中国少数民族聚集区农户贫困测度与分析
2020-09-10朱巧玲张明飞
朱巧玲 张明飞
(中南财经政法大学 经济学院,湖北 武汉 430073)
新中国成立以来的70多年创造了经济快速发展和社会长期稳定的双重奇迹。期间,中国的减贫工作取得了举世瞩目的成就。在人民群众的收入水平持续快速增长的同时,通过长期实施精准高效的扶贫战略,贫困人口总量和贫困发生率等指标都显著下降。当前,我国正处于全面建成小康社会,实现第一个百年奋斗目标的决胜时期,并即将开启全面建设社会主义现代化国家新征程。当此之际,受多因素综合影响的少数民族聚集区农户贫困已成为扶贫工作的重点。因此,以有效的方法充分掌握此类贫困人口及其所处环境的信息,并在提出假说之后进行验证,进而为制定反贫困政策提供支持,显然具有较高的理论与实践价值。
一、问题的提出
贫困问题既可以源于个体在健康、知识技能或社会资本等方面的缺陷,也可以源于投融资机会、产业发展的溢出效应和公共物品供给等方面的不足使个体面临人力资本投资、风险防范、机会获取和经济增长成果分享的障碍。阿玛蒂亚·森认为,只有通过有效的贫困维度选取与权重设定来构造测度体系,才能为消除贫困提供有力的支持。早期研究中的贫困测度方式主要是,基于特定区域的最低生活保障水平确定贫困标准,并根据居民的收入或支出进行贫困识别。然而,有效的贫困研究和反贫困政策都要求从健康、教育、投资机会和公共物品等维度测度个体遭受的不利影响,同时,研究对象及其所处的环境越是复杂多变,对多维测度的依赖性就越强。因此,各种多维贫困测度方法在进入21世纪之后被相继提出。其中,由Alkire & Foster(1)Alkire S, Foster J. Counting and Multidimensional Poverty Measurement. Journal of Public Economics, 2011, 95(7-8) :476-487.基于Kakwani & Silber(2)Kakwani, N. and Silber, J. Quantitative Approaches to Multidimensional Poverty Measurement. New York: Palgrave Macmillan, 2008.和Wagle(3)Wagle, U. R. Multidimensional Poverty Measurement: Concepts and Applications, Economic Studies in Inequality, Social Exclusion and Well-Being 4. New York: Springer, 2008.