基于RGB-D相机的矮砧苹果识别与定位
2020-09-04岳有军王红君
赵 辉,李 浩,岳有军,王红君
(1.天津理工大学 电气电子工程学院,天津 300384;2.天津农学院 工程技术学院,天津 300384)
0 引 言
利用机器视觉对果实进行识别与空间定位是解决实现果园机械化,智能化管理的关键。由于彩色图片获取方便,目前很多方法通过提取果实的颜色、纹理、形状等特征[1-4],或者基于深度学习的方式实现复杂场景下的果实识别与定位[5,6],此外相对于在目标周围生成识别框体的方法,高效的语义分割网络[7-9]可以对每个像素进行分类从而获取目标更精细的形状信息。
随着RGB-D相机的普及,基于结构光以及TOF(time of flight)技术能够高效获取目标的深度信息进而对果实进行空间定位,Lehnert等[10]将RGB-D相机安装在机械臂上,通过捕捉甜椒的彩色和深度数据,结合色差分割以及超椭球拟合算法完成对甜椒的识别与定位,实现室内环境下的甜椒采摘。文献[11]通过KinectV2相机采集苹果点云,并利用RANSAC(random sample consensus)算法对苹果形状进行估计。由于通过相机标定可以完成彩色图和深度图配准,十分便于二维语义分割的结果与三维信息的融合[12,13],在获取目标空间位置的同时能够提供更精确的轮廓信息,因此为了提升果实识别与定位的精度与速度,提出一种基于RGB-D相机的苹果识别与定位方法,利用KinectV2深度相机进行彩色数据和深度数据的获取,结合语义分割网络以及聚类方法,完成苹果点云的实例分割并对局部点云使用并行化的PROSAC(progressive sample consensus)算法进行形状拟合,最终获取果实的中心坐标以及形状信息,完成识别与空间定位。
1 苹果点云分割
1.1 数据获取
KinectV2是微软于2014年发布的第二代RGB-D相机,采用TOF技术,相比于第一代能更好适应光照变化,文献[14]测试了Kinectv2在不同位置的精度分布,数据显示,在距离目标0.5 m-3 m的范围内深度数据的精度最高,深度误差小于2 mm。考虑到深度图的质量以及目标果实在彩色图像中所占的比例,数据采集过程中控制相机与果树之间的距离为1 m-1.5 m的范围内。KinectV2采集到的彩色图片尺寸为1920×1080,而深度图尺寸为512×424,因此使用官方提供的SDK对彩色图片与深度图进行配准,配准后的彩色图像的尺寸与深度图像一致,如图1所示。

图1 彩色图与深度
1.2 基于DU-net的苹果图像语义分割
本文采用改进的U-NET网络对采集到的苹果图像进行分割,U-NET[8]网络采用编码解码结构,编码部分逐层提取图像特征,并减半特征图的尺寸,解码部分通过上采样逐层恢复特征图至原图尺寸。解码器与编码器之间通过跳跃结构将底层特征与高层特征融合,以此提高分割精度。由于池化层的存在,特征图每经过一次池化,尺寸便缩小为原尺寸的一半,使得网络对于小物体的分割精度较差,而将池化层去除会缩小神经元的感受野,致使网络不能很好提取图片的全局特征,针对这一点,使用空洞卷积[15]对原始网络结构进行改进,空洞卷积核结构如图2所示。

