基于知识图谱的抑郁症自动问答系统研究
2020-09-11田迎单娅辉王时绘
田迎,单娅辉,王时绘
(1. 湖北大学计算机与信息工程学院, 湖北 武汉 430062;2.湖北省教育信息化工程技术研究中心, 湖北 武汉 430062; 3.绩效评价信息管理研究中心(湖北大学), 湖北 武汉 430062)
0 引言
抑郁症(depression),也称抑郁障碍(depressive disorder),是指由各种原因引起,同时以显著且持久的心境低落为主要特征的一类心境障碍,持续时间一般超过两周,对患者的社会功能有着显著的影响,是严重危害人类精神和身体健康的重大疾病.据2017年世界卫生组织调查显示,我国的抑郁症患者高达4.2%.对于抑郁症患者来说,对抑郁症知识的认知非常重要.尽早的诊断和治疗可以降低病死率和复发率,亦能减轻患者自身的认知损害.
目前,临床上对抑郁症的识别诊断主要基于 ICD-10 或 DSM-V 中抑郁症诊断标准,同时结合医生对患者的访谈情况、量表情况和医生的个人经验进行[1].显然,这种方式适用于医生和患者一对一的检测,而且需要花费医生大量的时间.同时,这种方法也会受到一些主观因素的影响,比如患者的配合程度、医生的专业程度和患者对医生的信任程度等,这些因素都有可能导致诊断不准确.而且,很多患者缺乏对自身的疾病认知和就医意识,容易耽误病情,导致在就诊时患者很可能就已经达到了重度抑郁.所以在早期发现抑郁倾向和轻度抑郁症有助于及时进行干预,可避免抑郁症进一步加重.近年来,因为医疗资源的紧张和分布不均衡,很多在线求医问药的系统被开发出来,用户可以在线上选择自己想要咨询的医生,获取疾病的诊疗信息也变得方便起来.但是这种方式需要大量医生入驻线上平台并上线才能解答问题.针对上述问题,本研究构建基于抑郁症知识图谱的中文自动问答系统,该系统可以回答关于抑郁症的药物等信息,为病患提供抑郁症疾病自助查询.该系统增强了问答的时效性,不用等医生上线就能实时解答患者的问题,可以加强患者对自身病情的了解,同时可在一定程度上缓解医疗机构的压力.
1 知识图谱概念
1.1 基本定义知识图谱的概念是由Google于2012年5月提出,其初衷是为了提高搜索引擎的搜索能力和结果,并且改善用户的搜索体验. 知识图谱的结构跟图是一样的,都是由节点和边组成的,图中的节点对应知识图谱中的实体,边表示实体与实体之间的关系.知识图谱具有强大的描述能力,主要用来描述客观世界存在的各种实体、概念以及实体概念之间的关系[2].与传统的Web页面网络的区别在于,知识图谱中的节点由不同类型的实体代替了原来的网页形式,而图中的边也由实体间丰富的语义关系代替了原来的连接网页的超链接.
1.2 研究现状知识图谱分为通用知识图谱和领域知识图谱,近几年,专家们在两种知识图谱上都有很多的研究.已经存在的大规模通用知识图谱有Google Knowledge Graph和YAGO等. 通用域知识图谱领覆盖面全而广,因此更多强调的是实体,很难统一管理完整的全局本体层[3],使用者一般是普通用户.领域知识图谱是面向特定的行业和领域的,数据更多的是半结构化和非结构化的,常见的领域知识图谱有Open PHACTS、MusicBrainz、豆瓣等.现如今,也有越来越多的研究者开始构建中文知识图谱,且内容越来越丰富,如OpenKG.CN平台上有很多优秀的开放知识图谱.由于和人的健康息息相关,医学领域的知识图谱也被更多地开发出来.
