苏、日、欧人工智能发展错误决策后的哲学迷思
2020-09-11徐英瑾
徐 英 瑾
(复旦大学 哲学学院,上海 200433)
众所周知,现代理论计算机科学之父是英国学者图灵(Alan Turing, 1912—1954),实体意义上的现代计算机之父是美籍匈牙利人约翰·冯·诺依曼( John Von Neumann,1903—1957), “人工智能”(Artificial Intelligence,以下简称为AI)学科诞生的标志性事件则是1956年美国召开的“达特茅斯”会议。此后,计算机与人工智能业界与学界的最重要的进步,基本都发生在英语世界,特别是在美国。美国的苹果、谷歌、IBM、微软等技术巨头在相关领域内的领先地位,也是世界公认的。不过,也恰恰是因为AI研究在美国的相对成功,国内学界往往过分看重人工智能研究中的“美国经验”,而忽略了同一研究领域内的他国经验教训。应当看到,人工智能也好,广义的计算机技术也罢,其发展对任何一国的综合国力的提高都有举足轻重的意义,这一点亦为美国之外的各国技术与政经精英所知晓。因此,试图以“大国争雄”为目的,与美国一比高下的国家或国家联盟,显然都不可能放弃对相关技术领域的投入。而在我国之外,历史上各强国(或国家联盟)在计算机或人工智能领域内试图冲击美国的霸主地位(或至少接近其霸主地位)的典型案例,至少有以下三个:第一是苏联几十年间对美国计算机技术的跟踪与所谓的“控制论”研究,第二是日本的“第五代计算机计划”,第三是欧盟的“蓝脑计划”。有意思的是,虽然这三次努力的发起者各自的政治、经济背景都彼此不同,但这三次努力也都有明显的共性:第一,这些努力都不算成功;第二,这些努力均在一定程度上留下了政府干预的明显痕迹;第三,指导这些努力的决策方式都是奠基在此种或彼种错误的哲学预设之上的。而本文的任务,便是以回顾苏、日、欧三方各自的计算机/人工智能发展策略的技术史史实为入手点,揭露错误的哲学预设是如何进入各国的科学发展决策的,由此从反面体现健全的哲学思辨对于正确的科技决策所能够起到的不可或缺的作用。
一、苏联的计算机/人工智能研究计划背后的哲学失误
众所周知,在“冷战”期间,苏联一直以来是美国在科技领域的主要竞争对手——但奇怪的是,在AI领域,乃至整个计算机科学领域,其研究成绩都明显落后于美国。实际上,苏联倘若真想大力发展AI,既不缺人才(苏联有非常深厚的数学研究底蕴),也不缺资金(社会主义的举国体制完全能支撑得起相关的科研消耗),更不缺应用领域(AI在军事方面的价值是很明显的。1943年斯大林远赴德黑兰开会的飞机航线,就是苏联专家通过美国IBM公司提供的计算设备制定的。)那么,苏联的计算机/AI产业,为何一直留给世人“落后”的印象呢?对于该问题的讨论,我们不妨从苏联计算机发展的亲历者鲍里斯·马林诺夫斯基(Boris Nikolaevich Malinovsky,1921~)在《苏联计算机技术先驱》一书中的评论为入手点。具体而言,马林诺夫斯基将苏联计算机工业落后于美国的缘由归结为以下四点:(1)Boris N. Malinovsky, Pioneers of Soviet Computing (Edited by Anne Fitzpatrick. Translated by Emmanuel Aronie, published electronically, 2010):Ⅷ,http.//www.sigcis.org/tiles/sig-cismc 2010_001.pdf.
第一,“冷战”开始后,苏联政府拒绝了某些西欧公司与苏联合作开发新一代计算机的计划,导致研究上的故步自封;
第二,由于在战时使用IBM设备带来的“甜头”,苏联官方片面强调逆向工程学仿造西方器械的重要性,不顾科学家的反对,上马对于IBM-360计算机的仿造工作。此项计划所占据的资源过多,使得苏联本土的计算机发展计划被严重耽搁;
第三,20世纪70年代,苏联政府将全国的计算机研究力量分解为三个互不统属的部分,彼此信息不流通,导致大量的项目重复与资金浪费;
第四,苏联政府对科学研究与计算机技术之间的内在关联理解不是很深,这就使得计算机技术的发展规划很难被摆放在国家战略的层面上来加以重视。
不过,由于马林诺夫斯基本人是苏联时代计算机产业的亲历者,其判断多少受到其特定行业利益的影响,因此,评判结果未必完全客观。其实,他提出的四点指责,除了第三条多少切中了问题的要害,另外三条都是值得商榷的。
先说第四条。在这个问题上马林诺夫斯基至多只是说对了一半。更准确的说法是:苏联政府认识到计算机重要性的时间虽然比较晚,但很难说重视不够。根据许万增的概括,20世纪60年代中期之后,苏联党和国家领导人在历届党代会上都开始强调发展计算机的重要性。(2)许万增:《苏联计算机发展战略》,《国际技术经济研究学报》1990年第3期。如勃列日涅夫在1966年苏共二十三大、柯西金在1971年苏共二十四大上,都强调了发展计算机产业的重要性,而在后一个会议上,苏共甚至还在国策层面上批准了“OGAS”信息网络计划的一个缩减化版本(详后)。从1966年开始的苏联第八个五年计划中,计算机也成了国家重点扶持项目,得到相当的资金扶持。苏联教育当局亦从1985年9月开始,在全国中学开始普及计算机教育。从这个意义上说,至少在苏联中后期的历史中,苏联领导层对于计算机的重视程度还是颇为可观的。
至于马林诺夫斯基指责苏联当局的第一条理由,更是有所夸大。实际上,在所谓“输出管制统筹委员会(Coordinating Committee for Multilateral Export Controls)” (简称为“巴统”,因总部在巴黎而得名)的控制下,美国自身的企业也好,所有的美国的盟友国的企业也罢,其向社会主义阵营成员出口高科技设备的商业行为,都会受到重要的政治限制,敏感的计算机设备更是如此。在这些管制的基础上,美国在1974年还出台了“国家安全决定备忘录247号文件”,规定了对社会主义国家出口计算机设备的技术上限。这当然是首先针对苏联的。甚至在1979年美国放松对同为社会主义国家的中国的计算机产品出口限制之后,原来的对苏联的出口限制依然没有放松,以便作为苏联入侵阿富汗的政治惩罚。实际上,对于这种严峻的国际技术封锁环境,苏联方面并不是懵懂无知的,也采取了一定的反制措施。譬如,即使在“巴统”的制约下,苏联也利用部分美国盟友的“逐利”心态以及“巴统”的“行政例外程序”所提供的漏洞,努力获取西方先进计算机技术。具体而言,苏联在1967年以其盟国捷克斯洛伐克为管道,获取了一批先进的计算机技术(CPU与磁带处理器),1969年以其盟国波兰为管道从法国进口计算机,1971年直接从英国进口计算机,并由此引发了美国在巴统内部与其盟国的纷争。(3)更多的相关历史细节,请参看吴敏:《计算机与冷战——美国对苏联和中国限制出口计算机政策》,长春:东北师范大学硕士学位论文,2011年。从这个角度看,历史的真相与其说是像马林诺夫斯基所描述的那样,“苏联拒绝了与西方合作研制计算机的机会”,还不如说是“苏联欲求此类机会而不得”。
再来看马林诺夫斯基说的第二条批评。苏联当局决定仿制IBM-360是不是一个策略性失误呢?要回答这个问题,我们首先要来看看此时苏联的国产计算机与IBM-360计算机之间的性能水平之间的距离。在战后,苏联本国研制的计算机主要有:(1)MESM计算机,设计者是列别杰夫(Sergey Alexeyevich Lebedev 1902—1974),1948—1951年研制——这可是一台用了6000个真空管、消耗了25千万电力、需要10米长的空间摆放的大家伙。(2)BESM计算机,实为MESM的后继者,共发展四代,其中第一代与第二代使用真空管,第三代开始换用晶体管。此计算机曾用于防空导弹的信息控制。(3)M-220,主设计师安东诺夫(Veniamin Stepanovich Antonov,1925—),大约在1968年完成研制,其技术前身是M-20。(4)MINSK系列计算机,从1959年一直研制到了1975年,技术力量基于白俄罗斯加盟共和国(因此也在白俄罗斯独立后被称为该国第一代国产计算机),其中最先进的型号是MINSK-32。
