梯度下降算法对这些数据进行了训练,设置学习率在开始的1 000 个循环中为0.001,然后逐渐减少到最小值0.0001。图7 给出了其中一个分支网络在训练过程中的损失值变化过程。随着迭代次数的增加,损失值逐渐变小,在迭代次数约为10K 的时候模型达到了收敛。
本文通过多分支网络架构来解决训练模型应用到不同物流快递驿站摄像机视角变化问题,为了验证本文方法的有效性,采用图5 所示的视角分类网络结构实现了动作分类网络作为对比,简写为ResNet+LSTM。此外,由于iDT[17]作为手工提取的特征在众多的数据集上都取得了很好的识别性能,因此也将本文提出的方法与iDT 方法进行对比。表1 给出了这3 种方法对于异常行为的分类准确率,图8 为其对应的柱状图显示。
从表1 图8 可以看出,“扔”和“抛”这两类异常行为的识别率要低于其他3 种类别的异常行为,可能的原因是“扔”和“抛”这两个动作更容易受到货架的干扰。总体上,iDT 在这3 种方法中性能较差,取得的平均准确率只有60.6%,尽管iDT 在固定视角情况下取得了较好的分类性能,然后当将其训练的模型应用到新视角时,其手工提取的特征的泛化能力较差。ResNet+LSTM 方法获得了73.8%的平均分类准确率,分类的性能要优于iDT 方法,主要原因在于ImageNet 上预训练的卷积网络ResNet 提取的特征具有更好的表达能力。本文提出的方法获得了最好的性能,其分类平均准确率达到了82.9%,这主要是因为在ResNet+LSTM 方法的基础上,本文采用的分支网络架构能够根据新视角属于每个分支的概率提取其区分性特征并有效对其融合,从而使训练的模型能够更好地适应不同的物流快递驿站场景。
3 总 结
本文提出了一种基于深度学习的物流快递驿站异常行为识别方法,其采用卷积神经网络ResNet152 和递归神经网络LSTM 提取视频帧的上下文特征,并采用多路分支网络架构以使得训练的模型能够适应不同物流快递驿站的摄像机视角变化,实验结果验证了本文方法相比于基于手工特征的传统方法以及基于单网络结构的深度学习方法具有更好的性能。本文提出的网络结构的输入为连续的视频并依次判断每一帧属于异常行为的概率,因此可以方便地将其应用到实际场景中。在今后的研究中,拟通过增加深度图像以及光流信息来进一步提高识别的准确率。
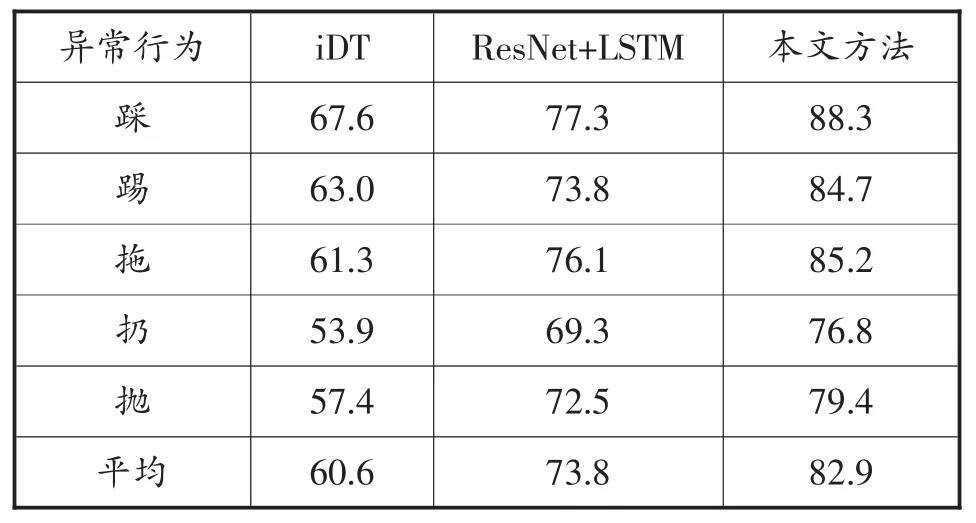
表1 三种方法对于异常行为分类性能对比
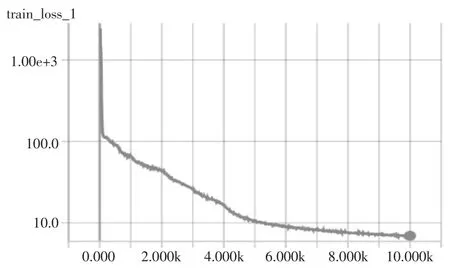
图7 分支网络训练过程中损失值变化过程
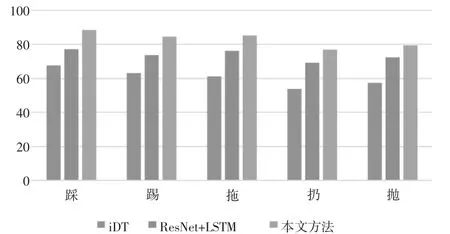
图8 三种方法对于异常行为分类性能对比
