基于深度特征和Seq2Seq 模型的网络态势预测方法
2020-09-04林志兴王立可
林志兴 ,王立可
(1. 三明学院网络中心,福建三明365004; 2. 福建师范大学数学与信息学院,福州350007;3. 中国科学院成都计算机应用研究所,成都610041)
0 引言
网络态势是由各种网络电子设备运行状况、网络行为和用户行为等因素构成的整个网络的当前状态和变化趋势[1]。网络态势预测尤其是入侵检测是网络安全中的一个核心问题。将机器学习和深度学习算法引入网络态势预测中可以有效地识别异常和可疑活动,实现高效、准确的网络入侵检测,可以解决三类网络态势任务,分别是:异常检测与攻击分类、加密攻击检测和零日漏洞检测。异常检测与攻击分类指的是利用网络通信协议自身存在的缺陷、用户终端操作系统缺陷入侵网络;加密攻击指的是利用加密技术来逃避防火墙和入侵;零日漏洞指的是被发现后立即被利用的安全漏洞,也称零时差漏洞[2]。
网络态势检测可分为三类:基于网络的入侵检测、基于主机的入侵检测和混合的入侵检测[3]。基于主机的入侵检测系统通过监视多个主机并检查网络流量来检测单个计算机上的恶意活动。基于网络的入侵检测通过检测网络流量来识别入侵。在基于网络的入侵检测中,传感器位于网络的瓶颈处,用于执行监视,通常是在非军事区或网络边界上,并且捕获所有的网络流量。混合的入侵检测通过分析应用程序日志、系统调用、文件系统修改和其他主机状态和活动来检测入侵[4]。混合的入侵检测指的是多种技术(如路由器和防火墙)一起使用,并根据多种行为数据[5]进行决策。
进行入侵检测时最重要的一个过程就是从原始网络数据中提取出流量的行为特征,行为特征可以分为统计特征、时序特征、协议特征和有效载荷特征四种。统计特征是整个网络数据流中通过统计结果得出的,比如某个主机请求次数、域名系统(Domain Name System,DNS)服务器接收的数据包个数等,Rughan 等[6]的研究验证了统计特征用于分类可以得到较高精度的结果,模型在服务类型分类中仅5.1%错误率。时间序列特征指的是数据包长度的序列、到达间隔时间序列和连续数据包的方向等,Yin等[7]使用数据包持续时间等特征在循环神经网络的模型进行分类,并在KDD(Knowledge Discovery and Data mining)的公开数据集上取得了很好的结果。协议特征指的是通过提取网络协议中的字段而得到的特征。有效载荷特征即通过提取基于TCP/UDP 传输中数据包的特定负载而获取的特征。基于数据包载荷的检测方法可以通过有效载荷特征来识别数据包[8],即能够通过深度学习方法提取攻击流量的有效载荷中隐含的特征信息,进而识别异常流量。Yuan 等[9]使用连续流序列提取多个区域,并按照长度滑动的时间窗生成三维特征图,准确率比传统的机器学习方法高了5%。
近年来,Seq2Seq(Sequence to Sequence)模型由于其出色的表现除了在机器翻译[10]任务中取得了非常显著的效果以外,在其他领域也有了广泛的应用,如:Seq2Seq模型结合注意力机制在文本摘要任务取得了突破,2016 年 Nallapati 等[11]就使用该模型在两个不同数据集上的评分均打破了历史记录;在自动对话任务中,清华大学周昊等[12]利用Seq2Seq 模型与给定的上下文相关向量和情感选项(比如:开心、忧伤等)生成了与之对应情绪的回复;在中文诗词生成任务中,Wang 等[13]在Seq2Seq模型的基础上提出了Planning 模型,可以保证后面几句诗词在生成时与诗词主题相关;陶涛等[14]将Seq2Seq 模型用到了加油站时序数据异常检测中,取得了不错的效果;近日,Facebook 人工智能研究院的 Lample 等[15]更是将该模型应用到了数学统计和近似问题中,这种模型的性能要远超现在常用的能进行符号运算的工具,例如Mathematica、Matlab、Maple等。
尽管目前的网络态势检测方法取得了不错的效果,但仍然存在很多问题,尤其是在特征构造上,目前的特征构造是完全基于人工的,这需要网络安全维护者手动构造特征,这些特征的构建完全是人类直觉驱动的,并不能提取网络数据中的深层次特征,而且目前网络态势检测方法没有充分利用网络数据中的时序特征,这往往会使预测结果不尽人意。这些问题都是目前急需解决的,因此本文提出了网络态势预测方法DFS-Seq2Seq,以有效地解决上述问题。
1 相关工作
1.1 深度特征合成算法
深度特征合成(Deep Feature Synthesis,DFS)算法[16]是可以直接从关系数据集中自动生成大量深度特征的算法。DFS能够针对数据库或日志文件中常见的多表格数据集和交易数据集自动抽取融合大量特征。该算法的输入是有关系相关的一组实体,算法定义了多种数学函数使用三种方式生成特征,这三种方式分别为efeat、dfeat、rfeat。上面描述的相关表示和定义如下:
实体(Entity)表示为 E1,2,…,K,每个实体中都有唯一标识,每个实体中有J个特征表示第k个实体的第i个实例特征j的值。三种类型的特征计算方式分别为:
1)efeat:依次对 xi,j′应用计算函数。直接计算每个属性的值合成特征,这些特征可由式(1)表示:

2)dfeat:相关实体 e ∈ Ek中的特征被直接转移为 m ∈ Ek的特征。

算法为给定实体合成的特征数量z由式(3)给出:

算法的目的就是为实体 E1,2,…,K提取生成新的 rfeat,dfeat和efeat特征。同时,和EK具有前向关系的表称为EF(多对一,可以进行dfeat 特征合成),具有后向关系的表称为EB(一对多,可以进行rfeat 特征合成)。深度特征合成算法模型如图1所示。

图1 深度特征合成算法模型结构Fig. 1 Structure of deep feature synthesis algorithm
1.2 自动编码器
自动编码器(AutoEncoder,AE)通过重建输入的神经网络训练过程实现降维。AutoEncoder 通过神经网络的训练后会在隐藏层中得到一个代表输入数据的低维向量[17]。如果它的解码器是线性重建数据,可以用均方误差(Mean Square Error,MSE)来表示它的损失函数,由式(4)表示:
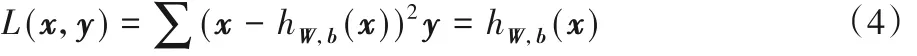
如果解码器选择Sigmoid 作为激活函数,那么AutoEncoder的损失函数如式(5)所示:
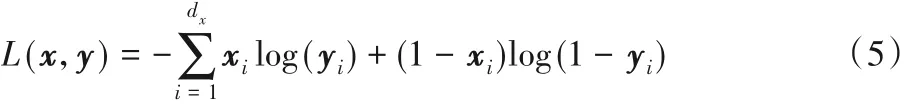
AutoEncoder的模型结构如图2。

图2 自动编码器结构Fig. 2 Structure of AE
1.3 长短期记忆网络
长短期记忆网络(Long Short-Term Memory,LSTM)是一种时间循环神经网络,是为了解决一般的循环神经网络(Recurrent Neural Network,RNN)存在的长期依赖问题而专门设计出来的,RNN 在处理长序列时会出现梯度消失的问题,LSTM 很好地解决了这个问题[18]。LSTM 有三种类型的门结构能够让信息在序列中传递下去:遗忘门、输入门和输出门。LSTM网络结构如图3所示。

图3 LSTM网络结构Fig. 3 LSTM network structure
遗忘门的功能是决定应丢弃或保留哪些信息。来自前一个隐藏状态的信息和当前输入的信息同时传递到sigmoid 函数中去,输出值位于0~1。遗忘门信息传递可由式(6)表示:

输入门的作用是更新细胞状态。首先将前一层隐藏状态的信息和当前输入的信息传递到sigmoid 函数中去,将值调整到0~1 来决定要更新哪些信息。输入门信息传递可由式(7)表示:

输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,将前一个隐藏状态和当前输入传递到sigmoid 函数中,然后将新得到的细胞状态传递给tanh 函数。最后将tanh 函数的输出与sigmoid 函数的输出相乘,以确定隐藏状态应携带的信息;再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。每个LSTM 单元的计算如式(8)~(11)所示,其中σ 和⊙分别是sigmoid函数和元素乘法。

2 DFS-Seq2Seq深度特征网络态势检测方法
2.1 数据处理与算法流程
基于上述网络态势研究现状,本文提出了DFS-Seq2Seq深度特征网络态势检测方法,该方法使用DFS 算法解决了手动特征提取费时费力、容易遗漏且不能提取深层次特征的问题。本文方法选择了两层的双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)网络来构造Seq2Seq模型,可以充分地拟合特征中的前后关系和深层次关系,能大大提升模型的性能。原始数据中的数据格式不统一,如果使用传统特征工程需要手动提取数据中的特征,会浪费大量时间,还可能会产生特征遗漏的现象,所以本文使用了深度特征合成算法自动提取融合特征,先将每个网络端口收集到的数据按照相同的时间间隔划分,然后把来自同一源的数据汇集并抽象成实体,再利用DFS 算法对抽象为实体的数据组进行特征合成,具体表现为前文中提到的efeat、dfeat、rfeat 三种特征合成方式,通过大量的预设特征构建方式可根据不同格式数据自动提取构造大量的特征,从而节约特征工程所消耗的时间,提高模型构造效率。通过DFS 算法得到一个特征集合,该集合内的特征由于是自动合成的,数量非常庞大,可能数百或上千,此时若直接将特征向量作为判别模型的输入会因为维度太大而影响模型效果,因此本文使用自动编码器来压缩特征向量,减少特征向量维度,以提高模型训练速度。在处理数据完成后本文分别针对危险操作与正常操作分类和危险操作持续时间预测分别训练了分类模型和回归模型,整个模型的流程如图4所示。

图4 DFS-Seq2Seq算法流程Fig. 4 Flowchart of DFS-Seq2Seq algorithm
本文中提到的DFS算法具体做法是对清洗过后的数据作深度特征合成,伪代码如算法1所示。
算法1 深度特征合成算法DFS。
输入 网络日志中互连的实体E1,2,…,K;
输出 合成的特征集合F。
1)初始化实体集合 Ei、E1:M、EV。
2)将实体中相关联的实体依照连接关系连接。
3)构造后向关系实体集合 EB= Backward(Ei,E1,2,…,M)和前向实体集合 EF= Forward(Ei,E1,2,…,M)。
4)遍历全部实体,若Ej包含在EB中,则进行rfeat 特征构造且构造的特征并入F。
5)再次遍历全部实体,若Ej∈EV则跳过该实体,否则进行步骤6)~7)。
6)合成构造Ei与Ej相关的dfeat 特征并将合成的特征并入F。
7)对Ei单个集合合成构造efeat特征并将特征并入F。
DFS 算法挖掘了大量网络态势与特征之间的关联,特征集合源自数据集中数据点之间的关系,对于网络中不同数据源点收集到的数据集,很多特征是采用数学运算及函数得到的,比如对一列数据求和、求均值、求方差等,这些与数据集本身无关的操作,定义为基元。DFS 还可以通过先前获取的特征跨实体应用基元派生出来新特征,通过设置搜索的最大深度参数deep可以控制创建特征的复杂度。
在对原始数据进行处理之后产生了大量的特征,这些特征往往是提取的深层次的冗余特征,为了防止冗余特征对模型造成负面影响,本文选择了自动编码器对特征进行降维。同时为了使自动编码器在受到一定程度的扰动时具有不变性,有很多种改进的办法,普遍的做法是对权值进行惩罚,此时AutoEncoder数学表达形式如式(1)所示:

上述改进方法在本文应用中效果并不理想,因此本文使用了Contractive AutoEncoder,它在AutoEncoder 上加入了雅克比矩阵的规则项,具体如式(2)所示:

其中:Jf(x)是关于隐含层输出值权重的雅克比矩阵,而表示的是雅克比矩阵的F范数的平方,即雅克比矩阵中每个元素求平方。

最后求和即可得到如式(4)所示的结果:

如此改进可以使得隐藏层向量对输入数据的微小的变动能够有更强的鲁棒性,增强模型的拟合能力。算法流程如算法2所示。
算法2 DFS-Seq2Seq深度特征网络态势预测方法。
输入 服务器接收的身份验证日志(auth)、计算机与服务器接收进程(proc)、中央路由器接收的网络流事件(flow)、域名系统(DNS)服务器收集的域名服务查找事件(dns)、身份验证数据中获取的特定危险事件(redteam);
输出 每条身份验证日志是否为危险事件及危险事件持续时间。
1)初始化参数DFS算法合成深度deep,一般取值为2~4。
2)日志数据清洗,删除无效、重复、错误日志数据。
3)选择合适的时间间隔对数据进行划分。
4)使用DFS算法对每个时间内的数据合成日志实体的深度为deep的特征。
5)用 Contractive Autoencoder 编码器对步骤 3)中合成的深度特征进行提取。
6)将编码之后的特征向量按照时序排列以保证模型接收数据时为正常的时间序列ordertime(log_id)。
7)使用双层的Bi-LSTM 模型构造判别模型的Encoder,其中每一步的输入为上一步中的特征向量。
8)构造Decoder,在训练过程中,将Encoder最后产生的上下文相关向量作为输入传给Decoder端LSTM的开始。
9)将 Encoder 和 Decoder 连 接 起 来 构 造 Seq2Seq 判 别模型。
10)使用判别模型对日志数据进行判断,找出用户行为中的危险操作。
11)若步骤9)中的预测结果是危险行为,则使数据转到预测时间模型,其模型的构建与步骤5)~8)相似;若判别为安全行为,则转去处理其他日志数据。
12)对危险行为报警并采取相应的应对措施。
2.2 Seq2Seq模型分析与构造
Seq2Seq模型的训练是本文中的关键内容。Seq2Seq模型的主要思路是将一种循环深度神经网络模型作为基本单元,把输入的序列映射为一个向量然后再生成输出序列,这一过程由编码(Encoder)输入与解码(Decoder)输出两个环节组成,前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。一般的Seq2Seq 模型结构如图5所示。
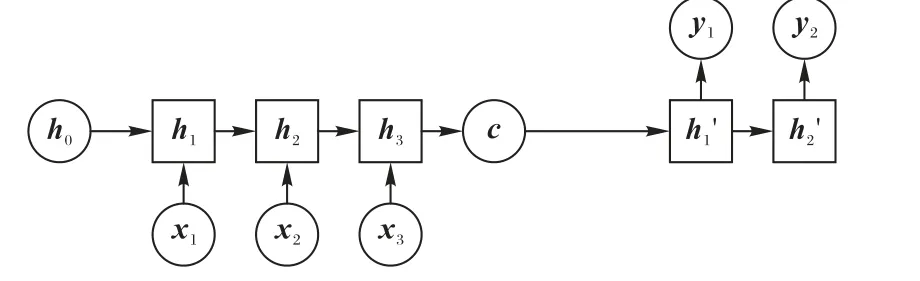
图5 Seq2Seq模型结构Fig. 5 Seq2Seq model structure
X =(x1,x2,…,xn)表示编码器的输入,在本文中是不同时刻原始数据中提取的特征向量;Y =(y1,y2,…,yM)表示解码器的输出,在本文中是判别值或回归值。本文实验中,编码器的隐藏层包含300 个隐藏单元,且每一个隐藏元在t时刻由式(5)~(7)计算:

并且为了简化公式,本文公式皆不考虑偏置项biases,且令初始的隐藏层参数为0。当第N 个特征向量输入编码参与编码后,则可由c = tanh(VhN)计算出上下文相关向量。Encoder 在最后一个输入之后计算出的上下文向量即是Decoder的输入为h′0= tanh(V′c)。
本文使用′来区分在Encoder 和Decoder 之中的各个参数,则在解码器中t时刻的隐层单元可由式(8)计算。
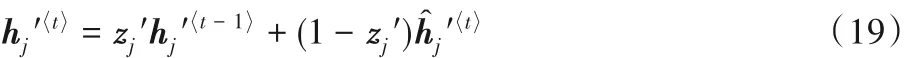
其中:

其中:e(y0)表示全零向量,表示Decoder 的开始;e(y)表示Decoder 每一步的输出结果。与Encoder 不同的是,Decoder 在每一个时刻会依照概率生成标签值,这个值的计算方法如式(12)所示:
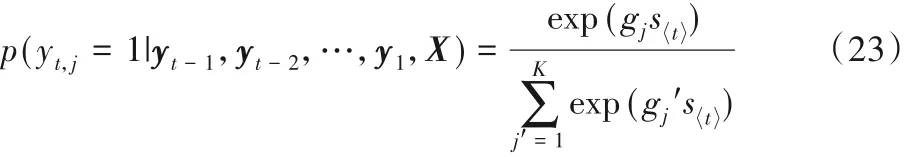
则第i个元素可由式(13)、(14)计算:
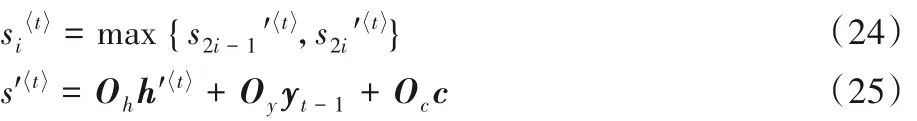
本文中Encoder 的输入序列是不同时刻计算机源提取的特征,这些输入通过编码后在编码器的最后以上下文相关向量c的形式输出,也就是该上下文相关向量c包含了输入序列的信息,在Decoder 部分该向量作为输入参与模型预测,从而模型预测结果是依赖于上下文相关向量的,而向量c 又由输入特征向量编码而来,所以网络异常的预测是依赖于模型输入特征的。
3 实验结果与分析
为了验证本文算法的有效性,采用Python 语言在Windows 平台进行了实现,并进行了一系列的实验验证,其实验环境为:Intel-Core i7-8750U2.20 GHz 处理器,24 GB 运行内存,64 位Windows 10 操作系统。本文使用的数据集为Kent2016,该数据集是从洛斯阿拉莫斯国家实验室的公司内部计算机网络中的5 个来源收集的连续58 d 的未标识事件数据。数据集中包括以下内容:
1)来自单个计算机和集中式Active Directory 域控制器服务器的基于Windows的身份验证事件;
2)来自单个Windows计算机的启动和停止事件;
3)内部DNS服务器上收集的域名服务事件;
4)在几个关键路由器位置收集的网络流数据;
5)一系列定义明确的危险报警分组事件。
数据集删除了知名的管理员账户的标识,但并未删除标识与系统相关的特定用户(系统服务和本地服务);而且在网络流数据中,未删除识别众所周知的端口(例如80、443 等)。关于数据集的描述如表1所示。
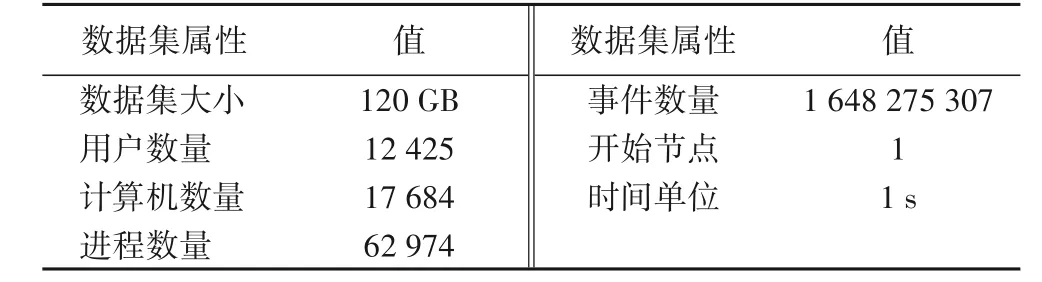
表1 Kent2016 数据集描述Tab. 1 Kent2016 dataset description
为了预测网络态势是否安全,训练了Seq2Seq 分类模型,分类模型中Seq2Seq 训练时Encoder 使用的是时间序列的特征向量,Decoder 的输出为网络是否安全的代表值:本文实验中网络态势健康输出0,即没有危险事件发生;网络态势不健康输出1,即可能会有危险事件发生。当网络态势预测为不健康时,本文训练了回归Seq2Seq 模型预测危险态势持续的时间,该模型与分类模型不同的是:Seq2Seq 输出的是一个值而不是一个二分类结果,该值代表的是危险态势持续的时间。由于模型可以根据历史数据对未来的态势作出预测,所以当网络数据流中产生的日志数据通过分类模型预测结果为1时,就会产生网络预警并通过回归模型预测出危险持续的时间。
基于数据预测网络事件是否为危险事件的模型评价中,本文使用了三个评价指标,分别是:准确率Acc(Accuracy)、召回率Re(Recall)和F1(F1-Score)。首先定义样例总数为N,则真正例TP(True Positive)表示被模型预测为正的正样本;假正例FP(False Positive)表示被模型预测为正的负样本;假负例FN(False Negative)表示被模型预测为负的正样本;真负例TN(True Negative)表示被模型预测为负的负样本。则Accuracy、Recall和F1分别由式(1)~(3)计算:

实验中选取了以下四种常用的分类算法与本文提出的DFS-Seq2Seq模型进行对比:
1)支持向量机(Support Vector Machine,SVM)。利用升维把低维样本向高维空间作映射,使原本在低维样本空间中非线性可分的问题转化为在特征空间中线性可分的问题,寻找一个超平面来对样本进行分割[19]。
2)贝叶斯(Bayes)。利用概率统计知识进行分类的算法,使用贝叶斯定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。
3)随机森林(Random Forest,RF)。用多棵决策树随机地建立一个森林分类器,当有一个新的输入样本进入时,就让森林中的每一棵决策树分别进行判断,然后看哪一类被选择最多,就预测这个样本为哪一类[20]。
4)长短期记忆(LSTM)网络。是一种特殊的RNN,能够学习长期依赖性。LSTM 单元由单元、输入门、输出门和忘记门组成。该单元记住任意时间间隔内的值,并且三个门控制进出单元的信息流。本文采用最常用的LSTM 分类器作为对比实验。
为了使本文算法和其他算法更好地进行对比,本文采用了10 折交叉验证对数据集进行测试和评价,并且在实验之前将所用的数据顺序随机打乱之后再从中随机抽取部分数据进行实验。表2 给出了本文DFS-Seq2Seq 算法采用不同的特征合成深度和其他四种对比算法(SVM、RF、Bayes、LSTM)分别在准确率、召回率和F1-Score 上的实验对比结果,其中deep是在特征合成时所使用的深度,实验中选择了最常用的2层和3层进行实验。
根据表2可以看出:本文提出的算法模型DFS-Seq2Seq在deep= 2 时的准确率较SVM、Bayes 和LSTM 分别提升4.0%、1.5%、1.1%;在deep= 3 时,准确率提升分别为4.3%、1.8%、0.56%。但对于准确率而言,不论deep如何取值,本文DFSSeq2Seq 算法都要低于RF 算法,说明它在准确率上的提升效果并不显著,这是因为数据集中负样本很少,数据极度不均衡,实验中用的对比模型RF 虽看起来准确率较高,但实际上模型并没有拟合数据集,只是将所有样本都预测为正常。本文更关心的是全部的危险事件被模型识别出来多少,需要使用危险事件的召回率,从实验数据中可以看出:在deep= 2时,DFS-Seq2Seq算法比其他四种算法模型的召回率提升分别为 7.4%、11.5%、6.5%、3.0%;在deep= 3 时,提升分别为7.2%、13.1%、6.3%、3.5%。通过这些数据可以看出,在最能说明问题的召回率指标上,DFS-Seq2Seq 算法提升显著,说明该算法对危险事件识别的性能比其他算法模型要好;而在准确率上表现最好的RF模型召回率最差,这也正好印证了之前所说的该模型没有拟合数据的说法。进一步使用F1-Score 评价指标来看:在deep= 2 时,DFS-Seq2Seq 算法的性能比其他四种算法分别提升5.9%、4.4%、6.2%、5.1%;在deep= 3 时,提升分别为5.3%、4.0%、6.1%、4.3%。从这几组数据的对比来看,DFS-Seq2Seq 算法的性能均远远优于对比算法,充分说明了该算法的优势。
为更清晰地展示本文算法训练模型的预测性能,在Accuracy、Recall和F1 下分别设置epoch={1,20,…,200},采用10 折交叉验证法对数据集进行评测,结果如图6 所示。从图6 中可以看出,随着训练迭代次数的增加,模型的准确率、召回率和F1-Score 评价指标均呈现出上升的趋势,且在上升至一定值后,趋于一个稳定的状态,然后随着迭代次数的增加,准确率、召回率和F1-Score 评价又略微下降。这说明实验中的模型通过训练具备了拟合数据的能力,且通过观察准确率和F1-Score 的大小可以看出模型的分类效果很不错;随着训练迭代次数的增加,模型的评价值有所下降,其原因是过度的训练使模型产生了过拟合,所以在实际训练模型时应当选择合适的训练迭代次数。在本文所设计的实验中,迭代次数约为80 时达到最佳,此时的模型准确率为0.891,召回率为0.958,F1-Score 为0.823,模型的评价值达到了最好状态,再继续迭代训练可能会产生过拟合。
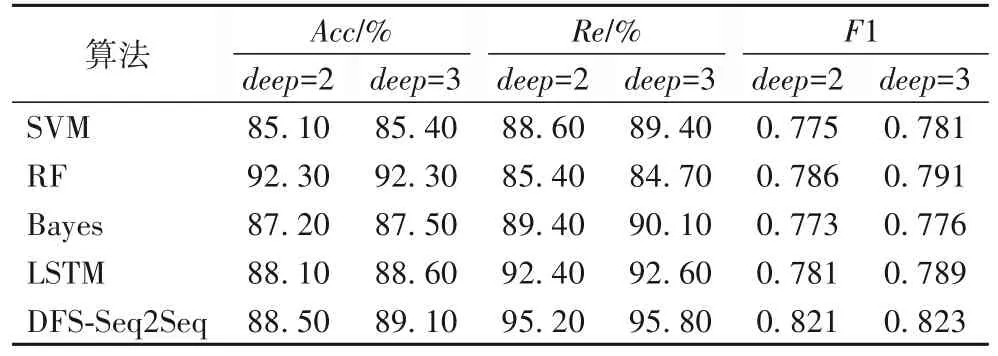
表2 各算法的准确率、召回率和F1-Score评价对比Tab. 2 Comparison of accuracy,recall and F1-score of various algorithms

