基于DenseNet自然场景文本检测
2020-09-04刘会江
刘会江,曾 浩,陈 阳
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
随着深度学习的快速发展,当前自然场景下的文本检测与识别在计算机视觉中也引起了更多的关注[1,2]。对于传统的OCR技术而言,要求检测的背景清晰、简洁、简单。检测的文字要求大小相互均等,文字与文字的间隔适中。只有在苛刻的条件要求下,传统的OCR技术才会检测好的结果,这就限制了传统OCR技术的应用。而自然场景的图片文本会受到许多不可控制因素的影响,比如图片清晰度、光照强度、拍摄角度、字体间的间隔与大小等。正是由于文本图片背景的不可预测性,如果直接把传统的OCR技术运用到对自然场景文本图片检测与识别上,会导致检测困难程度增加,识别效果不好,鲁棒性很差。
从2012年开始,深度学习获得快速的发展。AlexNet[3]神经网络到DenseNet[4]神经网络再到SeNet[5]神经网络,神经网络层级越来越深,结构越来越复杂,效果也越来越好。现在OCR技术的研究也转向了深度学习方向。基于深度学习的OCR算法比传统的OCR算法准确率上得到了很大的提升。但是前人基于深度学习的OCR算法运用在自然场景的文本检测与识别上面,准确率与召回率还有进一步的改良空间。
本文提出了一种基于DenseNet网络作为基础网络的DenseText网络模型。DenseNet网络的核心模块dense block的设计使得网络虽然有很深的网络结构,但是参数量更少、网络更窄。对缓解梯度下降问题,加强特征传播与特征重用等具有优势。同时这种dense block模块使得特征和梯度的传递更加有效,网络也易于训练。
1 相关工作
研究工作者早在上个世纪90年代就对自然场景文本检测展开了关注。主要通过颜色聚类的方法来划分目标区域,或者通过提取目标的纹理特征来进行文本检测。随后,Huang等[6]提出了最大稳定极值区域算法(MSER),Rathod等[7]提出了笔画宽度变换算法(SWT)。
基于深度学习的目标检测算法也历经变化,分为Two-stage与One-Stage。Two-stage算法代表网络是RCNN系列。开始版本R-CNN[8]算法,利用选择性搜索(Selective Search)从图像提取2000个候选区域(Region Prosal),最后送入分类器支持向量机(SVM)[9]输出结果。2015年,Girshick又提出了Fast R-CNN[10]算法。同年,Girshick和Ren等又提出了Faster R-CNN[11]网络,大大提高了检测精度。One-Stage算法代表网络如:SSD[12]、YOLO[13]、YOLO9000[14]等。One-Stage算法的优势提升检测速度。基于以上这些通用的目标检测方法,研究者通过对这一些方法改进使其适用于自然场景文本检测。2014年,Jaderberg等[15]借鉴R-CNN边界框回归算法提出了基于区域建议机制的文本算法。2016年,CTPN算法[16]被提出来了,使用VGG为基础网络进行检测,结果输入到BiLSTM[17]再经过转录层输出识别结果。2017年以后,更多自然场景文本的检测算法被提出来,EAST[18]、SegLink[19]、Textbo-xes[20]、Deep TextSpotter[21]等基于目标检测或者目标分割算法的改进,使其能够适应于自然场景的文本检测。
一般基于文本识别的算法分为两种:①基于字符识别,②基于序列识别。传统上,基于字符检测一般使用人工设计的算子提取特征(HOG[22],SIFI[23])。Rodriguez等[24]通过把识别问题转换成为检索问题,把文本字符嵌入到公共向量子空间中。Yao等[25]通过笔画特征在HOG特征谱上面进行滤波操作得到响应谱,然后在通过分类器Random Forests[26]进行分类。在基于深度学习识别中,Zhang等[27]构建了一个卷积神经网络来对英文的62个字符使用滑窗技术进行判别。而Alrnazan等[28]把单词图像设置为固定长度,再利用编码空间进行特征表示与识别。
