基于蚁群算法的STP系统测试序列优化生成
2020-09-04唐汇东杨华昌王浩然任宛星
唐汇东,杨华昌,王浩然,任宛星
(1.中国铁道科学研究院集团有限公司 通信信号研究所,北京 100081;2.北京华铁信息技术有限公司,北京 100081)
0 引 言
无线调车机车信号和监控系统(shunting train protection system,STP)是保证铁路调车作业安全的关键设备,当前已经在全路范围内推广使用。在STP系统投入运营前必须进行严格的测试与验证,以确保系统的安全性与可靠性,而测试案例和测试序列是执行功能验证的基础,故有必要研究测试序列的优化生成方法,以便将测试案例组合成为最有效和最优化的测试序列,从而节约测试时间,提高测试效率。
近些年来,针对铁路信号系统测试序列的优化生成问题,学者们展开了一系列研究工作[1-6],并提出了一些用于优化生成测试序列的算法,如改进Hungray算法[2]、深度学习与遗传算法[3,4]、动态规划算法[6]等。但还存在一些问题需要进一步研究:①在生成测试序列时未考虑被测功能的优先级,而实际测试时往往需要对系统关键功能优先执行测试;②生成测试序列时以极小化测试序列中包含的测试案例个数为优化目标,而实际测试时由于各个测试案例的执行时间长短不一,故测试序列中案例个数极小化往往并不等价于测试效率极大化。本文在前人研究的基础上,进一步考虑被测功能的优先级,并以最小化测试时间为优化目标,提出将STP系统测试序列的优化生成问题转换为求解有向图上的分层中国邮递员问题,并给出基于改进蚁群算法的测试序列优化生成方法。仿真结果表明,该方法可在不影响测试完备性的前提下大幅度节约测试时间,提高测试效率。
1 问题描述
1.1 STP测试需求
STP系统是基于计算机的控制系统,由地面设备和车载设备组成,其通过无线通信的方式将调车相关的信号、道岔、轨道电路区段等信息传送到调车机上,实现调车信号、调车进路在机车上的实时显示,并基于目标距离模式实现对车列的安全防护[7]。
铁路行业标准《无线调车机车信号和监控系统技术条件》[7]描述了STP系统应具有的各项功能和对应的技术指标,对STP设备执行测试,就是要检测STP设备的功能实现是否符合该技术条件。
1.2 测试案例
可将STP设备的运行过程看作是由一系列状态以及状态之间的转换构成,这可以通过测试案例来刻画。一个测试案例描述被测设备从某个状态到另外一个状态的转换,其包括3个基本要素:起始状态、相关输入/期望输出、结束状态,如图1所示。一个测试案例是某个系统功能的部分体现,通过执行测试案例,比较被测设备实际输出与测试案例期望输出的一致性,可实现对被测设备的功能验证。

图1 测试案例要素组成