1.3 医学知识图谱应用知识图谱的应用非常广泛,也发挥着越来越重要的作用.医疗信息系统有大量的、结构不一和动态的数据,知识图谱是一种组织和管理这些数据的高效方式.知识图谱使得医疗信息系统更加接近于人的思维和认知模式[4]. 目前知识图谱在医学上主要用于临床治疗决策支持、医疗智能语义搜索和医疗问答系统[5]等. 临床治疗决策支持是根据患者的个人情况,结合医疗领域的大数据分析,自动生成针对每个患者的治疗方案,提供给医生进行参考;医疗智能语义搜索是从医学知识图谱中联合相关的实体、关系和属性等信息来查询,从而优化医疗信息的搜索结果;医疗问答是医疗信息检索的另外一种形式,它的返回答案是自然语言形式的,专业性更强.本研究主要实现基于抑郁症知识图谱的问答系统.
2 抑郁症知识图谱构建
2.1 文献摘要数据获取中国知网作为学术资源整合型、具有国际领先水平的资源检索数据库,包含的抑郁症学术论文和资源丰富.通过关键字“抑郁症”在知网进行搜索,可以获得大量文献信息,本研究需要捕获的是抑郁症相关的摘要信息.使用Web 爬虫和WebKit浏览器引擎PhantomJS,可以获取知网上大量抑郁症相关的论文文章标题以及摘要数据[6].本研究一共爬取了1 898篇抑郁症相关的摘要信息,将所有摘要数据放置在一个文件中,方便后续的操作.
2.2 抑郁症知识抽取知识抽取,即从不同来源、不同结构的数据中进行知识提取,分为命名实体识别和关系抽取.实体抽取是从文本数据中识别和提取出命名实体,如药物名称和症状.关系抽取是提取出命名实体之间的关系.从文本中抽取三元组一般有两种方法:一种是先进行命名实体识别再进行关系抽取;另一种是同时进行实体和关系的抽取.因为本研究数据中的摘要主要是围绕一个疾病实体展开的,所以只需要抽取出另外一个实体以及两个实体之间的关系R.
本研究将实体一共分为7大类,分别为疾病、药物治疗、症状、诊断、非药物治疗、流行病学和其他.实体之间的关系包括疾病-诊断、疾病-药物治疗、疾病-症状、疾病-非药物治疗、疾病-流行病学、疾病-其他共6个关系类型.具体关系类型如表1所示.

表1 实体间常见关系类型
本研究中的三元组是通过人工标注和自动提取相结合的方式来提取的. 标注方式使用的是“关系名+BIOES”,其中“R-B”标记该实体的开始字符,“R-I”标记该实体的中间字符,“R-O”标记无关字符,“R-E”标记该实体的结尾字符,“R-S”标记单个字符.如图1所示,在训练数据时,首先是人工按照“关系名+BIOES”的标注方法将训练集中的数据进行标注,然后将其送入模型进行学习.测试数据时,首先用BiLSTM+softmax模型来预测出每个字的标签,然后对标签进行匹配,最后形成一个(实体,关系,实体)的三元组.本研究使用这种方法从论文摘要中获得了386个实体和472条关系.

图1 抑郁症知识图谱构建过程
2.3 知识表示知识图谱中用三元组来描述事实,表示为(e1,r,e2),其中e1表示实体1,e2表示实体2,r表示实体1和实体2之间的关系.对于每一个实体,选择以该实体为主语的三元组进行显示. 知识图谱是由多个实体以及实体之间的关系组成的,每个实体都有一个ID来标识,这个ID是全局唯一且确定的,每个关系则连接两个实体.
2.4 知识存储在知识图谱中,通常有两种存储方式,分别为资源描述框架(resource description framework,RDF) 数据库和图数据库 (graph database).
图数据库是根据“图”这种结构来存储和查询数据.它的数据模型主要体现在实体(节点)和关系(边)上,同时,对于键值对,也是可以处理的,因此这样的存储方式有利于处理复杂的关系问题.本研究使用开源图数据库Neo4j来进行抑郁症知识图谱的存储,因为其具有强大的图形搜索能力和一定的横向扩展能力. Cypher是Neo4j提供的声明式查询语言,用它可以完成任意图谱里面的查询过滤,是相对简单的查询语法,而且功能强大.与此同时,对于规模较大的数据,Neo4j里的neo4j-import工具[7],可以处理千万以上nodes的数据,而且处理速度非常快.本研究将关于抑郁症摘要中抽取的抑郁症相关的三元组通过Cypher语句和neo4j-import工具导入到neo4j数据库中.图2展示了抑郁症知识图谱的部分关系三元组.
