动态的加权孪生网络跟踪算法
2020-09-04熊昌镇
熊昌镇,李 言
(城市道路交通智能控制技术北京市重点实验室(北方工业大学),北京100144)
0 引言
计算机视觉是人工智能领域重要的研究分支,其中视觉目标跟踪技术更是重中之重。即在初始帧中确定目标的坐标和尺寸,在后续帧中能够通过跟踪框描述出目标的运动轨迹。该技术运用于安全监控、竞技体育、人机交互等领域。与其他深度学习的跟踪算法相比,基于孪生网络的目标跟踪算法在跟踪速度上有着绝对的优势,因此近年来吸引了众多的研究者,基于孪生网络的跟踪算法也得到了快速的发展。
孪生网络跟踪算法就是衡量模板图像在待检测图像上某一区域的相似程度。孪生神经网络有两个输入,即模板图像和待检测图像,将这两个输入送入两个相同的神经网络,这两个神经网络分别将输入映射到新的空间,形成输入在新空间中的表示;然后通过计算,评价两个输入的相似度。Bertinetto等[1]提出了全卷积孪生网络跟踪(Fully-Convolutional Siamese networks for object tracking,SiameseFC)算法,提取特征的卷积神经网络(Convolutional Neural Networks,CNN)[2-4]离线训练,该网络只有卷积层和池化层,是典型的全卷积神经网络,在线不更新策略,使得跟踪速度可以达到实时,58 帧/s的速度远超其他深度学习的跟踪算法。Guo 等[5]提出了动态孪生网络跟踪(learning Dynamic Siamese network for visual object tracking,DSiam)算法,在SiameseFC 的框架中增加了目标形变和背景抑制层,提高了跟踪器的判断能力。Li 等[6]提出了高效的孪生区域推荐网络跟踪(High performance visual tracking with Siamese Region Proposal Network,SiamRPN)算法,将区域推荐网络(Region Proposal Network,RPN)与孪生网络结构进行了结合,RPN 有两个分支,一路用于区分前景和背景,一路用于对跟踪框的回归,有效地提高了跟踪的精度。Zhu等[7]提出了基于干扰物感知的孪生网络跟踪(Distractor-aware Siamese networks for visual object tracking,DaSiamRPN)算 法 ,在SiamRPN 的基础上提出了增量学习,为了选择出更好的跟踪框,在训练中添加了三类样本对,有效地提高了跟踪器的泛化能力。Wang 等[8]提出的快速在线目标跟踪与分割(Fast Online Object Tracking and Segmentation,SiamMask)算法将提取特征的浅层网络AlexNet[9]换成了更深层网络的ResNet(Residual neural Network,ResNet)[10],并在 RPN 并行加入掩膜分支进一步提高了跟踪的准确率。
