数据中心Web系统非结构化数据治理策略及措施
2020-09-14杜小丹吴成宾王惟洁刘新跃罗德彪
杜小丹, 吴成宾, 王惟洁,2, 何 源, 刘新跃, 罗德彪
(1. 成都大学信息网络中心,成都610106;2. 成都理工大学地球物理学院,成都610059)
0 引 言
随着科技的发展、竞争的加剧,以及进一步提高服务意识、服务质量的需求,许多组织机构需要对多年来信息化建设过程中积累和沉淀下来的最重要的资产之一,即数据资产进行统一治理和深度挖掘,以期获得更好的收益。因此,近年来数据中心[1]的建设始终是一项重要的工作,智慧型数据中心建设的核心理念是数据治理[2-3],数据治理包括数据的标准化、数据整合、数据集成、数据分析、数据质量分析、数据共享融合等诸多方面[4-7]。数据治理是一个漫长的过程,需要循序渐进地分步推进,才有可能建成一个良好的数据生态圈[8]。从目前的情况来看,对业务流程系统的数据治理相对比较重视,而对Web系统的数据治理则不够重视。数据中心数据治理的目标是建成个人Web 数据中心平台,形成个性化的数据微服务,不断完善数据治理生态建设,建成数据治理免疫系统,全面保障数据资产,建成大数据智慧分析决策系统,为领导决策提供有力支撑。
1 Web系统数据存在的问题分析
MySQL[9]由于集开源、免费、使用方便以及高可靠性等诸多优点于一身而被广泛使用,据第三方权威评测机构DB-Engines 提供的数据表明,近20 年来,MySQL一直雄踞全球Web数据库市场占有率首位,但一些较早期设计的基于MySQL 的Web 系统往往对各种结构化和非结构化数据[10-11]没有实行有效管控,随着并发访问量越来越大,系统性能下滑显著,原因主要在于:①Web服务器上除了部署、运行程序文件之外,许多上传的各种附件虽然其URL 信息保存在数据库中,但是URL对应的实际的文件却存放在Web 服务器上,导致其负载过重;②数据库服务器本身负载也过重,部分Web 系统把包括文本、图像、音频、视频等几乎所有类型的结构化和非结构化数据都存入数据库,而这类数据量往往较大,传输时非常耗费带宽,如果数据库和Web服务器不在同一台服务器上,那么为了获取一幅图像(或者音视频等),客户端需要从Web服务器取数据,Web 端又需要从数据库端获取,这样会同时在数据库端和Web 端两处I/ O 上都形成访问瓶颈。进一步的分析发现,部分早期设计的不规范的Web系统中,通过Web页面上传的图像、音频、视频等二进制非结构化数据文件,在数据库中常以base64[12]编码形式保存,且可能与结构化文本等信息混合存放在同一个字段中,因此需要设计算法来剥离以base64编码形式保存的非结构化数据。base64 是互联网上最常见的用于传输8 bit数据的编码方式之一,通常用于把二进制数据编码为可见的字符形式的数据,这是一种可逆的编码方式。base64 编码将每3 bit变成4 bit,因此编码后长度增加1 / 3。编码后的数据是一个字符串,其中包含的字符为:A-Z、a-z、0-9、+、/共64 种字符,规定将“=”作为填充字符,因此base64 编码实际上由65 种字符组成。
2 Web系统数据治理策略及措施
Web系统数据治理的主要策略是将非结构化数据从数据库服务器和Web 服务器剥离出来单独存放在不同的服务器上,治理的直接结果是减少带宽占用,消除I/ O瓶颈,提高响应速度,并为下一步提升Web数据的标准化水平、提升数据质量和共享融合水平奠定基础。为此需从两个方面同时给Web 服务器和数据库服务器减负:①将各种上传的附件文件(包括普通文件,图像、音频、视频等文件,其URL 链接信息保存在数据库中)从Web服务器剥离出来,② 将数据库中以base64 编码保存的各种图像、音视频等非结构化数据从数据库中剥离出来。剥离出来的各种非结构化的数据文件全部转储到单独的文件、图像、音频、视频服务器上,达到既减负又分流非结构化数据的目的。数据治理具体措施主要包括如下几个处理步骤:初始化;非结构化数据识别、提取、剥离;剥离了非结构化数据后剩下的结构化数据回写数据库;最后将剥离出来的非结构化数据文件迁移到单独的各类服务器上。
2.1 初始化
分别配置图像、音频、视频、文件服务器,假设其根路径分别为image,audio,video,file,分配相应的IP地址和域名,假设根域名为example. com,则图像、音频、视频、文件服务器的域名可分别设置为image.example. com,audio. example. com, video. example.com,file. example. com。在运行本文提出的策略措施算法的计算机(以下简称为A 机)上创建目录image,audio,video,file,分别用于暂时存储剥离出来的图像、音频、视频及普通文件。