3 基于抑郁症知识图谱的问答系统
3.1 问答系统概念问答系统是知识图谱应用的一个重要组成部分. 问答系统是指用户以自然语言的形式向系统输入问题,系统通过分析和理解这些问题之后,从知识图谱中找到相对应的结果,最后形成答案,以自然语言的形式返回给用户.问答系统相比于传统的搜索引擎,针对性更强、准确率更高,用户也更容易接受. 近年来,国内在医疗问答系统上有不少的研究,如颜昕[8]构建的社区健康问答系统使用的是自然语言处理技术和机器学习算法相结合,姚智[9]开发的医疗问答系统使用的是深度学习技术,并且该系统已经上线使用,得到了较好的用户评价.
在医疗问答系统中,使用知识图谱的优势在于:1)语义理解智能化程度高:在知识图谱中,所有实体都用具有语义信息的边相关联,在匹配问题和知识图谱中知识点的过程中,这些关联信息有助于语义理解智能化;2)回答问题的准确率高:知识图谱中的知识是经过人工标注或者格式化抓取的,数据的准确性有一定保证;3)检索效率高:知识图谱的结构化组织形式,为计算机的快速知识检索提供了格式支持,计算机可以利用结构化语言(如 SQL、SPARQL 等)进行精确知识定位.本研究设计并实现了基于抑郁症知识图谱的中文问答系统,用户可以通过该系统实现实时的线上求医问诊,更加方便快捷地获取想要的信息.
3.2 问答系统实现问答系统主要包括以下几个模块:输入问题的预处理、医学实体识别、问题模板匹配、基于Neo4j数据库的查询和生成答案.系统整体设计思路如图3所示.
