基于多尺度特征融合与反复注意力机制的细粒度图像分类算法
2020-09-03高圣楠马希涛
何 凯,冯 旭,高圣楠,马希涛
基于多尺度特征融合与反复注意力机制的细粒度图像分类算法
何 凯,冯 旭,高圣楠,马希涛
(天津大学电气自动化与信息工程学院,天津 300072)
细粒度图像分类是对某一类别下的图像子类进行精确划分.细粒度图像分类以其特征相似、姿态各异、背景干扰等特点,一直是计算机视觉和模式识别领域的研究热点和难点,具有重要的研究价值.细粒度图像分类的关键在于如何实现对图像判别性区域的精确提取,已有的基于神经网络算法在精细特征提取方面仍有不足.为解决这一问题,本文提出了一种多尺度反复注意力机制下的细粒度图像分类算法.考虑到高、低层级的特征分别具有丰富的语义、纹理信息,分别将注意力机制嵌入到不同尺度当中,以获取更加丰富的特征信息.此外,对输入特征图先后采取通道和空间注意,该过程可以看作是对特征矩阵的反复注意力(re-attention);最后以残差的方式,将注意力结果与原始输入特征相结合,将不同尺度特征图的注意结果拼接起来送入全连接层,以更加精确地提取显著性特征.在国际上公开的细粒度数据集(CUB-200-2011、FGVC Aircraft和Stanford Cars)上进行实验仿真,分类准确率分别达到86.16%、92.26%和93.40%;与只使用ResNet50结构相比,分别提高了1.66%、1.46%和1.10%;明显高于现有经典算法,也高于人类表现,验证了本文算法的有效性.
细粒度图像分类;多尺度特征融合;反复注意力机制;ResNet50
图像分类是计算机视觉领域的重要研究内容,传统的图像分类主要采用决策树[1]、K近邻算法(K nearest neighbors,KNN)[2]、支持向量机(support vector machine,SVM)[3],以及多层感知机(multilayer perceptron,MLP)[4]方法.2012年,AlexNet[5]神经网络在ImageNet数据集上获得成功,为图像分类领域的发展带来了新的机遇.此后,各种神经网络模型[6-10]层出不穷.
随着图像分类技术的发展,细粒度图像分类技术应运而生.细粒度图像分类指的是:在同一类别下对各个子类别进行精细划分,例如:对飞机、汽车、鸟类等图像进行精细划分,以判断其具体型号和种类.上述图像具有类间差异小、类内差异大的特点,因此在精确提取判别性特征,以及定位显著性区域方面难度较大.此外,细粒度数据集都需要专业人士进行标签标注,成本较高,这就导致每种类别的样本数远小于粗分类样本数,容易导致过拟合的现象.由于子类别图像特征过于近似、姿态各异、背景干扰等因素的存在,传统神经网络模型遇到了很大困难,已成为限制该领域发展的主要瓶颈.
为解决上述问题,本文提出了一种基于多尺度特征融合与反复注意力机制的细粒度图像分类算法.其中,多尺度主要是考虑到高、低层级分别具有丰富的语义特征和纹理信息,将注意力机制嵌入到不同尺度,有助于获取更加复杂的特征信息.反复指的是对输入特征图先后采取通道和空间注意,该过程可以看作是对特征矩阵的反复注意力(re-attention).对输入特征图进行权重分配,以矩阵对应元素相乘的方式,将注意力机制得到的权重矩阵先后作用于输入特征矩阵.通道注意力可以让网络重点关注某幅特征图,空间注意力可让网络重点关注某个主要特征,有助于提高细粒度图像分类的准确率.
1 经典细粒度分类算法
2012年,Yao等[11]提出一种无码本和无注释的方法,实现了细粒度图像分类.2013年,Berg等[12]基于局部区域的一对一特征表示方法,实现了细粒度图像分类.鉴于传统算法对细粒度图像分类准确率低,模型泛化能力差,基于深度学习实现细粒度图像分类逐渐成为当前的主流,算法主要分为强监督算法和弱监督算法2大类.其中,强监督算法需要基于人工标注特征完成[13-15].与之相比,基于弱监督算法生成的特征矩阵具有更好的表现力.例如:2015年,Xiao 等[16]提出一种基于深度卷积神经网络的两级注意力模型.2017年,Cui等[17]提出了一种通用的池化框架,以核函数的形式来捕捉特征之间的高阶关系.
