基于垂直集成Tri-training的虚假评论检测模型
2020-09-04尹春勇朱宇航
尹春勇,朱宇航
(南京信息工程大学计算机与软件学院,南京210044)
0 引言
随着电子商务和社交网站等网络平台的兴起和快速发展,越来越多的用户频繁地在这些平台上进行浏览、社交、购物等网络行为,并且为了分享各自的体验和观点,用户发布了大量的评论来展现自己[1]。在其他用户浏览文章或商品等发布的信息时,评论具有相当大程度的导向作用。有些用户仅仅根据发布信息下面的评论决定自己的观点,而忽略了关注发布的信息本身,这在电子商务中尤为可见。
在网络购物时,由于商品实体与购买者分离,店家给出的信息并不完全可信,而他人的评论代表着其购买商品后的实际使用体验,购买者通过阅读这些商品评论可间接获取所买商品的体验信息,以此来判断商品是否值得购买。然而,随着商品评论越来越能决定用户的购买决策,以及网络平台缺乏可信评论的筛选机制,虚假评论也就应运而生。虚假评论是指评论者为获取某些利益发布不符合客观真实经历的评论,而且这些评论对于商品有极端情感的倾向(比如过分吹捧或过分诋毁)。电子商务网站中的虚假评论日趋増多,这不仅会给消费者传递错误信息,降低用户体验;同时也容易给商家造成不必要的经济损失。而识别出虚假评论并采取相应的措施处理会提升评论的整体可信度,指导消费者做出正确的购买决策[2]。由此可见,有效识别电子商务网站中的虚假评论已成为一项急需解决的任务。
2008 年,Jindal 等[3]首次提出了虚假评论检测这一问题,指出由于虚假评论的高度混淆性导致其检测尤其困难。Jindal等[4]在分析了亚马逊网站的评论之后,总结出了最有可能是虚假评论的三原则,并以此来标注评论。最初的虚假评论检测是利用词袋特征和词性特征来对评论进行语法上的分析[5-6],并且在某些数据集上取得了良好的效果。然而,文献[7]中的研究表明,使用情感等文本特征来区分虚假评论的效果并不显著,因为在故意伪造的评论中,这些评论的文本特征并不能明显识别虚假评论。在测试时增加评论者的特征,检测效果可能会得到一些提升。随后,虚假评论检测添加了评论者、评论者群体的特征[8-11],从用户方面来识别虚假评论。除了特征提取部分之外,训练算法对检测效果也有很大影响。虚假评论检测可以被视为文本分类中的一个二分类问题,将评论分类为虚假评论和真实评论。用于虚假评论检测的分类算法包括贝叶斯分类、决策树分类、支持向量机(Support Vector Machine,SVM)分类和随机森林[12-17],其原理是在训练集中学习一个目标函数,该函数将每个样本矢量映射到预定义的类型标签。聚类算法是将相似的评论分到一个类中,并且不同的类之间的差异尽可能大[18]。神经网络也因深度学习的兴起而逐渐应用于文本分类中,利用反向传播来修正输入层传递到输出层的结果与预期结果不一致的错误[19-21],实现实际输出值与预期输出值之间的统一。神经网络的不足之处是在训练阶段时需要提供大量的文本和相关类别信息,以此来保证训练的准确度。
目前,虚假评论检测虽然有了快速的发展,但也面临着诸多技术上和非技术上的难题和挑战[22-24]。虚假评论检测技术面临的挑战主要体现在以下两个方面:1)大规模有准确标记的样本难以获取;2)人工选取的特征难以完全表示文本语义。
因此,针对面向标记样本规模受限的虚假评论检测问题,半监督学习利用带有标签的未标记样本来增强分类效果,因此它是解决标记样本过少的一个有效方法。其代表性算法有协同训练、PU 学习(Positive Unlabeled learning,PU learning)等[25-27]。协同训练要求数据具有两个足够冗余且满足条件独立性的视图,同时两个视图对于类别标记是独立的。协同训练被应用在社交网络小规模标记样本中的虚假评论检测[28]。评论文本特征、评论者特征和评论对象特征构成三个视图,虚假评论检测可依据其中的两个视图进行协同训练。在文献[29]中,模型首先训练具有少量标记数据的原始分类器,然后在社交图形传播中建立信任和不受信任的顺序,并选择由分类器判断的可信用户和其排序评分为新的训练数据,然后重新训练分类器,检测效果比常规的协同算法更好。Gilad 等[30]提出了一种基于垂直集成的Co-training(Vertical Ensemble Cotraining,VECT)算法,利用保存协同训练算法各个迭代过程中的分类器权重共同标记样例,并在最后全部集成到最终分类器中,以此来解决标记数量过小的识别问题,在多个文本分类数据集上的检测效果都优于传统Co-training算法。
为解决虚假评论检测中由于样本标记过少而影响检测效果的问题,本文提出了一个基于垂直集成Tri-training(Vertical Ensemble Tri-training,VETT)的虚假评论检测模型,该模型主要是结合评论文本特征和评论者的行为特征这两种特种作为特征提取,而后通过VETT 算法来分类评论。在初始样本中标记样本过少时,VETT 算法过程利用Tri-training 以往迭代的分类器模型先训练各自在这轮迭代的3 个分类器模型,然后通过标记样本选择置信度较高的样本数据来修正3 个分类器权重,以此来提高标签标记的准确率。
1 相关工作
1.1 虚假评论检测模型
如图1 所示,面向标记规模过小的一般虚假评论检测模型分为特征提取和半监督学习两个部分。特征提取主要是从原始数据中获取能够检测出虚假评论的特征,这些特征主要是经过分词处理后的文本特征,而评论者特征、评论对象特征可以有选择地加入。其中评论文本特征是评论内容中所蕴含的信息,而评论者的特征为评论发布者的一些行为特征和其自身信息。评论对象特征指那些评论的主题,比如商品和事件内容。而在检测方法中主要是通过利用半监督学习算法来区分真假评论。