等研究提出的A-F多维贫困测度方法在理论界引起了极大的关注,并迅速成为研究贫困问题的典型方法。其实,王小林与Alkire在2009年就曾探索性地使用过这种方法(4)王小林、Alkire:《中国多维贫困测量: 估计和政策含义》,《中国农村经济》2009年第12期。。此后,这种方法在中国学者的同类研究中得到迅速推广,如邹薇等对中国的贫困问题实施了动态多维度考察(5)邹薇、方迎风:《关于中国贫困的动态多维度研究》,《中国人口科学》2011年第6期。;郭建宇等研究了多维贫困测量指标的权重设定与调整对贫困测算结果的影响(6)郭建宇、吴国宝:《基于不同指标及权重选择的多维贫困测量——以山西省贫困县为例》,《中国农村经济》2012年第2期。。
本文将研究范围界定为中国少数民族聚集区农户贫困问题。虽然此类贫困人口在近年来因经济发展而快速减少,但依然是中国贫困人口的主体,并呈现显著的集中趋势。就此而言,有效缓解此类贫困是中国实现区域经济协调发展和全面建成小康社会的重要途径。然而,由于经济发展的地域差异、生态条件和文化观念等因素的综合影响,此类农户的多维贫困比其他地区更为严重。随着“深度脱贫、精准扶贫”战略的推进,中国理论界除了在一般贫困问题的研究中精炼多维测度方法,还逐步拓展该方法在地域类型上的应用范围,但目前专门就少数民族聚集区农户贫困进行多维测度与分析的研究尚不多见。因此,本文认为,以充分利用农户特征和村庄经济发展状况等信息为基础,在多维测度方法的指导下,分析导致此类贫困的关键成因,并基于经济事实进行验证,对于精准扶贫战略的实施有重要参考价值。
二、A-F测度方法应用的相关设定
A-F多维贫困测度方法假设经济个体(家庭或个人)在多个方面遭受剥夺,并使用“双界限”方法对此进行测定。其操作流程是先设定个体在相应的单一维度是否处于贫困状态的判断标准,再确定个体在既定数目及以上的维度同时处于贫困状态时则被判定为贫困的维度数目的临界值。
(一)基本符号及其定义
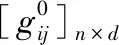
(二)贫困的识别、加总与分解
令个体贫困状况变量为ρk(yi,z)。当ci≥k时,ρk(yi,z) = 1,个体i为多维贫困;当ci≤k时,ρk(yi,z) = 0,个体i为非多维贫困。其中,k值存在是否考虑权重的区别。若不考虑权重,k∈[1,d]。当k= 1,只要存在一维剥夺,即被认定为贫困,而当k=d,则只有d维剥夺同时存在才被认定为贫困。若考虑权重,k∈[0,1]。此时,定义贫困的主流标准是个体在1/3及以上维度处于贫困,k的取值一般为1/3或0.3。