2.2 非结构化数据识别、提取、剥离流程
对数据库中存在非结构化数据的每个表执行base64 编码以及URL链接信息数据扫描、识别、提取、剥离操作,直到整个数据库处理完毕。假设某个表名为newsdata,其含有newsid,postdate,content 3 个字段,其中content字段混合存储了结构化的文本数据、以base64 编码的非结构化的图像、音频、视频等数据,以及URL链接信息数据。从content 字段中扫描、识别、提取、剥离非结构化数据的主要流程为:
①A机连接数据库,构建查询语句:sql =" select newsid,postdate,content from newsdata where content!=NULL ",执行该sql语句,将返回的表查询结果集保存在结果集变量rs中,转②。
②从结果集rs中读取一条记录,检测是否读到结果集尾,若是,转⑧;若否,将当前记录的newsid,postdate,content字段内容分别赋予全局变量newsid ,postdate,content,全局变量bChanged 赋初值FALSE,转③。
③ 执行普通文件URL 识别、提取、剥离模块,转④。
④执行图像文件base64 编码及URL识别、提取、剥离模块,转⑤。
⑤执行视频文件base64 编码及URL识别、提取、剥离模块,转⑥。
⑥执行音频文件base64 编码及URL识别、提取、剥离模块,转⑦。
⑦执行剥离了非结构化数据后剩下的结构化数据回写数据库模块,转②。
⑧关闭结果集,关闭数据库连接。
(1)普通文件URL识别、提取、剥离模块流程
① 初始化int 型局部变量iPosH =iPosT =iCount=0,转②。
②以iPosT 为起始位置,扫描content 中有无“<a”特征串[13],将扫描到的特征串起始位置赋予iPosH,检测“iPosH < = - 1”,若是,表明没有扫描到该特征串,转④;否则,以iPosH 为起始位置,扫描content中有无“>”特征串,将扫描到的特征串起始位置赋予iPosT,检测“iPosT < = - 1”,若是,转④;否则,检测“iPosT >iPosH”,若是,转③,否则转④。
③以iPosH为起始位置,扫描content中有无“href=”特征串,若有,判断“href =”后面引号中指明的文件链接URL是否为相对路径,若否,说明该文件没有存放在正被处理的Web 服务器上,无需剥离,更新下一次扫描的起始点位置为:iPosT =iPosH + 1,转②;若是,从postdate串中提取出“年月”,根据“年月”在A机上的file 目录下创建路径,从URL中提取出文件名称,并将文件按以下规则重新命名:文件名+ iCount.后缀名,拷贝URL 文件到A 机相应路径下,修改content 串,将原来的URL 替换为“http:/ / file.example. com/路径/新文件名”,然后删除原来的URL文件,修改变量bChanged =TRUE,iCount + +,更新下一次扫描的起始位置:iPosT =iPosH + 1,转②。
④本模块处理完毕,转下一模块。
(2)图像文件base64 编码及URL 识别、提取、剥离模块流程
① 初始化int 型局部变量iPosH =iPosT =iCount=0,转②。
②以iPosT为起始位置,扫描content 中有无“<img ”特征串,将扫描到的特征串起始位置赋予iPosH,检测“iPosH < = - 1”,若是,转⑤;否则,以iPosH 为起始位置,扫描content中有无“>”特征串,将扫描到的特征串起始位置赋予iPosT,检测“iPosT <= - 1”,若是,转⑤;否则,检测“iPosT > iPosH”,若是,转③,否则转⑤。
③ 以iPosH 为起始位置,扫描content 中有无“data:image /”[14]特征串,将扫描到的特征串起始位置赋予iPicPosH,检测“iPicPosH < = - 1”,若是,转④;否则,以iPosH 为起始位置,扫描content 中有无“;base64,”特征串,将扫描到的特征串起始位置赋予iPicPosT,取得图像类型:iPosHOff =length(" data:image /" ),
ImgType =substr(content,iPicPosH + iPosHOff ,iPicPosT-iPicPosH-iPosHOff)。
