基于有效感受野的目标检测算法
2020-08-27杨建秀
杨建秀
(山西大同大学物理与电子科学学院,山西大同 037009)
目标检测的任务是确定图像中所有感兴趣目标的位置和大小,是计算机视觉领域中的研究热点,广泛应用于智能视频监控、机器人导航、工业检测等诸多领域。但在实际的应用场景中,由于各类物体存在不同的形状、姿态、外观以及遮挡、光照等外界因素的干扰,使得目标检测存在着许多困难,特别是小目标的检测。由于深度学习爆发式的发展,目标检测算法已由基于手工特征的传统算法快速向基于深度学习的检测算法转变。
基于深度卷积神经网络的检测算法主要有两种,一种是基于两阶段(two-stage)的目标检测算法,如R-CNN 系列[1-2],首先要依据输入图像产生可能包含目标物体的区域候选框,然后对生成的区域候选框进行精细的分类和回归;另一种是基于单阶段(one-stage)的目标检测算法,如YOLO[3]和SSD[4]等,该算法直接在卷积神经网络中提取特征同时完成目标物体的分类和位置回归。针对小目标物体检测的算法,主要是利用网络内部多尺度特征金字塔的浅层预测完成对小目标的分类回归;同时为了增强小目标的特征表达能力,一些网络结构如FPN[5],RetinaNet[6]和RefineDet,利用自顶向下结构为小目标提供上下文信息。鉴于人脑识别小目标的策略,可以适当增大对小目标物体的感受野,就可以很好的识别目标。因此,本文提出一种基于有效感受野的小目标检测算法。该算法在单阶段目标检测算法SSD的基础上,利用自顶向下结构进行层间特征融合的同时,采用空洞卷积操作为小目标提供多样性的有效感受野来增强特征,使其学习到更有效的语义信息来提高小目标特征的判别性和鲁棒性,为解决小目标的识别检测问题提供一条新思路。
1 有效感受野的目标检测算法
1.1 网络结构
目标检测算法是在基于单阶段目标检测SSD[4]基础上实现的,整体结构共分为三部分,SSD 原始结构网络的特征提取层(Original Feature Layers,OFL),有效感受野模块(Effective Receptive Field Module,ERFM) 和最后特征增强的预测层(Enhanced Feature Layers,EFL)。整体的网络结构设计如图1 所示。本文沿用原始SSD 的基础网络结构VGG-16作为卷积特征提取的主干网络。由于较小的目标很容易在更深的卷积层中丢失,本文只保留了Conv1_1 到Conv_fc7 的卷积层,移除了Conv_fc7之后较深的卷积特征层,同时可保证利用自顶向下结构进行特征融合后可得到全局上下文信息来提供有效的感受野。因为较深的卷积层有更大的感受野,利用自顶向下结构添加上下文信息时会引入大量的背景干扰,不利于小目标的精确定位。同时根据无人机数据集中小目标尺寸分布情况,本文选择Conv3_3,Conv4_3,Conv5_3 和Conv_fc7 四个不同的特征层用于小目标物体的检测,生成四个原始特征提取层。然后根据本文提出的有效感受野模块将这些原始特征提取层转换为对应的四个增强的特征预测层P3、P4、P5和P6。最后利用soft-max分类损失函数和regression 回归损失函数实现多目标多类别的精确定位。
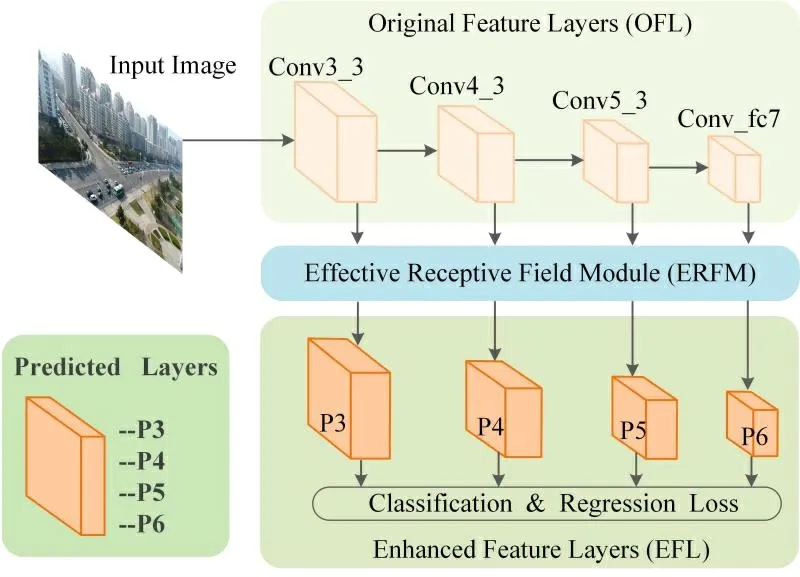
图1 目标检测的整体网络结构设计图
1.2 有效感受野模块(Effective Receptive Field Module,ERFM)