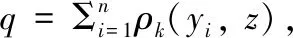
(1)
同时,可以从地区或维度等角度分解多维贫困指数M0,以便发现贫困在地区或维度间的差异,进而为制定反贫困政策提供支持。若按维度分解M0,可将公式(1)改写为:
(2)
若按地区分解M0,并假设调查个体来自G个地区,n为各地区的个体数ni之和,可将公式(1)改写为:
(3)
三、中国少数民族聚集区农户多维贫困测度
(一)资料来源
本文所用数据来自中国家庭追踪调查(CFPS)(7)联合国《人类发展报告2016》技术细节中(第8页),提到中国多维贫困所使用资料来自 2012 China Family Panel Studies(CFPS 2012); http://hdr.undp.org/sites/default/files/hdr2016_technical_notes.pdf.。这主要是基于如下两方面考虑:一是该资料包含较新的微观家庭调查资料,最早为2010年,最近为2016年,与“精准扶贫”国家战略的实施时间相吻合。二是该资料能全面反映某一群体的贫困变化。因此,近年来使用该数据进行贫困分析的研究日益增多(8)相关研究:侯亚景:《中国农村长期多维贫困的测量、分解与影响因素分析》,《统计研究》2017年第11期;李晓明、杨文健:《儿童多维贫困测度与致贫机理分析——基于CFPS数据库》,《西北人口》2018年第1期;张昭、杨澄宇、袁强:《“收入导向型”多维贫困的识别与流动性研究——基于CFPS调查数据农村子样本的考察》,《经济理论与经济管理》2017年第2期。。同时,本文将CFPS村居调查问卷中“您村/居是否为少数民族聚集区?”问题选择“是”的村庄的居民界定为少数民族聚集区。
本文选择删除给出无效回答的调查户。如果在回答中选择“无法判断”、“缺失”、“不适用”或“不知道”等,那么不仅删除相应的个体,而且删除所在的家庭。由于研究对象为全国少数民族聚集区的农户,本文只使用调查数据中农村家庭资料。同时,由于2016年的调查数据仍未完整公布,本文选用2010和2014两个年度的数据。经整理,2010年家庭样本涉及9个省区、857户家庭,2014年的家庭样本涉及9个省区、618户家庭。样本的地区分布显示,我国少数民族聚集区在西部地区所占比重约为八成。
(二)多维贫困指标设定
本文参考已有文献资料,选择从教育、健康以及生活水平等三个维度共计11个指标进行多维贫困识别,并在权重设定方面采用等权重设定方式。见表1所示。