结合具体历史背景来看,很难说这些计算机性能不好——其中的MESM与BESM的性能,也曾在欧洲称霸一时,而BESM则稳定服役了二十年,可谓非常“皮实”。但这些机器都有一个共性,即它们要么就是基于真空管的第一代计算机,要么是基于电子管的第二代计算机,而都不是基于小规模集成电路的第三代计算机,遑论基于大规模集成电路的第四代计算机。但IBM-360恰恰是一台划时代的产品。作为第三代计算机的代表产品,对它的研制曾迫使IBM消耗50亿美金进行商业豪赌。除了使用了当时非常先进的集成电路作为更为便宜、轻便与稳定的硬件基础之外,IBM公司还在IBM-360之上使用了“微指令”(microcode)技术,以便将机器指令与相关的电路实现分离,最终使得机器指令可以更为自由地进行设计与修改,而不用考虑到实际的电路架构。这些“黑科技”使得IBM-360的性能在大幅度提升的同时,也远远超越了苏联的既有计算机。在面对如此可怕的技术差距的情况下,对仿制美国技术产品颇有心理依赖的苏联当局,自然会联想起当年图波列夫设计局仿制美国B-29轰炸机、研制出图—4的成功经验(后者在西方有“B-29斯基”之昵称),而转而去研究IBM-360的“苏联化”问题。若抛开版权这一微妙的法律问题不谈,苏联当局的这一决策从功利角度看是有一定合理性的,毕竟沿着别人的脚印前进,试错成本要远远小于自己开创新路。譬如,作为苏联时代唯一在市面上贩售的个人电脑,在1984投入使用的BK-0010电脑价格最终被压缩到600卢布之内(1984年的1卢布大约相当于同时期的1.26 美元),其性能也算是可接受的,其出现亦大大便利了全苏联展开的对于青少年的计算机教学工作。但这种产品恰恰是在苏联对“苹果II”电脑进行不成功的仿制之后才逐步成功的(相关仿制成果乃是价格昂贵到BK-0010之10倍左右的“Agat”计算机)。如果当初苏联当局不作出仿造IBM-360的决策,最后恐怕连BK-0010这个级别的产品也不会具有。
从上面的分析看,苏联计算机产业不够发达的根本原因,并不在于马林诺夫斯基所说的以上三条,而在于内生于苏联政治结构与工业体系的一些固有问题:
第一,苏联缺乏足够强大与广泛的中层政治精英,以支持计算机技术运用。由于苏联是典型的计划经济体制,而社会的经济生活又被各级经济管制官员所控制,所以,这些中层干部对于计算机技术的态度,就对此类技术在苏联的命运产生了决定性的影响。但由于计算机技术具有提高信息处理效率的天然属性,对于它的使用必然会威胁到经济干部编制的规模,因此,其在苏联国情下的命运,也就完全不难被预测到了。在这方面的最典型案例,就是苏联版的“互联网计划”的夭折。这就是所谓的“OGAS”系统(即“全国自动系统”,英文“All-State Automated System”)的研制计划。该计划的最早提倡者是基托夫(Anatoly Ivanovich Kitov, 1920—2005)。他受到 “控制论”(cybernetics)思想的影响(对于控制论的介绍详后),提出要在全国范围内建立计算机网络信息处理系统,以提高苏式计划经济体系的运作效率,减少人为浪费。但因为这样的计划需要建立一个横跨军、民的跨行业信息整合平台,对军方特权利益有所触动,所以计划没有实施。在1971年,计算机专家格卢什科夫(Victor Mikhailovich Glushkov)则沿着基托夫的足迹,正式提出了OGAS计划。按其规划,该网络一旦建成,莫斯科的经济主管部门将通过处于首都的网络中心,实时了解全国约200个城市网络节点与约20,000个经济运作终端传输来的经济信息,而且各个节点之间也能进行信息传输。思想超前的格卢什科夫甚至设想利用此系统进行电子货币支付。然而,虽然苏共“二十四大”只批准了对于一个局域版本的OGAS计划的投资,但当时的苏联财政部部长加尔布佐夫(Vasily Fyodorovich Garbuzov, 1911—1985)则出于部门利益的原因,一直对该计划的实施进行行政阻挠。由此,苏联错过了抢在美国之前建立一个互联网系统的唯一机会。(4)甚至这样的“互联网”也不是我们现在所使用的互联网,因为苏式的互联网具有明显的纵向信息控制特征,体现了明显的计划性,而现有的互联网主要是建立在相对平等的信息节点之间的横向关系之上的,体现了明显的非计划性。但因为本文不是专门讨论互联网的,对于这个问题笔者不想深究。
第二,苏联缺乏与计算机工业配套的先进电子工业。根据塞利格曼(Daniel Seligman)对戈尔巴乔夫时代的苏联计算机工业的评估,当时苏联的计算机的本质是对于6—10年前美国IBM计算机的仿制品,而且在这些产品中,没有一款质量比得上其盟友东德生产的ES-1055 计算机(大约等于美国的IBM-370),此外,即使就计算机设备的产量而言,苏联方面的数据也不太乐观。截至1984年,苏联全国的44,000家工业生产单位中,装备有大型计算机主机的单位才占7.5% 。(5)Daniel Seligman,“The Great Soviet Computer Screw-Up”, Fortune Magazine July 8(1985).而苏联计算机产品在质与量这两方面的劣势,显然又是与基础硬件的生产能力落后密切关联的。以现代计算机的产生密切相关的集成电路工业为例:根据已经解密的美国中央情报局文件《苏联在集成电路生产方面的进展》(1974年撰写,1999年解密(6)Central Intelligence Agency, “Soviet Progress in the Production of Integrated Circuits”, September(1974):ER RP 74—17,https://www.cia.gov/library/readingroom/docs/DOC_0000484024.pdf.)的披露,截至报告撰写时间为止,苏联的集成电路工业的产量竟然不到美国的4% ,而且整个苏联相关工业部门也都受到生产工艺落后、管理水平落后等问题的严重困扰。
第三,苏联缺乏与计算机硬件工业配套的计算机软件研究。按照美国著名智库“哈德逊研究所”(Hudson Institute)所提供的报告《苏联在1980年代的计算机软件及其运用》(7)Richard W. Judy & Robert W. Clough, “Soviet Computer Software and Applications in the 1980s”, January 9(1989):HI-4090-P, https://www.ucis.pitt.edu/nceeer/1989-801-5-2-Judy.pdf.的意见,苏联工业界提供的计算机软件有五大特点:大量复制西方计算机软件,缺乏原创性色彩;一些计算机软件在西方技术内核的基础上具备了俄文界面,仅仅实现了最低限度上的本土化;苏联软件与西方同类产品的平均技术差距是10年左右;苏联软件的发展,亦受制于机器的内存与电话网络线的传输力方面的限制;苏联软件的界面不太友好,没有编程训练的新用户很难上手。总之,与西方同类产业相比,苏联在计算机软件方面的落后程度,与其在计算机硬件方面的落后程度,是相辅相成的。
以上给出的这三点分析,虽然都貌似比较“务实”,但从比较“务虚”的哲学角度看,它们又都有一定的共性。这就是:苏联当局虽然从“大国争霸”的角度对计算机工业的发展给予了一定的重视,却没有在哲学层面上理解计算机工具的实质。概而言之,任何计算机工具的终极目的都是为了提高人类进行信息处理的效率,以便进一步解放人类的生产力,增加劳动者的闲暇时间,以实现马克思所说的“人的充分发展”。这就需要计算机工业与一个更为广泛的“人类用户导向”的文化相互匹配。然而,苏联的经济政策长期压制市场经济的发展,也没有像我国那样创造性地发明出“社会主义市场经济”这样的新的经济运作理念,这就在根本上使得普通人民群众的真实市场需要没有办法得到体现,并以此为契机促进面向民用的计算机产品的开发。而仿造美国民用产品的战略,虽然靠“搭技术顺风车”解决了一部分问题,却也使得俄罗斯民族本身的文化特色无法浸润到相关的仿制产品之中。此外,苏联以国防为导向的工业布局,也使得以“粗笨”为特点的重工业得到了片面发展,却挤压了以“精巧”为特点的新兴电子工业的发展空间,而这一点既直接拖累了民用计算机的发展,又反过来导致苏式武器的电子系统(如战斗机、舰船的雷达导航与火控系统)的技术状态无法从民用计算机的进步中得到“反哺”,由此还导致了苏联军事装备战斗性能的落后。这种情况,迫使苏军一直试图以更大的装备编制来应对北约的质量优势,而由此占据的人力资源与经济资源又进一步挤压了苏联的民用工业资源,最终造成了其经济—技术生态的恶性循环。
