基于改进即时学习算法的镨/钕元素组分含量预测
2020-09-05陆荣秀饶运春朱建勇
陆荣秀,饶运春,杨 辉,朱建勇,杨 刚
(1.华东交通大学电气与自动化工程学院,江西南昌 330013;2.江西省先进控制与优化重点实验室,江西南昌 330013)
1 引言
在稀土分离企业中,实现稀土生产过程的自动控制,获得稳定、合格的稀土产品,关键环节是实时掌握和了解稀土萃取过程中监测点各元素组分含量变化[1-2].近年来随着人工神经网络、支持向量机回归等智能建模方法在过程控制中的推广应用,基于数据驱动的软测量建模方法在稀土萃取工业过程中的研究也越来越多[3-6].针对镨/钕(Pr/Nd)萃取过程中元素的组分含量与其颜色特征相关的特性,部分学者将颜色特征应用于稀土元素组分含量的快速检测中.文献[7]在色调-饱和度-强度(hue-saturation-intensity,HSI)颜色空间提取H分量作为颜色特征,利用最小二乘法拟合组分含量与H分量之间的函数关系,首次实现了镨/钕元素组分含量的软测量预测.文献[8]采用主成分分析法在HSI颜色空间中分析各颜色分量对组分含量的影响,选取影响较大的H,S特征分量一阶矩作为输入,并利用最小二乘支持向量机(least squares support vector machine,LSSVM)建立镨/钕元素组分含量全局预测模型.文献[9]以镨/钕溶液图像的H,S,I分量一阶矩作为模型输入,并由加权最小二乘支持向量机(weighted least squares support vector machine,WLSSVM)建立组分含量预测模型,实现了镨/钕元素组分含量预测精度的提升.上述3种软测量方法均为离线建立的全局模型,适用于萃取过程工况稳定的环境下;而在实际的稀土萃取分离中,现场生产工况会因为各种因素发生变化,如原始料液配分、有机浓度以及环境温度发生变化等情况,此时离线建立的全局模型预测精度将会有所下降,因此有必要建立一种能够能跟随工况特性自适应更新的组分含量在线预测模型.
目前,不少学者将即时学习方法[10-13]用于工业过程建模,通过在线建立预测模型,提高模型预测精度.文献[14]将时间有序性融入到样本相似度准则计算中,应用到湿法冶金浸出过程的浸出率预测,在精度和实时性上效果表现良好.文献[15]将变量相关性引入到即时学习算法样本相似度准则的计算中,应用于选择性催化还原(selective catalytic reduction,SCR)脱硝系统建模,预测精度和实时性能够满足要求.文献[16]将特征加权策略引入即时学习算法,应用于工业高炉中的硅含量在线预测,获得了较好的预测性能.文献[17]提出了一种基于云模型相似性度量的改进即时学习算法,运用到球磨机的料位测量中,实现了球磨机料位的实时准确检测.
在基于即时学习策略的软测量建模中,保证模型高精度的关键是准确选取算法学习集和建立合适的局部模型[18-21].本文以萃取现场采集的Pr/Nd溶液图像H(hue),S(saturation),I(intensity),RR(relative red)和颜色矢量角(color vector angle,CVA)颜色特征分量一阶矩和Nd元素组分含量为预测模型的历史数据库,采用K矢量邻近(K-vector nearest neighbors,K-VNN)方法[22-23]确定学习集,由互信息公式[24-25]计算各个输入变量的权重,建立基于LSSVM 的稀土萃取过程组分含量预测模型;当稀土萃取工况发生变化时,引入由相似度阈值更新和数据库更新组成局部模型更新策略,较正局部模型以满足非线性系统的实时建模要求.将该模型运用到镨/钕萃取现场数据测试仿真实验,结果表明本文方法在准确性和实时性上均满足稀土元素组分含量检测需求.
2 基于即时学习算法的在线建模方法
即时学习算法是一种基于数据驱动的建模策略,根据当前状态信息在历史数据库搜索相似的数据构成算法学习集,以此建立预测模型.即时学习算法的特点在于可根据不同工况更新模型参数,具有本质的在线自适应能力;相比于全局模型,基于即时学习策略的局部模型所需样本数据较少.而决定基于即时学习策略的建模方法性能优劣的关键在于选取合适的学习集和局部模型.
2.1 学习集的选取
对于历史数据库样本输入和样本输出集合:

其中:Xi为历史样本输入,yi为历史样本输出,m为特征向量个数,采用K-VNN方法计算当前工况点输入Xq与历史数据库中样本输入Xi的欧式距离d和夹角β,表达式如下:

以数据信息的指数(exponential kernel)与夹角余弦加权之和构成相似度准则[23]选取Xq的学习集,当前工况点输入Xq与历史数据输入Xi之间的相似度计算如式(2)所示:

式中:λ为加权因子,它的取值范围为λ ∈[0,1],λ越大距离所起的作用就越大.相似度准则在表示Xi与Xq相似程度的同时也代表了历史数据输入Xi对模型的影响程度,即式(2)中相应的相似度Sqi越大则其对模型的影响越大.对Sqi按降序排列,由相似度准则选取与当前工作点相似度最大的k个(该值一般由经验估计)历史数据构造即时学习算法的学习集Ωk:

2.2 局部模型的建立
由式(3)确定的即时学习算法学习集Ωk通常是小样本数据集,为了保证模型的准确性,选用具有快速学习能力、计算简单且适用于小样本数据建模等特点的LSSVM算法建立即时学习算法的局部模型[26].LSSVM的最小化目标函数为

其中:ei为误差向量,γ为用于择中训练误差和模型复杂性的惩罚系数.为求解该优化问题,构建拉格朗日函数:

因此,可以将优化问题的求解转换成一个线性方程组的求解.根据Mercer条件,LSSVM的模型预测输出为

式中:Xq为当前工作点输入,Xi为学习集样本输入,αi为拉格朗日算子,b为偏差值,K(·)为径向基核函数,

由上述推导过程,需要优化的参数组合为(γ,σ),其中γ为误差惩罚系数,σ为高斯核函数宽度,采用网格搜索法与十折交叉验证[27]优化上述参数.
3 基于加权相似度准则的即时学习算法
在基于数据驱动的软测量建模过程中,历史数据的各个输入变量和输出变量的相关程度并不相同,因此在选取即时学习算法学习集的时候需要考虑变量相关性的影响.互信息可以通过计算各输入与输出变量的相关度来衡量各变量之间的相关性,将该相关度引入到即时学习算法学习集的选取中,用以选取当前工况点的建模邻域,进而提高模型的预测精度.
3.1 基于互信息的加权相似度准则
在信息论中,两个随机变量间的互信息(mutual information,MI)是变量之间相互依赖性的量度,互信息与相关性成正相关.对于历史数据库中的输入变量zd=(x1d,x2d,···,xNd)T,d=1,2,···,m,计算各输入变量与输出变量之间互信息的公式如下:

式中:d=1,2,···,m;N为历史数据库的样本总数目;φ(·)为digamma函数,具有式(9)的一般性质:

式(8)的基本思想是:令历史数据库中每个输入变量与输出变量组成二维矩阵Qd=(zd,y),将矩阵每个点Qid=(xid,yi)与其他点的欧式距离排列,该点K近邻距离定义为.εid=max{εxid,εyi},是这两点间的水平距离,是这两点间的垂直距离.将所有与点Qid的水平距离严格小于的点的个数定义为nxid,距离点Qid的垂直距离严格小于的点的数目定义为nyi.图1为互信息计算公式参数确定示例图,当K取1时,nxid=6,nyi=4.