上述方法由于对判别性特征提取能力不足,分类准确率较低.为此,人们提出了一些改进算法.例如:2015年,Lin等[18]提出利用双线性网络结构来实现特征提取,提高了分类精度.同年,Jaderberg等[19]提出了一种空间变换网络,先对输入数据的特征图进行变换,再进行识别分类.冀中等[20]将空间变换网络与双线性网络相结合[18],在细粒度鱼的数据集上取得了较好的分类效果.2018年,Peng等[21]提出一种目标-局部注意力机制,利用两种模型分别获取目标区域和局部特征,再分别送入分类器进行分类.2018年,Dubey等[22]采用混淆矩阵的方法来防止过拟合,有效地解决了细粒度图像类间差异过小的问题.同年,Wang等[23]在VGG16网络结构上增加了一条支路,用于提取局部信息,形成了一个双流的非对称网络,综合考虑全局和局部特征来实现细粒度图像分类.2019年,Chen等[24]提出一种破坏重建学习方法,通过对输入特征矩阵的局部信息进行破坏,来增强网络提取显著性细节的能力.
2 本文算法
在提取显著性特征与去除冗余信息方面,现有细粒度分类算法仍有较大的改进空间.为此,本文提出一种反复注意力机制,如图1所示.输入图像经ResNet基本网络提取相关特征后,将注意力机制以多尺度的方式嵌入到特征提取器当中,将ResNet网络结构的多尺度输出作为本文注意力机制的输入特征矩阵,经过本文注意力机制后,特征图的维度信息不发生变化,由此获取丰富准确的判别性特征.
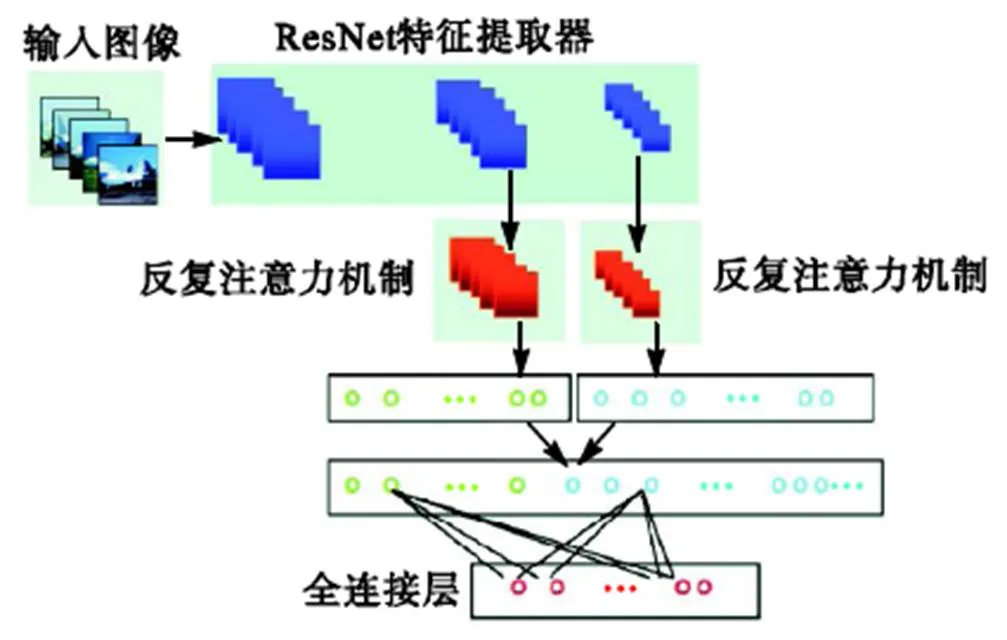
图1 本文提出的具有多尺度特征融合与反复注意力机制的网络结构
2.1 反复注意力机制
已有的一些注意力机制:如卷积块注意模块(convolutional block attention module,CBAM)[25],采用通道注意力支路和空间注意力支路串行的结构,瓶颈注意模块(bottleneck attention module,BAM)[26]则是将通道维度和空间维度的注意力结果直接相加.为了更好地提取特征,融合不同维度的特征信息,本文提出了一种反复注意力机制,如图2所示.