综上所述,现有基于孪生网络的跟踪算法在跟踪时不需要在线学习,模板(目标)特征只根据预处理的第一帧图片进行提取,之后不再进行更新,虽然速度上表现优异,能够达到实时跟踪的要求,但是由此导致模板特征不能很好地适应目标的表征变化;另外,在SiamMask 的掩膜分支中,模板路浅层特征含有冗余性,会污染生成的目标掩膜,使得跟踪精确性没有进一步提高。
针对基于孪生网络的跟踪算法出现的上述问题,本文对快速在线目标跟踪与分割算法进行了以下几点改进:1)为了提高模板特征的表达能力,通过设置学习率,利用第一帧提取的模板特征与后续帧提取的模板特征进行学习,这样能够丰富模板特征的语义信息,提高算法的鲁棒性;2)在得到目标掩膜(mask)的过程中,稀释了模板路降维的特征,减少了冗余特征的信息干扰,提高了算法的精确性。最后为了验证本文算法的有效性,在两个具有挑战性的数据集上进行了详细的实验,并与几个近期具有代表性的跟踪算法进行比较,实验结果表明本文所提方法得到了很有竞争力的结果。
1 全卷积孪生网络
为了保持跟踪器的精确性和实时性,采用了全卷积孪生网络的框架。另外,为了证明本文方法的有效性,将在本节介绍SiameseFC、加入RPN 的SiamRPN 以及视频对象跟踪和半监督视频对象分割算法SiamMask,在第2 章介绍本文的改进方法。
Bertinetto 等[1]提出的 SiameseFC 算法共有两个分支:一路为模板分支,一路为待检测分支。全卷积孪生网络是线下训练的,作用于模板分支的模板图像z 和待检测分支的待检测图像x,输出为一维响应图。在响应图中找到得分最高的点,通过双三次插值算法反向计算,找到目标的位置。该算法的模板路图像是经过第一帧图像预处理得到的,在跟踪过程中不进行更新。这两个输入由同一个CNN 进行处理,生成的两个相互关联的特征图根据式(1)得到相似度响应图:

式中:f(z)、f(x)分别是模板图像和待检测图像由CNN 提取的特征;*为卷积操作。网络中的最优参数ω是采用随机梯度下降训练得到的,从大型可视化数据库(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)[11]中选取了大量的图片对(zi,xi),给定相应的标签响应图Yi∈ {-1,+ 1},然后最小化式(2)的逻辑回归损失函数L(·):
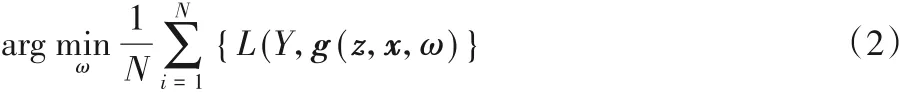
式中,N为训练样本数。
Li等[6]在 SiameseFC 的基础上提出了 SiamRPN 算法,该算法大幅提高了跟踪速度,原因是加入了RPN,RPN 有两个输出:
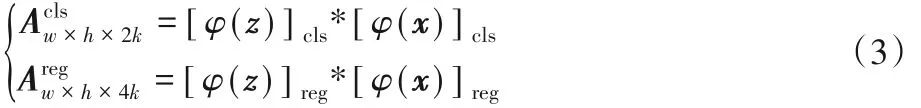
式中φ(z)、φ(x)分别为模板特征和待检测图像特征。其中:是分类分支的输出,包含 2k 个通道向量,通过 softmax损失分类,区分前景和背景是回归分支的输出,包含4k 个通道向量,使用了可变宽高比的边界框预测目标的尺度和位置,解决了SiameseFC 中计算多个目标尺度而减缓跟踪速度的问题,速度最高可达到200 帧/s。该算法将SiameseFC与Faster R-CNN 巧妙地联系起来,RPN 并行计算,有效地提高了跟踪精度。