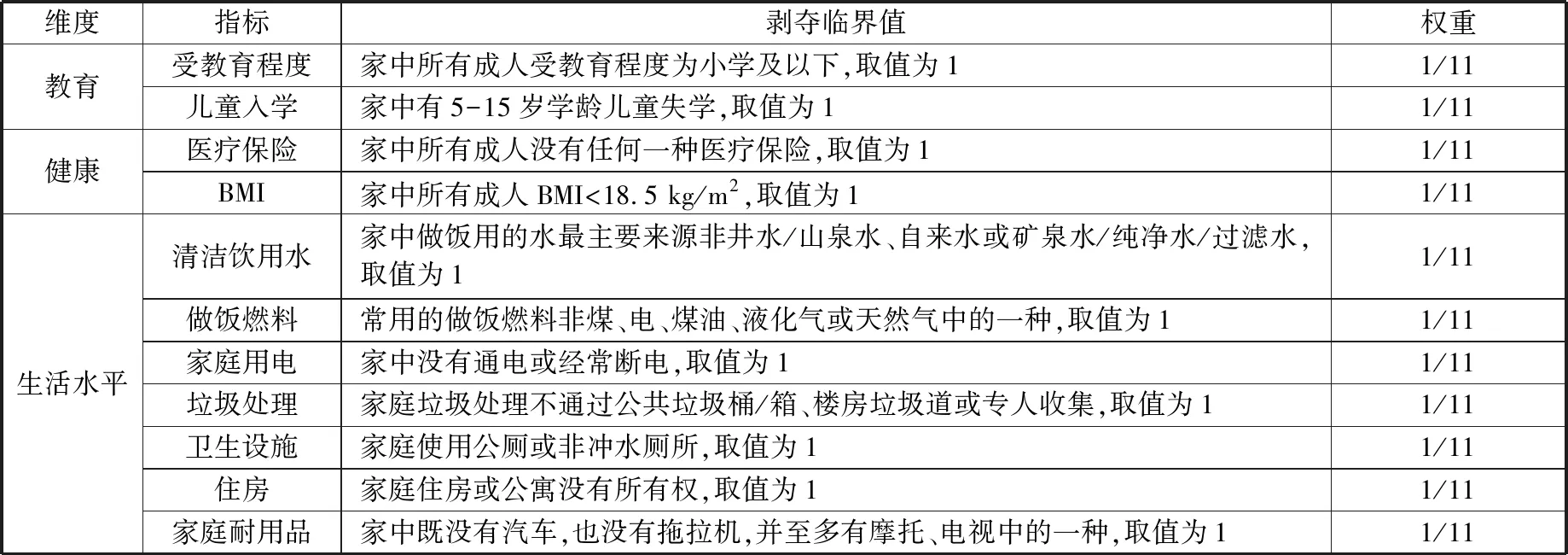
表1 多维贫困指标设定
(三)贫困测度结果
1. 单维度贫困测度
从上述11个维度分别估算单维贫困发生率,结果显示,在2010年,少数民族聚集地区农户单维贫困中较为突出的维度是:94.75%的农户在垃圾处理时不通过公共垃圾桶/箱、楼房垃圾道,82.85%的农户常用的做饭燃料非煤、电、煤油、液化气或天然气中的一种,76.55%的农户没有卫生设施,65.34%的农户家中所有成人受教育程度为小学及以下,55.19%的农户既没有汽车,也没有拖拉机,且至多有摩托、电视中的一种;而在2014年,单维贫困中较为突出的维度是:77.02%的农户没有卫生设施,70.87%的农户在垃圾处理时不通过公共垃圾桶/箱、楼房垃圾道,59.55%的农户常用的做饭燃料非煤、电、煤油、液化气或天然气中的一种,以及40.94%的农户家中所有成人受教育程度为小学及以下等,整体表现出与2010调查年度类似的特征。
2. 多维贫困估计结果
基于CFPS2010、CFPS2014中国农村居民调查数据,可以运用A-F测度方法对样本中少数民族聚集区农户进行多维贫困测量,其结果如表2所示。相关数据显示,2014年较2010年在贫困比率、贫困剥夺份额和多维贫困指数等方面都明显降低,这意味着中国少数民族聚集区农户多维贫困状况得到了较好的缓解。
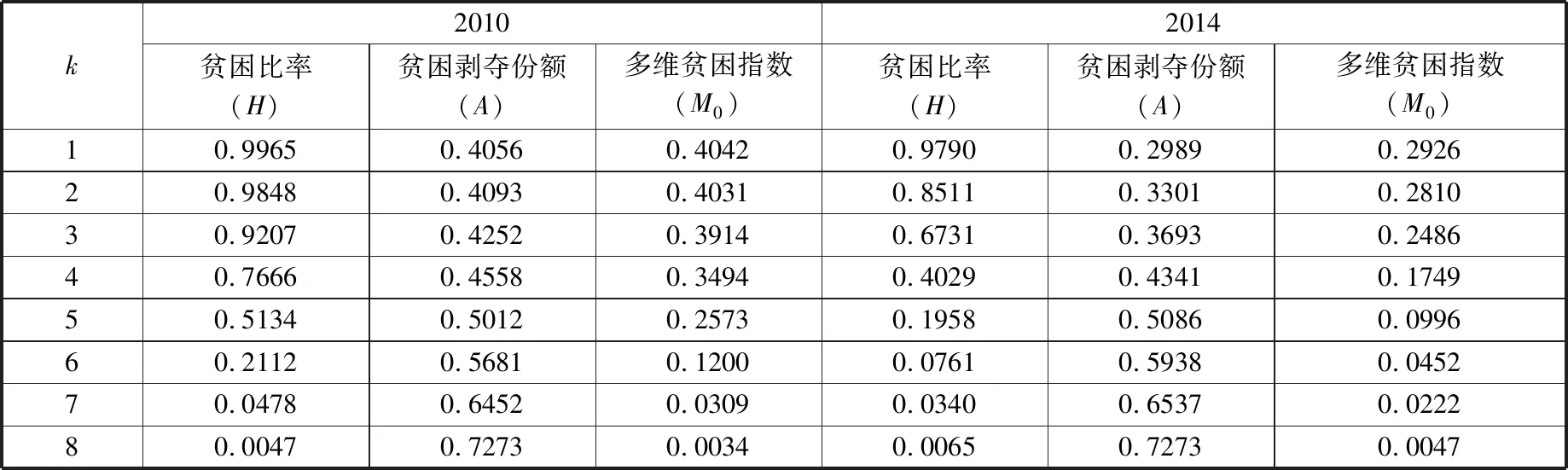
表2 中国少数民族聚集区农户多维贫困估计结果
3. 多维贫困指数分解
(1)维度分解
表3是2010年中国少数民族聚集区农户在不同k值下的贫困指数的维度贡献率。以k= 4为例,相应的多维贫困指数为0.3494,即同时存在4个维度贫困的贫困指数为0.3494。其中,垃圾处理对贫困的贡献率最大,为19.61%;做饭燃料的贡献率次之,为18.40%;卫生设施的贡献率为15.24%。
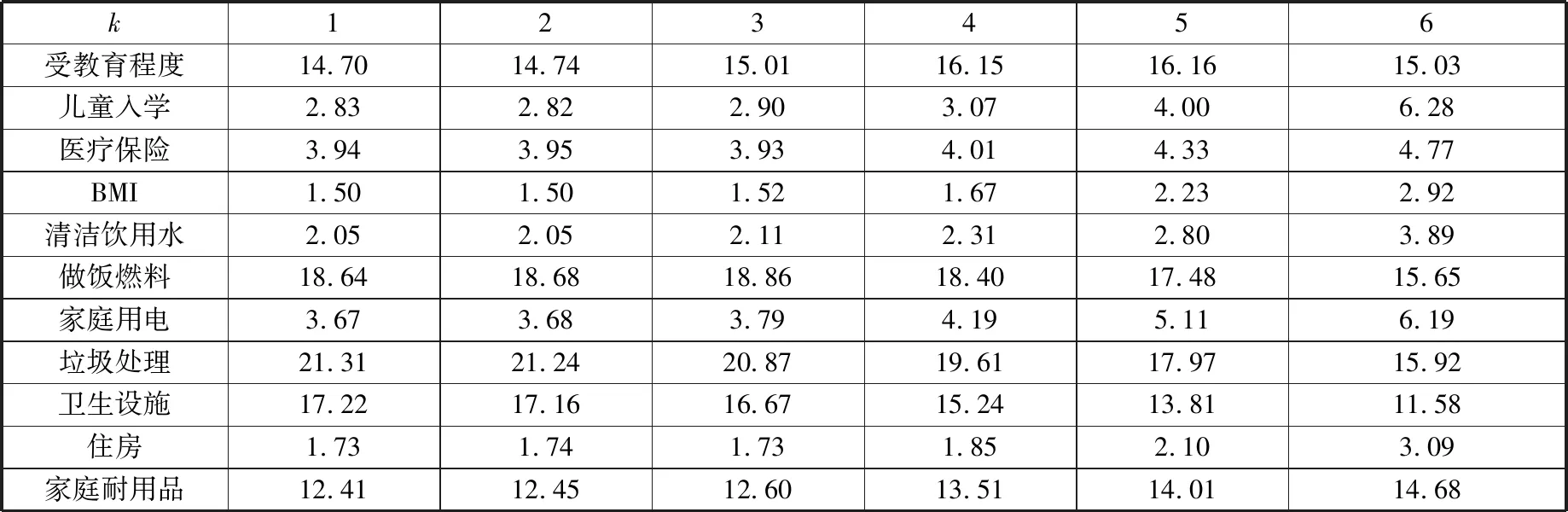
表3 2010年中国少数民族聚集区农户多维贫困维度贡献(%)
表4是2014年聚集区农户贫困在不同k值下的贫困指数的维度贡献率。以k= 4为例,多维贫困指数为0.1749,即同时存在4个维度贫困的贫困指数为0.1749。其中,垃圾处理的贡献率最大,为19.68%;卫生设施的贡献率次之,为17.66%;做饭燃料的贡献率为17.24%。