图1 互信息中εid,nxid,nyi值的确定示例Fig.1 Example of determining the εid,nxid,nyi value in mutual information
根据每一个输入变量与输出变量的互信息确定各输入变量对应的权重,wd为第d个输入变量的权重,计算式为

W=[w1··· wm]T为输入权重向量,将该权重融入历史数据和当前工作点:

则基于互信息加权的相似度准则为

式(11)作用与式(2)相同,由基于互信息加权的相似度准则计算当前工况点输入Xq与历史数据样本输入Xi的相似度Sqi,以此构造即时学习算法的学习集Ωk.
3.2 累积相似因子确定学习集大小
选取合适的学习集是决定基于即时学习策略建模方法性能优劣的重要环节,学习集样本选择过多可能造成信息冗余,增加建模时间,影响模型实时性;学习集样本选择过少又可能造成信息的缺失,导致模型精度降低.传统即时学习算法对于学习集样本个数k的选取通常是在[km,kM]范围内由经验确定,选取的k值存在很大的主观性.本文采用式(12)所示的累积相似因子[28]来确定学习集的大小,按照贡献度的值选择k值,这样可以在获得大部分相似样本的同时减小学习集规模.式中:sk为设定的贡献度,该值大小由实验确定;km为输入向量的个数;kM为数据库样本个数;分子表示排序后相似度前k组样本的贡献之和,分母表示当前时刻工作点Xq与所有样本的相似度总和.

3.3 基于加权相似度准则的即时学习算法建模
由于传统即时学习算法的相似度准则没有考虑到输入与输出变量间的相关性,本文根据信息论中的互信息原理计算各输入与输出变量的相关程度,通过引入加权相似度准则使学习集的选取更加合理,进而提高模型的精度.基于加权相似度准则的即时学习算法建模步骤如下:
步骤1对于工业现场采集的输入输出历史数据库,应考虑相关冗余信息的剔除以及数据归一化等预处理;
步骤2引入互信息加权的相似度准则,按式(8)计算各输入变量和输出变量的互信息,将互信息代入式(10)计算各变量权重,将计算出的变量权重乘以相应的历史数据代入式(11)构成新的相似度准则;
步骤3由式(11)计算当前工作点Xq和历史数据样本的相似度,并更新式(3)降序排列相似度,通过累积相似因子式(12)来确定k值从而确定学习集Ωk;
步骤4确定学习集Ωk后,采用式(6)建立局部模型,由网格搜索法与十折交叉验证优化参数(γ,σ),对当前工作点进行预测;
步骤5进入下一时刻工作点,等待读取新工况数据样本.
4 基于模型更新策略的即时学习算法
传统即时学习算法应对现场工况和环境的变化的方式是通过不断更新局部模型,但若每次新样本输入都建立局部模型会增加耗时,影响模型实时性.另一方面,用于建模的历史数据库来源于离线获取,并不能包含所有工况的数据,有必要对历史数据库进行更新用以提高模型的预测精度.因此,本文基于相似度阈值更新和数据库更新策略判定是否需要更新局部模型,以此降低计算量,提高算法的精度和实时性.
4.1 模型更新策略
模型更新策略由相似度阈值更新和数据库更新两部分组成,相似度阈值更新用于提高模型的实时性降低计算量,数据库更新通过更新历史数据库提高模型的精度.
4.1.1 相似度阈值更新
在传统即时学习软测量建模方法中,由于对每个工作点都都建立局部模型,计算量较大.现考虑现场工况的实际变化,引入基于相似度阈值的模型更新策略,即当工况产生突变的时候,及时更新局部模型;而在工况稳定的时刻沿用之前建立的模型,以此降低局部模型更新频率,减少模型建立的时间,提高预测模型的实时性.具体流程如下.
假设t0为模型初始时刻,初始工作点为Xt0,以加权相似度准则选取初始输入工作点的最大建模邻域,通过累积相似因子sk确定学习集的k值,进而确定最终学习集为Ωk.采用式(6)建立局部模型
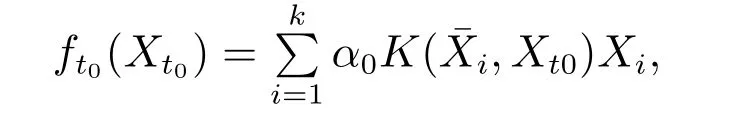

若下一时刻工作点Xt1与工作点Xt0的相似度比设定的相似度阈值大即当时,当前系统处于平稳状态,系统局部模型不变,当前工作点的预测输出仍由上次建立的局部模型求得.此时相似度阈值不变,仍为