图2 原始卷积与空洞卷积
相比于原始卷积,空洞卷积根据膨胀系数r,在卷积核单元之间插入r-1个零,以此来达到增大感受野的目的。假设原始卷积核尺寸为K,空洞卷积的卷积核尺寸由式(1)确定
Kd=K+(K-1)(r-1)
(1)
对于3×3的原始卷积核,膨胀系数为2的卷积核尺寸为5×5,感受野增大至7×7,但参数数量与原始卷积核相同,因此空洞卷积能够在保持参数数量不变的同时,增大感受野并维持特征图尺寸,提升了网络对小物体的分割精度。改进后的网络结构如图3所示。
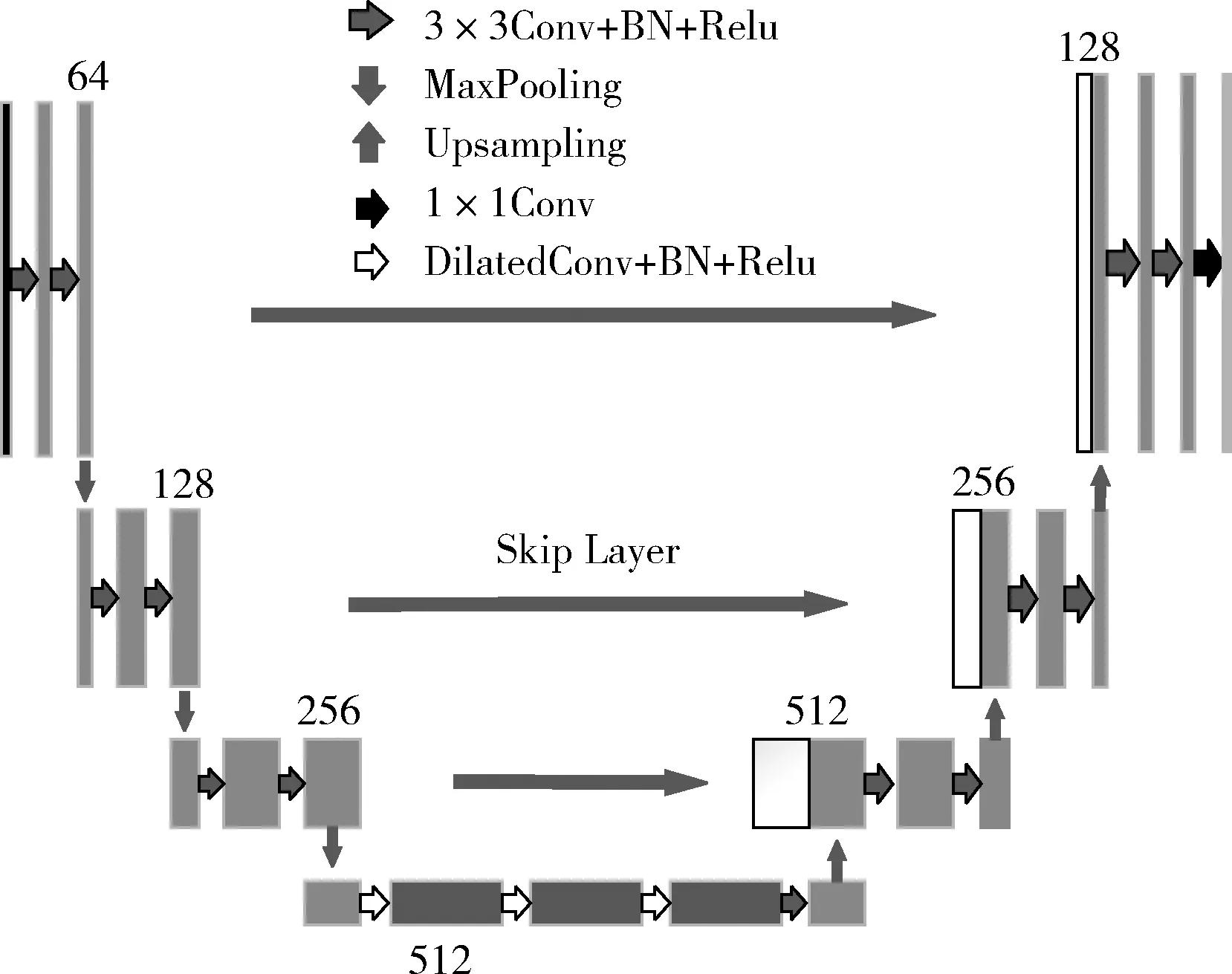
图3 DU-Net网络结构
网络编码部分使用预训练的VGG16网络进行初始化,去掉第四个池化层并引入一组空洞卷积序列,膨胀系数设置分别为2,3,5,并在之后使用一层普通的3×3卷积进行平滑处理,以此来减弱网格效应并减半通道数。解码部分的上采样层与池化层对应,采用双线性插值的方式恢复特征图尺寸,网络的最后使用1×1卷积计算像素计算各类别的分数,损失函数为Softmax交叉熵损失。本次训练在服务器中进行,服务器系统版本为ubuntu18.04,配置为Intel Xeon(R) CPU E5-2650 v4 @ 2.20 GHZ×48核的处理器,64 GB内存,一块GTX1080TI显卡,显存11 GB。训练集包含1000张分辨率为256×256的小尺寸图片和1000张分辨率为512×512的大尺寸图片,如图4所示。小尺寸图片包含苹果数目较少,且果实较为完整。大尺寸图片则包含更复杂的场景。测试集尺寸为512×512,共300张。