对比两个调查年度的数据可知,受教育程度、做饭燃料、家庭用电以及家庭耐用品对多维贫困的贡献程度在下降;而医疗保险、BMI、清洁饮用水、卫生设施以及住房对多维贫困的贡献程度在上升。
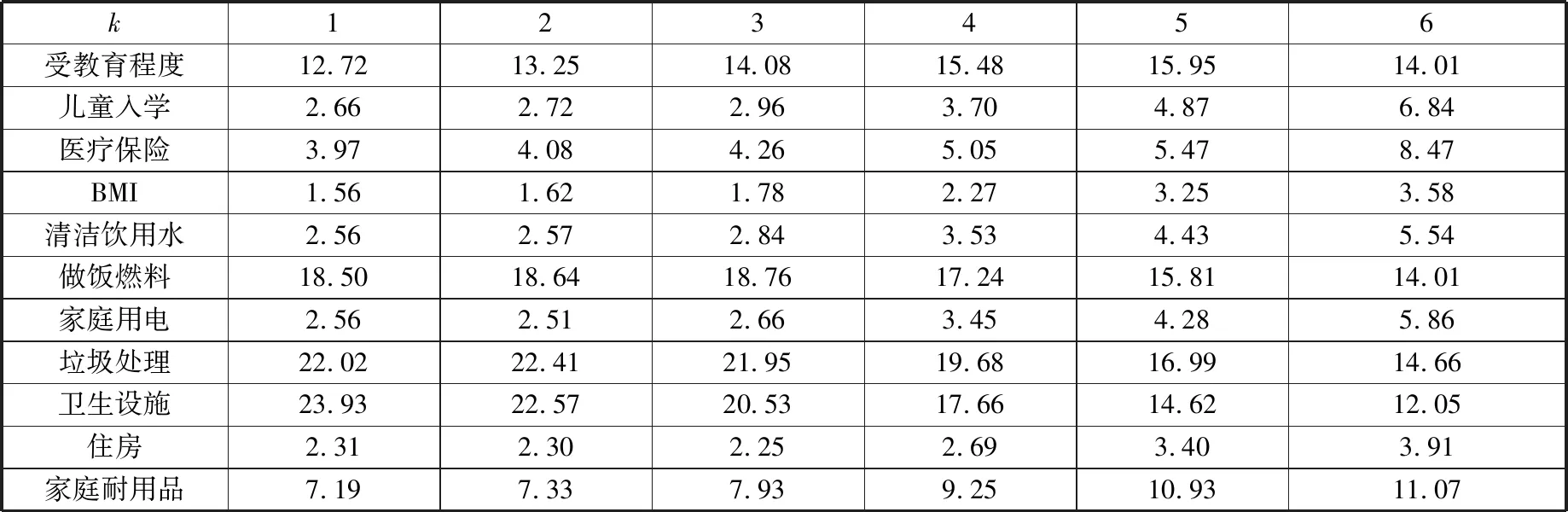
表4 2014年中国少数民族聚集区农户多维贫困维度贡献(%)
(2)地区分解
通过对多维贫困指数M0进行基于区域的分解,可以得到不同k值下各区域多维贫困指数的贡献率,结果见表5和表6。以k=4为例,2010年全国多维贫困指数为0.3494,其中,东部、西部以及东北地区少数民族聚集区农户多维贫困指数分别为0.0282、0.2878和0.0334;各区域对全国多维贫困指数的贡献率分别为8.08%、82.36%和9.56%。显然,西部地区的贫困指数最高,贫困问题最为严重。
同样以k=4为例,2014年全国多维贫困指数为0.1749,其中,东部、西部以及东北地区农户多维贫困指数分别为0.0057、0.1489和0.0203;各区域对全国多维贫困指数的贡献率分别为3.28%、85.11%和11.61%。同样,西部地区的贫困指数最高,最为严重。
两个调查年度的对比显示,东部地区对多维贫困指数的贡献程度在不同的k值下都实现了不同程度的下降,而西部和东北地区的贡献则呈现上升态势。在全国整体多维贫困指数呈现持续下降的前提下,这一结果说明西部和东北地区的贫困状况在相对意义上有所加剧,这些地区依然是精准扶贫的主战场。
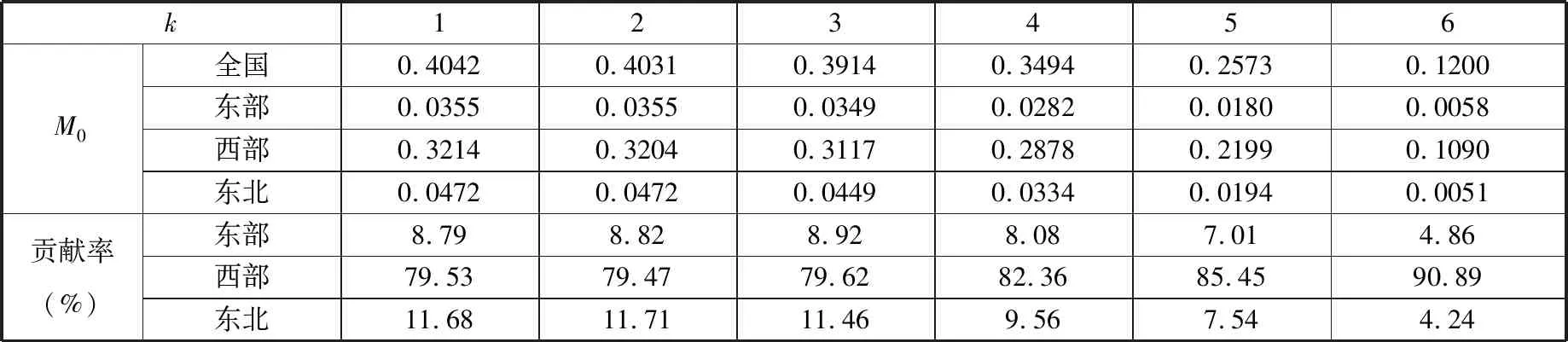
表5 不同k值下多维贫困指数(M0)的地区分解结果(2010)
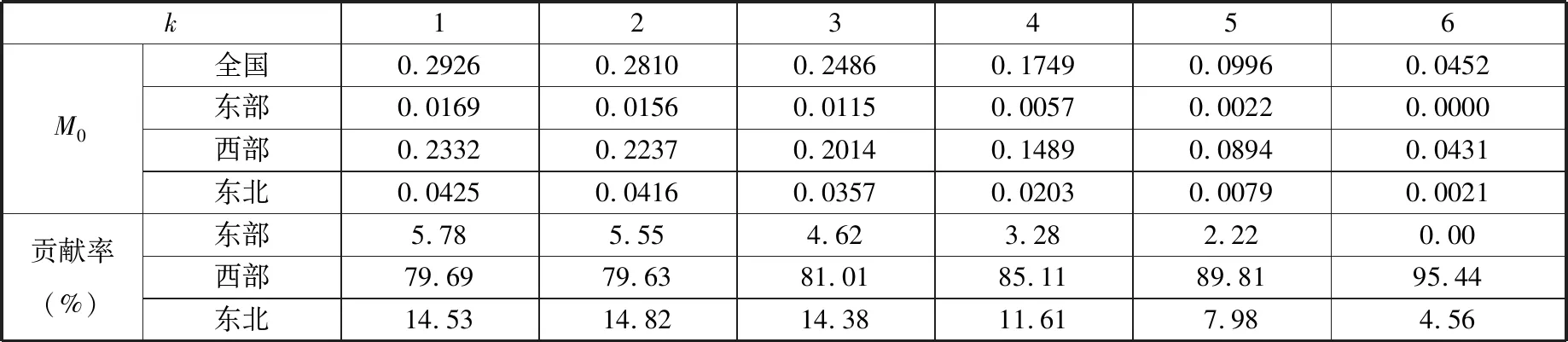
表6 不同k值下多维贫困指数(M0)的地区分解结果(2014)
四、 中国少数民族聚集区农户致贫因素分析
在多维贫困测度之后,可以探讨导致贫困的成因。问题是,多数社会调查资料都具有层级结构,会使个体之间存在非独立性,导致经典回归方法的分析结果具有显著的偏差。所幸的是,分层线性回归能很好地解决非独立性问题。如果将农户分为贫困与非贫困,分层Logisitc回归就是研究贫困问题的适当选择。
(一)模型设定
本文采用两层Logistic回归模型,其中,农户被设定为第一层,而村庄则被设定为第二层。具体而言,在该回归模型中,有关农户和村庄模型的形式可以进行如下设定:
(4)
(5)