苏联在哲学层面上对于计算机工业与宏观经济体系之间的关系的误解,同样也以另外一种形式,体现在对于AI的布局与谋划之中。或说得更清楚一点,因为AI的“面向用户”特征要比广义的计算机工业来得更为明显,苏联时代的AI研究,实际上要比其对一般计算机平台的研究还要落后。有意思的是,“AI”这个词本身,在苏联时代都不是一个“合法”的技术名词。苏联专家要讨论AI研究,就必须借用另外一个名词,即前面所提到过的 “控制论”(cybernetics)。所谓“控制论”,就是对一切可能的机器与生物有机体内部的信息控制方式与交流方式的研究。由于该研究天然具有某种横跨人类智能与机器智能的两栖性,因此,将其当作对AI的某种替代性称呼,则多少也是有点道理的。但为何苏联专家要舍近求远,用“控制论”取代“AI”呢?这就牵涉到一个在特定政治背景中对特定技术名词的“正名”问题。简言之,在当时的环境下,讨论“AI”要比讨论“控制论”更显得具有“政治正确性”,因为“AI”纯然是美国式的概念,而“控制论”则否。
从表面上看,这一判断貌似有点奇怪,因为控制论的建立者并非俄国人,而是美国人维纳(Norbert Wiener,1894—1964),只是他父亲是从波兰移民来的犹太人罢了。其实,由于维纳的国籍问题,苏联当局本来对维纳的理论并不友好。在20世纪50年代的时候,苏联官方便曾组织力量集中批判过维纳的学术观点,甚至给其戴上“资产阶级的反动伪科学”的意识形态帽子。但后来情况慢慢发生了变化。根据本杰明·彼得斯(Benjamin Peters)的历史考证(8)Benjamin Peters,“Betrothal and Betrayal: The Soviet Translation of Norbert Wiener's Early Cybernetics”,International Journal of Communication 2(2008): 66—80.,在1952年,苏联的控制论研究领军人物之一基多夫(他同时也是前文提到的那位苏式互联网的先驱者之一)于苏联的一家涉密图书馆第一次读到了维纳的重要著作《控制论》(9)[美]维纳:《控制论,或关于在动物和机器中控制和通信的科学》,郝季仁译,北京:北京大学出版社,2007年。,并深为其观点所折服(当时此书在苏联境内尚是禁书)。此后基多夫就以“何为控制论?”为题,在苏联内部的多次学术会议上做学术报告,成了俄语世界中维纳理论的头号宣传员。非常具有戏剧性的是,当时一位掌握了不少行政资源的苏联哲学家兼数学家考尔曼(Arnošt Yaromirovich Kolman,1892—1979)也注意到了维纳的理论。他认为马克思、恩格斯利用统计学方法预测资本主义社会运动规律的方法论,在维纳的控制论那里得到了一种新的体现,并以此为理由主张推广控制论的思想。虽然从学术角度看,考尔曼的这种断言的文本根据或许是值得商榷的,但在当时的历史背景下,他的这个政治诊断,依然为苏联学术界大张旗鼓地引入美国人维纳的思想提供了强有力的行政保护。同时,赫鲁晓夫时代相对宽松的政治环境也为苏联专家大胆引用美国科学家的观点提供了可能性。后来,更为重磅级别的人物也开始为控制论摇旗呐喊了,此即获得苏联国防部副部长高位,并被授予海军上将军衔(工程类)的博格(Aksel Ivanovich Berg, 1938—1979)。博格是“全苏联控制论研究理事会”的理事长,而该理事会的活动也使得“控制论”在苏联从被批判的对象,一跃成了挂在贩夫走卒嘴上的学术时髦词汇。至此,在完成了从1954年到1961年的“为政治合法性而斗争”的阶段后,从20世纪60年代到80年代,控制论最终成了苏联境内的“显学”。根据彼得斯的考证,在1962年夏于苏联境内举办的一次主题为“控制论中的哲学问题”的会议上,组委会收到的论文竟有1000篇,提交论文者来自哲学、数学、语言学、生物学、物理学等不同领域(10)Benjamin Peters, “Normalizing Soviet Cybernetics”,Information & Culture 47(2)(2012):145—175.,可见会议声势之壮。
“控制论”的研究虽然在苏联貌似繁荣,但苏联实质上的AI研究水平却依然远远地落在了美国的后面。这又是为何呢?在笔者看来,其根本原因是苏联学者们完全搞错了哲学与工程学的结合方式。马克思、恩格斯无疑都是伟大的哲学家,但是这并不意味着哲学研究的所有工作就是在对象文本与马、恩经典原著之间建立起语义联系,以便为对象文本的政治合法性提供辩护(这种研究方法,可以简称为“贴标签”)。真正的科学技术哲学研究,无疑要对相关技术路径的哲学前提予以系统地发掘,并在一个较高的层面上对相关前提的后果进行提前预报,而这除了学者对相关科学技术的内容有所了解之外,还需要学者熟悉分析哲学的一般论证与写作技巧。但从总体上来说,苏联哲学界对于英美分析哲学的基本方法是陌生的,对与AI相关的英美哲学分支——AI哲学、心灵哲学、逻辑哲学——的内容也是陌生的。换言之,苏联时代虽然吃“哲学饭”的学者人数不少,但具备与西方哲学家进行对话之资质的“高手”却非常稀少。
另外,正如前文所提到的,维纳的思想进入苏联具有很强的偶然性,而一旦他的思想得到了传播许可证明,这反而使得AI发展中的其他思想路数——比如在英美更为正统的纽艾尔(Allen Newell)、司马贺(Herbert Simon)等人所代表的符号AI路线(11)Allen Newell and Herbert Simon, “Computer Science as Empirical Inquiry: Symbols and Search”, Communications of the ACM19(3)(1976):113—126.——就没有机会为苏联科学界所重视。换言之,苏联科学界对于西方学术情报的获取是有严重的“偏食症”的,严重缺乏格局感。
此外,为苏联专家所看重的“控制论”思想本身还是带有很大的拼凑性的。其核心部分——对于控制系统所处理的信息流的量的统计学处理、预测与滤波理论、计算系统的记忆装置设计,等等——要么理论抽象性太强,要么只有在防空火控系统等特殊用途的装置里得到了验证,要么在理论上的猜测之处还比较多,而这些理论之间的联系也不是那么清楚。而控制论的核心哲学理念——系统的稳定性取决于其对于正反馈信息与负反馈信息的平衡性处理能力——则因为可以套用的领域太多,其与AI的核心话题(知识表征、模式识别、自然语言处理,等)之间的关系反而显得有点疏远,实际上无助于苏联制作出特别有用的AI设备。
最后,正如前文已指出的那样,“控制论”可能与苏联现实结合的唯一一个应用点,便是通过OGAS系统来给全国的计划经济体系进行数码化升级。但因为中层政治精英的不配合态度,这一应用并未得到实现。而从哲学角度看,即使苏联侥幸地抓住了这样一个机会,这样的信息管制系统依然与通常意义上的AI无甚关联,因为严格意义上的互联网只是AI运作的某种外部数码环境,而不是AI本身。严格意义上的AI,就其物理实现方式,依然脱离不了基于微型计算机的本地化信息处理方式,而就其虚拟表现形式而言,则依然无法脱离特定的、可与微机的硬件基础相互匹配的软件构架。而正如前文所指出的,无论在微型计算机的设计与制造方面,还是在计算机软件的自主研发方面,苏联都乏善可陈。
二、日本“五代计算机”失败背后的哲学教训
试图以国家力量与美国的计算机产业一比高下的另外一波努力,则来自属于美国阵营的日本。与苏联相比,日本的计算机产业既有明显的不同,也有某些类似之处。其不同之处在于:
(1)由于战后的日本属于美国在亚洲的重要盟友,不受“巴统”的技术禁运影响,因此日本可以与美国进行比较充分的技术交流,充分吸纳美国的最新技术成就。以比较敏感的集成电路产业为例:1969 年,日本日立公司便与美国罗克韦尔公司合作,建设大规模集成电路生产厂,而没有受到来自美方的任何政策阻挠。甚至在80年代中期美日开始贸易摩擦之后,美国也主要是通过扶持中国台湾与韩国的半导体产业来间接制衡日本,而没有对日本加以直接的技术出口限制。得益于此,日本战后的半导体工业亦长期是英语世界之外的龙头老大(譬如,1975年日本半导体产业的产值达 12.8 亿美元,占全球的 21%,成为全球第二大半导体生产国;截至 1990 年,日本半导体企业在全球前 10 名中占据了 6 席,在前 20 名中占据了 12 席。)(12)更多相关历史细节,请参看冯昭奎:《日本半导体产业发展与日美半导体贸易摩擦》,《日本研究》2018年第3期。这就为日本的计算机产业发展奠定了比较坚实的硬件基础。
(2)与曾经连阅读在美国公开出版的《控制论》也要小心谨慎的苏联专家相比,日本的计算机专家不但可以自由阅读各种西方前沿学术资料,而且还有赴美进行学术交流的宝贵机会。譬如,“第五代计算机”计划的领军专家渕一博(Kazuhiro Fuchi,1936—2006)与其得力干将元冈达(Moto-oka Tohru)都有在美国伊利诺斯大学的学习背景,而该团队的另外一员大将古川康一(Koichi Furukara)则在美国加州的斯坦福研究所做过调研。美国的计算机领军人物、1994年图灵奖获得者爱德华·阿尔伯特·费根鲍姆(Edward Albert Feigenbaum,1936—)亦与该团队成员有着密切的学术联系。这种同时期的苏联专家所难以企及的国际人才支撑队伍,则为日本的AI研究提供了强大的人力资源支撑。
但与苏联相比,日本的计算机产业政策也有一些类似之处:
(1)战后日本虽然在政治体制上采用三权分立的西式制度,但是经济产业政策依然有明显的计划经济色彩,并因此带有一种“准苏式特征”。1949年,日本政府成立了一个叫“通商产业省”(简称“通产省”,2001后改名为“经济产业省”)的政府部门,能够对经济与产业制定高层次的监管政策,督导大企业的投资方向。譬如,为了赶超美国的先进技术和推动日本半导体技术的发展,通产省便把六家半导体计算机公司组成了三个配对组(富士通与日立一组、日本电气与东芝一组、三菱电机与冲电气一组),1972 年至1976进行大量财政补贴,并在1976年结合全国相关优质企业成立了巨型卡特尔组织,专攻集成电路的生产(13)冯昭奎:《日本半导体产业发展与日美半导体贸易摩擦》,《日本研究》2018年第3期。,由此大大促进了相关产业的发展。尝到甜头的通产省自然也在第五代计算机计划的规划与立项中,继续发挥这种“政府主导”的作用。需要注意的是,渕一博所在的科研单位——电子技术综合研究所(在英文文献中常被简称为“ICOT”)——就是从属于通产省的,这与美国以私有企业与私立大学作为信息技术原发点的做法构成了鲜明的反差。应当看到,虽然政府主导的产业技术政策在有美国成熟预研成果的技术领域的确能够迅速见效,但此种行政化导向也必然会压制具有创新性的技术思路的形成,并导致行业发展的后劲不足。这一点在“第五代计算机”计划的最终失败中得到了充分的体现。
(2)虽然日本是美国的重要的军事盟友,但是在经济领域却有向美国的领导地位进行“逆袭”的雄心,这一点又类似于苏联在军事领域向美国“叫板”的行为。譬如,20世纪80年代以后,日本在钢铁、汽车制造、电视机制造与半导体生产等诸领域都全面打开了美国市场,为日本获取了大量贸易顺差。第五代计算机计划的实施,部分地是受到了这种“经济民族主义”的鼓励。
(3)与苏联专家在硬件层面上仿造美国IBM-360计算机的思路相平行,日本的计算机专家,在软件编程思路上亦受到美国老师的影响(只是受惠于相对宽松的国际微环境,其追赶美国的脚步要比苏联同行们紧得多了)。从某种意义上说,第五代计算机计划无非就是费根鲍姆的“专家系统”(详后)设计思路的全面拓展。然而,这种过于直接的“拿来主义”,却使得审慎的哲学批判精神与积极的创新精神并没有在相关的研究中发挥其应有的作用。同时,第五代计算机领军人物清一色的工科背景,亦使得身为日本人的他们竟然无法从日本本土哲学(特别是后文所要提到的九鬼周造哲学)的传统精神宝库中获取资源,以便从一个更高的层面来审视自身的研究路线图的哲学缺陷。
那么,到底什么叫“第五代计算机”呢?“第五代计算机”这个名目显然预设了前四代计算机的存在。前四代计算机的分类主要是根据对相关机器的硬件制造技术的分类。第一代计算机的硬件基础是电子管,第二代是晶体管,第三代是集成电路,第四代是大规模集成电路。 “第五代计算机”与前四代的不同,首先并不在于硬件方面的本质不同(实际上其硬件基础无非就是第四代计算机的平行增强版,也就是将单个CPU升级为平行进行信息处理的多套CPU),而在于软件编制与用户体验方面的不同。元冈达与斯通(Harold S. Stone)曾将第五代计算机的设计目标概括为如下四点:
(甲)在硬件的层面上,实现推理、联想与学习的基本机制,并使得它们成为第五代计算机的核心功能。
(乙)为基本的AI软件做好准备,以便充分利用上面提到的这些功能。
(丙)充分地利用模式识别与AI研究的结果,以便制造出一个对人类来说颇为便利的人—机界面。
(丁)构建一个“软件支撑系统”,以解决所谓的“软件危机”,促进软件生产。(14)Tohru Moto-oka and Harold S, “Stone Fifth-Generation Computer Systems: A Japanese Project”, Computer3(2017):6—13.
但任何一个对AI发展的现状稍有了解的读者都应当看出,这个制定于20世纪80年代的研究目标,即使放到今天来看,也显得野心过大了。其问题主要体现于如下方面:
第一,第五代计算机的整个计划都是基于在20世纪70年代相对红火的“符号AI”技术进路的,而没有预先估计到与之完全不同的联接主义进路(即神经元网络技术,也就是今天的深度学习技术的前身)会在80年代异军突起。因此,该计划的制定者根本就没有预想到,其目标列表的(丙)项所提到的“模式识别”任务,其实更适合由联接主义方案所解决,而并不适合由符合AI进路所解决。
第二,第五代计算机的编程所依赖的Prolog语言(这种语言在1972年由法国人考尔麦劳厄(Alain Colmerauer,1941—2017)发明),在本质上是一种在一阶谓词逻辑的框架中进行编程的语言,因此,这种语言不可能不继承一阶谓词逻辑所具有的一些基本局限,譬如缺乏对于模糊性推理的模拟能力。而目标(甲)所提到的类比能力与学习能力,显然就牵涉到了对于模糊性推理的模拟能力(因为“A与B之间的可类比性”与“对于某技能的习得”,本身就预设了“梯度性”概念,而传统一阶谓词逻辑是无法表征该概念的)。这也就是说,第五代计算机的编程所依赖的Prolog语言与相关规划目标之间,是存在着某种天然的不和谐的。这当然不是说,我们无法利用Prolog语言为某种元语言,并在对象语言的层面上进行模糊推理——但至少在第五代计算机计划中,Prolog语言就是作为知识表征语言使用的,因此在这种情况下,它肯定是无法进行模糊推理的。
第三,即使在符号AI的天地里,日本人所依赖的Prolog语言的普及程度,也不如麦卡锡(John McCarthy, 1927—2011)发明的LISP语言,因此,对Prolog语言的选择使得该项目很难达到其任务列表中所提到的目标(丁),即构成一个比较成规模的软件生态环境。而富有讽刺意味的是,甚至日本自己的全日航空公司所采用的第五代计算机计划的衍生产品——用于乘客个人信息查询“个人串行推理机”(Personal Sequential Inference Machine,简称PSI)——也需要将原本运行的Prolog语言分解为LISP语言来执行,更不用提市面上基于LISP语言的PSI对于基于Prolog语言的PSI所具有的至少10倍的商业销售量优势了。(15)Edward Feigenbaum and Howard Shrobe, “The Japanese National Fifth Generation Project: Introduction, Survey and Evaluation”, Future Generation Computer Systems 9(1993): 115.