4.1.2 数据库更新
由于S(Xi,Xq)的值直接反映了Xq和原数据库中样本的相似程度,此信息包含当前样本输入Xq周围的“密度”情况.也就是说,如果原数据库中包含很多类似Xq的数据点,则建模邻域Ωk中样本点的S(Xi,Xq)值都比较大,通过密度参数j和δ设置数据更新机制对数据进行删选,若当前工况下的数据点密度达到设定要求,为了避免旧数据点对预测产生干扰,用当前样本点替换与其相似度最小的样本点;若不满足这个要求,则说明此时的数据是新工况下的数据点或是未达到密度要求的工况数据点,将其加入到数据库中,以此抑制数据库的无限增大.具体描述如下.
在当前Xq的建模邻域中,如果S(X1,Xq)=1,说明在邻域中,样本点X1完全类似于Xq,令更新标志Flag=0,丢弃当前的样本输入.
若S(X1,Xq)<1且S(Xj,Xq)>δ,说明有较多类似Xq工况的数据点,此时为了删除某些可能干扰学习集选取和预测的旧数据点,令更新标志Flag=1,用当前样本点q替换数据库中与其相似度最小的样本点j.
不满足上述条件,则认为当前样本输入Xq是新工况下的数据点或是未达到密度要求的工况数据点,令更新标志Flag=2,将当前样本点q添加进数据库中.
该更新策略特点在于利用了学习集Ωk中样本的排列方式,无需额外的计算;通过密度参数设置数据删选条件,可以有效抑制数据库的无限增加,策略中密度参数j和δ的取值范围为1 <j ≤k,0 <δ <1,通过具体对象的实验对比确定.
4.2 基于模型更新策略的即时学习算法
传统的即时学习软测量建模方法需要对每个工作点建立局部模型,大大降低了模型的实时性,因此本文在第3节的基础上通过引入第4.1节中的模型更新策略来提高模型的实时性,同时该策略中的数据库更新能够通过更新历史数据库来提高模型精度.图2为改进后的即时学习算法建模流程图.

图2 改进即时学习算法建模流程图Fig.2 Modeling flow chart based on improved just-in-time learning algorithm
相应的建模步骤如下:
步骤1同第3.3节步骤1;
步骤2同第3.3节步骤2;
步骤3同第3.3节步骤3;
步骤4确定学习集后Ωk,采用LSSVM建立局部模型,由网格搜索法与十折交叉验证优化参数(γ,σ),对当前工作点进行预测,同时设定初始相似度阈值;
步骤5通过数据更新策略判断是否满足数据更新条件,满足条件则更新历史数据库;
步骤6读取下一时刻工作点,当前工作点Xq按步骤1-3确定学习集Ωk,通过模型更新策略判断是否更新模型,若(ti为上次更新局部模型的时刻),则需要更新LSSVM局部模型,步骤同上,同时更新相似度阈值S*=S(Xk,Xq),转至步骤5更新Flag值判断是否需要更新历史数据库;否则沿用之前更新的局部模型预测.
综上所述,该算法考虑输入与输出数据的相关性,通过互信息计算各个输入变量与输出量的相关度,将该相关度引入到即时学习算法学习集的选取中,用以选择当前工况点的建模邻域,其中学习集大小k值由累积相似因子确定;确定学习集后,采用LSSVM 作为即时学习算法的局部模型预测工作点的输出;为避免局部模型过度重构,减少局部模型建模的耗时,提高预测的实时性,引入了基于相似度阈值和数据库更新的模型更新策略;同时通过引入的数据库更新策略抑制数据库的无限增大,提高模型的预测精度.
5 组分含量预测模型仿真试验
稀土萃取是利用溶剂萃取法实现稀土各元素分离和提取的过程,而在稀土萃取工业过程中,如何快速准确的检测萃取槽内的稀土组分含量分布是决定稀土萃取产品质量的重要一环,只有实时掌握和了解稀土萃取过程中关键监测点各元素组分含量值变化才能及时调整工艺参数、保证产品质量.鉴于萃取现场生产原料的来源地和批次不同,原始料液配分差异较大,会对稀土萃取分离过程工况产生直接影响;另外,有机浓度和环境温度的变化也会引起工况发生类似的变化.目前对稀土萃取过程组分含量的预测研究仍停留在离线状态,当现场工况发生变化时离线模型可能无法适应新的工况进行准确预测,致使模型预测精度下降.本文从在线建模的角度出发,采用改进即时学习算法进行组分含量的在线预测,根据现场工况的变化情况建立不同的局部预测模型,进而提高稀土元素组分含量的预测精度.
为了检验改进即时学习算法在稀土萃取过程组分含量建模过程中的预测性能,以江西某稀土公司的Pr/Nd萃取分离生产过程为研究对象,在更换稀土萃取原始料液配分和温差明显变化等工况变化时刻,从Pr/Nd萃取线的混合槽体中采集85份样本溶液,离线化验样本溶液的元素组分含量,其中Nd元素组分含量分布在1.8%~99.965%,采用机器视觉技术获取混合溶液图像并提取溶液图像的H,S,I颜色特征分量一阶矩、相对红色分量RR[29]和颜色矢量角CVA[30].以混合溶液的H,S,I,RR和CVA值作为模型输入,以Nd元素组分含量作为模型输出,组成历史数据库:

i=1,2,···,85,建立颜色特征分量与Nd元素组分含量的对应关系.
在此次仿真实验中选取70组数据作为训练集,剩余15组数据作为测试集用于验证组分含量预测模型的有效性.为了消除各变量间数量级差异带来的影响,对历史数据库进行归一化处理.将处理后的训练集按式(8)与式(10)计算各输入和输出变量间的互信息与对应权重,计算结果如表1所示,其中Nd元素组分含量与H和CVA颜色分量的相关度较大,I分量与组分含量的相关度最小,这充分说明不同颜色特征分量对组分含量的影响是不同的.将计算出的权重代入式(11)获得加权相似度准则用于即时学习算法学习集的选取.
本文仿真实验使用相同的历史数据库,分别采用5种建模方法进行对比试验:最小二乘支持向量机(LSSVM)全局模型、互信息加权最小二乘支持向量机(MI-LSSVM)全局模型、基于传统即时学习(just-in-time learning,JITL)的最小二乘支持向量机(JITL-LSSVM)、基于传统即时学习的互信息加权最小二乘支持向量机(MI-JITL-LSSVM)和基于模型更新策略即时学习算法的互信息加权最小二乘支持向量机(MI-SJITL-LSSVM).需要注意的是:方法1来源于参考文献[8],模型输入是H和S颜色特征分量;方法2是对参考文献[9]的改进,模型输入是H,S和I颜色特征分量,为了更好的与本文局部模型的预测性能进行比较,输入权重采用互信息加权方式确定;方法3是本文第1节描述方法,即基于传统即时学习算法的预测模型;方法4是本文第2节描述方法,引入了互信息作为相似度加权的即时学习算法预测模型;方法5为基于模型更新策略的即时学习算法预测模型,其数据库更新的两个自由度参数j和δ以及相似度准则的加权系数λ和累积相似因子sk借鉴文献[31]由实验对比确定,j取10,δ取0.9,λ取0.66,sk取0.8.仿真测试结果见图3-4,各模型部分参数如表2所示.
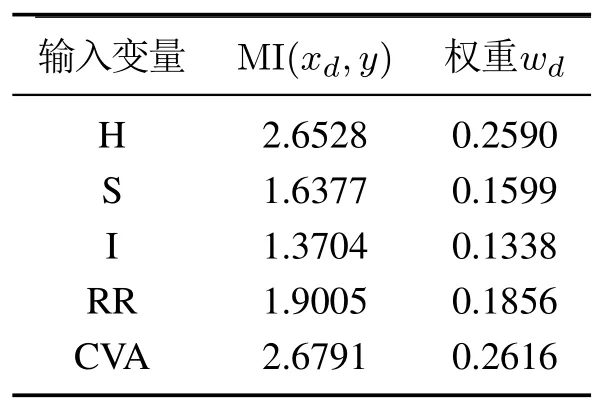
表1 各输入变量和输出变量间的互信息和权重Table 1 Mutual information and weight between each input variable and output variable