这里iPosHOff 为图像base64 编码特征串(即“data:image /”)长度,ImgType 为取得的图像类型(如PNG,JPG 等),substr 为取子串函数,第1 个参数content为被取串,第2 个参数表示从被取串读取的偏移量,第3 个参数为预截取的子串长度。
以iPicPosH为起始位置,扫描content 中有无“,”特征串,将扫描到的特征串起始位置赋予iPosComma,检测“iPosComma < = - 1”,若是,更新下一次扫描的起始位置:iPosT =iPosH + 1,转②。
为即将提取出的图像文件按照如下规则命名:年月+ iCount. ImgType,然后指定文件的URL 地址为“http:/ / image. example. com/路径/文件名”。
提取图像文件base64 编码数据:img =substr(content,iPosComma + 1,iPosT-iPosComma-1)。
上传的图像极有可能由于各种原因,致使其base64编码被修改,使得提取出的img 不能还原成图像文件,故需对img进行如下处理:去掉img 尾部单引号和/或双引号及其后的所有数据;去掉img尾部的空格;将img非尾部的空格全部替换成“+”,这样即可按照base64编码规则将img还原成二进制的图像文件。
还原的图像文件暂存在A 机的image 目录下,修改content串,将扫描到的图像base64 编码(即位于iPosH和iPosT之间的所有子串,含头尾)替换为类似如下“http:/ / image. example. com/路径/文件名”的URL ,修改变量bChanged =TRUE,iCount + +,更新下一次扫描的起始位置:iPosT =iPosH + iPosHOff ,转②。
④以iPosH为起始位置,扫描content中有无“src=”特征串,若有,判断“src =”后面引号中指明的文件链接URL是否为相对路径,若否,说明该文件没有存放在正被处理的Web 服务器上,无需剥离,更新下一次扫描的起始位置:iPosT = iPosH + 1,转②;若是,则从postdate串中提取出“年月”,根据“年月”在A机上的image 目录下创建路径,从URL中提取出文件名称,并将文件按以下规则更名为新文件:文件名+iCount.后缀名,拷贝URL文件到A 机相应路径下,修改content 串,将原来的URL 替换为“http:/ / image.example. com/路径/新文件名”,然后删除原来的URL文件,修改变量bChanged =TRUE,iCount + +,更新下一次扫描的起始位置:iPosT =iPosH + 1,转②。
⑤本模块处理完毕,转下一模块。
接下来的视频、音频文件base64 编码及URL 识别、提取、剥离模块算法流程与图像文件base64 编码及URL识别、提取、剥离模块算法流程类似,只是特征码不一样而已,不再赘述。
2.3 剥离了非结构化数据后剩下的结构化数据回写数据库模块流程
检测标志变量bChanged是否为TRUE,若是,说明该条记录被修改了,需要重新回写到数据库中,构建SQL语句:
sql = " update newsdata set content =content where newsid =newsid";
execute(sql);/ /执行SQL回写命令
2.4 剥离出来的非结构化数据文件迁移到单独的各类服务器
将剥离出来的暂存在A 机上file、image、video、audio目录下的所有非结构化数据文件分别转储到文件、图像、音频、视频服务器上,这样就完成了非结构化数据文件的迁移。
3 结 语
Web系统非结构化数据经过数据治理后获得的新的扁平化的Web系统架构如图1 所示,最终用户访问新Web系统时,如果要获取图像、音频、视频或者其他普通文件等非结构化数据,仅需访问Web服务器和数据库服务器各一次,取得URL 信息后,客户端直接从相应的服务器去获取实际的数据文件,不会给Web
服务器或数据库服务器带来多次访问的压力,消除了访问瓶颈,提高了系统响应速度。扁平化的Web系统结构非常易于横向扩展而无需对程序软件做任何修改,保护了用户投资的同时,也缩短了规模化部署周期。此外,新系统也可以很方便地部署负载均衡设备、CDN(Content Delivery Network,内容分发网络)设备、以及实施静态化页面等Web 系统优化措施[15],这些为下一步提升Web数据的标准化水平、提升数据质量和共享融合水平奠定了坚实的基础,从而为最终迈向良好的数据中心数据生态圈提供了先决条件。
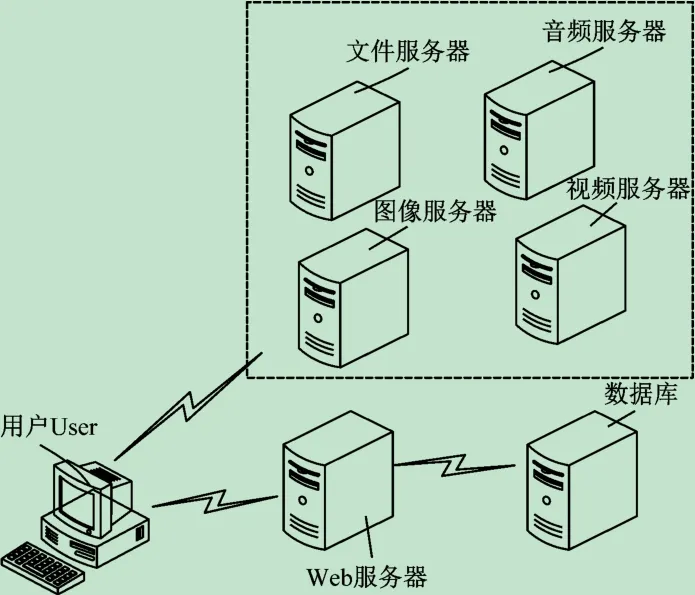
图1 数据治理后的扁平化Web系统架构