第四,第五代计算机目标列表的(丙)项所涉及的人—机界面研究,显然会涉及对“自然语言理解”(Natural Language Processing,简称NLP)模块的研究,即让人类用户能够不经任何编程训练,仅仅使用标准的自然语言(对日本人而言当然就是以东京语为基础的标准日本语),就能顺利地给机器下指令,并理解机器的信息输出。而第五代计算机的研究者还给自己的NLP模块研制提出了非常具有野心的技术目标(16)Edward Feigenbaum and Howard Shrobe, “The Japanese National Fifth Generation Project: Introduction, Survey and Evaluation” 9(1993): 107.,即系统包括的词汇量要达到100,000,具有的语法规则当有2000条,句法分析能力的准确度将达到99%,而当多个言谈者用标准日语与标准语速进行谈话时,系统对单个日语单词的辨别准确度将达到95%。这些目标即使对于今天的NLP研究来说,都显得过高了,遑论在20世纪80年代。另外,日语本身的复杂性、暧昧性、一音多义性与语法难解性,也使得日语非常不适合成为NLP研究的“练手语言”。(17)徐英瑾:《“中文屋”若被升级为“日语屋”将如何?——以主流人工智能技术对于身体感受的整合能力为切入点》,《自然辩证法通讯》2018年第1期。
第五,正如前文所提到的那样,第五代计算机规划是美国既有的“专家系统”的一个全面拓展版。所谓“专家系统”,就是“一个以特定方式编制的计算机程序,以使得其能够在专家的知识层面上运作”(18)Edward A. Feigenbaum and Pamela McCorduck, “The Fifth Generation: Artificial Intelligence and Japan's Computer Challenge to the World.Boston”, Addison-Wesley (1983):63—64.,而这里的“专家”,就是指医疗、法律、金融等特点领域内的专家。传统的“专家系统”的研制方法,是先将一个特定知识领域内的知识用逻辑语言加以整编,然后利用逻辑推理规则推演出用户所欲求的特定结论。只要特定领域内的知识的数量是可控的,且相关程序的应用范围是确定的,此类研究方法往往还是能够得出在商业上有用的产品的。但日本的第五代计算机计划的问题是:它将特定领域内的专家系统拓展为了横跨各个领域的超级知识系统,使得研究的面铺得太开,增加了项目失败的风险。同时,全系统缺乏一个类似于人类的注意力机制以及记忆提取机制的高层面“机器心理”模拟层,这就使得系统很难像人类那样,在特定的语境中根据当下得到的语境信息来灵活、快速地调取所记忆的知识。
而尤其令人感到遗憾的是,虽然第五代计算机计划是日本人主导的,但是其背后的运行逻辑基本上是美国既有的符号AI思路的全面升级化,而根本就没有体现日本传统哲学的影响。譬如,该研究方案所运用的Prolog语言所预设的“偶然性排除原则”与“知识完备性假设”,就是与日本京都学派的重要哲学家九鬼周造提出的“偶然性哲学”的基本精神直接抵触的(详后)。换言之,如果渕一博这样的日本工科人才能够花费一点时间了解一下本土的九鬼哲学的基本要点的话,他们就会发现,Prolog语言也好,作为其竞争性语言的LISP语言也罢,其实在根底上就忽略了外部世界的偶然性与人类程序员的无知性对机器本身所执行的知识推理任务所会产生的影响。
下面笔者对支持上述的断言进行展开。从实质上看,Prolog语言实际是逻辑学教材里所提到的“霍恩子句”(Horn clause)的计算机程序版本。对于该子句的一个简单化的说明案例,则来自“拼木桶”的比喻。假设有一个五边形木桶,而字母p、q、r、s、t则代表其侧面的5个拼件、u则代表“木桶的完整”,那么,下面的这个句子就代表了这个意思:如果木桶的5个拼件都到位了,则整个木桶也就完整了。
公式一:(p∧q∧r∧s∧t) →u
其逻辑等价形式则是:
很明显,上述式子的有效性,取决于导出“u”的前提集是否完备,而这一点又取决于两点:从形而上学的角度看,外部世界中只要存在着“(p∧q∧r∧s∧t)”所表征的前提性事件,从中就会必然地导出为“u”所表征的衍生性事件,而不存在着这些前提性事件到位,后续性事件却没有发生的偶然性;从知识论的角度看,人类主体(特别是程序员)是有能力了解到那些使得“u”的发生得以可能的所有的前提性事件到底是什么的。这两点,便是运用霍恩子句的两个哲学前提:“偶然性排除假设”以及“知识完备性假设”。然而,这两个假设本身都在日本哲学家九鬼周造那里得到了严峻的批判。
九鬼周造(Shūzō Kuki, 1888—1941)是日本京都学派的重要代表人物,曾在德国弗莱堡大学与洪堡大学分别跟胡塞尔(Edmund Husserl, 1859—1938)与海德格尔(Martin Heidegger, 1889—1976)学过哲学。由于他在AI诞生元年(1956年)到来前15年就过世了,这就使得粗心的观察者很容易忽略他的思想对于AI的启发意义。将九鬼与AI联系在一起的关键词是“偶然性”,因为上文所提到的“偶然性排除假设”本身就提到了“偶然性”,而九鬼所留下的最重要的哲学著作,也恰恰就提名为《偶然性的问题》(其日文版在1935年首次出版)。顾名思义,这就是一部以“偶然性”概念为核心范畴而展开立论的哲学著作。
简略地说,“偶然性”的概念在九鬼那里分为三个层次,而其中的第一、第二层次都明确挑战了“知识完备性假设”,第三层次则明显挑战了“偶然性排除假设”,下面分别具体考察之。
(1)定言判断(即“S是P”这样的判断)中的偶然性(19)《九鬼周造全集》第2卷,东京:岩波书店,1980年,第19—44页。。在九鬼的文本中,其典型案例是一枚因为变异而长出了四片叶子的三叶草。假设这枚草叫“a”,则像“a是三叶草”这样的一个定言判断便包含了主词“a”与谓词“三叶草”之间的某种冲突:按照“三叶草”的“名义本质”(nominal essence),能够被归类为该谓词的对象应当是全部只有三片叶子的,而在此,却明明发现“a”所指涉的对象既具有四片叶子,又被“三叶草”这词所谓述,而这一点本身就构成了对“三叶草”的“名义本质”的反驳。换言之,像“a是三叶草”这样的定言判断的存在,说明了“三叶草”这个谓词的某些基本特征——如“有三片叶子”——并不是必然地贯穿于能够被该谓词所谓述的所有对象的。换言之,总有一些对象会偶然地不具有上述基本特征。套用“霍恩子句”的话语框架来说,如果字母“p”……“t”表示了一个概念在“名义本质”层面上所具有的所有属性,而“u”代表了该概念本身,那么“公式一”就可以被替换为:
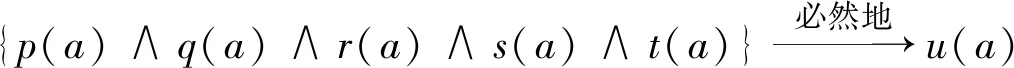
而九鬼的“定言的偶然性”概念则是将上述公式的推出符号“→”上面的模态词“必然地”置换为“偶然地”,由此得到:

但这种替换显然对第五代计算机计划所预设的“知识完备性假设”构成了挑战,因为该假设要求程序员具备针对一个概念的所有下属属性的完备知识,并通过“霍恩子句”来检查某个对象是否完全满足所有的这样的属性列表,由此进一步判断该对象是否属于相关概念。但“公式四”的蕴意是:程序员至多只能获得针对某概念的所有下属属性的非完备知识,而从这个知识集推出“u(a)”的过程就只能是偶然的,因此是可以允许出现例外的。
试图挽救“知识完备性假设”的编程员,显然会通过增加相关概念的属性列表来使得原本不完备的属性知识变得完备化。譬如,针对三叶草的案例,他们会补充说:关于三叶草的外部形态的属性列表,的确不足以解释为何四片叶子的三叶草还依然是三叶草,但只要我们将相关的属性列表替换为关于此类植物的遗传学知识,我们就依然能够维持“公式三”所提到的那种推理必然性。而由于这种遗传学知识往往是以科学假说的形式出现的,所以,由此出现的推理必然性就是所谓的“假言判断中的必然性”。
而九鬼则针锋相对地提出了第二个层次的“偶然性”概念与之对抗:
(2)假言判断(即“若P则Q”这样的判断)中的偶然性。(20)《九鬼周造全集》第2卷,东京:岩波书店,1980年,第45—148页。为何在这个层面上依然会存有偶然性呢?九鬼针对三叶草案例的论辩是:即使某人知道了关于遗传学的所有可靠知识,并因此知道:在怎样的外部条件被满足的情况下,三叶草的遗传基因会发生突变,并由此产生具有四片叶子的三叶草的变种——他还欠读者一个更深入的解释,以说明为何这些使得特定的遗传变异发生的特定外部条件恰好在此时此地的这个时空坐标被满足了。而此类重要的额外知识的缺席,则会继续威胁到“知识完备性假设”自身的安全性。由此看来,即使在假言判断的层面上,偶然性也是难以被消除的。