在实际的测试过程中,由于测试案例数目通常非常庞大,而测试时间和测试资源却非常有限,在执行测试时,应优先测试与系统关键功能密切相关的测试案例,然后再测试与辅助功能相关的测试案例,以便尽早地发现系统中潜在的关键功能缺陷,从而及时反馈给开发人员或数据制作人员进行修改。所以每个测试案例有一个对应的测试优先级,该值越高,则测试时应优先安排测试。
1.3 测试序列优化生成
在执行某个测试案例之前,需要先执行某些系统功能,以便将被测设备的状态转换到该测试案例的起始状态,而这些系统功能又包含在其它测试案例之中,由此可以看出:直接执行单个测试案例来验证系统需求是不可取的[1],这将导致大量测试案例被重复执行,严重影响测试效率。应将多个相关联的测试案例按照一定规则串接起来一同测试,从而使得序列中前面的测试案例可为后面的测试案例创造执行条件,这样可减少测试案例重复,提高测试效率。如图2所示,将多个测试案例按照一定规则串接到一起,就构成了测试序列。

图2 由测试案例串接形成测试序列
测试序列的构建原则:①在测试序列中,后一个测试案例的输入态(起始状态)必须能与前一个测试案例的输出态(结束状态)相匹配;②为使测试覆盖所有的测试案例,完整的测试序列应能对所有的测试案例执行测试;③优先级高的测试案例应在优先级低的测试案例之前执行测试;④为提高测试效率,应尽量减少整个测试序列的测试时间。
不同的测试案例串接顺序对应着不同的测试序列。当前主要由测试人员凭借自身经验从测试案例库中挑选案例并串接形成测试序列。当测试案例数目较多时,这种人工串接形成的测试序列往往包含大量的冗余测试项,从而导致测试效率低下;同时也容易因人为疏忽而造成测试案例遗漏,从而影响功能测试的完备性。故有必要研究测试序列的优化生成算法,以便利用计算机基于测试案例集自动生成最有效和最优化的测试序列。
测试序列优化生成的目标是:在满足上述测试序列构建原则的前提下,通过合理安排测试案例,使得整个测试序列的总测试时间最少。
2 模型构建
2.1 模型假设
本文所建模型基于以下假设:①测试成本只考虑时间成本;②优化生成测试序列时,不考虑测试案例执行失败的情形;③当测试案例作为测试项时,其执行所需时间是固定的;④当测试案例作为系统状态转换项时,其执行所需时间也是固定的。
2.2 变量定义
A={a1,a2,…,aN}——测试案例集合;
S={s1,s2,…,sM}——生成的测试序列;
p(ai)——测试案例ai的测试优先级;
xij——0-1决策变量,xij=1时,表示sj=ai;xij=0时,表示sj≠ai;
rj——0-1决策变量,rj=1时,表示在测试序列S中sj为测试项;rj=0时,表示在测试序列S中sj为状态转换项;
t1(ai)——测试案例ai作为测试项时,其执行所需时间;
t2(ai)——测试案例ai作为状态转换项时,其执行所需时间;


2.3 测试序列优化生成问题的数学模型