图2 本文反复注意力机制网络结构
具体做法是:先将某一层级的特征矩阵,并行经过通道和空间注意力支路,分别得到通道和空间权重矩阵;再将特征矩阵与通道权重矩阵相乘,网络能够按重要程度,对输入图像的不同特征图进行权重赋值,重要的特征图具有较大的权重值;在此基础上,再与空间权重矩阵相乘,使网络能够学习到每张特征图显著性区域的位置信息,以去除无关背景的干扰,在此过程中,将两条支路的注意力支路结果先后作用于输入特征矩阵上,这一过程体现了本文注意力机制的反复操作;最后以残差的方式,将注意力结果与输入特征结合.具体过程可表述为

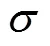
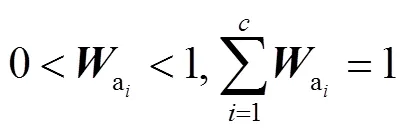
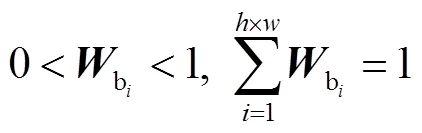
2.2 通道注意力机制
传统算法压缩激活网络(squeeze and excitation networks,SENet)[27]、BAM[26]在通道注意力支路采用平均池化对空间维度进行压缩,未能充分提取纹理特征;CBAM[25]将平均池化结果与最大池化结果直接相加,结合方式过于简单.为了充分保留背景和纹理信息,本文采取将两个池化结果进行拼接的方法,如图3所示.
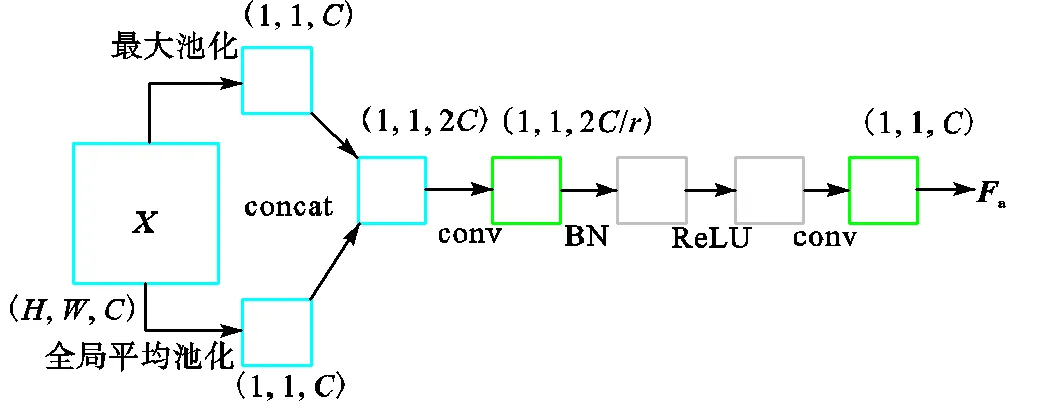
图3 本文通道注意力支路网络

2.3 空间注意力机制
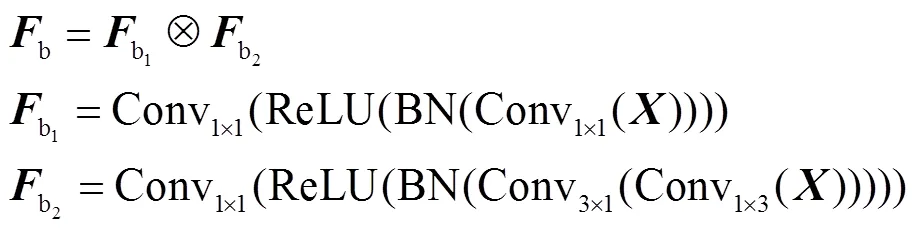
式中:为图4中上面一条支路得到的特征矩阵;为下面一条支路得到的特征矩阵;Fb为空间特征描述子;代表矩阵对应元素相乘.为保证特征矩阵的大小不变,使用时padding设为0,使用和时,padding分别设为(0,1)和(1,0).