试图挽救“知识完备性假设”的编程员,显然会通过追溯使得特定条件得以被满足的时空聚合性背后的深层条件,由此进一步完善他们心目中的属性列表。但九鬼的问题是:对于特定的属性进入特定时空坐标这一点的解释,肯定会依赖于对相关对象的历史演化过程的追溯,而这种追溯又难免会逼迫我们进一步去追溯该对象在历史上所承载的那些属性的形成机制,由此导致无穷后退。这种无穷后退除了会在编程作业的层面上导致“组合爆炸”的问题之外,也必然在形而上学层面上预设一个“拉普拉斯妖”(法语“Démon de Laplace”)式的全知者以及该全知者心目中世界图景的纯然必然性。但在九鬼看来,没有任何理由去阻止我们去预设“偶然性排除原则”的反面是正确的,此即“偶然性”的最深层次:
(3)选言判断(即“要么属性P的示例出现在了此时空坐标,要么出现在了彼时空坐标”这样的判断)中的偶然性。(21)《九鬼周造全集》第2卷,东京:岩波书店,1980年,第149—250页。换言之,在九鬼看来,在某个追溯层次上,“属性P的示例出现在了此时空坐标,而非彼时空坐标”这一点干脆就是无法通过必然性的话语方式而得到解释的,因此,我们必须坦然接受在这个层次上所呈现出的偶然性。而九鬼本人的佛教倾向则使得他将此种偶然性进一步与富有佛教色彩的概念“绝对无”相互联系,以便与“必然性”概念颇有渊源的西方基督教传统相互对抗。
佛教文化与基督教文化之间的争执,当然不是一般的计算机编程者所需要关心的。不过,九鬼哲学对于偶然性概念的全面包容,若真能被全面引入AI建模作业的话,将使得编程员从寻找对天下万物之充分、完美之定义的劳苦作业中被解放出来,由此大大减少由此导致的建模成本。由此,我们甚至可以说,九鬼其实已经以他的方式,预报了在“有限知识”的约束条件下,行动主体如何做出“廉价七成正确”的决策的认知科学路线与AI研究路线。但很可惜的是,在他之后的日本第五代计算机研究计划的领军人物,纯然忽视了九鬼的这些哲学洞见,而在早就陈旧不堪的“知识充分性预设”的蛊惑下,陷入了“以有涯追无涯”的思维怪圈。然而,公平地说,即使这些计算机专家能够意识到九鬼哲学的重要性,对于九鬼哲学理念的恰当“落地”过程,也需要在认知科学方面与编程语言方面的大量准备,而第五代计算机区区10年的研究时间无论如何都是不够的。
不过,在本节的最后,为了平衡立论,笔者还是想再说几句赞扬日本当时AI发展策略的好话。抛开哲学考量不谈,考虑到日本人在第五代计算机计划上的投资也不过就是4亿美金(对于日本在80年代如日中天的经济实力而言,这其实只是九牛一毛),很难说该项目的失败造成了多大的财政损失。另外,按照费根鲍姆的讲法,这个项目至少提高了广大日本的计算机工程师的编程水平(22)Edward Feigenbaum and Howard Shrobe, “The Japanese National Fifth Generation Project: Introduction, Survey and Evaluation”,Future Generation Computer Systems 9(1993): 106.,而这一点也能勉强算是该项目的一个成就。与之相比,下面就要提到的欧盟的“蓝脑计划”,不但经济耗费更多,哲学基础更为薄弱,而且在广受学界诟病之后,依然在欧盟的官方保护下,继续低调进行。与之相比,日本通产省至少既不缺乏“壮士断腕”的勇气,亦不缺乏“愿赌服输,适可而止”的佛系心态。
三、欧盟的蓝脑计划评述
从总体上看,欧洲的计算机与AI的产业发展水平是不如美国的,互联网企业的发展与移动支付手段在市场中的普及程度也相对落后。在这种大背景下,除了追加资金之外,欧盟用来对抗美国技术霸权的主要策略是打“隐私保护”牌,以道德化法规,以法规博商利。实施该策略的具体动机如下:
由于目前基于大数据的AI技术的发展,往往有赖于相关技术研发方对于用户数据信息的大量获取与分析,所以,这种AI发展路径对于人类隐私的伤害几乎是不可避免的。而这就使得对于大数据技术的立法限制,具有了某种天然的道德优势。欧盟对于这种优势的利用,在客观上也能够为美国互联网企业在欧盟地区的拓展制造一些障碍,以便为欧盟本土企业的生存腾挪出空间。同时,由于为这种立法行为提供支撑的近代西方启蒙主义价值观也为美国所分享,故此,该策略的运用,既可以大大压缩美国企业在道德领域的辩护空间,也可以管控欧美商业—技术纠纷的层级。基于这种观察,2018年5月25日,欧盟出台了《通用数据保护条例》(General Data Protection Regulation,简称GDPR)(23)European Parliament, “General Data Protection Regulation”, https://gdpr-info.eu/, 2018.,强调数据提供方的知情权,并明文规定了用户的“被遗忘权”,即用户个人可以要求责任方删除关于自己的数据记录。据此法规,2019年1月22日,美国的谷歌公司被法国隐私监管机构(CNIL)处以5000万欧元(约合5700万美元)的巨额罚款,原因是谷歌未能依据“GDPR”规定向用户正确披露该公司是如何通过其搜索引擎、谷歌地图和YouTube等服务收集用户的隐私数据的。在GDPR的基础上,2020年2月19日,欧盟委员会又于布鲁塞尔发布了内容更为全面的《人工智能白皮书》。(24)European Commission, “White Book on Artificial Intelligence: A European Approach to Excellence and Trust”, https://ec.europa.eu/info/sites/info/files/commission-white-paper-artificial-intelligence-feb2020_en.pdf, 2020.针对人脸识别技术,该白皮书特别强调,欧盟数据保护规则原则上禁止以识别特定自然人为目的处理生物数据(如人脸信息),特殊条件除外。同时,该《白皮书》也特别强调了“可信赖的人工智能框架”,以夯实2018年12月18日欧盟委员会已经公布的《可信赖的人工智能道德准则草案》(25)European Commission, “High-Level Expert Group on Artificial Intelligence: Ethics Guidelines for Trustworthy AI”,https://ai.bsa.org/wp-content/uploads/2019/09/AIHLEG_EthicsGuidelinesforTrustworthyAI-ENpdf.pdf, 2018.所给出的文件精神,即AI研发必须以人为中心,尊重人类的尊严、平等和自由等基本权利,等等。
从价值观的角度上看,欧盟的AI发展规划背后的道德原则当然是值得肯定的。然而,从哲学角度看,一种过于强调“应然”的技术规范指导原则,也必须要有特定的技术手段加以支撑。以航空工业为例:在机舱增压技术发明之前,让“客机的旅客感到旅行舒适”的规范性要求便是难以落地的,因此,在缺乏相应技术保障的前提下,一种对于此类规范的文牍式强调,也会变成纯粹的观念性游戏。同样的道理,除非欧盟能够提出与大数据技术以及深度技术相对抗的新的AI发展路径,以便在技术层面上,而不仅仅是在文件层面上规避对于用户隐私的大范围榨取。否则,除了以消极的方式对美国的互联网巨头进行罚款之外,就很难看到这样的法规政策能够以怎样的积极方式促进AI的发展。然而,在上述《白皮书》的文本中,欧盟对于AI发展的正面扶持政策,主要也只是体现于AI与欧洲相对强大的领域(机械,运输,网络安全,农业,绿色与循环经济,医疗保健以及时尚和旅游业)的结合之上,而且此类的扶持政策缺乏进一步具体的技术路线图加以支撑的。所以,很难说欧盟的AI发展策略是具有真正的可持续的。
不过,这并不是说在一个更小的尺度上,欧盟没有提出过一个与AI相关且的确主要由欧盟的资金加以支持的技术发展路线。实际上,所谓的“蓝脑计划”,便是这样的一个技术发展路线。但是,支撑该计划的哲学理念却是混乱的,甚至也没有体现出欧盟所提倡的“可信赖的人工智能”理念所应当具有的任何特征。而这一点也就从一定程度上映照出了“可信赖的人工智能”这一概念自身的空洞性。