测试序列优化生成问题的数学模型可以表达为:基于N个测试案例构成的无序集合A={a1,a2,…,aN},构建一个由测试案例组成的序列S={s1,s2,…,sM},使得在符合约束条件下目标函数最小化
(1)
(2)
(3)
(4)
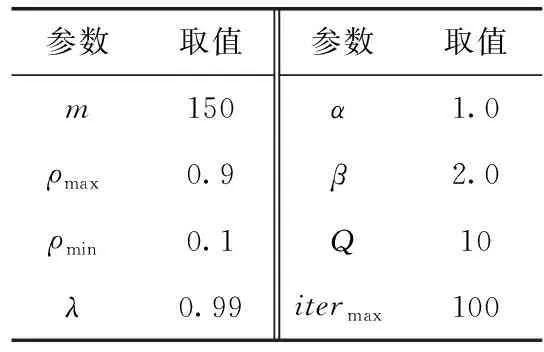
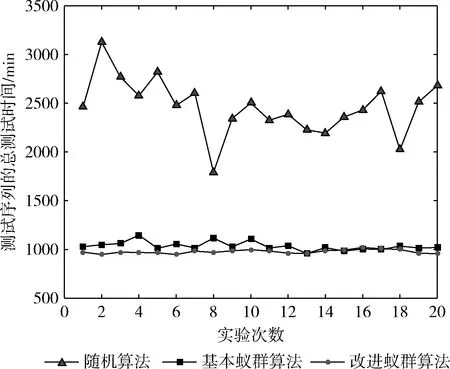
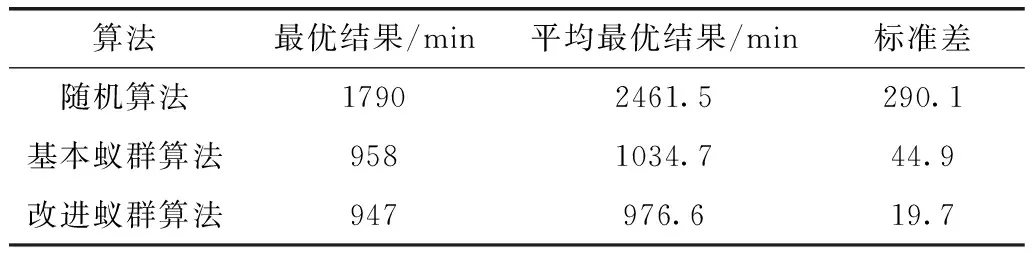
p(sj)≥p(sk),ifrj=1,rk=1,j ∀j,k∈[1,M] (5) 式(1)为目标函数,表示最小化测试时间;式(2)表示测试完备性约束,即测试序列S需能对所有的测试案例执行测试;式(3)表示测试序列S中的所有测试案例均来自测试案例集合A;式(4)表示测试序列S中的任意两个相邻测试案例sj和sj+1需满足状态一致性;式(5)表示测试优先级约束,即优先级高的测试案例应在优先级低的测试案例之前安排测试。 对于测试案例集合,不妨以各个测试案例状态为顶点,以测试案例为弧,构建带权的、具有多重弧的有向图G=(V,A),如图3所示。图G中每条弧具有权值和优先级,其中权值为对应测试案例的执行所需时间,优先级值为对应测试案例的测试优先级。则测试序列S={s1,s2,…,sM}等价于图G中的一条路径L,且S中的测试案例sj对应于路径L中的一条弧。对测试案例sj执行测试,可视为对路径L中的对应弧执行服务。在测试序列S中,如果sj为测试项,则对应弧在路径L中称为服务边,其服务费用为t1(sj);反之如果sj仅作为状态转换项,则对应弧在路径L中称为走行边,其通过费用为t2(sj)。 图3 以测试案例为弧构建有向图G 设测试案例集共有K个测试优先级,令弧集合A=A1∪A2∪…∪AK,其中Ai表示优先级为i的弧集。为保证按测试优先级顺序构建测试序列,针对测试优先级p 经过上述变换之后,测试序列的优化生成问题等价于:在上述有向图G中,寻求一条可对图G中的所有弧按优先级顺序执行服务的路径L,且路径的总费用最小。此问题即为有向图上的分层中国邮递员问题(hierarchical chinese postman problem,HCPP)。1992年Gélinas证明[8]:有向图上的分层中国邮递员问题是NP-hard问题。当图的节点规模较小时,该问题可以使用穷举法或传统的经典法求解,但当节点规模增大时其计算量将呈现爆炸式增长。考虑到STP系统的逻辑复杂性,上述有向图G将非常庞大,此时只能利用启发式搜索算法来寻求较优解或满意解。 当使用蚁群算法优化生成测试序列时,由于其中的某些测试案例可能需要重复出现多次,这将导致蚂蚁搜索过程中的禁忌表无法建立,本文通过构建图G′来避免此问题。