基于字符识别的缺点很明显,需要非常大的分类网络,特别是是像中文这种字符,会造成训练困难等问题。现在更常用的是基于序列识别的方法。基于序列识别是利用循环神经网络来进行识别。循环神经网络代表性网络是LSTM[29]网络。Shi等[30]利用CNN网络提取文本特征,再使用BiLSTM网络获取上下文信息,最后加入一个转录层用来进行结果输出。另外还有一种基于编码-解码-注意力模型(EDA)模型,先把序列编码成固定长度的向量,再把固定长度向量进行解码,变成输出序列。其中Lee等[31]的R2AM结构以及Ghosh等[32]的结构都是根据编码-解码-注意力模型而提出来的。
2 DenseText文本检测模型
2.1 DenseText layers层
本文提出的基于DenseNet自然场景文本检测是一个端到端可训练的网络。本论文设计的网络与SSD网络的思想类似,对不同的层进行不同卷积大小的映射,能够得到不同尺度的特征图,网络示意图如图1所示。SSD网络采用VGG-16作为基础网络。保留了conv_1层至conv4_3层,并把最后两个全连接层换成卷积层,即conv_6层至pool11层。本文采用DenseNet作为基础网络,取前conv_4层,同样增加了一些卷积层与池化层,并在conv_5层后面增加卷积层进行不同尺度的输出。最后,在进行后处理前增加一个文本框层,也就是DenseText layers,用来聚合所有层的输出。总体来说,整个网络结构只包含卷积层和池化层,可以对任意大小的图像文本进行训练。
DenseText layers是进行文本框回归的核心组件,进行边框的回归以及文本的预测。对于每一个特征映射的位置,通过卷积运算把文本分类的得分以及边框的偏移量输出到相关联的默认框。假设特征图的中心位置为(i,j),默认框设为b0=(x0,y0,w0,h0),DenseText layers则是用来预测偏移量的值(Δx,Δy,Δw,Δh),置信度为c,边界框b预测值为b=(x,y,w,h)。预测值、偏移量、真实值三者之间关系如下
(1)
为了能够检测多尺度文本图像,每一个特征层都有不同大小与比率的默认框。遍历每一个默认框与实际框的IOU进行匹配。由于单词的自身特点,为此我们设计6个纵横比,分别为1、2、3、5、7、10。但是这就会导致默认框在水平方向上表现的更加密集,竖直方向上面则表现稀疏。就会匹配不到最佳的默认框,或者出现最佳默认框不能够完整回归整个文本图片,导致竖直方向上面检测结果不良。参考Textboxes结构,为此我们对每一个默认框都设置垂直偏移量(如图2所示)。图中只绘制部分的纵横比,在4*4的网格上面,正方形框表示纵横比为1的默认框,长方形框表示纵横比5的默认框。虚线加粗正方形框为实线加粗正方形框的垂直偏移量。虚线长方形框为实线长方形的垂直偏移量。
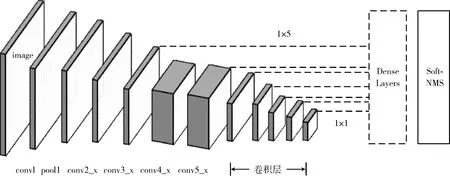
图1 基于DenseNet网络改进的DenseText网络模型

图2 垂直偏移量
对于通用目标检测算法而言,检测目标一般具有明显的边界,对不同大小的目标设置不同的纵横比与比率,把物体边界检测出来再进行回归,输出结果。但对于自然场景文本图像而言,图像文本并没有明显的边界,且文本图像的中的单词具有本身的特点,像英文单词与中文句等语言,一般都是长条形,表现的特点是水平方向比较密集,竖直方向比较稀疏。针对此特点,我们使用1*5的卷积核(最后一层使用1*1卷积核)代替一般目标检测中使用的3*3卷积核。长方形卷积滤波器产生的接收域能够更好适应图像文本的特点,且能够避免方形滤波器带来噪声的影响。
2.2 损失函数
我们使用了与SSD相同的损失函数。x的取值为1或者0,当xi,j=1表示第i个默认框与第j实际框相匹配,反之表示不相匹配。总目标损失函数由两部分组成,分别为位置损失和置信度损失,公式如下
(2)