经典的FPN[5]和StairNet 利用自顶向下结构形成多尺度特征金字塔来增大感受野,但每一特征层的感受野都是相同的,限制了目标检测的性能。本文提出的有效感受野模块ERFM在利用自顶向下结构在网络内部形成一个多尺度特征金字塔的同时,在具有一样感受野的特征层中利用空洞卷积提供多样性的感受野。空洞卷积[7]可以在不降低分辨率的情况下来增大感受野,同时又可以进一步获取多尺度的上下文信息,而且不需要引入额外参数。因此,ERFM 不仅可以利用自顶向下结构提供全局的上下文信息增大有效的感受野,也可利用空洞卷积得到多样性的感受野,使其目标学习到更为有效的上下文信息和语义信息。因此ERFM为小目标提供了增强的特征表示,提高小目标的判别能力和鲁棒性,其结构图如图2所示。
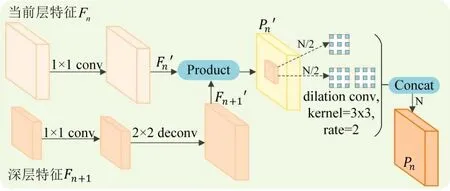
图2 有效感受野模块(ERFM)
为确保当前特征能够与深层特征进行点对点相乘(element-wise product),本文先对当前特征层Fn进行1×1 卷积得到Fn',然后深层特征Fn+1也进行1×1 卷积,并对其结果进行反卷积操作得到和Fn' 相同大小尺度的特征层F'n+1。将Fn' 和Fn+1'进行点对点相乘得到新的特征图Pn',本文对新的特征图Pn' 按通道数分为两半分别对其进行不同次数的空洞卷积操作,最后将其结果级联在一起得到增强后的预测特征层Pn。因此,ERFM利用自顶向下结构和空洞卷积操作为小目标提供全局和局部上下文信息的同时,又提供多样性的有效感受野来增强特征,使其学习到更为有效的语义信息来提高小目标特征的判别性和鲁棒性。
2 实验结果与分析
2.1 实验环境
为了验证本文的算法性能,本文实验数据采用公开可用的无人机车辆数据集[8],其中训练图像样本的数量为23,258,测试样本为16592 张图像。人工标注图像中的3类目标分别为小汽车、卡车和公交车作为训练数据集。实验的硬件环境为NVIDIA GeForce GTX-1080Ti GPU,软件仿真平台为Ubuntu16.04 操作系统下的Caffe 深度学习框架[9],CUDA版本为8.0,cuDNN 版本为6.0。本文实验利用公开分类网络VGG ISSVRC[10]的权重作为网络训练的初始值,训练图像大小为300×300,每批次训练图像数量(batch size)为16。训练所用初始学习率为0.001,训练次数共为120 k次,在80 k次和100 k次时学习率降为0.0001和0.00001.
2.2 实验结果分析
移除了SSD中Conv_fc7之后的卷积层,利用自顶向下的结构为小目标提供全局上下文信息得到合适有效的感受野,避免较深层引入太大的感受野会带来较多的背景干扰;同时利用空洞卷积操作为小目标提供局部上下文信息从而得到多样性的有效感受野来增强特征。由图3可以看出,本文提出的小目标检测算法对不同尺度、形变、遮挡、模糊程度和照明度等情况下能够保持高的召回率以及具有良好的检测性能。
3 结论
针对小目标判别性不足的问题,本文借鉴人脑识别小目标的策略,适当增大小目标感受野有利于它的准确定位,为此提出一种有效增大感受野的小目标检测算法。本文以单阶段多尺度特征预测的神经网路结构为基础,利用自顶向下的结构将深层语义特征和浅层细节特征进行融合,为小目标提供全局上下文信息来增大有效的感受野;同时利用空洞卷积在不降低分辨率的情况下增大感受野,可以进一步获取多尺度的局部上下文信息增强小目标的特征表示。实验结果表明,本文提出的基于有效感受野的小目标检测算法,可以较好解决处于遮挡、阴影干扰等复杂环境下小目标定位问题,为中高级计算机视觉问题提供良好的预处理手段。