具体方法如下: 图4 由图G生成图G′示例 由于STP系统的所有测试案例状态均可从未上电状态转换得到,也均可回到未上电状态,故各个测试案例状态之间均可达,所以有向图G′中任意两个顶点之间必然存在双向的有向弧,即有向图G′是全连通图。 在图G′中将路径的费用定义为:途经的各条弧及各顶点的权值之和。于是测试序列优化生成问题再次等价于:在图G′中寻求一条路径L′,使该路径可按顶点优先级顺序经过有向图中各个顶点至少一次,且路径的总费用最小。此为一个类似旅行商问题。 为计算3.1中有向图G′每两个顶点(v′i和v′j)之间有向弧(i,j)的权值,需计算图G中从测试案例ai的结束状态转换为测试案例aj的起始状态所需的最短路径。可使用Floyd最短路径算法[9]求取图G中任意两个顶点之间的最短路径。此最短路径体现的物理意义为:在考虑测试时间成本的前提下,为实现指定的测试案例状态转换,应依次执行哪些测试案例。 在3.1中已将测试序列优化生成问题转化为一个类似旅行商问题,该问题可通过蚁群算法来寻求一个较优解。蚁群算法是一种用来在图中寻找优化路径的机率型算法。该算法具有分布式计算、正反馈等优点,但也存在收敛速度慢、容易陷入局部最优解等缺点[10-12],对此,本文通过动态调整信息素挥发系数并引入邻域搜索机制,以期增强算法的全局搜索能力,加快算法收敛速度。 3.3.1 蚂蚁状态转移策略 设测试案例集共有K个测试优先级,令上述有向图G′中顶点集V′=V′1∪V′2∪…∪V′K,其中V′i表示优先级值为i的顶点集。为保证按优先级顺序生成测试序列,蚂蚁总是先遍历V′K中的顶点,之后再遍历V′K-1中的顶点,依此类推。 设蚁群共包含m只蚂蚁,在图G′中蚂蚁k(k=1,2,…,m)依据弧上的信息素浓度以概率的方式选择步进方向,采用禁忌表tabuk来记录其已经走过的顶点,并使用levelk记录当前的顶点优先级。在t时刻,蚂蚁k从顶点i向顶点j移动的概率为 (6) 当蚂蚁k遍历完当前优先级的顶点集,此时allowk为空,若levelk>1,则令levelk←levelk-1,并开始遍历下一个优先级顶点集;否则,蚂蚁k此轮路径搜索完毕。 3.3.2 信息素更新策略 在一轮搜索之后,对图G′中弧(i,j)上的信息素按如下方式进行调整 (7) (8) 信息素挥发系数ρ影响算法的收敛速度和全局搜索能力,其值过大,则搜索过程接近于随机搜索,算法收敛速度慢;相反,其值过小,则全局搜索能力偏弱,易陷入局部最优解。基本蚁群算法采用固定的挥发系数ρ,存在难于平衡收敛速度与全局搜索能力的问题,为此,本文对挥发系数ρ引入动态调整策略:在算法早期,使用较大的挥发系数,以获得较强的全局搜索能力;在算法后期,使用较小的挥发系数,以加快收敛速度。