图4 部分训练图片示例
网络基于Caffe框架实现,网络参数的更新方式为随机梯度下降且动量设置为0.95,学习率随迭代次数T的增加按照式(2)进行衰减,其中gamma和power分别设置为0.0001和0.75。

(2)
整个训练过程分为两个阶段,首先使用小尺寸图片进行训练,BatchSize设置为8,网络的初始学习率设置为0.01,迭代20 000次后利用大尺寸图片对网络进行微调,此时BatchSize设置为2,初始学习率为0.001,迭代10 000次后完成训练,最终测试效果如图5所示。

图5 U-Net、DU-Net效果对比
相比于原版U-Net,空洞卷积的引入以及特征图尺寸的增大使得网络对小目标的分割精度更高。分别对FCN-8S,原始U-NET以及改进的DU-Net进行测试,使用平均像素精度MPA,和平均交并比MIOU作为衡量指标,测试结果见表1。

表1 FCN,U-Net,DU-Net分割效果对比/%
1.3 点云滤波
通过相机的内参矩阵可以将深度图片转化为点云,而配准后彩色图像与深度图像尺寸相同,且像素之间存在对应关系,因此可以将语义分割后的彩色图片映射到点云上,生成语义点云,如图6(b)所示。利用条件滤波器进行背景滤除,并获取对应颜色的苹果点云。对苹果点云中每个点统计其以1 cm为半径的范围内所包含的相邻点的个数,认定相邻点个数小于20的点为离群点并加以去除最终得到分割去噪后的苹果点云。如图6(c)所示。

图6 语义点云的生成以及背景去除
2 苹果点云的实例化分割
2.1 建立八叉树索引
八叉树是一种专门用于描述三维空间的数据结构,每一个父节点的节点数目只能有8个或零个。八叉树算法从最大体素开始划分,并判断节点是否包含数据点,若包含则继续划分,直到划分至最小体素分辨率。八叉树算法可以将空间点云转换成离散的体素形式,进而确定体素之间的邻接关系。通过统计点云在各坐标轴上的最大、最小值,并以|Xmax-Xmin|,|Ymax-Ymin|,|Zmax-Zmin|为三边长度构建初始体素,本文中最小体素分辨率Rvoxel设置为5 mm。
2.2 基于LCCP算法的点云聚类
矮砧苹果果实分布较为密集,对于果实层叠遮挡严重的情况,传统的基于距离以及密度的聚类方法没有很好利用到点云的几何信息,很容易将多个苹果分割成一个。相比于传统聚类方法。LCCP[16](locally convex connected patches)算法通过体素块之间的距离以及法线信息分析果实之间的凹凸性关系,能更好分割层叠苹果。
LCCP算法首先使用超体聚类对点云进行过分割并生成超体素,超体聚类是K-means算法的一种变体,通过在体素空间均匀设置种子点,并且根据体素间邻接关系以及相似性对点云进行过分割处理。相似性度量为,颜色、距离、法线度量的组合,如式(3)
(3)

对于相邻的两片超体素块Pi,Pj,LCCP算法采用CC(extended convexity criterion)和SC(sanity criterion)判据分别针对表面连续和表面不连续的情况对邻接超体素进行凹凸性分析,如果两片超体素块之间为凸则认为它们属于同一个物体。
当表面连续时,通过CC判据判断相邻体素块之间的凹凸关系
(4)
(5)
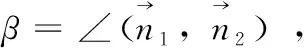
(6)