3 实验结果及分析
为了验证本文算法的有效性,将提出的多尺度特征融合与反复注意力机制嵌入到标准的ResNet50网络当中,在国际标准细粒度图像数据集上进行测试,并与经典的细粒度分类方法进行比较,以验证算法的有效性.
3.1 数据集选取
本文选取3个标准的国际细粒度数据集:CUB-200-2011、FGVC-Aircraft和Stanford Cars,进行分类实验测试.①CUB-200-2011数据集由加利福尼亚理工学院颁布和维护,包含200类,共10000余张鸟类图像,其中,5994张用作训练集,5794张用作测试集.②FGVC-Aircraft数据集包含100种飞机类型,共10000个飞机图像;其中,训练集和测试集按2∶1的比率进行划分.③Stanford Cars数据集由斯坦福大学发布,包含196类,共16185张汽车图片;其中8144张为训练数据,8041张为测试数据;每个类别按照年份、制造商、型号进行区分.
图5展示了FGVC-Aircraft数据集的部分训练样本,其中,不同行的飞机图像分属不同类别,由上到下依次为:Boeing 737-200、Boeing 737-300、Boeing 737-400、Boeing 737-500和Boeing 737-600.从图中可以看出:①目标在整幅图片中只占据了较小一部分区域,且背景信息复杂;②不同类别图像之间差别很小;③同一类别图像受不同的光照条件和拍摄角度的影响,大小、形状、色差都有很大差别.这些因素的存在,使得该数据集的细粒度分类十分困难,除非是专业人士,普通人也很难区分.

图5 FGVC-Aircraft数据集示例
3.2 实验环境及参数选择
实验所用计算机配置为:Intel Core i7-7800X的CPU,64G的内存,两块GTX 1080Ti的GPU,每块11G的显存;在Linux16.04系统、python编程环境下运行,使用pytorch框架,对细粒度数据集分类.由于每个类别中的样本数较少,直接训练容易产生过拟合;为此,本文采用权重迁移学习[28],将在ImageNet数据集上训练好的权重参数作为本任务的参数初始化值,使得网络能够快速收敛;同时对训练数据集进行随机裁剪、水平翻转等操作来增强数据集.
为验证不同参数对分类精度的影响,分别选取不同学习率和batch_size进行分类,分类准确率如表1所示.其中,3组实验的参数设置分别为:①训练样本的batch_size设为24,改变学习率变化步长和衰减程度,每20个迭代次数(epoch),学习率乘以0.5;②训练样本的batch_size设为20,每15个epoch,学习率乘以0.8;③训练样本的batch_size设为24,每15个epoch,学习率乘以0.8.
表1 不同参数下的识别准确率对比
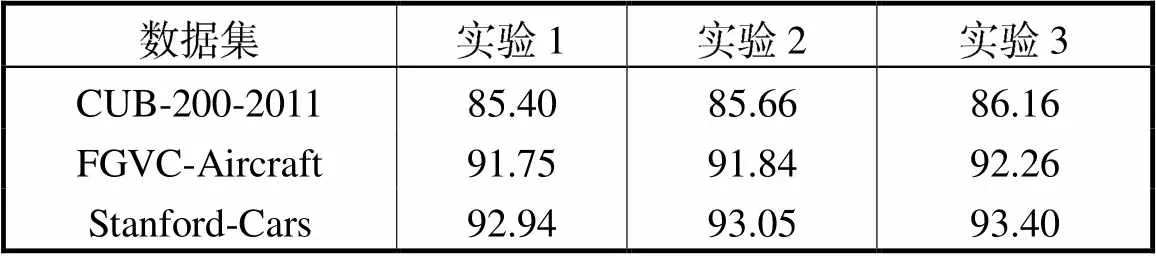
Tab.1 Comparison of identification accuracy under dif-ferent parameters %

3.3 结果分析
利用本文算法,在3种国际标准细粒度图像库上进行训练和分类,训练和测试准确率,以及对应的损失函数曲线如图6所示.从图6中可以看出:epoch介于0~25时,准确率有显著提升,损失函数也有明显下降;在经历25个epoch后,准确率和损失函数曲线有微小变化并逐渐趋于平滑;由此可见,本文算法模型的收敛速度较快,在不同数据集上均能取得较好效果,具有较强的泛化能力.