具体调整方式为 ρ(t)=ρmin+λt(ρmax-ρmin) (9) 式中:ρmax和ρmin为预先定义的常数,分别表示允许的挥发系数最大值和最小值;λ为(0,1)范围内的常数,表示挥发系数的变化率。 3.3.3 2-OPT邻域搜索 从式(6)可知路径上的信息素浓度越高则后续蚂蚁选择该路径的概率越大,但是当某条路径上的信息素浓度过高时,大量的蚂蚁在此路径上聚集,导致不能及时进行进一步的路径搜索,从而影响全局搜索速度,甚至陷入局部最优解。为了改善此种情况,在蚁群完成一轮路径搜索后,对该轮迭代得到的最优解引入2-OPT邻域搜索机制[13]: 设该轮迭代得到的最优路径为L′min,随机选取一个测试优先级值q(q∈[1,K]),然后以遍历的方式交换路径L′min中属于优先级q的任意两个顶点的位置,每次交换后得到一个新的路径,如果发现新路径长度更短,则使用新路径替换原L′min。 上述2-OPT邻域搜索机制对于蚁群算法而言实际是引入了一种“突变”机制,使得算法搜索过程可及时从局部极值点中跳出。 3.3.4 算法步骤 步骤1 参数初始化,设置蚁群规模m、信息素挥发系数ρmax和ρmin、信息素挥发系数变化率λ、信息素相对重要程度α、能见度相对重要程度β、最大迭代次数itermax,并置初始迭代次数iter=1,令有向图G′中每条弧上初始的信息素τij(t)=const; 步骤2 将m只蚂蚁随机放置到图G′中最高优先级顶点集V′K的各个顶点上。然后对每只蚂蚁按照3.3.1状态转移策略确定下一个要前往的顶点,并移动蚂蚁到该顶点中,重复该过程直到m只蚂蚁都访问完图G′中的所有顶点; 步骤3 针对每只蚂蚁计算路径长度,并挑出当前迭代次数下的最短路径L′min; 步骤4 针对L′min,按3.3.3执行邻域搜索; 步骤5 依据式(7)~式(9)更新图G′中各条弧上的信息素; 步骤6 若iter 通过3.3可以得到图G′中按照优先级顺序经过各个顶点且总费用最小的路径L′,设路径L′中的各个顶点(即测试案例)依次为(a1,a2,…,an)。针对L′中相邻的两个测试案例ai和ai+1(i∈[1,n-1]),设测试案例ai的结束状态为vi,测试案例ai+1的起始状态为vj。在执行完测试案例ai之后系统处于状态vi,为了能执行测试案例ai+1,需要将系统状态从vi转换为vj。而在3.2中,我们已经求得此状态转换需要依次执行哪些测试案例(b1b2…bm),将这些测试案例插入到上述L′的ai与ai+1之间(图5),即可得到最终的、优化后的测试序列。 图5 合成测试序列 为验证文中算法的有效性,针对包含150个测试案例的STP系统测试案例子集,由测试人员依据经验划分为5个测试优先级,并基于以往测试过程统计出各个测试案例的执行所需时间,然后在Matlab2015a环境中使用文中的算法优化生成测试序列。实验时使用的参数见表1。 