其中,N表示默认框与实际框匹配的数量。如果N=0,则损失函数设置为0。c表示置信度,l表示预测框位置,g表示地面真实框位置。位置损失函数则是预测框(l)与地面真实框(g)参数之间的Smooth L1损失[14]。置信度损失是采用softmax损失。
2.3 Soft-NMS算法
通用目标检测算法通常都会用非极大值抑制算法(non-maximum suppression,NMS)对大量的候选框进行后处理,删除冗余的候选框,得到一个最佳的检测框。NMS算法的原理,选取得分最高的候选框依次遍历所有剩余的候选框求IOU(人工为IOU设定一个阈值Nt),把大于该阈值的候选框强制性置为0。这样会产生两个问题:①如果被置为零的候选框内存在目标,就会造成对该目标检测失败,并降低检测率。②NMS的阈值不容易确定,阈值设置小就会出现误删,阈值设置过大就会增加误检风险,增加了算法假阳性。
基于NMS算法存在的以上问题。本文将使用Soft-NMS[33]算法对后处理进行改良。Soft-NMS算法的原理是,如果得分最高的检测框与剩余候选框IOU大于阈值,那么该候选框就会有很低的分数,并不会像NMS算法那样直接把候选框置为零。如果该检测框与遍历剩下的候选框的IOU低于已设定的阈值,那么对检测得分分数并不会有很大的影响。并且Soft-NMS算法不会增加额外的参数与训练量,易于实现。该算法得分重置函数有两种计算方式,分别为线性加权函数式(3)和高斯加权函数式(4)。
线性加权
(3)
高斯加权
(4)
2.4 识别模型
目前文本识别主要包括两个方向,基于字符/单词的识别和基于文本序列的识别。基于字符/单词的识别一般采用人工设计的算子(或者CNN网络)进行特征提取,再使用分类模型完成字符的识别。基于文本序列识别的算法一般采用两种常用的识别模型,EDA模型和CNN+BiLSTM+CTC[34]模型。
本文所采用的识别网络CRNN就是一种CNN+BiLSTM+CTC模型结构。CRNN是一个特征提取、特征建模以及转录为一体的神经网络框架。CRNN网络具有能够实现端到端训练、能处理任意长度的序列且不限于任何预定词汇等优点。一般的步骤是用CNN网络对自然场景文本图像进行特征提取,再用BiLSTM(bidirectional long short-term memory)网络对序列上下文信息进行捕获,并对序列进行标注,最后将BiLSTM网络每帧预测转换成为标签序列,并采用CTC作为损失函数进行网络的优化。
CRNN的转录方式是按照每帧预测yi对标签序列l定义概率,并且忽略l中每个标签所在的位置。条件概率被定义为由映射到l上所有概率的和,参看式(5),转录公式如式(6)所示
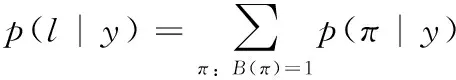
(5)
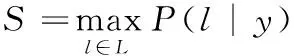
(6)
3 实验结果
3.1 数据集
ICDAR[35]:ICDAR数据集是举行文本检测与识别竞赛的公开数据集,包含训练(training)与测试(testing)两个子集。本文使用的是ICDAR2013数据集,主要针对水平方向的文本检测。该数据集标注效果好、准确率高。
Synth Text:Synth Text数据集不是现实中的图片,是将单词与自然图像进行合成的图片。该数据集包含了80万个图像,大约有800万个合成单词。每一个文本目标都对文本字符串、字符以及字符边界框进行标注。本实验使用该数据集进行预训练。
3.2 训练细节
本文训练的图像尺寸为300*300,使用随机梯度算法(SGD)进行训练。初始学习率设置为10-3,当迭代了4万次以后学习率设置为10-4。动量设置为0.9,权重衰减设置为5×10-4。本文DenseText网络模型先在Synth Text数据集进行预训练,然后在ICDAR2013数据集进行微调。对所有的图片都采用随机裁剪和翻转的方式进行数据增强。实验的设备使用两台GTX 1080在PC端进行实验。识别的模型采用CRNN网络。
3.3 评估验证
本文实验的评估标准参数主要依赖于如下3个参数:准确率(P)、召回率(R)和F-measure(F),具体公式计算如下