图6 不同数据库的准确率和损失函数
为验证本文多尺度特征融合与反复注意力机制的有效性,分别采用 ResNet50基本模型,引入多尺度的ResNet50模型,以及本文算法模型,在3个国际标准图像数据库上进行细粒度分类,其top-1结果如表2所示.从表中可以看出,将反复注意力机制以多尺度的方式与ResNet50结合起来,可以显著提升分类精度,在3个标准图像库上均取得了最高分类精度,证明了本文多尺度反复注意机制的有效性.
采取不同特征提取模型获得的反向传播显著图如图7所示.其中,图7(a)为原始输入图片,图7(b)、图7(c)、图7(d)分别为采用ResNet50、基于多尺度的ResNet50、以及本文算法提取特征所获得的反向传播显著图.从图中可以看出,图7(b)由于只使用ResNet50提取特征图,不能有效提取判别性区域,也无法有效过滤背景的干扰信息;图7(c)由于充分考虑了多尺度的特征,与图7(b)相比可以获得更多的特征信息作为分类依据;图7(d)在图7(c)的基础上采取了反复注意力机制,使网络能够重点关注显著性的特征和更具判别性的特征,同时能够有效去除冗余信息,节约计算成本,效果良好.
表2 不同特征提取模型识别准确率对比

Tab.2 Comparison of identification accuracy under dif-ferent feature extract models %
为了测试本文模型在细粒度分类方面的准确性,分别在3个国际标准细粒度图像库上,与当前经典细粒度分类算法进行比较.其中,双线性卷积神经网络(bilinear convolutional neural network,B-CNN)[18]利用双线性网络结构实现特征提取,循环注意卷积神经网络(recurrent attention convolutional neural network,RA-CNN)[29]采用递归注意网络学习判别性特征,动态计算时间(dynamic computational time,DCT)[30]在已有的注意力模型基础上引入了启止动作,来学习最佳注意区域.top-1分类结果如表3所示.

图7 采取不同模型获得的反向传播显著图
从表3中可以看出,与只使用ResNet50相比,在CUB-200-2011、FGVC-Aircraft和Stanford-Cars数据集上,本文算法的分类准确率分别提高了1.66%、1.46%和1.10%.与经典的双线性算法相比,本文算法在CUB-200-2011、FGVC-Aircraft和Stanford-Cars数据集上,分别提高了2.06%、8.16%和2.10%;与其他经典方法相比,也有不同程度的提高,均获得了最高的分类精度,证明了本文算法的有效性.鉴于目标局部注意模型(object-part attention model,OPAM)算法[22]和DCT算法[30]仅在数据集CUB-200-2011和Stanford-Cars上进行了实验;为公平起见,本文仅给出了上述两种算法在相关数据集上的对比实验结果.
表3 不同算法细粒度分类准确率对比

Tab.3 Comparison of identification accuracy of different fine-grained classification algorithms %
此外,从表中还可以看出:CUB-200-2011数据集的分类准确率最低;这是由于鸟类目标较小,姿态各异,易受背景干扰;此外,该数据集类别数目最多,但训练样本数目最少,因此分类难度最大.
注意力区域可视化效果如图8所示.其中,图8(a)为原始图像,图8(b)为准线ResNet50特征图注意力区域的可视化效果,图8(c)为本文算法的特征图注意力区域的可视化效果.从图中可以看出,本文算法可以精确定位判别性区域,同时能去除无关的背景信息,特别是在判别性区域提取难度最大,背景最为复杂的CUB-200-2011数据集上,效果提升最为 明显.