那么,什么叫“蓝脑计划”呢?说得直白一点,该计划的核心思想就是在一台叫“蓝基因”(Blue Gene)的超级计算机上,构建一个数码虚拟脑,以便整合神经科学学界既有的对于大脑的数据,最终完成此类知识的“大一统”。该计划的主持人是洛桑联邦理工学院的神经科学家马克拉姆(Henry John Markram, 1962—),研究的资助在相当程度上来自欧盟委员会(后者在2013年给予该项目10亿欧元资助)。由于该计划兼跨神经科学、医药学与AI,所以,支持该计划的学术野心其实还要大于日本第五代计算机计划的。但由于该计划在方案设计时存在一些难以修补的结构性漏洞,所以,目前的进展并不顺利,相当多的业界人士认为它已经失败。创刊于1857年的美国老字号杂志《大西洋》就在2019年7月22日刊登了一篇题目为《人脑计划并未履行其诺言》的文章(26)Ed Yong, “The Human Brain Project Hasn't Lived Up to Its Promise”, The Atlantic JULY 22(2019), https://www.theatlantic.com/science/archive/2019/07/ten-years-human-brain-project-simulation-markram-ted-talk/594493/.,该文是这么讥讽该项目的:
马克拉姆的目标,并非是建立一个简化版本的大脑,而是一个极为复杂的大脑摹本:这个摹本的细节会一直落实到其构成的神经元之上,落实于神经元之间的电传导,甚至是落实于在神经元内部的那些起到开关作用的基因机制。从该计划一创立开始,对于该路径的批评就不绝于耳,譬如,这种路径的自下而上(bottom-up)策略就由其荒谬性而显得很不靠谱。对于大脑的种种堂奥——比如神经元是如何彼此联接与合作的,记忆是如何构成的,决策是如何完成的——我们所知的,要远少于我们所未知的,因此,在区区十年内将这些细节全部吃透,在时间上肯定是远远不够的。其实,仅仅将不起眼的秀丽隐杆线虫(一种约1毫米长的雌雄同体的小线虫——引者注)的区区302个神经元加以图像化并建模,就已经足够难了,更不用提对我们的颅腔内的860亿个神经元进行建模了。“大家都认为这计划太不实际了,以至于都不认为这是个值得追求的目标”——正在撰写一本关于为大脑建模的著作的神经科学家林德赛(Grace Lindsay)如是说。
如果说“目标太大,进展太小”是学界对于蓝脑计划的最普遍批评的话,那么,这样的科研规划又是如何通过欧盟委员会的评估的呢?这就牵涉到了一切官僚主导的科研计划所具有的某种通病(而这一通病也体现在日本的第五代计算机计划中),这就是:越是显得野心勃勃的科研计划,就越是容易激发不太懂科研的行政当局的虚荣心,并得到预算方面的支持——而为蓝脑计划大开绿灯的欧盟委员会(European Commission)亦不能免俗。从表面上看,与隶属于主权国家的日本通产省不同,欧盟委员会所为之服务的欧洲联盟是国家联盟,而非单个主权国家,因此,该组织的预算审批能力貌似应当是有限的。但实际上,欧盟委员会的实际权力却要大于其名号所暗示的样子。如果将欧盟看成是一个准国家的话,那么,欧盟委员会、欧盟议会与欧洲法院就构成了一个超国家层面上的“行政—立法—司法”三位一体机构,而且欧盟委员会在三者之中权重竟然还是最大的(作为欧盟条约监护人,欧盟委员会负责监督各欧盟成员国对欧盟法律的履行,而且在必要之时可以在欧洲法院对欧盟成员国提起控告)。欧盟委员会的此种强势地位当然也使得其获得了强大的预算(包括科研预算)分配力。根据欧盟官网的信息(27)European Union, “How the EU Budget is Spent”, https://europa.eu/european-union/about-eu/eu-budget/expenditure_en, 2020.,在所有的欧盟预算中,欧盟委员会在“预算方案制定”与“预算实际分配”两个关键环节中获得了主导权(尽管预算方案的批准权依然在欧洲议会)——由此不难推出,任何科研项目只要得到了该委员会的行政当局的认可,就可以在预算方面得到优厚的支持。而蓝脑计划就是这样的一项科研计划。根据生物学家施耐德(Leonid Schneider)的观察,为了使蓝脑计划的预算资金能够年年到位,上层主管当局似乎与项目负责人构成了某种合谋:在2013—2015年的年度科研进展评估中,评估团的专家名单都是向社会公开的,而2016年的评估团成员名单却转为了“不公开”,且他们所撰写的明显带有“放水”性质的评估报告本身,(28)European Commission,“Human Brain Project: Review and Highlights of Scientific and Technical Achievements”, https://drive.google.com/file/d/0By2HqPi4t2RbWGFZNGlfZGM2TXM/view?usp=drive_open September 2016.也沦落到了“数数发了几篇文章”这样的外行水准。为此,施耐德讥讽道:
现在诸位应当明白了,人脑模拟计划,与其说是一个货真价实的科研计划,还不如说是一个科研资金的崇拜者所构成的偶像崇拜团体。理解了这一点,诸位也明白为何该计划的成就不可能以科学的方式来加以评估了。无论该团队做得好还是不好,其成就都会得到正面的评价,因为当欧盟选择了像马奎特(Wolfgang Marquardt)这样的人做项目中介人,而不是诚实地承认错误、解散项目组并重新分配资金的时候,欧盟已经预设了该计划肯定会成功(马奎特是“余利希研究中心(Forschungszentrum Jülich GmbH (FZJ))的主席。按照施耐德的描述,他属于代表德国方面参与蓝脑计划的利益协调人——引者注)。(29)Leonid Schneider,“ Human Brain Project: Bureaucratic Success Despite Scientific?Failure”, https://forbetterscience.com/2017/02/22/human-brain-project-bureaucratic-success-despite-scientific-failure/, 2017.
看得更深一点,施耐德对于蓝脑计划与特定长官意志之间的合谋机制的诟病,亦揭露了相关项目立项过程中哲学批判精神的缺失。毋宁说,哲学批判精神本身就代表了行政主导的科研立项活动的反面:其一,行政官僚往往以5年、10年为政绩考核的最大时间段,因此非常容易犯下“好大喜功”的毛病,而不顾科研方案的实际可操作性;与之相比,哲学思辨往往争论继续几百年(甚至上千年)都没有结果,这就使得哲学家对于项目的失败抱有更大的平常心;其二,现代科学研究往往经费消耗巨大,这就使得项目的失败会导致巨大的追责压力,而这种压力也反过来驱使研究者与行政管理当局合谋,夸大科研效果;而经费消耗较少的哲学研究则没有如此明显的造假冲动;其三,更重要的是,与科学争鸣相比,哲学讨论往往更倾向于对一个理论得以成立的观念前提进行深挖,这就使得哲学讨论在根底上就比科学研究更具颠覆性,而非建设性。当然,这种颠覆性的批判精神,若不加制衡,也会对人类学术的整体发展产生不利影响——但对于这种精神特质的适当运用,至少能够在项目立项的纸面推演阶段起到“谬误清道夫”的作用,以避免一些劳民伤财的研究计划去占据那些更有希望成功的研究计划的有限预算。
而从哲学角度看,蓝脑计划的核心问题,就是它在哲学上预设了两个彼此矛盾的哲学前提:第一个是“生物学还原主义”(biological reductionalism),第二个是“功能主义”(functionalism)——而这两者之间的冲撞,本该是能够通过“谬误清道夫”的工作而在观念层面上就被发现的。
那么,什么叫生物学还原主义呢?这是说,人脑的高层次心理机能,在原则上都可以被还原为与之相关的底层生物学事件。基于这种观察,对于人类智能的研究,也必须奠基于对于实现智能的基本物质条件——大脑的微观活动——的研究。而这一推论与AI之间的关系则在于:有鉴于人类智能是我们已知的唯一的高级智能形式,所以,对于AI的研究,也必须植根于对于人脑的研究。故此,在蓝脑计划的支持者看来,对于大脑的数码建模是AI研究的不二法门。
但仔细的读者恐怕不难发现,上面的论证包含了一个跳跃,即对于生物学还原主义的彻底遵从并不会立即导致对于数码大脑建模规划的支持。这是因为,无论对于大脑的数码建模会精细到如何之地步,其物理实现方式依然是“硅基”的,而非“碳基”的,而二者之间的差距之大,足以让一个生物学还原主义的忠诚信仰者去怀疑:对于大脑的数码建模到底会在多大程度上实现智能。而要弥补这个理论漏洞的唯一办法就是引入一种叫“功能主义”的哲学立场,即认定某种高层次的生物机能具有认知论上的不可还原性与“多重可实现性”(multiple realizablity)——譬如说,通过对于大脑的数码建模而发现的关于大脑运作的某种抽象机能,既能实现于硅基物理载体(如计算机),又能实现于碳基物理载体(如人脑)。这样一来,对于大脑的神经科学研究对于AI的启发意义,也就变得可以说通了。