图1 面向标记规模过小的虚假评论检测模型Fig. 1 Fake review detection model for small labeling scale
电子商务中的虚假评论检测常用的特征有商品评论特征、用户行为特征和商品信息特征三类[31-37]。
1.1.1 商品评论特征
如表1 所示,商品评论特征是评论文本信息间接或直接计算而得来的属性值,主要包括情感极性、评级矛盾、一致性、人称比例、评论文本长度、商品评论文本相似度、历史评论文本相似度等。

表1 评论文本特征Tab. 1 Review text characteristics
情感极性表达主观信息,如人们的意见、立场和情感,反映人们的情感趋势。情感极性分为积极情感极性和消极情感极性。与正常评论相比,虚假评论往往具有异常的情绪表达,即过分赞美和恶意诋毁。情感极性的计算方法通常通过文本中的情感词数量的加减来实现。
1)评分偏离性SD(Score Deviation)。此特征表示了某条评论的评分与商品整体评分的偏差程度。在电子商务中,用户给商品的评分包含商品评分f1、物流评分f2和服务评分f3三种,同时商家店铺也有这三种整体的平均评分ft。SD越大,表明评论者给出的评分与整体评分的距离越远,评分与其他评论者的评分趋势越偏离,评论越有可能是虚假评论;相反地,SD值越小,给出的评分越符合其他评论者的平均打分习惯,评论也趋于真实性。计算公式如式(1)所示:

2)一致性CES(Consistency of Emotional bias and Score)。此特征指评论文本的情感偏向EB(Emotional Bias)与评论所得评分以及平均评分S的偏差程度,两者偏差越小,评论与评分一致性就越高,评论越可能是真实的。计算公式如式(2)所示:
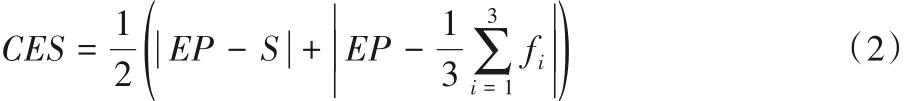
3)人称比例PR(Person Ratio)。此特征指评论文本中出现“我”第一人称的次数与出现诸如“你”“它”“他”等人称的次数的比值。虚假评论发布者通常喜欢使用第一人称来伪造评论,以此来增强评论的代入感,迷惑消费者的判断。计算公式如式(3)所示:

其中:f_n表示第一人称的出现次数,o_n表示其他人称出现的次数,分母加1是为了避免分母为零。
4)评论文本长度。即评论文本字符数,它计算的是评论文本中的字符数,但不包括标点符号。
5)商品评论文本相似度PRS(Similarity of Product Reviews)和历史评论文本相似度HRS(Similarity of Historical Reviews)。也就是说,当前评论类似于当前商品的所有评论或评论者的所有历史评论的文本的相关程度。文本的相似性越大,表明评论越有可能是通过复制或部分修改形成的虚假评论。PRS和HRS的计算公式如式(4)和(5)所示:

其中:p_r是评论商品的所有评论;h_r是当前评论者的所有历史评论;r是当前评论;l是当前评论的长度;sim()函数是相似度计算函数,可用余弦相似度来计算。
1.1.2 用户行为特征
此类特征包括评论者的个人信息和在此平台发布评论的一系列网络行为等。由于虚假评论者试图模仿真实评论的描述来干扰检测结果,用户的行为特征从侧面能反映出虚假评论者的异常行为,能在一定程度上识别评论的真假。这类特征主要包括评论频率、用户信誉级别、个人信息完整度、评级标准偏差、不同产品的评分差异等,如表2所示。

表2 评论者行为特征Tab. 2 User behavior characteristics
1)评论频率。指评论者在一个时间单位中发布的评论数量。评论者发表评论的频率越大,评论者就越有可能是水军。
2)用户信誉级别。其他用户接受该用户的评论越多,可信度越高,真实程度越高。
3)评论者个人信息的完整性。评论者个人信息越完整,他就越有可能是真实用户,而个人信息太少的用户更有可能是虚假评论发布者。毕竟,个人信息越完善,发布者的真实信息就越能确定。
4)评论者的标准偏差。评论员用于给商品打分的历史评分以计算标准偏差。虚假评论者给商品的评分很极端,标准偏差过大;普通用户的历史评分相对稳定,因此标准差相对较小。
5)不同产品评论的评分差异。普通用户给出的分数往往波动很小,而虚假评论者的分数通常比较极端,无论是高分还是低分,都形成了两级分化趋势。
1.1.3 商品特征
这类特征包括该商品的评论数、平均评分、商品信息等,通常与上述两类特征有紧密的联系,故不单独使用。
1.2 传统的Tri-training算法
半监督学习主要是有效地利用少量标记数据和大量无标记数据来训练分类器。Blum 等[38]提出了一个由两个分类器协同工作的Co-training 协同算法。它使用两个分类器协同训练标记数据,由某个分类器训练的标记数据添加到另一个分类器的标记数据集中,以此训练这个分类器,并重复这个过程直至两分类器再无区别。Co-training算法必须满足这一假设:数据属性具有两个充分冗余的视图。但一般来说,数据难以满足具有两个充分冗余视图的要求。不过研究者提出了一种Tri-training 算法[39],它不需要完全冗余的视图或不同的分类算法,而是通过在原始数据集中利用随机采样bootstrap 方法来获取3 个数据子集,并且训练出3 个分类器,就可以确保分类器之间的差异。Tri-training使用3个分类器,以便通过简单的投票规则确定可被信任的标记数据。详细情况是:对于未标记数据x,如果Ci和Cj对于x的标记是相同的,那么就把x及其标记y加入到Ck(k≠i,j)的标记训练数据集中。
由于简单投票将噪声引入了第三分类器,因此在Tritraining 算法中增加了一种控制条件,以确保噪声环境中分类误差率的收敛。考虑学习数据集错误率ω与训练数据集容量m的数据噪声速率之间的关系如式(6)所示:

其中:c为一个常量。
如果要确保ωt<ωt-1(t为迭代次数),则在训练期间必须满足式(7):

其中:Lt表示在第t次迭代期间前两个分类器要添加到第三个分类器的标记数据;τt是Lt的标记错误率;σL是L上的噪声数据程度。
很显然|Lt|>|Lt-1|,那么通过进一步细化获得的约束如式(8)所示:

因此τt<τt-1而且|Lt|> |Lt-1|。为了确保式(8)为真,有时需要提取Lt的子集作为新添加的标记集。
2 基于VETT的虚假评论检测模型
针对标记样本比未标记样本小得多的情况,本文提出一种基于VETT 的虚假评论检测模型,具体的模型示意图如图2所示。首先,模型需要对原始数据进行预处理,主要过程是整理原始数据集并删除不符合实验的数据。然后通过特征提取获得目标数据集。目标数据集可以视为特征属性数据集,这对于训练的分类器和后续检测非常有用。在此步骤中,数据集中的评论文本和用户属性将在数字上进一步量化,以满足测试的需要。在特征工程过程中,该模型采用用户行为特征和评论文本功能的混合特征作为目标数据集的属性集。最后,通过VETT 算法对目标数据集进行训练,以检测评论中的虚假评论。
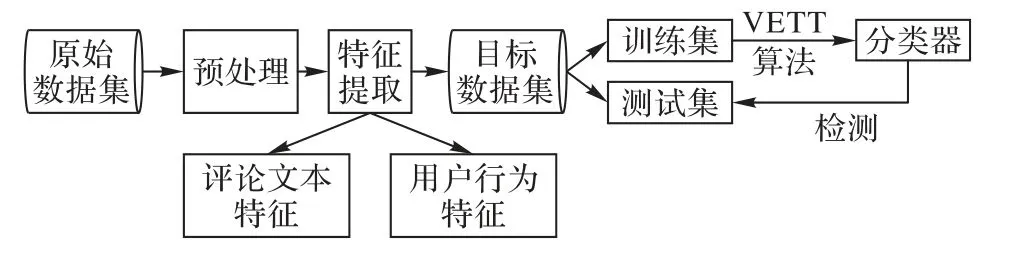
图2 基于VETT的虚假评论检测模型Fig. 2 Fake review detection model based on VETT
在特征工程中,比较正常用户和虚假评论发布者的评论数据,不难发现这种情况:作为正常用户,在决定要购买产品时,必然会在电商平台中搜索产品,平台会给出关于该产品销售的相关信息(如价格、销售来源),用户浏览这些相关产品(如品牌或性能),然后比较这些不同来源的相似产品,最后做出购买决策,发布自己的意见;相反,虚假评论者并无此购物前的商品比较过程,只是在下单购买时与正常用户相同,但多数不会浏览其他相似的产品,否则会增加成本。因此,用户浏览某种产品及其同类产品的历史记录是一项重要的特征。
针对这种情况,本文提出一种新的用户行为特征——商品浏览度,并给出了其计算方法。商品浏览度定义为:在发布商品评论之前的一段时间内,用户浏览类似商品的历史记录与之前查看关于该产品所有历史记录的比值。在发布真实的商品评论之前,用户不可避免地会浏览其他与该商品类似的产品,因此用户的商品的历史浏览记录尤为重要。商品浏览度PBR(Product Browsing Relevance)计算公式如下:

其中:T 表示在特定时间段内购买商品前的天数,Ni表示与第i 天浏览类似商品的浏览记录数,Mi表示在第i 天浏览购买商品的记录数。由于用户在电商平台上只要购买成功,浏览该商品的历史记录必然存在一次,因此分母不存在零值。PBR值越大,越有可能是真实评论;反之,PBR 值越小就越有可能是虚假评论。
Tri-training 存在两个缺点:第一个缺点是标记样本集中添加太多未标记的样本可能会严重影响性能。产生这种情况的原因有错误标记的样本、标记样本集训练的分类器之间差异不大、分类模型造成少量样本过于稳定等。第二个缺点是,Tri-training 训练过程中生成的最终分类模型不会以任何方式来利用迭代过程中创建的各种分类器所代表的知识。这之所以成为一个问题,不仅是因为分类器迭代时丢失的信息依然具有可用性,还因为这些模型是作为Tri-training 训练过程的一部分生成的,使用它们没有额外的成本。
因此,本文提出一种基于垂直集成的改进Tri-training 算法(VETT)。该方法认为,Tri-training 迭代过程生成的模型仍然具有有用的检测性能,即使迭代更新的模型标记错误,以前的迭代模型也可以纠正错误标记。在传统的Tri-training 迭代过程中,3个分类器只要其中2个分类器标记一个数据为相同标签,就将其交予第三个分类器的训练集中,即不考虑第三个分类器对于该数据的标记情况,这样便会导致未标记数据被错误标记的情况。Tri-training 的迭代过程更像一种集成器,标注样例服从少数服从多数的策略。而分类器的差异性越大,标注样例的准确度就越大。所以参与集成的各种分类模型需要提供关于数据集实例的标签的不同置信水平。文献[30]中,研究者发现连续迭代的分类器精度有显著的波动,即迭代的模型之间具有差异性;而且选择额外实例的不同策略对Co-training 算法的性能有显著的影响。尤其对于决策树这样的分类器来说,这些变化更为显著,决策树利用特征的层次顺序,每个属性具有特定的分割点。以此类推,在Tri-training算法中,3 个分类器模型在数次迭代后,各自的精度都会逐步提高,这就与其在迭代过程中生成的迭代模型有了差异性。如果在3 个分类器迭代前,分类器首先与其以往迭代的分类器模型确定自己分类可信度最高的样例,可以减少分类器之间的噪声干扰,减少错误标记。因此,本文提出利用以往迭代的模型来减少Tri-training迭代过程中产生的错误标记。
如图3 所示,在Tri-training 训练的迭代过程中,先训练初始的3个分类器,而后先用传统的Tri-training训练并保存各个分类器迭代中的分类器权重。这一步是先产生一个分类器的以往迭代模型,为之后利用分类器与其历史迭代模型之间的多样性来确定自身训练集高信任度的样例作准备。3 个分类器的历史分类模型各自至少需要3 个(奇数个并且少数服从多数),这样才能判定自身训练集的样例标签。