表2 软测量模型参数Table 2 Soft measurement model parameters
图3是5种建模方法预测值与化验值的对比图,纵坐标为组分含量值;图4为5种建模方法预测值与化验值之间的相对误差,纵坐标为相对误差百分比.为了更好地对比模型测试结果的优劣,以式(13)平均相对误差(MEANRE)、式(14)最大相对误差(MAXRE)和式(15)均方根误差(root mean square error,RMSE)3个误差作为衡量模型性能的指标,表3为各个模型测试性能指标结果.

式中:yi为第i组Nd元素组分含量的化验值,为第i组Nd元素组分含量的输出预测值,n的值为15.

表3 软测量模型测试性能结果比较Table 3 Comparisons of soft-sensing test performance
由图3-4及表3可以得出以下结论:
1)方法5组中分含量预测模型的平均相对误差、最大相对误差和均方根误差分别为0.7816%,3.2670%和0.01148,3个测试性能指标均优于方法1-3;而方法4的平均相对误差最小,原因是该方法的局部模型一直处于更新状态,从算法耗时上可以看出,方法4是以损耗实时性为代价提高模型精度,因此,本文提出的方法5综合性能指标最佳;
2)对比在线局部模型方法3与方法4的性能指标发现,在采用互信息对各个输入变量进行加权能够有效提高模型预测精度,证实了变量相关性对模型预测精度的影响;
3)对比表3离线全局模型方法2与在线局部模型方法4的预测性能指标,由于本文方法4增加了RR,CVA颜色分量作为模型输入,其预测精度有较大提高,且由表1各变量间的互信息值也表明,RR和CVA颜色分量对组分含量有较大影响;
4)从算法耗时方面衡量,由于全局模型方法1-2仅建立一次预测模型,因此所需运算时间最短,但因其属于离线建模方法,萃取工况变化后会降低模型预测精度;比较本文所述的3种在线建模方法,方法5由于具有模型更新策略,减小了模型更新次数进而缩短了建模时间,在适应不同萃取工况准确预测元素组分含量的前提下,能够有效提高模型实时性.
综上,对比表3离线全局模型方法1-2和在线局部模型方法3-5的预测性能指标,在线局部模型预测性能指标总体上更优,说明适应工况变化的在线建模方法能够有效提高稀土元素组分含量的预测精度;在线局部模型方法3-5预测值与化验值的相对误差绝对值均小于5%,都达到了稀土萃取生产现场的应用要求,能够实现稀土元素组分含量的快速准确预测,其中本文提出的方法5(MI-SJITL-LSSVM模型)由于引入了模型更新策略,在算法的预测精度和实时性上总体表现效果更佳.

图3 组分含量软测量模型预测输出结果Fig.3 Output result of component content soft-sensing model

图4 组分含量软测量模型输出相对误差Fig.4 Relative error of component content soft-sensing model
6 结论
为了精确预测具有离子颜色特征的镨/钕萃取过程中元素的组分含量,本文提出了一种基于改进即时学习算法的组分含量预测模型.引入互信息改进即时学习算法的相似度准则用于学习集的选取,同时通过引入相似度阈值更新和数据库更新的模型更新策略判断局部模型是否需要更新,从而在保证准确性的前提下提高模型实时性.通过与LSSVM,MI-LSSVM全局模型和基于传统即时学习算法的LSSVM模型进行比较,结果表明本文提出的MISJITL-LSSVM组分含量预测模型通过引入互信息计算的变量加权相似度准则得到更加合理的学习集,能够有效提高模型预测精度;由于引入了模型更新策略,模型的预测精度和实时性得到了较大提高,能够满足稀土萃取组分含量检测的快速性和准确性要求,同时可为具有颜色特征的其他工业过程监测提供借鉴.