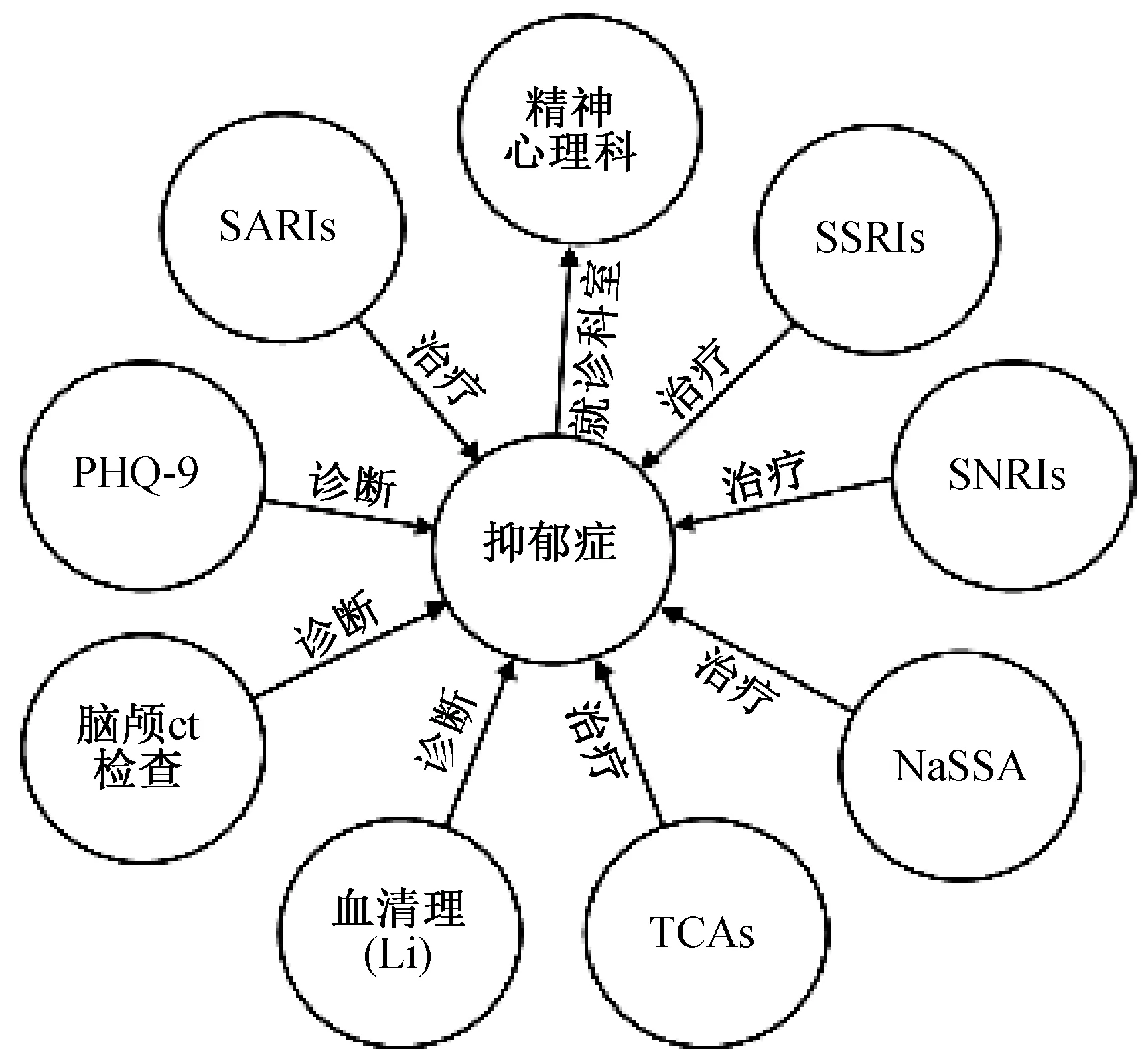
图2 抑郁症知识图谱中的部分关系三元组
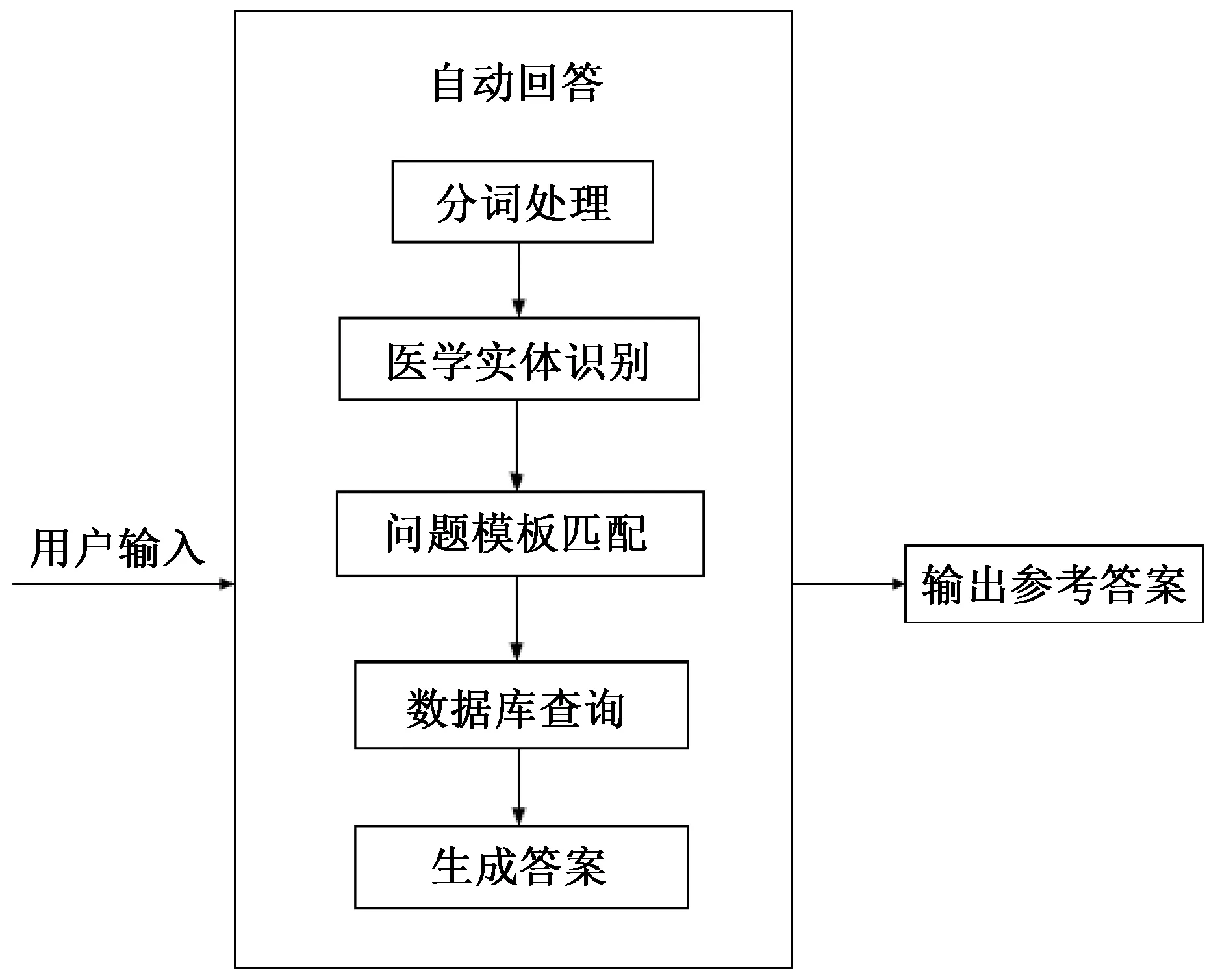
图3 问答系统整体设计思路
3.2.1 输入问题 用户自己输入关于抑郁症症状和药物等想要查询的问题,如“哪个药物可以治疗抑郁症?”“抑郁症的主要症状有哪些?”等等.
3.2.2 输入问题的预处理 输入问题的预处理即需要将中文进行分词,中文分词是将一句话分解成一个个有意义且符合原句逻辑和意思的词语[10].英文语句之所以不需要分词是因为英文中的每个词与下一个词都有空格,而空格是单词之间的一个明显标记.中文句子的词与词之间是没有空格等标记的,又因为机器不能像人一样通过自己的理解来分辨句子中的字词以及一些常见说法,所以需要将句子进行分词处理.
3.2.3 医学实体识别 医学实体识别非结构化文本中抽取医药和疾病等实体,并对实体出现的位置和类别进行标记.医疗领域的实体通常构词复杂、书写形式多样,并且常有多种指称,识别难度相对较大,有可能出现识别出的实体与真实实体不一样的情况.为解决这些问题,本研究使用BiLSTM+ CRF[11]模型,该模型可以识别复杂的药物名称,并且在各个医药数据集上均取得了不错的识别效果.