图3 VETT算法的流程Fig. 3 Flowchart of VETT algorithm
然后是本文的垂直集成策略,主要分为两步:组内垂直集成和组间水平集成。组内集成是分类器Mi先由其之前的迭代模型训练集成而成(即将之前的迭代模型一起作为一个组训练,即等效于一个小型集成分类器),图3 中Ai是将之前的三次迭代模型在其训练集TA上训练集成。在某个迭代过程中,一个分类器的3 个往上迭代的历史分类模型通过在这个分类器的训练集上寻找到一致确认的高信任样例,将其标注后放入到训练集中,并且交由上一次迭代模型训练成此次迭代的分类器。
组间集成是对于组内集成后的3 个分类器对未标记的数据进行标注,在两个分类器标注一致的样例放置到第3 个分类器的训练集中,然后3 个分类器在自身的训练集中依次训练,得到本次迭代的最终分类器,保存更新这3 个分类器权重。最后在迭代完之后,集成为一个最终分类器。
具体的VETT算法如下:
输入L(标记集),U(未标记集),n(迭代次数),AI(迭代选择的索引),V(验证集)。
输出ET(扩展训练集),M(最终分类器)。
初始化ET=L,AI= 0。
第一步 在L上利用bootstrap 抽样方法选出3 个初始训练集Tj(j=A,B,C),并通过分类算法I训练得到3个初始分类器A0、B0、C0。
第二步 如果i<n或者U≠∅时,继续第三步,否则跳至第七步。
第三步 如果i<4时,跳至第五步,否则继续第四步。
第四步 若i≥ 4,Si(S=A,B,C)由其以往迭代过程的3个分类器Si-3、Si-2、Si-1在训练集Tj上集成而得,Si-3、Si-2、Si-1标注U中的数据,将3 个分类器都标注相同的样本数据{x,y}(x为数据,y为标签)训练集Tj中,同时将U中标记的最可靠数据{x,y}添加到ET中,在新的训练集Tj中训练得到分类器Si。
第五步Ai、Bi、Ci标注U中的数据,将其中两个分类器标注相同的样本数据{x,y}放置到第3 个分类器的训练集Tj中,同时将未标记集U中3 个分类器标记的最可靠数据{x,y}添加到ET中(更新U和ET)。
第六步 在新的训练集Tj中训练得到3 个分类器Ai、Bi、Ci,保存其分类器权重,集成分类器M,并在V上验证性能Vi,如果Vi<Vi-1,则意味着此次的分类性能比上一次迭代中的分类性能差,把它还原到上一次的训练迭代中(即AI的值减去1),跳出至第七步;否则,AI值加1,转回第二步。
第七步 结束训练。
本文算法只是在传统的Tri-training 算法迭代过程中加入了分类器以往迭代过程中的分类模型,利用连续迭代过程中分类器与其迭代模型所产生的差异性来解决3 个分类器之间的噪声干扰。从算法的空间复杂度来看,VETT 除了Tritraining 的空间开销外,由于要保存分类器之前迭代的分类模型,需要占用额外的存储空间来保存这些分类权重。不过这个开销是固定的,因为每次迭代,算法只保存此次迭代的最终分类器权重,同时更新之前该分类器往上的四组迭代权重。相当于一个数组包含5 个元素,每次迭代完,所有元素的位置前移一位,将此次迭代的最终结果放置在第5个位置。3个分类器就相当于3 个数组。因此,这个空间开销是固定的,即为O(1)。算法的空间复杂度来看,额外的时间开销主要是在一个分类器的以往迭代模型做集成标注时产生的。该分类器的权重首先由上一次的分类模型通过本次迭代最近以往3 次的迭代模型获取置信度最佳的样例训练得到,即迭代过程中分类器的权重计算总共有两次;而传统的Tri-training 只有一次,就是在3 个分类器之间标注的时候。因此VETT 的算法开销为O(T(ET) +T(HT)),其中T(ET)表示迭代模型集成标注的代价,T(HT)是指经典的Tri-training 在其迭代过程中的代价。由于每次迭代时,分类器都会对所有未标注的数据进行一个标记,还有一个置信度的值。如果保存每个分类器的前p个置信度较高的正例和q个置信度比较高的反例,那么无疑T(ET)的开销就会大幅度减少。可以添加一个固定的缓存池来存储迭代过程的分类模型所对应的前p+q个置信度较高的未标记数据的标注情况,这样能减少迭代模型再次计算标注情况的时间。
3 实验与分析
3.1 数据集
实验中使用的数据集包括黄金数据集[40]和Amazon 商品数据集[41],以及美国点评网站Yelp 上收集到的两个数据集YelpChi和YelpNYC[42]。
Li 等[40]使用众包平台获取评论数据集,数据集中的评论来自于芝加哥地区的酒店评论。他们收集了400 条被定义为正面和积极的虚假评论,以及从登录网站收集和处理的400条真实评论。这些评论共800条。
Amazon 数据集包含580万条评论、214万用户和670万个产品,涉及3个领域的书籍、音乐DVD和工业产品。数据的标签采用基于规则标注的方法来标记,其优点是基于规则标注的方法不依赖于人工,标记的成本低,很容易获得大量的标签数据,不足之处是会包含一定的噪声。表3 显示了Amazon 数据集的特定属性。