图8 特征图注意力区域可视化
3.4 算法复杂度分析
为了对本文算法的综合性能进行评价,本文对不同算法的分类准确度与复杂度做了对比,结果如表4所示.从表中可以看出,Cimpoi等[31]在深度卷积特征的基础上引入Fisher Vector,取得了较好的细粒度分类效果;经典的双线性算法[18]采用并行的VGG16[6]提取特征,虽然提高了分类准确度,但也导致了参数的成倍增加;Gao等[32]提出了两种紧凑的双线性表征,在保证分类精度的同时,大大减少了参数量;本文算法在原有的ResNet50[8]结构中引入了反复注意力机制,在不显著增加参数的前提下,有效地提升了分类准确率.
表4 不同细粒度分类算法性能对比
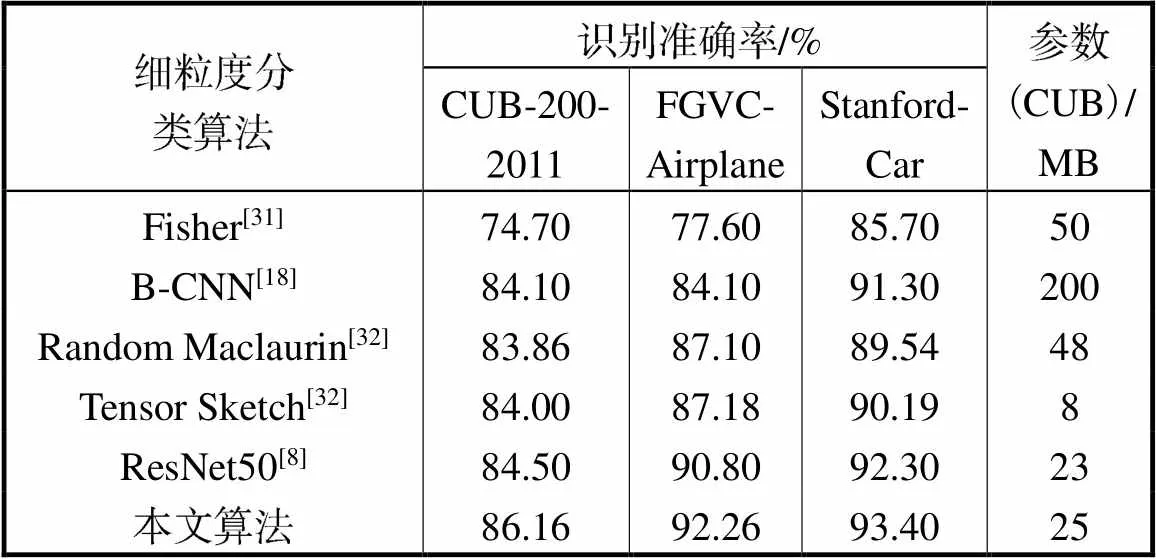
Tab.4 Performance comparison of different fine-grained classification algorithms
4 结 语
本文提出了一种多尺度特征融合与反复注意力机制网络模型作为特征提取器.首先,在结构上融合了多个尺度的特征描述子,增强了网络对输入图像特征信息的表达能力.其次,对每个尺度的输入特征矩阵,一方面采用通道注意力机制去除冗余的特征信息,另一方面采用空间注意力机制去除无关的背景信息.实验结果表明,本文算法取得了比较理想的细粒度图像分类效果,与经典算法相比,准确率有了较大程度的提高.
本文算法属于一种端到端的训练模型,模型结构简单,提出的多尺度特征融合与反复注意力机制网络具有较强的结构迁移性和嵌入性,适用于不同的基本神经网络模型;此外,本文算法在不同的细粒度数据集上均能取得较好效果,具有很强的泛化能力.
[1] Srivastava A,Han E,Kumar V,et al. Parallel formulations of decision-tree classification algorithms[C]//Proceedings of the International Conference on Parallel Processing(ICPP). Minneapolis,MN,USA,1998:237-244.