3.2.4 问题模板匹配 用户输入的问题需要让计算机分解成各实体之间的关系,如疾病和药物之间的关系,这一模块就是实现问题理解的功能.对于问题理解,本研究使用的技术是基于模板匹配[12]的方法,即根据常见的问题人工设计问题模板,当接收到用户输入的问题后,将问题和模板用相似度匹配算法进行计算,相似度最大的就是对应该问题的模板.这种方法适用于领域内的问答系统,不需要用大量数据来学习和训练,易于实现,且后期可扩展性大.不同实体的问题模板如表2所示.
3.2.5 基于图形化数据库的查询 图形数据库中查询使用的是Cypher语言.结合前面识别出的医学实体名称和模板匹配得到的关系名称,根据规则生成对应的Cypher语句.已知一个实体名e和关系名称r,查询跟e有r关系的实体的Cypher语句模板如下:Match(a)-[:关系名]-(b)where b.name=“实体名”return a.name.其中,关系名和实体名用之前得到的实体和关系名替换.例如,对于问题“哪些药物可以治疗抑郁症?”,系统识别出的实体是抑郁症和药物,再根据问题模板匹配,得出两个实体的关系是药物治疗.然后根据识别出来的实体名称和关系名称,生成对应的Cypher语句:Match(a)-[:药物治疗]-(b)where b.name=“抑郁症”return a.name.根据Cypher语句查询到的结果,系统生成一段自然语言形式的回答返回给用户,如“可以治疗抑郁症的药物有舍曲林、米氮平等.”