但为何说上述这种功能主义立场,就一定会与生物学还原主义的立场产生冲突了呢?这是因为,功能主义的最激进版本,本来就是与最激进版本的生物学还原主义彼此不相容的,而人为地使得二者彼此相容,对于二者的“祛激进化处理”又难免给人留下“特设化处理”(ad hoc treatment)的口实,难以获取普遍化的理论说服力。具体而言,激进的生物学还原主义者完全可以从如下角度攻击蓝脑计划:该计划为何那么执着于对于哺乳动物(特别是老鼠)的大脑的神经元之间的突触联接状况的数码重建呢?难道这就是生物学应当关注的全部吗?为何不去研究诸如肾上腺皮质激素、下丘脑激素、多巴胺等化学物质的分泌对于智能系统的运作的影响呢?还有,数量是神经元10倍之多的胶质细胞的运作状态,为何被遗忘了呢?很显然,如果蓝脑计划的研究路线图完全按照激进生物学还原主义的要求去做的话,其研究领域涉及的面之大,将完全使得项目本身变得不可被操作。而激进的功能主义则完全可能从另外一个角度攻击蓝脑计划:为何我们要执着于在神经元突触联接的层次上进行大脑建模呢?为何我们不能在高于神经生物学的心理层次从事这种建模工作呢?具体而言,对于人类的语言机能、推理机能的研究,若被还原到神经科学的层面上,难免会陷入“只见树木、不见森林”的尴尬境地,而难以为AI的研究提供清晰可辨的指导意见——而如若我们将研究的层次一下子拉到心理学的高层面上的话,那么,心理学理论自身的简洁性,难道不能以更直接的方式对AI产生更为直接的帮助吗?需要注意的是,心理学研究路径的这些支持者未必会在观念上彻底排斥神经科学的研究。譬如,他们完全可以利用神经科学证据去评判哪些既有的心理学理论更能得到神经科学的支持——但即使如此,基于“多重可实现性”概念,那些得到神经科学支持的心理学理论也依然会保持自身的抽象性,而不用被重新还原到神经科学的微观描述方式中去。而这种独立性又进一步使得AI研究能够直接从心理学那里获得指导,而不是非常曲折地从关于相关心理建构的神经学建模出发获得灵感。
那么,面对激进的生物学还原主义与激进的心理功能主义的两面夹击,蓝脑计划的支持者为何还如此执着于对于神经元突触模型的研究呢?答案就只能建立在他们对于一个关键词的膜拜之上,此即:“电”。我们知道,主流的计算机设备当然是由电能驱动的,而生物组织也会在自身的活动中发生各种电位变化,由此释放生物电。由此,电,就成了将生物脑与计算机进行联系的某种神秘通道——而在神经科学的范畴中,最典型的脑电承载单位便是神经元(包括其突触、轴突,以及其细胞膜表面的诸多离子通道)。恐怕也正是基于这种观察,马克拉姆的团队才特别执着于对于神经元的数字建模。他于2015年在《细胞》杂志上正式发表的一篇论文,对幼鼠体感皮层中相当于一个功能柱组织的一块1/3 mm3 大小的组织进行了建模,该模型据说能够准确预测生物电是如何在真正的神经元组织中产生的。(30)Henry John Markram et al, “Reconstruction and Simulation of Neocortical Microcircuitry”, Cell 163(2015): 456—492.而这项研究,也成了目前蓝脑计划在科研领域内的最大斩获之一。
然而,从哲学功能主义的角度看,对于生物大脑而言,电的产生只是一系列复杂生物化学反应所导致的外围性现象,而这些复杂的生化反应在功能上却未必就只与脑电的产生相关。譬如,乙酰胆碱在突触之间的合成固然能够促进神经电的释放,但此类化学物质也能扮演别的(甚至完全相反的)功能角色,如在心脏组织中的乙酰胆碱就具有抑制神经传递的效果。而与之做比较,作为现代计算机的硬件基础的集成电路,其构成却与之完全不同。毋宁说,从本质上看,集成电路就是采用一定的工艺,把一个电路中所需的晶体管、电阻、电容和电感等元件及布线集成在一起的小型功能组件,因此,其所有构成部分本身都是在功能的意义上“为电而生”的。换言之,既然电流的存在之于集成电路的功能性意义,不同于其之于神经元功能柱之功能性意义,那么,不少神经科学家对于生物电现象的强调本身,可能就是建立在对于偶然现象与本质性现象的哲学混淆之上的。而这些混淆,本该是能够通过耗费较少的哲学活动就加以澄清的。
四、总结性评论
至此,本文已经对苏、日、欧三方各自的计算机产业与AI发展规划中的错误,作出了哲学层面上的检讨。现在我们就从更高的层面上,对由此得到的教训进行提炼。
教训一:计算机产业的发展与AI的研究,需要相对宽松的国际环境,以便在国与国之间进行基本的产业与技术交流。而考虑到美国在相关产业的领先地位,相对宽容的国际关系几乎略等于当事国与美国的关系。很明显,在本文提到的苏、日、欧三方中,与美国外交关系最紧张的就是苏联,而受到美国技术禁运最严厉的也是苏联,最后,信息技术发展最落后的依然还是苏联。这一点无疑是耐人寻味的。
教训二:AI研究的最终指向不明确,风险极大,10年的研究规划只能完成阶段性项目,而无法毕其功于一役。但无论是日本的第五代计算机计划还是欧洲的蓝脑计划,都以10年为期,如此逼仄的时间预算当然会在根本上威胁到项目最后的执行度。后来者当引以为戒。
教训三:AI研究的投资方,无非是公司、国家与大学三方(不过,在国立大学占据主导地位的国家,大学的投资也主要来自国家)。而在本文中提到的苏、日、欧的研究规划,都有明显的国家行政导向倾向,这就使得相关项目很难摆脱行政虚荣心的羁绊,而导致规划目标的片面拔高。与之相比,美国的AI研究的主力投资方乃是私人公司与私立大学,这就使得来自资本方的考量能够部分克服上述行政虚荣心。不过,基于资本增值目的的科研投资也可能会带来过于急功近利的立项取向,因此,在政界督导、资本吸纳与学术创新之间达成某种平衡,才是促成AI健康发展的中庸之道。
教训四: 哲学批判精神都没有在苏、日、欧的相关科研计划中发挥重要的作用,这就使得一些大而化之的研究规划没有在“概念论证”的阶段受到足够认真的检视,而这种缺憾,又是与人文学科在整个科研预算分配游戏中的边缘化地位密切相关的。具体而言,在苏联,这种边缘化地位主要是缘于独立于行政意图的纯粹哲学研究自身的不成熟;在日本,这种边缘化地位缘于日本战后的思想界对于以九鬼哲学为代表的日本本土哲学的系统性遗忘;而即使在哲学的社会地位相对较高的欧盟地区,哲学自身的批判性,亦在“跨学科研究”的名目下,被预算争夺游戏与行政虚荣心的合谋所牺牲。这当然不是说“跨学科研究”是不值得追求的,而是说,跨学科研究的必要性,并不意味着“所有的特定跨学科研究方案都是好方案”。毋宁说,在行政虚荣心与预算获取冲动的支配下,在当下的学术游戏中容易得到青睐的跨学科研究方案,与其说是因为其在概念论证的层面上真正具有前景,还不如说是因为其所联合的学科各自具有强大的话语权,并因此很容易通过“强强联手”而在预算分配游戏中构成“马太效应”。以蓝脑计划为例:既然神经科学与AI都是具有强大的既有话语权的学科,蓝脑计划对于二者的形式上统合就会使得项目本身获得很强的行政说服力。而与之相比,那些从哲学角度看,对于AI研究可能更为重要的学科——如心理学、语言学——却因为自身学术话语权的边缘化,而在AI研究的预算分配游戏中被排斥。对于AI事业的健康发展来说,这绝对不是一件好事。
中国未来的AI事业发展,也当充分吸取以上四点教训。应当看到,在改革开放以后的很长一段时间内,我国通过系统引入西方的科技技术,一直处在远比苏联有利的信息科学发展生态位上。但最近几年发生的中美贸易与科技纠纷,则在高端芯片生产方面与国际人才的流动方面,对我国的AI事业的发展构成了制约。同时,我国目下的AI发展的基本策略,就是利用中国庞大的互联网用户所产生的数据红利,拓展缘起于美国的深度学习技术的应用范围,这就使得相关技术的发展更容易受到美国来自技术供应端、知识产权端与政策制约端的三重打压。而要从这种死局中找到活路,创新性的哲学思维就显得十分重要。譬如,如果我们能够开拓出一种基于小数据的(而非大数据的)、并由此在原则上就不需要大量获取用户个人信息的新AI发展思路,就完全可能由此规避美国目前针对我国的大多数政策限制。但非常令人遗憾的是,对于这条思路所具有的战略意义,在国内的学术界与科技政策界中还没有得到普遍的共识。(31)对于该思路的全面阐述,请参见徐英瑾:《心智、语言和机器——维特根斯坦哲学与人工智能科学的对话》,北京:人民出版社,2013年。
致谢:美国圣路易斯大学哲学系的博士候选人赵海丞为本文的撰写提供了部分资料。美国天普大学计算机系的王培副教授阅读了本文的初稿,并提出了批评意见。特此致谢。