表3 Amazon数据集的数据格式Tab. 3 Data formats of Amazon dataset
在点评网站Yelp 上收集到的两个数据集都是关于餐馆和酒店服务的用户评论。YelpChi 数据集是在美国芝加哥收集的部分餐馆和酒店评论,包含67 395条评论,其中虚假评论有8 916 条;YelpNYC 数据集是纽约地区的餐馆评论,总计359 052条评论,包括36 875条虚假评论。
3.2 实验评价标准
为了全面衡量本文方法的有效性,基于精度和召回率两个指标,将F1 值作为度量虚假评论检测性能的最终评价指标。精度P(Precision)、召回率R(Recall)和F1值(F1-Score)的公式如下所示:

其中:TP指正确识别的虚假评论数量,FP为错误标识为真实评论的虚假评论数,TN作为检测正确的真实评论数量,FN指的是被误认为是虚假评论的真实评论数量。
3.3 实验结果分析
对于每个数据集,20%用作测试数据,80%用作训练数据。实验中未标记的样本数据占整体的比率设置为60%,特征的选择为混合特征(评论文本特征和用户行为特征)。针对黄金数据集中数据量太小的情况,实验使用10 折交叉验证方法。对于Amazon 数据集和Yelp 两个数据集,随机抽取40%作为标注数据,并进行了10 次实验。与本文算法比较的检测方法包括传统的 Co-training、Tri-training、基于 AUC(Area Under Curve,AUC)优化的 PU-learning(PU learning based on AUC,PU-AUC)[43]和 VECT[30]。表 4 是不同方法的虚假评论检测效果对比。
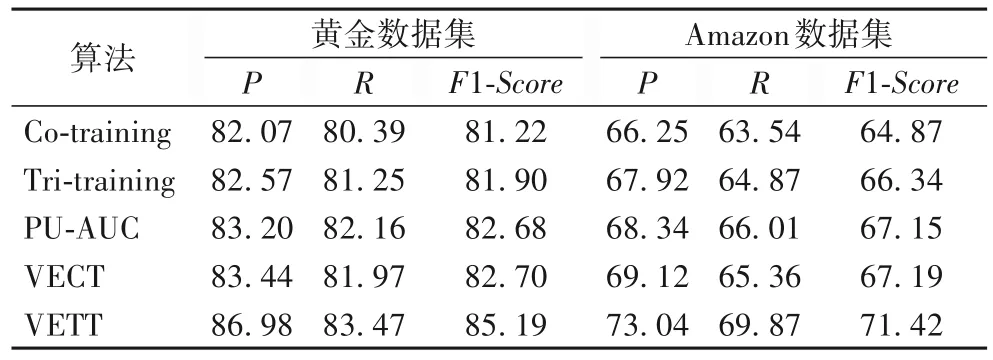
表4 黄金数据集和Amazon数据集上不同算法的性能对比 单位:%Tab. 4 Performance comparison of different algorithms on gold and Amazon datasets unit:%
从表4 中可以看出,在黄金数据集中,每种算法的检测效果都远远高于Amazon数据集中的检测性能,产生这种情况的原因是真实环境中的评论更为复杂,远非简单地能被人为区分。本文的VETT算法在黄金数据集上的检测性能指标F1值比传统的 Co-training、Tri-training 的 F1 值分别高了 3.97 个百分点和 3.29 个百分点,同时也比 PU-AUC、VECT 算法的 F1 值分别提高了2.51、2.49 个百分点。而在Amazon 数据集中,本文的VETT 算法的F1值更是分别比Co-training、VECT 的F1值提高了大约6.5、4.2 个百分点。而在表5 中,本文的VETT 算法在YelpChi 和YelpNYC 数据集的性能最优。在YelpChi 中,VETT 分别比 Co-training、Tri-training、PU-AUC、VECT 提高了4.94、3.83、2.17、1.83 个百分点;而在 YelpNYC 中,VETT 也比其他四个算法分别高了4.72、3.48、1.62和1.45个百分点。这说明了本文提出的基于VETT 的虚假评论检测模型在标注规模受限的情况下依然有较好的分类性能。