[2] Guo Gongde,Wang Hui,Bell D A,et al. KNN model-based approach in classification[C]//OTM Confederated International Conferences CoopIS,DOA,and ODBASE. Catania,Sicily,Italy,2003:986-996.
[3] Mao Q H,Ma H W,Zhang X H. SVM classification model parameters optimized by improved genetic algorithm[J]. Advanced Materials Research,2014,889/890:617-621.
[4] Coskun N,Yildirim T. The effects of training algorithms in MLP network on image classification[C]// Proceedings of the International Joint Conference on IEEEPortland,OR,USA,2003:1223-1226.
[5] Krizhevsky A,Sutskever I,Hinton G. ImageNet classification with deep convolutional neural networks[C]//26th Annual Conference on Neural Information Processing Systems 2012. Lake Tahoe,NV,United states,2012:1097-1105.
[6] Simonyan K,Zisserman A. Very deep convolutional networks for large-scale image recognition[C]// 3rd International Conference on Learning Representations,San Diego,CA,USA,2015:1-14.
[7] Ioffe S,Szegedy C. Batch normalization:Accelerating deep network training by reducing internal covariate shift[C]// 32nd International Conference on Machine Learning. Lile,France,2015:448-456.
[8] He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al. Deep residual learning for image recognition[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA,2016:770-778.
[9] Howard A G,Zhu Menglong,Chen Bo,et al. MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications[EB/OL]. https://avxiv.org/ abs/1704.04861,2017-04-17.
[10] Huang Gao,Liu Zhuang,van der Maaten L,et al. Densely connected convolutional networks[C]// Conference on Computer Vision and Pattern Recognition(CVPR). Honolulu,HI,USA,2017:2261-2269.
[11] Yao Bangpeng,Bradski G,Li Feifei. A codebook-free and annotation-free approach for fine-grained image categorization[C]// 2012 IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos,CA,USA,2012:3466-3473.
[12] Berg T,Belhumeur P N. POOF:Part-based one-vs.-one features for fine-grained categorization,face verifi-cation,and attribute estimation[C]// 2013 IEEE Conference on Computer Vision and Pattern Recognition. Los Alamitos,CA,USA,2013:955-962.
[13] Donahue J,Jia Yangqing,Vinyals O,et al. DeCAF:A deep convolutional activation feature for generic visual recognition[C]//31st International Conference on Machine Learning. Beijing,China,2014:988-996.
[14] Branson S,van Horn G,Belongie S,et al. Bird Species Categorization Using Pose Normalized Deep Convolutional Nets[EB/OL]. https://arxiv.org/abs/1406.2952,2014-06-11.
[15] Zhang N,Donahue J,Girshick R,et al. Part-based R-CNNs for fine-grained category detection[C]// 13th European Conferenceon Computer Vision. Zurich,Switzerland,2014:834-849.
[16] Xiao Tianjun,Xu Yichong,Yang Kuiyuan,et al. The application of two-level attention models in deep convolutional neural network for fine-grained image classification[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA,USA,2015:842-850.
[17] Cui Yin,Zhou Feng,Wang Jiang,et al. Kernel pooling for convolutional neural networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA,2017:3049-3058.
[18] Lin T Y,Roychowdhury A,Maji S. Bilinear CNN models for fine-grained visual recognition[C]// 2015 IEEE International Conference on Computer Vision. Santiago,Chile,2015:1449-1457.
[19] Jaderberg M,Simonyan K,Zisserman A,et al. Spatial transformer networks[C]// 29th Annual Conference on Neural Information Processing Systems. Montreal,QC,Canada,2015:2017-2025.
[20] 冀 中,赵可心,张锁平,等. 基于空间变换双线性网络的细粒度鱼类图像分类[J]. 天津大学学报:自然科学与工程技术版,2019,52(5):475-482.
Ji Zhong,Zhao Kexin,Zhang Suoping,et al. Classification of fine-grained fish images based on spatial transformation bilinear networks[J]. Journal of Tianjin University:Science and Technology,2019,52(5):475-482(in Chinese).