(7)
(8)
本次实验将超体素聚类的种子点间距Rseed设置为5 cm,Rvoxel设置为5 mm,即最小体素分辨率。Dc,Ds,Dn分别设置为0,2,4,βT设置为10,LCCP聚类效果如图7所示。

图7 LCCP算法聚类效果
3 局部点云的形状拟合
由于单一视角获取的点云数据仅能反应果实的局部信息且苹果果实的形状近似球体,因此本文采用PROSAC渐近采样一致性算法对每个聚类进行空间球拟合,确定果实的中心坐标以及形状信息。
PROSAC为RANSAC的一种变体,在进行采样之前,PROSAC算法优先利用一个评价函数对点云中每一个点进行评估并将数据点按照评价函数值的大小进行降序排列,评价函数越高的数据点越有可能是内点,算法选取前n个评价函数值最高的数据点作为采样子集Un,采样点在Un中随机采样,最有可能是内点的数据点被优先选取,由内点计算出的模型更有可能是正确模型,因此相比于RANSAC,PROSAC收敛更快,计算出的模型更精确。此外,Un的大小随迭代次数不断增大,评价函数值相对较低的点也会不断被采样到,此外Un的大小随着迭代次数不断增大,这样即使某个内点被错误的赋予了较低的评价函数值,也有很大几率在一定迭代次数内被采样到,使得生成的模型更加精确。
由于KinectV2采用TOF的方式获取目标的深度数据,点云数据的分布往往呈现中心密度高,四周密度低的现象,因此以每个点半径1 cm的范围内相邻点的数量作为评价函数值对数据点进行排序,若一点的评价函数值越高,则说明该点周围的点云越密集,属于内点的概率就越大。

(9)
每次迭代后记录模型所包含的内点数量,并以此作为评价模型优劣的标准。算法产生正确模型所需的最少迭代次数Tmin可以通过概率的方式估计,即
(10)
其中,η表示算法最终能得到正确模型的置信度,设置为0.95,m为求解模型所需要最少采样点数,ε为内点在数据集中所占比例,每次迭代后,若当前模型包含的内点数量大于之前模型的内点数量,则认为当前模型为最优模型,并根据式(10)更新Tmin,若当前迭代次数大于Tmin,则算法停止,返回最优模型,并利用最小二乘法进一步拟合模型中包含的内点,作为最终的模型。
以LCCP算法分割后的苹果聚类为PROSAC算法的输入,由于聚类与聚类之间相互独立,互不影响,十分适合并行化处理,因此采用多线程的方式,对多个聚类同时进行形状拟合,提升算法效率。
由于枝条遮挡,本应属于同一个果实的点云可能会被算法归为不同的聚类,使得一个果实被识别为多个如图8(a),图8(b)所示,此外点云数量过小的聚类更有可能是噪声或因遮挡而产生的点云残片,因此不对点云数量少于100的聚类进行拟合以此减轻噪声以及遮挡对拟合效果的影响,并且在算法结束之后对所有的球心坐标建立KD-Tree索引,对每个球心进行半径为2 cm的范围检索,若不同球心之间-的距离小于2 cm则认为对应的聚类属于同一个果实,并将各聚类中的点合并,重新进行拟合,校正后的结果如图8(c)所示。