表5 Yelp数据集上不同算法的性能比较 单位:%Tab. 5 Performance comparison of different algorithms on Yelp datasets unit:%
为了验证第2 章模型中特征提取(评论文本特征和用户行为特征)的有效性,本文在Amazon 数据集中比较了基于VETT 的虚假评论检测模型在不同特征情况下的分类效果。在此实验中,未标记的标注数据的比例设置为60%,并选择单一的评论文本特征、单一的用户行为特征以及两者的混合特征这三种情况,以此来作对比实验,观察算法在不同特征下的分类性能,实验结果如表6 所示。从表6 可以看出,使用混合特征的算法的F1 值最高,表明本文选择的混合特征是有效的。
为了验证本文算法在少量的标注数据中可以获得更好的检测结果,在Amazon数据集上进行了标注率对于算法效果影响的实验,将训练集中的标记样本数量从10%依次增加到20%、40%、60%和80%。实验结果如图4 所示,当标记样本的比例从10%增加到60%时,尽管前3 个标注率中虚假评论检测到的F1 值不同,但总体趋势是增加的,并且标记样本的比例也在增加。当标注数量较大时,F1 值趋于稳定。因此,从实验结果可以看出,相较于VECT 和Co-training 算法,本文的VETT 算法可以在少量标记样本的条件下获得更好的识别结果,即可在大大减少标注量的同时获得更好的检测效果。

表6 Amazon数据集上不同特征下本文算法的F1值 单位:%Tab. 6 F1-Score of the proposed algorithm under different characteristics on Amazon dataset unit:%
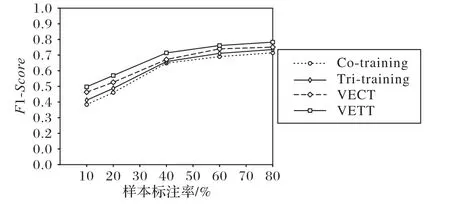
图4 Amazon数据集上不同标注数据比例下四种算法的F1值Fig. 4 F1-Score of four algorithms under different proportions of labeled data on Amazon dataset
4 结语
高质量的标记数据对于虚假评论的分类至关重要,但是,在许多情况下,标记数据的数量比未标记的数据要少得多,因为标记样本可能既昂贵又耗时,因此采用半监督学习来利用未标记的数据和少量标记数据进行训练是非常有效的。
本文提出一种基于垂直集成Tri-training(VETT)的虚假评论检测模型,结合评论文本特征和用户行为特征,采用VETT来训练分类器,以此检测虚假评论。实验结果表明Tritraining 迭代过程生成的分类器模型仍然具有一定可用的检测性能。由于此算法重用训练迭代中的分类器,计算成本较低。此外该方法结合了大量的分类模型,对分类性能有了实质性的改进,并且使结果更平滑、可靠。
不过本文算法也还存在一些不足:首先对于虚假评论的特征依然是人工设计的,这并不能更为全面地表示一个评论,针对这一方面,未来会对评论文本的特征做进一步的研究,从而能够从词向量上深层地表示文本的语义;其次是迭代停止问题,训练迭代过程依然是人工设置,虽有验证集验证最佳效果,但这无疑加大了训练时间和成本,所以当分类效果最佳时迭代自动停止是一个很好的解决方向,加入强化学习是一个不错的方法;最后是实验的数据集在训练前会有噪声,以及训练时依然会有错误标注,考虑到噪声过滤机制的问题,以后会对样本的抗干扰方面做进一步的研究。