SiamMask算法[8]能够并行完成视频目标跟踪任务和视频目标分割任务,沿用了SiameseFC 的跟踪框架,将提取特征的AlexNet 换为深层网络ResNet,将一维的响应图拓展到了多维,在RPN 原有的回归分支和分类分支的基础上,加入掩膜分支用于目标分割,能够更好地定位目标。在三个分支训练了三个子网络,主干网络与子网络均采用离线端到端的训练方式,掩膜分支利用logistic回归损失:
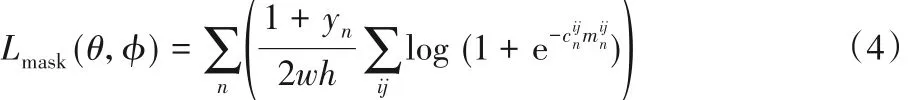
式中:θ、φ 为主干网络与子网络的参数;yn为第n 个候选响应窗口的标签为第n个候选相应窗口中像素(i,j)对应的掩码标签;为分割网络预测结果。SiamMask总损失函数为:
式中:Lscore、Lbox分别为分类分支损失和回归分支损失,λ1、λ2、λ3为权值。
2 本文算法
本文算法的框架如图1 所示。在视频第一帧确定跟踪目标,利用相同的CNN对模板图像z和待检测图像x进行特征提取。为了适应目标表征变化,从第二帧开始,每帧计算一次模板特征,并与第一帧模板特征进行融合学习,更新后的模板特征与待检测图像特征进行卷积计算得到多维响应图。另外,为了得到更精确的目标掩膜,在掩膜分支加入了加权融合策略,减少了冗余特征的干扰。
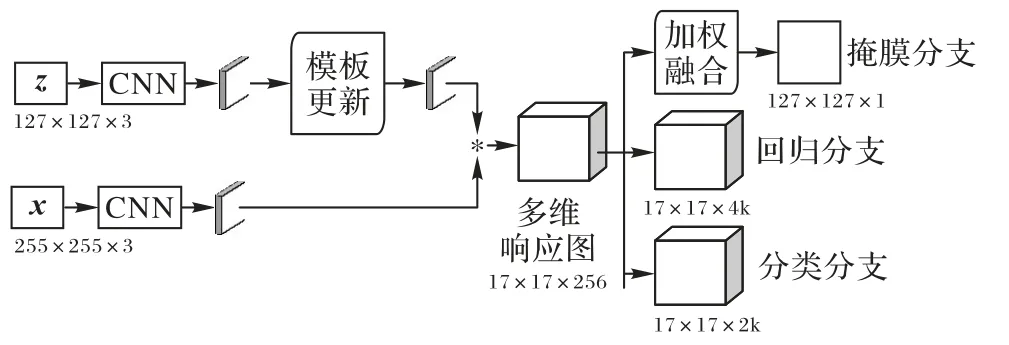
图1 所提算法框架Fig. 1 Framework of the proposed algorithm
2.1 模板特征更新
深度卷积神经网络提取的特征有很好的表达能力。浅层卷积提取的特征包含目标的空间信息,能很好地区分背景干扰;深层卷积提取的特征包含目标的语义信息,能很好地区分相同类别的物体。SiamMask 选用了深层网络ResNet 的Conv4_3 层的特征,模板特征仅在初始帧进行提取,在跟踪过程中不进行更新,待检测图像特征与模板特征进行多维相似度度量计算,得到用于定位的多维响应图;但由于模板特征固定不变,当目标被严重遮挡或者发生形变时,容易出现跟踪失败的情况。所以通过设置学习率对模板特征更新,使模板特征能够更好地适应目标的表征变化。
图1上路即模板路(从模板图像z到更新后的模板特征),首先通过CNN 提取初始帧模板特征并保留,第二帧以第一帧获取的目标中心点为中心截取127× 127× 3 的图片块,再通过CNN 对图片块提取特征,将提取的第二帧模板特征与第一帧模板特征进行加权融合。选取第一帧模板特征进行融合是因为目标是在非遮挡下提取的特征,包含的目标语义信息最为丰富。每一帧都进行此操作,极大地丰富了模板特征的语义信息,经过学习的模板特征与待检测图像提取的特征进行卷积操作,得到的多维响应图更加精准。模板特征更新公式为:

式中:η 为学习率;f1(z)为第一帧图像提取的模板特征;fi(z)为第i帧图像提取的模板特征。
2.2 加权的掩膜细化模块
掩膜细化模块如图2 所示。多维响应图被分成大小相等的单位候选响应窗口,候选响应窗口表示模板图像与待检测图像在某一区域的相似度。通过分类分支找到多维响应图中得分最高的候选响应窗口,通过上采样的方式,将低分辨率的特征图与高分辨率的特征图进行融合。