式(4)中i=1, 2, …,nj表示省份j中的第i户调查家庭,j=1, 2, …,J表示村庄,nj为村庄j总调查户数。P(Yi j= 1) 表示村庄j农户i贫困发生的概率,P(Yi j= 0) 表示村庄j农户i贫困不发生的概率,log{P(Yi j= 1)/[1-P(Yi j= 1) }表示P(Yi j= 1)的Logit变换,经过这一变换,贫困发生率就可以写成自变量的线性表述。式(4)意味着农户贫困发生概率的Logit变换是K个解释变量X的线性函数。β0j、βkj分别代表截距项和第k个解释变量Xkj所对应的回归系数。
式(5)的设定表示截距项β0j和斜率项βkj随村庄j变化而变化,而且都是与村庄j有关的S个解释变量W的线性函数,Wsj表示村庄j的第s个解释变量。此时,β0j和βkj解释变量W的个数既可以相同,也可以不同。
(二)变量设定
因变量Y:本文将当k= 4时处于多维贫困的农户界定为贫困户,此时Y= 1,而低于这一临界值的则是非贫困户,此时Y= 0。
解释变量:鉴于CFPS数据库的特点,本文从户主特征、家庭人口特征、家庭禀赋以及村庄特征等角度选取14个变量作为解释变量。需要说明的是,CFPS家庭问卷中并无户主这一项,对于2010年度调查资料,本文使用“谁是家庭主事者”来代替,对于2014年度调查资料,使用“买房子谁说了算”来代替。所有解释变量可以处理成两种类型,包括9个分类变量和5个数值变量,各变量的定义与类型设定如表7所示。
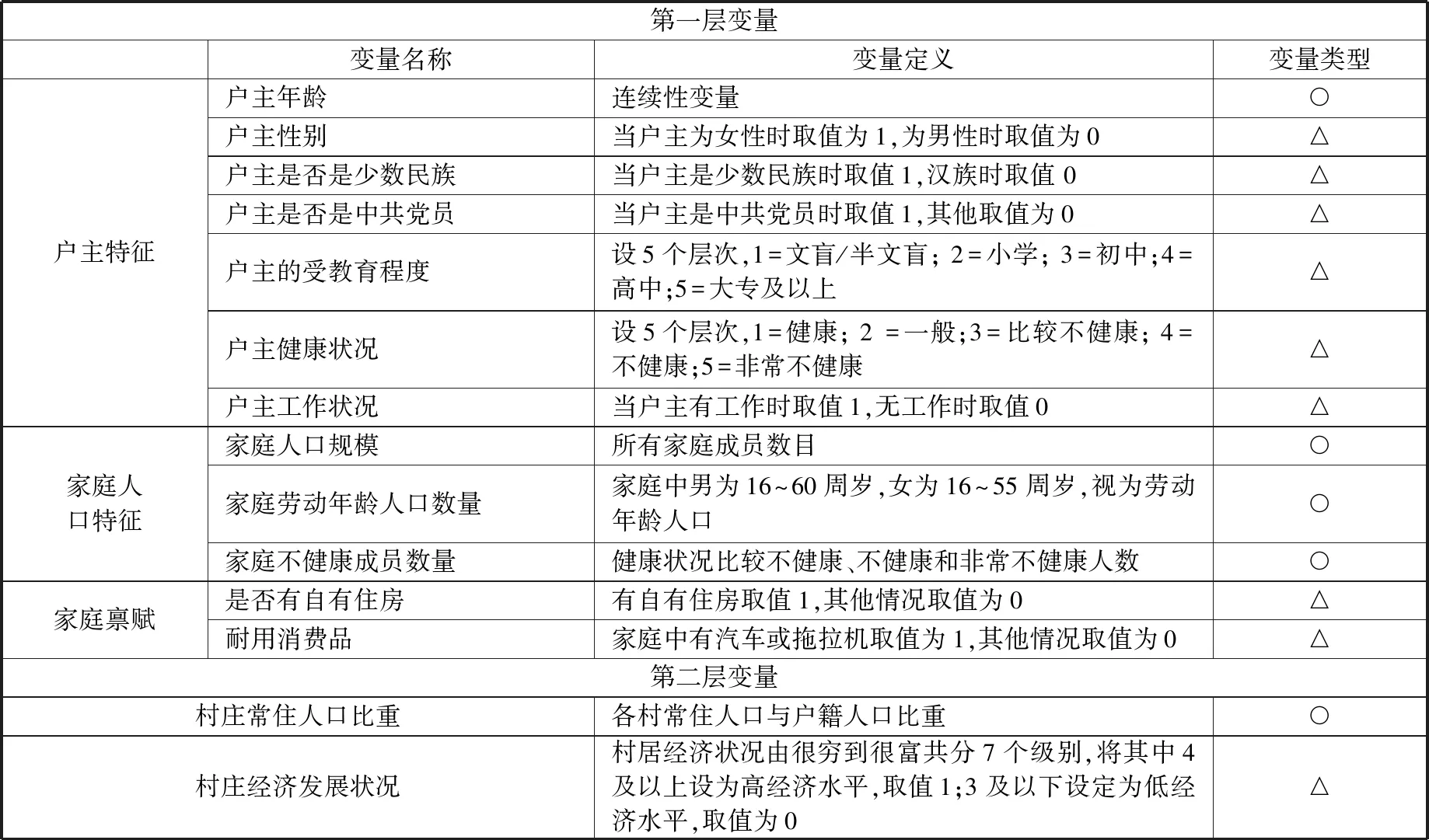
表7 解释变量设定
(三)模型结果与分析
1. 变量的描述性统计分析
通过描述性统计分析可知,在2010年,户主的平均年龄为46.22岁,平均家庭人口规模为4.68人,而2014年的数值则分别是47.59岁和4.67人。同时,两个调查年度的结果都体现如下特征:贫困户户主年龄更高、贫困户户主是党员的比重明显更低。通过相关性检验,包括以列联表χ2独立性检验方法检验分类变量和以独立样本t检验方法检验数值变量,结果显示,当选择以10%作为显著性水平时,户主年龄、户主性别、户主是否是少数民族、户主受教育程度、家庭中劳动年龄人口、家庭是否有自有住房以及是否有耐用消费品等变量在贫困户与非贫困户之间都存在显著性差别,而其余变量则不存在显著性差别。
此外,与第二层变量相关的分析结果显示,在样本范围内,村庄常住人口比重的变化幅度较大,在2010年,最高者为1,最低者为0.6237,均值为0.9232,同时,有37.50%的村庄经济发展水平较高,62.50%的村庄经济发展水平较低;到2014年,村庄常住人口比重的最低值下降为0.4178,而村庄经济发展水平较高的比例上升为70.27%。这意味着村庄的经济结构特征和经济发展水平都实现了实质性改善。