图6 评价值随迭代次数变化Fig. 6 Evaluation value varying with iteration times
在对危险事件持续时间预测的模型评价中,选择了以下三种经典的回归算法与本文提出的DFS-Seq2Seq 算法作对比:
1)线性回归(Linear Regression)。使用多个独立输入变量(特征变量)和输出因变量之间的关系创建模型,模型保持线性,输出是输入变量的线性组合。
2)多项式回归(Polynomial Regression)。使用一个因变量与一个或多个自变量间多项式的回归分析方法
3)岭回归(Ridge Regression)。目标函数在一般线性回归的基础上加入了正则项,在保证最佳拟合误差的同时,使得参数尽可能地“简单”,使模型的泛化能力更强(即不过分相信从训练数据中学到的知识)。正则项通常采用一、二范数,使得模型更具有泛化性,同时可以解决线性回归中不可逆情况[21]。
基于用户数据预测危险事件持续时间的模型评价中,本文采用了两个经典评价指标,分别是平均绝对误差(Mean Absolute Error,MAE)和决定系数(R-Square),反映了算法预测危险持续时间的准确度。假定用户危险操作持续时间为t_real,持续时间平均值为t_mean,模型对该用户危险操作时间的预测为t_predict,则评价指标MAE 和R-Square 对模型的评价分别由式(4)、式(5)计算:

表3 给出了DFS-Seq2Seq 危险事件持续时间预测模型使用不同的特征合成深度与其他三种回归算法(线性回归、多项式回归、岭回归)在MAE 和R-Square 评价准则下的实验结果。由表 3 数据可知,DFS-Seq2Seq 算法在deep= 2 时在 MAE 评价(MAE 的值越低算法的性能越好)下相较于其他三种算法提升分别为13.5%、7.5%、6.1%,在deep= 3 时提升分别为10.9%、7.4%、6.3%;在R-Square 评价准则(R-Square 值越高算法的性能越好)下,DFS-Seq2Seq 算法在deep= 2 时比另外三种算法性能提升分别为28.0%、20.9%、10.5%,在deep= 3时性能提升分别为28.7%、22.0%、10.4%。通过这组数据和分析可以发现DFS-Seq2Seq 算法在预测危险事件持续时间方面比其他算法有了极大的提升。本文实验还有一个比较有意思的现象就是在采用特征合成深度即deep= 3 时,模型的效果几乎都比deep= 2 时要好一些,这是因为在合成特征深度为3时已经包含了深度为2的所有特征,并且深度的增加挖掘了数据中更多的信息,在实际应用该方法时应选择实体间最深关系深度作为deep的值以保证挖掘到更多数据中的信息。

表3 各算法的MAE和R-Square评价指标对比Tab. 3 Comparison of MAE and R-Square of various algorithms
综上可知,本文提出的DFS-Seq2Seq 深度特征网络态势预测方法使用了DFS算法可以挖掘数据中的深层次信息并合成特征,随后使用本文设计的Seq2Seq 模型可以充分拟合这些数据,从而无论是在对危险事件识别还是在危险事件持续时间预测上均比对比算法更加出色,进一步可以更加有效地对网络中的危险事件进行预测,达到及时阻止网络非法入侵、维护网络安全的目的。
4 结语
维护网络安全一直都是一项十分重要的任务,网络安全可以保证社会的稳定和每个网络用户的隐私不被侵犯。随着网络入侵者的手段变得更加复杂多样,不难发现传统的数据挖掘和机器学习方法在网络入侵检测中是有用的,但在处理网络上的大数据时存在局限性。本文通过将来自不同来源的安全事件通过深度特征合成算法关联起来,并训练优秀的Seq2Seq 模型分别执行危险事件识别分类任务和危险事件持续时间预测任务,可以获得比传统方法更好的网络态势感知。随着移动互联网和大数据时代的到来,网络中的数据量大、数据复杂等问题比以往任何时候都要棘手,这要求不断改进算法、改进模型、改进流程以达到维护网络安全的目的,值得一提的是如今的海量数据中包含了大量文本数据,想要挖掘这部分数据中的信息,必须要使用自然语言处理相关技术,接下来将针对这些问题进一步展开工作,力争创造出适应场景更广阔、更有效的网络态势检测方法。