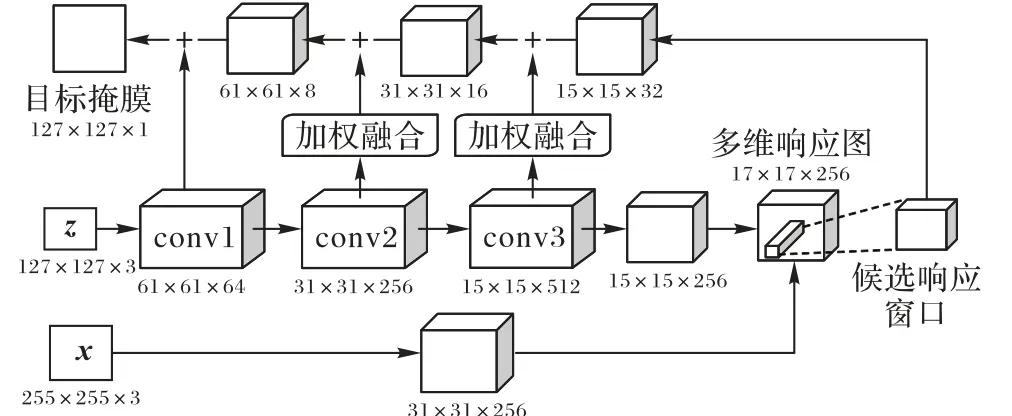
图2 掩膜细化模块Fig. 2 Mask refinement module
在融合的过程中,将模板图像z 提取的第一层、第二层和第三层特征通过降维的方式与候选响应窗口上采样的特征直接相加,在这个过程中,包含目标空间信息的通道被舍弃,包含背景干扰信息的通道被保留,导致目标分割定位不准确。在保留模板特征空间信息的前提下,对其进行加权,将更多的注意力放在上采样的优质特征上,以减小降维特征对上采样特征的干扰。该方法经实验证明,模板图像z 提取的第二层和第三层卷积降维特征对上采样的特征干扰最大。在跟踪过程中,为了保证跟踪器的性能,需要设置合理的融合权重以充分发挥特征的表现能力。所以,将第二层降维特征与上采样特征进行加权融合,其融合权重比例为1∶1.25,第三层降维特征与上采样特征融合比例为1∶2。该特征融合公式为:

3 实验与结果分析
为了评估本文改进算法的有效性,选用VOT2016[12]、VOT2018[13]这两个被广泛应用以及具有挑战性的数据集进行测试,这两个数据集均有60组长短不一的视频,包含6种视觉干扰,每组视频序列中至少包含一种视觉干扰,具有代表性。
实 验 平 台 为 ubuntu16.04 系 统 下 的 PyCharm PROFESSIONAL2017,所有跟踪实验均在配置为Intel Core i5-4590CPU,GTX 1060 GPU,内存为16 GB 的计算机上完成。实验中采用的评价标准为精确性(Accuracy)、鲁棒性(Robustness)以及预期平均重叠率(Expected Average Overlap Rate,EAO),其中Accuracy 是根据跟踪算法预测的目标框与标注的真实框的重叠率计算得到的。首先计算第t 帧的重叠率:


式中Nvalid表示视频序列的长度。Robustness 用来测试跟踪算法的稳定性,数值越大,表示稳定性越差,如下式所示:

式中:F(k)为跟踪算法在跟踪的第k 次重复中的失败次数。EAO 是根据精确性和鲁棒性计算得到的,将数据集中所有序列按长度Ns分类,计算长度为Ns的视频序列每一帧一次性的准确性,然后计算每个长度为Ns视频序列的准确性,通过下式得出该长度Ns的EAO值:

最后对不同长度的EAO 值求平均,设序列长度范围为[Nmin,Nmax],则:
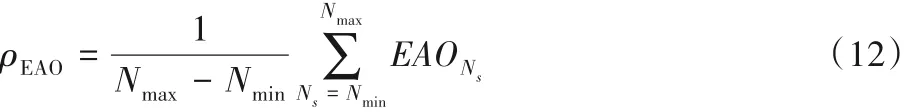
EAO为一个数值,可用此值评测跟踪算法的综合性能;使用每秒钟处理的帧数(Frames Per Second,FPS)评估跟踪的速度,即实时性。
3.1 算法改进实验
本部分实验对比模板更新过程中不同学习率对跟踪过程的影响和掩膜细化模块根据不同权重融合特征对结果的影响,并做了可视化对比实验。
3.1.1 不同学习率对比实验