2. 回归模型结果
对于分层线性模型而言,是否应该将层级影响纳入考虑范围的主要判定指标是组内相关系数(Intra-Class Correlation,ICC),即组间方差占组内方差与组间方差之和的比重,其实质是因变量的变异中可用组间方差解释的部分。Cohen(1988)认为,当ICC > 0.059时,就应选择以分层线性模型对层级影响进行处理。其中,分层线性模型一般使用软件HLM实现。而在以HLM软件进行分层Logistic回归估计时,有两种估计程序,即特定单元模型和总体平均模型。比较而言,总体平均模型估计需要更少的假设条件,并对随机效应的设定偏误缺乏敏感性,在实践中更为常用。因此,本文选用总体平均模型进行分层Logistic回归估计。
从Logistic回归分析的角度看,通过使用全部解释变量构建模型,并以两个调查年度的数据进行检验,结果显示,可以将全部解释变量分为对贫困有正向影响和负向影响的两种类型。其中,在2010年,全部解释变量中参数检验不显著的变量包括户主年龄、户主是否是党员、户主是否是少数民族、户主工作状况、家中人口规模和家中不健康人口数量。同时,户主是男性(9)多数研究认为户主为女性更容易引起贫困;但也有研究发现户主性别为女性更不容易引起贫困。如樊丽明、解垩:《公共转移支付减少了贫困脆弱性吗?》,《经济研究》2014年第8期;郭熙保、周强:《长期多维贫困,不平等与致贫因素》,《经济研究》2016年第6期。、户主不健康、家庭没有自有住房以及汽车或拖拉机等固定资产的家庭更易陷入贫困,而户主受教育程度越高、家中劳动年龄人口越多,则越不容易陷入贫困。而在2014年,参数检验不显著的变量则包括户主年龄、户主是否是党员、户主受教育程度、户主健康状况、户主工作状况和家中不健康人口数量。此外,通过剔除参数检验不显著的变量重新构建模型,各变量的参数估计结果与其在原模型中的表现高度相似,从而意味着分析结果是有效的。
从分层Logistic回归分析的角度看,通过在截距项部分引入村庄常住人口比重以及村庄经济发展状况两个层级变量,相应的回归分析发现,村庄常住人口比重、村庄经济发展状况对模型的截距项具有显著影响,这意味着采用分层思维进行模型设定是合理的。就2010调查年度而言,户主年龄、户主性别、户主受教育程度、家中劳动年龄人口、住房是否自有等变量对贫困影响皆为显著;而在2014年,户主年龄、家中劳动年龄人口、住房是否自有、是否拥有汽车或拖拉机等变量对贫困影响显著。
