基于专家系统与DAN网络的围棋局面判断算法
2020-08-25王彦博
李 枫,王彦博
(1.北华大学大数据与智慧校园管理中心,吉林 吉林 132013;2.天津大学建筑工程学院,天津 300350)
计算机博弈(也称机器博弈)是现代人工智能领域的热点问题,也被认为是人工智能领域最具挑战性的研究方向之一.计算机博弈就是让计算机像人类一样,学习并实现博弈功能.简而言之,就是希望计算机有类似人一样的准确思维、判断和推理决策能力[1].计算机博弈有两次受到全世界关注:第一次是在1997年,“深蓝”计算机国际象棋程序打败人类世界冠军卡斯特罗夫;另一次是在2016年,由谷歌团队设计的阿尔法围棋(AlphaGo)以4∶1战胜了李世石.这两次胜利,不仅给计算机博弈领域带来了巨大的突破和影响,同时也掀起了整个人工智能领域的研究高潮[2].围棋人工智能一直是计算机博弈领域的重点,开发运用的算法及决策方式有助于扩大智能计算方法的适用范围,解决一大类优化、决策和规划智能问题,从而进一步扩展人工智能的疆域.蒙特卡洛评估是一种动态评估方法,与传统利用单纯围棋知识的思想完全不同,更多地利用数学统计中的概率思想,在一段时间内大幅提高了计算机对围棋局面判断的水平,实现了由传统计算机围棋到现代计算机围棋的飞跃[3].阿尔法围棋开拓出的利用深度学习——人工神经网络解决计算机围棋问题的方法进一步拉开了计算机棋手与人类棋手的差距,利用价值评估系统以及增强学习网络成为研究、讨论的热点.但就形势判断来说,单纯使用神经网络需要训练大量有标签的棋谱,对硬件条件、时间、数据量要求都非常高.基于此,将传统的蒙特卡洛、专家系统等方法与神经网络相结合成为一个研究方向.但在没有配备高端服务器的情况下进行神经网络局势判断存在以下问题:第一,大规模数据及其标签不容易获得;第二,训练所需时间太长,对机器性能要求太高.因此,为了解决传统方法专家系统评估不准确,单纯使用“势函数”带来计算误差,以及采用“value net”方法训练时间太长及对机器性能要求过高的问题,本文选择专家系统模式库、影响函数给出特征值,将特征值传递给深度适配网络(Deep Adaptation Network,DAN),利用少量样本训练获得较好的评估模型[4].
1 围棋规则及局面评估
1.1 围棋规则
围棋,是一种智力运动,起源于中国,有几千年历史.当代围棋主要使用纵横各19个垂直交叉的方格型棋盘,形成361个交叉点(在围棋中称为“点”).棋局开始后,双方各执一种棋子,黑先走,轮流下子,交替行棋,落子后不能移动.
对于输赢的计算一般有3种规则,即日韩规则、中国规则和应氏规则.其中,日韩规则在终局时需黑贴6.5目,中国规则为黑贴3又3/4子,应氏规则为黑贴8目.
1.2 围棋局面判断
局面评估,在围棋中称为“形势判断”.在人类棋手的对弈中,一张一弛正确与否大部分取决于对形势判断的精确程度,能否做到张弛有序,取决于对形势判断与局部及全局协调的计算能力;对于围棋智能对弈系统,局面评估同样至关重要.在早期的围棋对弈软件中,大部分选择把确定目数(围棋中对所占区域的专业术语)作为形势判断的依据,忽略了“势”(围棋中对于隐藏势力的描述)、“孤棋”(没有完全活,但有存活可能性的棋子或棋串)对当前局面的影响.后来的改良方法加入了“势函数”,即将各个棋子对距离为“1”(相邻一格)的影响力赋予一个对应值(如“9”),随着距离增大依次递减.这种方式较大地提高了形势判断的准确性,但得出的判断值依旧不能完全体现当前局面的优劣.
2 基于价值评估的局面判断算法
基于价值评估的围棋局面判断流程见图1.本算法利用专家系统中的影响函数计算产生特征值并输入到深度适配网络,通过小样本数据训练,可以得出围棋局面判断网络.网络采用深度适配网络DAN.
2.1 专家系统及影响函数
专家系统主要用来组成价值评估模块.将通过专家系统计算到的知识库特征与影响函数计算出的特征值输入到深度适配网络中,形成计算机对棋面的价值评估,如局面分布、黑白棋当前形势、厚薄等等.知识库应用相对简单,主要通过模式匹配:死活库简化计算机对基本死活型的判断,定式库给出可能的下一步选点,模式库对3×3棋盘分块.遍历比对输入数据,若符合知识库的特征则作为之后网络的输入特征使用.
围棋中的影响函数按照一定规则(比如根据棋子的数量、有无断点等)判断价值,之后计算每一个棋子对周围一定范围的影响值.如果出现某交叉点受多个棋子影响,则根据己方或对方的方式进行权值叠加计算,最后给定阈值,将当前棋局划分出黑、白势力范围,赋予相应数值.影响函数的计算需要3步完成:评估、规范化、生成.