本文算法通过设置学习率的方式去更新模板,使得模板特征能够更好地适应目标的表征变化。在测试的众多学习率中选出了四组不同的学习率在VOT2016 和VOT2018 上进行了测试,以精确性和预期平均重叠率EAO 对跟踪结果进行评估,实验结果如表1 所示。学习率为0 是SiamMask 算法的实验结果,当把学习率设置为0.06时精确性和EAO 在VOT2016和VOT2018 中提升幅度较为明显,表明通过学习目标变化后的模板特征有效地提高了跟踪器的鲁棒性。
3.1.2 不同权重融合特征的对比实验
SiamMask 算法在掩膜细化模块将含有空间信息的高维特征降维后直接与相同通道数的候选响应窗口上采样的特征相加,为了减少因为降维带来的冗余特征干扰,在本实验中对模板图像z所提取的第二层(Conv2)以及第三层(Conv3)降维后特征乘以不同的权重系数再进行相加操作,实验结果如表2 所示。权重系数是通过反复实验得到的,表中选取了三组有代表性的权值进行比较,这三组权值均提高了跟踪性能,其中对Conv2 乘以0.8 和对Conv3 乘以0.5 时跟踪效果最好,说明稀释模板图像z降维特征再融合的方式有效,最终选取权重系数为0.8和0.5。
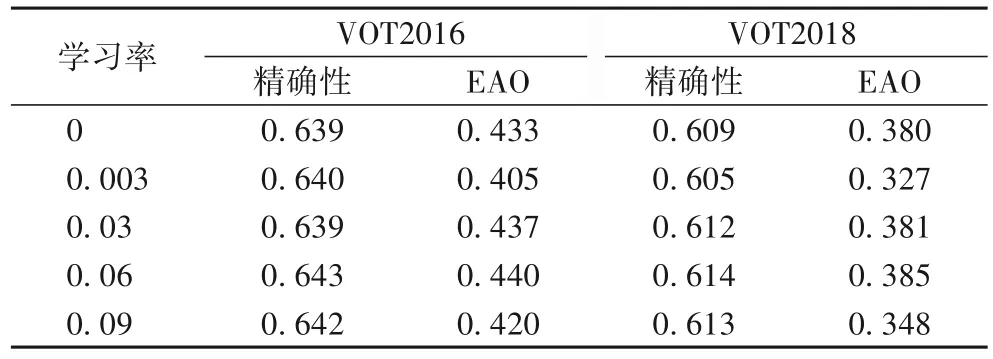
表1 不同学习率时的性能对比Tab. 1 Performance comparison with different learning rates
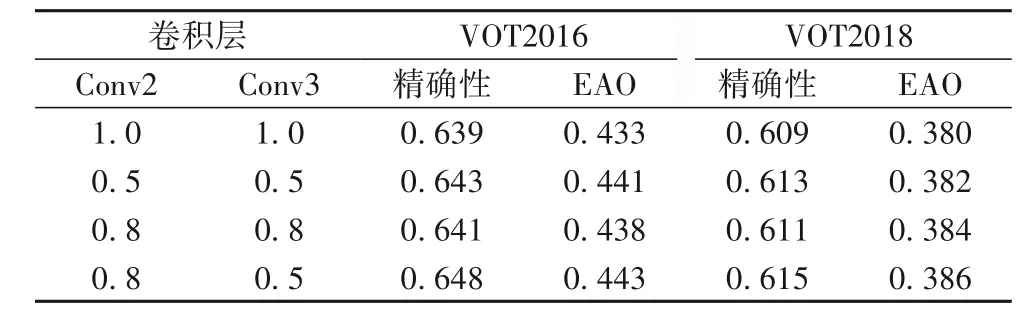
表2 不同权值时的性能对比Tab. 2 Performance comparison with different weights
3.2 与其他孪生网络算法的对比实验
在VOT2016 数据集中选取了四种基于孪生网络框架的算法和两种主流算法进行对比,分别是:SiameseFC 算法[1]、SiamRPN 算法[6]、DaSiamRPN[7]以及 SiamMask[8]算法、ECO 算法[14]和 CCOT 算法[15],实验结果如表 3 所示,本文算法的精确性和鲁棒性均优于其他六种对比算法。另外,在VOT2016 数据集测试中,本文算法的EAO 比SiamMask 算法高了1.7 个百分点,比VOT2016 短时跟踪挑战赛冠军CCOT 算法高了11.9个百分点,并没有因为改进策略影响跟踪速度,仍达到实时跟踪的要求。
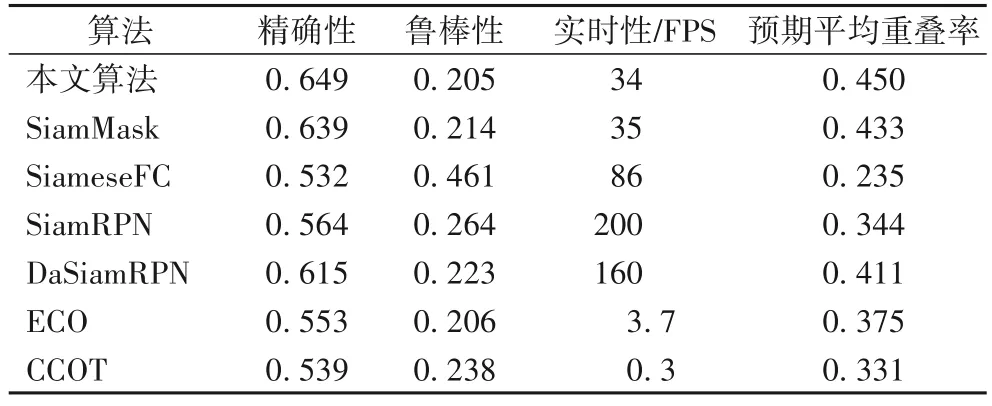
表3 VOT2016上7种算法的结果对比Tab. 3 Result comparison of 7 algorithm on VOT2016
在VOT2018 数据集中选取了六种基于孪生网络框架的算法进行比较,分别是:SiameseFC 算法[1]、SiamRPN 算法[6]、DaSiamRPN[7]、SiamMask[8]算 法 、DSiam[5]算 法 以 及SA_Siam_R[16],精确性、鲁棒性和实时性的实验结果如表 4 所示。在VOT2018 数据集测试中,本文所提算法的EAO 高于VOT2018短时跟踪挑战赛冠军EAO 为0.389的自适应学习的判别式相关滤波器(Learning Adaptive Discriminative Correlation Filters,LADCF)算法[17],EAO、精确性和鲁棒性均高于其他六种基于孪生网络框架的算法。