通过两类回归分析的对比可知,农户贫困判定的有效性在很大程度上依赖于层级变量的引入。换言之,如果不考虑层级变量,家庭劳动年龄人口数量等变量对贫困的影响将被严重低估,而户主性别和住房是否自有等因素的影响则会被高估。
五、结论与政策建议
本文以中国农村家庭追踪调查(CFPS)数据为基础,将A-F多维贫困测度方法运用于少数民族聚集区农户贫困的测度与分析。研究发现,垃圾处理、卫生设施与做饭燃料对此类区域农户贫困的贡献度较大。2014、2010两个调查年度的对比显示,受教育程度、做饭燃料、家庭用电以及家庭耐用品对少数民族聚集区多维贫困的贡献程度在下降;而医疗保险、BMI、清洁饮用水、卫生设施和住房等对多维贫困的贡献程度在上升。同时,通过多维贫困的地区分解发现,西部少数民族聚集区的贫困指数最高,对多维贫困的贡献程度约为八成。此外,分层Logisitc回归结果表明,户主年龄、家中劳动年龄人口、住房是否自有、是否拥有汽车或拖拉机等变量对贫困影响皆为显著。而Logistic回归模型与分层Logistic回归模型的对比分析显示,农户贫困判定的有效性在很大程度上依赖于是否引入层级变量。因此,本文认为,能有效减缓此类贫困的政策措施主要包括:
第一,大力发展少数民族聚集区的农村经济。本文选用的村庄常住人口比重和村庄经济发展状况等层级变量在本质上都是农村经济发展状况的反映,而相应的分析结果显示,乡村经济的振兴发展对于提升农户的就业机会和收入水平有重要影响,能够有效减缓少数民族聚集区农户贫困。
第二,通过强化乡村建设规划和公共财政投入等途径改善农户的住房条件和公共物品的供给水平。目前,少数民族聚集区农户在建房时依然主要是从自身的局部利益出发,较少考虑配套设施建设,导致脏、乱、差现象比较突出。同时,此类农户在医疗、教育、经济机会的获取和溢出效应的分享等方面远低于全国农村的平均水平。因此,完善乡村建设规划,增加公共财政投入,是少数民族聚集区扶贫工作的重要内容。
第三,加大政府对少数民族聚集区农户的科技投入,积极开展以就业为导向的科技培训,以增强农民就业能力。政府在扶贫政策的实施过程中应该以少数民族聚集区的经济发展特征为基础,有针对性地提供此类区域农民急需的职业技能和农业科技知识等方面的培训,以期有效提高就业与经济机会获取能力。
总之,从政策效果的可持续性看,有效的扶贫政策高度依赖于扶贫方式实现从“输血式”向“造血式”转变。因此,只有以充分掌握此类农户及其所处环境的信息为基础,通过多维贫困测度与分析确定致贫的关键成因,并有针对性地实施包括有效提升农户的人力资本水平,大力增加公共物品供给,以及有效改善农村经济发展的环境条件等内容的政策调整,才能为实现少数民族聚集区农户的有效脱贫提供坚实的支持。