图8 校正错误拟合
4 实验与结果分析
拟合算法的测试在台式机上进行,CPU型号为Intel Core I5-4590,线程数为4。程序基于C++语言编写,使用PCL点云库对点云数据进行处理并利用openmp对程序进行多线程加速。本文方法将与文献[11]所用方法进行对比。文献[11]对于分割后的点云并不进行聚类处理,采样点直接在整个点云集中选取,通过循环执行RANSAC算法对输入点云进行球面拟合并再将已被分割的点云剔除,直到剩余点云小于给定阈值时停止。这种方法当果实个数较少时取得了不错的效果。但当果实数量较大,遮挡较严重时,该算法的拟合效果较差。根据式(10),RANSAC与PROSAC算法通过η和内点比例ε来估计算法所需的最小迭代次数Tmin,由于文献[11]算法并不限制采样范围,其内点比例约为为ε=ni/N,其中ni为第i个苹果所包含的点云数目,N为数据点总数,ε随着果实个数的增多而逐渐降低,如果要保证一个较高的置信度η(一般取为0.95)则算法所需的迭代次数会变得非常大。当迭代1000次时,拟合出现了较大的误差,如图9(a)所示,直到迭代3000次时算法才能正确的拟合其中一个苹果点云,如图9(b)所示。此外,由于文献[11]算法是以一种串行的方式执行算法,前一次误差影响到后一次的拟合过程,误差会逐渐累计,最终产生错误的拟合结果,如图9(c)所示。而本文方法,将采样范围限制在每个聚类当中,内点比例显著增大,算法收敛更快,即使在多果的情况下,算法仍旧能够在有限的迭代次数内实现较好的拟合效果。如图10(a),图10(b)分别为迭代50,100次时的拟合效果。由于聚类与聚类之间相互独立,即使出现拟合错误的情况也不会影响其它聚类的拟合效果,此外,由于对点云基于密度进行排序,采样点总是首先在密度较高的部分进行选取,在果实点云残缺较为严重的情况下,受到离群点的影响较小,因此能很好拟合层叠遮挡严重的果实如图10(c)所示。
相比于串行方式,本文采取并行方式同时对多个果实聚类进行拟合,提升了算法的效率。本次实验选取15组不同点云数量的样本,点云数目最少为3200,最大为15 900。分别以串行和并行两种方式执行算法。耗时对比如图11所示。

图9 文献[11]算法拟合效果
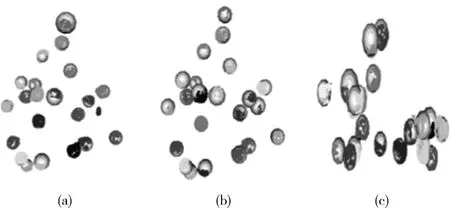
图10 本文算法拟合效果

图11 串行方式与并行方式处理时间对比
为衡量算法对苹果识别的准确率,本次实验分别拍摄不同光照程度,果实数量以及遮挡层叠情况的点云图像40张,每张点云图片中果实数量最少为10,最多为32。利用游标卡尺测量苹果水平方向,竖直方向,以及两对角线方向的半径并求均值作为最终的半径长度,测得半径长度最小为4.1 cm,最大为4.8 cm。将半径阈值设定为Rmin为3 cm,Rmax为6 cm,利用排水法测量每个苹果的体积。将数据集按照果实数量以及遮挡程度分为果实数量较少,果距较大,层叠程度轻微以及果实数量大于20个,且层叠遮挡严重两个集合,分别对文献[11]算法与本文算法进行测试,设每个聚类中点云数量为Ni,算法拟合聚类所得到的内点数量为ni,球半径为R,若满足
(11)
则认为当前聚类被算法成功拟合,果实被正确识别。算法的准确率为正确识别的果实数量与果实总量的比值,测量结果见表2。
由于光照以及叶片遮挡会影响苹果图像的分割精度,使得最终每个聚类包含的点云数目差异较大,本次实验统计算法在不同点云数目下的半径均方根误差以及体积均方根误差,以此衡量算法对残缺点云的拟合效果,见表3。由表3可知,当聚类所包含的点云数量大于500时,算法拟合精度较高,随着点云数量减少,往往会产生误差较大拟合结果,但半径均方根误差较为稳定,对点云数量不足200的情况,最大半径误差不超过1 cm,因此本文算对光照,遮挡等影响有较强的鲁棒性,可以完成复杂环境下果实的识别与定位。

表2 识别准确率对比/%

表3 不同点云数目下的拟合效果
5 结束语
本文首先利用扩张卷积对原始U-Net网络进行改进,提升了网络对小目标的分割精度,采用二维向三维映射的方式生成语义点云,完成苹果区域的点云分割,基于LCCP算法对苹果点云进行实例化分割,并使用多线程的PROSAC算法对局部点云进行拟合,实验结果表明,本文算法能够高效地对空间果实进行识别,对多果实且存在层叠遮挡的情况亦能取得不错的效果,能够对残缺点云进行较为精确的拟合以此获取果实的形状与位置信息。