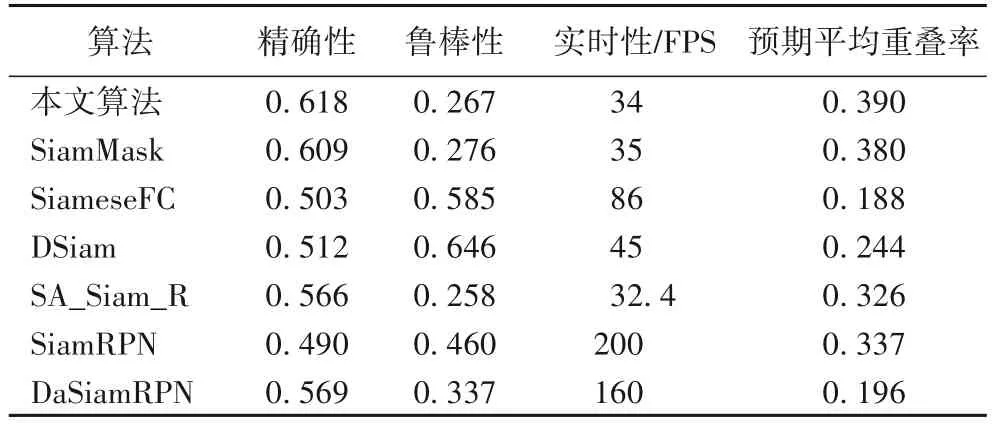
表4 VOT2018上7种算法的结果对比Tab. 4 Result comparison of seven algorithms on VOT2018
图3 给出了四种基于孪生网络的跟踪算法在graduate、girl、gymnastics1、car1这四组数据上的跟踪效果。

图3 四种跟踪算法的部分跟踪结果对比Fig.3 Comparison of tracking results of four tracking algorithms
在图3(a)的graduate 视频序列中,主要的干扰因素是遮挡,在目标被遮挡前,四种算法均可以较好地定位到目标,在第287 帧左右时,目标发生遮挡,SiameseFC 算法和DSiam 算法出现了明显的跟踪偏差,本文算法和SiamMask 依然能够准确地跟踪目标;在图3(b)的girl 视频序列中,主要的干扰因素也是遮挡,在第106 帧左右时,目标发生遮挡,SiameseFC 和DSiam 跟丢目标,SiamMask 出现了跟踪偏移的现象,遮挡结束后本文文算法在视频的第139 帧依然稳定跟踪到目标,其他三种算法全部跟丢目标;在图3(c)的gymnastics1 视频序列中,主要的干扰因素是形变,从图中可以看出目标从发生形变到最后一帧,本文算法和SiamMask 有良好的稳定性;在图3(d)的car1 视频序列中,主要的干扰因素是模糊运动,目标在模糊运动前,本文算法与SiamMask 有较好的跟踪效果,在第683 帧左右时,目标发生模糊运动,可以看出四种算法均出现了明显的偏移现象。综上所述,在目标发生遮挡、形变时本文算法能够更好地跟踪目标。
4 结语
SiamMask 算法的跟踪效果优于其他基于孪生网络框架的跟踪算法,由于深度卷积特征具有超高的表征能力,所以性能比较稳定,但出现类内物体干扰或者目标被严重遮挡时,会出现跟踪丢失或者跟错的情况,因此本文做出以下改进:首先,利用第一帧模板特征通过设置学习率与后续帧提取的模板特征进行融合学习,丰富了模板特征的语义信息,增强了特征的表现力,提高了跟踪器的鲁棒性;同时,在掩膜细化模块对降维特征进行了加权操作,减少了冗余特征的干扰,提高了跟踪精确性。在VOT2016 和VOT2018 数据集上进行测试,并对不同学习率和不同权重对跟踪效果的影响进行了分析,结果显示本文算法在VOT2016 数据集中测试的EAO 比SiamMask 算法高 1.7 个百分点,在 VOT2018 中比 SiamMask 算法高1 个百分点,实验结果均优于其他对比算法,从而验证了本改进算法的有效性;而且在两个数据集测试速度均超过了34 帧/s,满足实时跟踪的要求。下一步工作将针对快速移动和模糊运动干扰,进一步提高目标跟踪的效果。