(7)
(8)
(9)
其中,TP表示将正样本预测为正样本数目,FP表示将负样本预测为正样本的误报数,FN表示将正样本预测为负样本的漏报数目。准确率(P)与召回率(R)之间可能会出现矛盾的情况,其中一个测试指标较高,而另外一个测试指标较低。这时就需要综合考虑两者指标的情况,就采取F-measure评估方法。
3.4 检测结果评估
DenseText在ICDAR2013数据集上进行了测试,评估该模型的性能。如表1所示,在准确率(P)上面表现出良好的性能结果,召回率(R)的表现结果比前人的结果都要优异。对于准确率与召回率之间平衡的检测指标F-mea-sure,我们的网络表现出来的结果也比前人的结果更加的优秀。
如表1所示,为了进一步验证我们DenseText层的有效性,我们也把目标检测的优秀网络SSD与Faster R-CNN网络与我们网络进行同等环境的实验。在IC13 Eval与Det Eval进行测试,实验结果表明,直接把目标检测的网络运用到自然场景的文本检测效果并不理想,特别是召回率很低,存在很多假阳性框。而我们的网络则表现出来更加优秀的结果,验证了对网络改良的必要性。对比选用VGG16作为基础网络TextXBoxes,我们则选用DenseNet网络作为基础网络,实验结果表明DenseNet网络能够提取更多的细节特征,网络有效性比VGG网络更好。对比当前水平检测效果最好的CTPN网络,我们的准确率比它低了0.03,但是我们的召回率结果比CTPN网络的召回率更加优秀,召回率高了0.02。

表1 水平方向文本检测对比结果
综上所示,我们网络的准确率是表现结果最好的网络之一,我们的召回率则比之前的网络都要优秀。原因之一是我们的网络还使用Soft-NMS算法对后处理进行改进。传统方法都是使用NMS进行后处理,如果候选框与得分最高框的IOU大于设定的阈值,就把该候选框直接置为零。这样会增加检测假阳性,降低结果的准确率。为了验证我们使用Soft-NMS算法代替传统的NMS算法能够在召回率表现更好的效果,我们在ICDAR2013数据集进行测试。对Soft-NMS(G)表示高斯加权、Soft-NMS(L)表示线性加权、传统的NMS算法进行了实验对比(见表2)。

表2 后处理对比实验结果
为了更好测试效果,固定高斯加权系数σ并设置为0.5,分别在阈值Nt取值0.3、0.5、0.7下进行实验。实验结果表明,在同等条件下,不管是高斯加权还是线性加权的Soft-NMS算法的召回率比NMS算法的召回率都要高。对于Soft-NMS的两种加权方式,采用高斯加权的表现结果比采取线性加权的表现结果要优秀。当Nt取值为0.5时召回率的比在Nt取为0.3和0.7表现的更高。综上所述,我们采取Soft-NMS算法进行后处理的结果比采取NMS进行后处理的结果表现的更加优秀,能够提高网络的召回率。
对自然场景文本图片的部分检测与识别结果如图3所示。图3前两排是检测结果:我们可以观察到不管是对图片中大跨度单词、小文字单词或者是数字,都能够很好检测出来,具有良好的泛化性。图3第三排,是用CRNN网络识别的结果,当DenseText网络能够检测出来很好的结果的时候,CRNN网络大部分能够识别出来。但是我们注意到,最后一张图片中的Farm单词,尽管被很好检测出来了,但是却被CRNN网络识别成rarm单词。下一步的研究工作,改良网络使其对任意方向文本图片有较好检测率,并改善网络的识别率。

图3 水平方向自然场景文本图片的检测与识别结果
4 结束语
由于自然场景图片文本的多样性与复杂性,并容易受到光照、文字跨度等不可控因素的影响,难度远远大于传统OCR技术。本文提出一种基于DenseNet为基础网络的DenseText文本检测算法。为了适应文本的特点,使用长方形的卷积核代替传统的正方形卷积核,并且用Soft-NMS算法进行后处理,能够有有效提高文本检测的准确率。最后使用CRNN网络进行识别。形成一个端到端的自然场景文本检测与识别的系统。实验结果表明,本文提出的算法准确率上表现出优异的结果,特别是召回率较前人结果有显著的提升。