表1 参数设置 为验证算法性能,分别使用随机算法、基本蚁群算法和改进蚁群算法生成测试序列,各实验20次,统计生成的测试序列的总测试时间,实验结果如图6所示。针对各算法,分别统计实验的最优结果和平均最优结果,并计算标准差,结果见表2。从实验结果可以看出:①相较随机算法而言,基本蚁群算法和改进蚁群算法均大幅度缩减了测试序列的总测试时间,从各次实验的平均最优结果来看可分别节省58%和60%的测试时间,均呈现出良好的优化效果;②改进蚁群算法的各次实验最优结果(947 min)和平均最优结果(976.6 min)均优于基本蚁群算法(958 min和1034.7 min),即改进蚁群算法呈现出更好的全局搜索能力;③相较随机算法和基本蚁群算法而言,改进蚁群算法的各次实验结果标准差更小,即各次实验的结果一致性更好,算法整体表现更平稳。 图6 各次实验结果 表2 算法对比 图7展示了基本蚁群算法和改进蚁群算法的迭代对比情况。可以看出,基本蚁群算法在63次迭代后收敛到最终结果;而改进后的蚁群算法在38次迭代后即收敛到最终结果,且计算得到的最终结果要优于基本蚁群算法。可见文中信息素挥发系数动态调整策略和2-OPT邻域搜索机制的引入,有效增强了算法的全局搜索能力,并且加快了算法的收敛速度。 针对当前STP系统测试序列主要由测试人员凭借经验人工生成的现状,本文研究了测试序列的优化生成方法。在考虑被测功能优先级的前提下,设计了以最小化测试时间为目标的优化模型,并将其转换为求解有向图上的分层中国邮递员问题,此为一个NP-hard问题。提出了一种基于改进蚁群算法的测试序列优化生成方法,并且针对基本蚁群算法收敛速度慢、容易陷入局部最优解等缺陷,通过动态调整信息素挥发系数并增加2-OPT邻域搜索机制,有效增强了算法的全局搜索能力,加快了算法收敛速度。最后通过仿真实验验证了算法的有效性。 文中提出的测试序列优化生成方法具有一定的普适性,可适用于其它铁路信号系统的测试序列优化生成。但也存在一些不足,比如优化生成测试序列时只考虑了测试案例的执行所需时间,而未考虑测试案例的操作复杂度,故未来可继续探索测试序列的多目标优化生成问题。3 算法设计
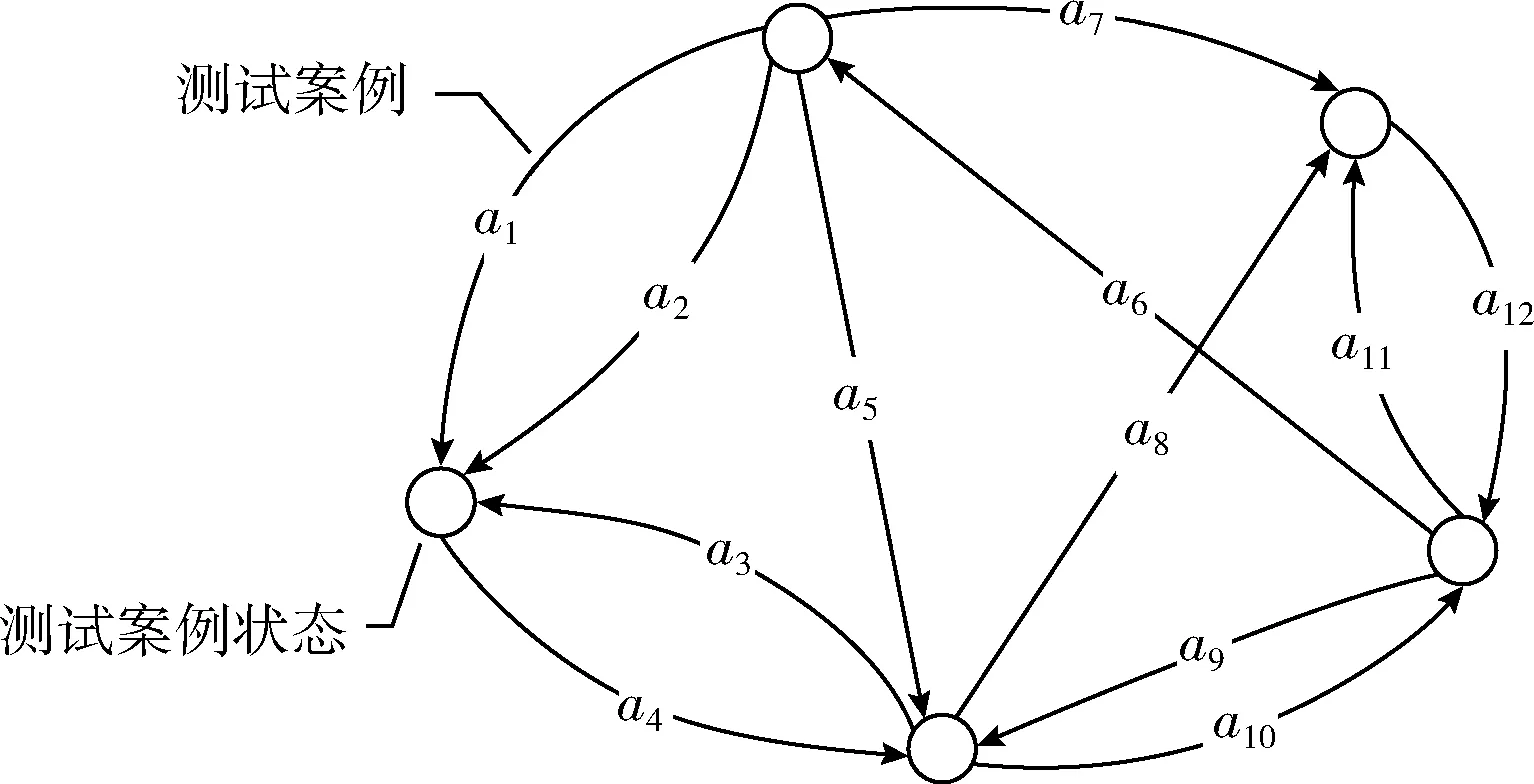
3.1 转化为类似旅行商问题
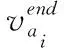

3.2 计算测试案例状态转换最短路径
3.3 使用改进蚁群算法优化测试序列
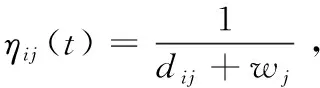
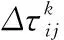
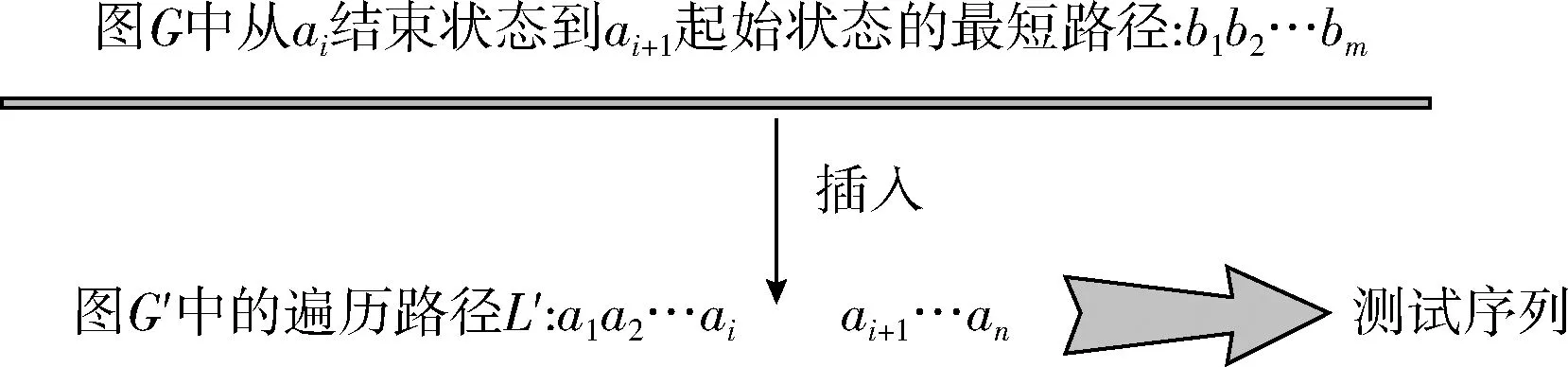
3.4 测试序列合成
4 仿真实验
5 结束语