[21] Peng Y,He X,Zhao J. Object-part attention model for fine-grained image classification[J]. IEEE Transactions on Image Processing,2018:27(3):1487-1500.
[22] Dubey A,Gupta O,Guo P,et al. Pairwise confusion for fine-grained visual classification[C]// 15th European Conference on Computer Vision. Cham,Switzerland,2018:71-88.
[23] Wang Y,Morariu V I,Davis L S. Learning a discriminative filter bank within a CNN for fine-grained recognition[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Los Alamitos,CA,USA,2018:4148-4157.
[24] Chen Y,Bai Y,Zhang W,et al. Destruction and construction learning for fine-grained image recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Long Beach,USA,2019:5157-5166.
[25] Woo Sanghyun,Park Jongchan,Lee Joon-Young,et al. CBAM:Convolutional block attention module[C]// 15th European Conference on Computer Vision. Munich,Germany,2018:3-19.
[26] Park Jongchan,Woo Sanghyun,Lee J Y,et al. BAM:Bottleneck Attention Module[EB/OL]. https:// arxiv.org/abs/1807.06514,2018-07-17.
[27] Hu J,Shen L,Sun G. Squeeze-and-excitation networks[C]// Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA,2018:7132-7141.
[28] Yuan Chenhui,Cheng Chunling. A transfer learning method based on residual block[C]// 2018 IEEE 9th International Conference on Software Engineering and Service Science. Beijing,China,2018:807-810.
[29] Fu J,Zheng H,Mei T. Look closer to see better:Recurrent attention convolutional neural network for fine-grained image recognition[C]// 2017 IEEE Conference on Computer Vision and Pattern RecognitionHonolulu,HI,USA,2017:4476-4484.
[30] Li Zhichao,Yang Yi,Liu Xiao,et al. Dynamic computational time for visual attention[C]// 2017 IEEE International Conference on Computer Vision Workshop. Los Alamitos,CA,USA,2017:1199-1209.
[31] Cimpoi M,Maji S,Vedaldi A. Deep filter banks for texture recognition and segmentation[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA,USA,2015:3828-3836.
[32] Gao Y,Beijbom O,Zhang N,et al. Compact bilinear pooling[C]// 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA,2016:317-326.
Fine-Grained Image Classification Algorithm Using Multi-Scale Feature Fusion and Re-Attention Mechanism
He Kai,Feng Xu,Gao Shengnan,Ma Xitao
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
Fine-grained image classification aims to precisely classify an image subclass under a certain category. Hence,it has become a commonand difficult point in the field of computer vision and pattern recognition and has important research value due to its similar features,different gestures,and background interference. The key issue in fine-grained image classification is how to extract precise features from the discriminative region of an image. Existing algorithms based on neural networks are still insufficient in fine feature extraction. Accordingly,a fine-grained image classification algorithm using multi-scale re-attention mechanism is proposed in this study. Considering that high- and low-level features have rich semantic and texture information,respectively,attention mechanism is embedded in different scales to obtain rich feature information. In addition,an input feature map is processed with both channel and spatial attention,which can be regarded as the re-attention of a feature matrix. Finally,using the residual form to combine the attention results and original input feature maps,the attention results on the feature maps of different scales are concatenated and fed into the full connection layer. Thus,accurately extracting salient features is helpful. Accuracy rates of 86.16%,92.26%,and 93.40% are obtained on the international public fine-grained datasets(CUB-200-2011,FGVC Aircraft,and Stanford Cars). Compared with ResNet50,the accuracy rate is increased by 1.66%,1.46%,and 1.10%,respectively. It is obviously higher than that of existing classical algorithms and human performance,which demonstrate the effectiveness of the proposed algorithm.
fine-grained image classification;multi-scale feature fusion;re-attention mechanism;ResNet50
TN911.73
A
0493-2137(2020)10-1077-09
10.11784/tdxbz201910029
2019-10-16;
2019-11-06.
何 凯(1972— ),男,博士,副教授.
何 凯,hekai@tju.edu.cn.
国家自然科学基金资助项目(61271326).
Supported by the National Natural Science Foundation of China(No. 61271326).
(责任编辑:王晓燕)