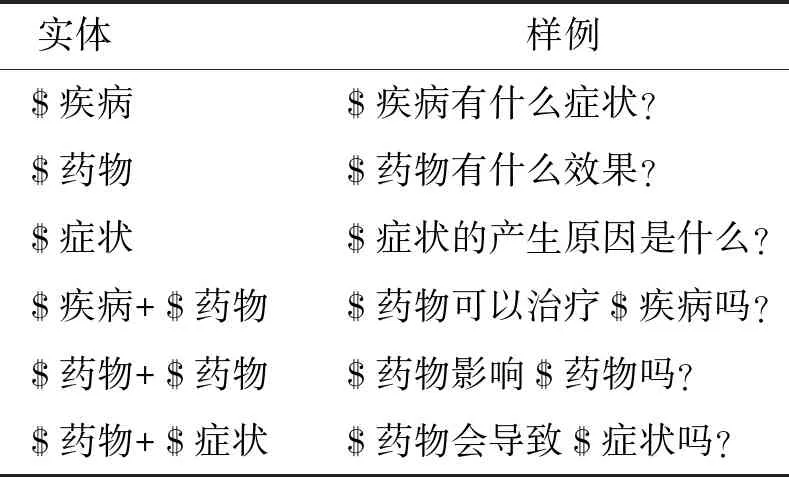
表2 不同实体的问题模板
3.2.6 生成答案 根据系统返回的结果,执行一定的语法和语义规则,形成符合自然语言逻辑且语句通顺的答案发送给用户.
3.3 系统性能分析
3.3.1 数据准备 为了验证本文中基于抑郁症知识图谱的问答系统性能,本研究分别从准确率P,召回率R和F值等3个指标来进行分析,具体计算方法如式(1)所示.其中Pnum是表示问答系统给出的回答中正确的个数,Rnum表示本研究问答系统总共给出的回答个数,Anum是实际问题的正确答案个数.其中正确回答是指用户输入的问题实体和语义被正确识别,且返回的回答符合自然语言形式.本研究人工设计了100个跟抑郁症相关的问题作为问答系统的测试数据,依次将这些问题输入到问答系统中,统计Pnum和Rnum的值.
(1)
3.3.2 实验分析 从表3的实验结果可以看出,系统回答的准确率和召回率都较高,证明本研究构建的基于抑郁症知识图谱的问答系统可以有效地为用户提供抑郁症知识问答服务.对于正确回答的问题进行分析发现,有些是跟问题模板表达方式相同的句子,而有些是跟问题模板有相同实体和语义但表示方法不同的句子,这说明基于知识图谱的问答系统具有较高的语义理解程度.对于系统没有正确回答的问题,分析得知:1)对于这些问题中的实体,系统可以识别,但是语义信息没有出现在模板中则不能识别,如“抑郁症的一般发病年龄是多少?”及“抑郁症是否遗传?”等等;2)还有一些问题是因为一些属性信息不全导致的,如药物的副作用和使用方法应该是保存在属性信息里面的.

表3 实验结果
基于系统存在的不足,本研究下一步的改进方向是:1)尽可能全面地补充抑郁症知识图谱中实体的属性信息,这样就能回答更多的关于属性的问题;2)扩充抑郁症知识图谱中的疾病覆盖率,结合更多疾病进行诊断和给出治疗意见;3) 增加更多的关系类型和关系子类型,回答更多种语义的问题;4)使用深度学习中更多算法对问题理解这个模块进行研究.
4 总结与展望
本研究从抑郁症文献中抽取出抑郁症相关的实体以及实体之间的关系,将实体和实体之间的关系形成知识三元组,从而构建抑郁症的知识图谱.知识图谱有很多应用,本研究选取其中的问答系统这一应用,实现基于抑郁症知识图谱的问答系统.该问答系统可以回答药物-疾病、药物-症状等语义信息的问题.实验结果表明,问答系统有0.79的准确率和0.73的召回率,且F值为0.76,证明该系统的实用性.目前,基于抑郁症知识图谱的问答系统回答的准确率还有待进一步提升,未来将继续使用更多的算法,研究如何提高回答的准确率,并且将属性信息更加充分地补充到抑郁症知识图谱中.