本文提及的影响函数[5]见图2.如果将该影响函数产生的数值直接输入DAN网络进行训练,会引起网络参数迭代过程漫长、难以收敛.因此,对数据进行预处理.预处理特征值生成方法:由影响函数分成3个特征图,第1个特征图表示黑方的控制范围,即取值为+1的位置为1,其余为0;第2、第3个特征图分别表示白方的控制范围以及每个交叉点是否属于棋子能够影响到的范围.通过以上方法得到的特征值可以更好地输入DAN网络进行训练而不会产生歧义.
2.2 评估算法中的DAN网络
由于传统的神经网络是以完整的图像输入,生成标量化的结果概率分布,而本算法输入的特征值是多个维数不同的向量,且希望得到的是19×19带有标签的向量结果,因此,选取输入、输出较为灵活的DAN网络.
图3为DAN模型结构,该模型结构围绕循环构建了一个代理结构.为了避免像传统蒙特卡洛方法盲目选择搜索空间,此模型只能通过前文中的特征值范围来观察可选空间,即去掉了许多冗余的搜索部分,提升了时间和空间效率.模型总体架构包含6个AL以及2个FC(全连接层).6个AL分别具有64、128、256、512、512个内核;两个全连接层大小为1 024.将3×3个内核用于6个AL的卷积层和循环层,并且在每个AL后带有ReLU激活函数,同时使用2×2的最大池化层.所有这些卷积层和递归层都经过归一化处理.全连接层之后为ReLU激活函数和SOFTMAX计算,最后得到的结果成为输出值.其中,非法点在输入部分设置为0.
特别地,在训练过程中,将目标函数J(θ)设置为
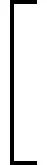
其中:Ep(si:r:θ)为第p层的模型输出;R为奖励值,比如设置结果胜为1,负为0;si为第p-1层输出局面;r为第p层输入坐标;θ为第p层实时参数.为了避免出现过拟合问题导致参数难以优化,将梯度样本θJ(θ)近似化为
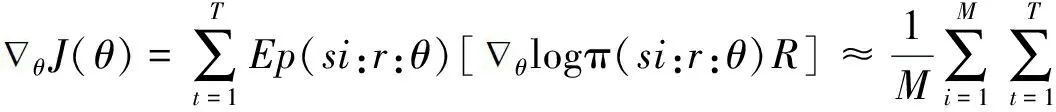
其中:M表示步数.
3 实验数据及实验过程
3.1 实验数据
本文实验使用两个数据集进行训练和测试.第1个数据集来自GoGoD(2015年冬季版),数据包含82 609个已有棋谱,训练部分以中国规则的数据为主,包含约70 000个棋谱.本实验没有选用常用的KGS棋谱数据集,原因是该数据集中有很多中、低级别数据,影响训练效果.为了充实数据,还收集了一个新的围棋数据集(PGD),包含25 000个专业棋谱.以上数据集格式均为SGF格式.
为了方便实验,每个数据均由以下几种变量作为标签训练:DTEVPWWRPBBRRE,分别代表日期、比赛类型、黑棋、白棋、选手名称、黑棋实力、结果.训练网络过程中产生的特征见表1.

表1 训练特征通道
3.2 实验过程
在局面评估系统中,由于只负责对当前局面进行选点,输入数据为专家系统提供的局面特征,输出数据为下一步要走棋的位置,因此,训练过程也是以某个局面作为输入,下一步走棋位置作为输出.本文训练中的数据集包括大量棋谱信息,如比赛双方信息、时间、比赛结果等等,以及一棵用于表示走棋顺序的结点树.
训练中,网络以训练数据的特征作为输入,并与其标签计算交叉熵来迭代训练网络,使得参数最佳.首先将围棋中的19×19局面视为具有19×19通道的图像,每个通道编码信息由表1数据组成.其中,深度适配网络部分由1个标准的卷积层和1个设计的循环层组成.首先执行图像矩阵的卷积运算,从先前的图层中提取局部邻域特征,之后在输出的前一步使用递归方法,迭代提高参数的训练精度.在此过程中,每个神经元都随着迭代次数优化.
本文使用Caffe框架实现深度适配网络DAN[6].作为目前深度学习常用框架,Caffe框架训练方便,可用多种语音调用.本文采用Python语言调用Caffe框架,完成深度适配网络训练.棋步产生即等价于调用1次前向算法,利用Python语言实现前向算法.在交互过程中,当轮到计算机落子时,界面模块通过系统调用Python前向算法,并返回1个走棋位置.在训练过程中,本文分别尝试了训练3层、5层和8层深度适配网络,在保证收敛的情况下努力尝试提高神经网络的泛化能力,最终确定使用8层深度适配网络作为棋步产生引擎.
图4为本实验中网络针对两个数据集迭代过程中精确度的变化情况.由图4可知:两个数据集的精度都在网络迭代次数为190~210区间达到峰值,之后随着迭代次数的增加产生过拟合现象,导致精度下降.
3.3 实验结果及分析
由图4可知,本文实验中的神经网络在面对高维数据(比如上万次大数据)时,没有出现大幅跌宕,非常理想地呈现出精度随着迭代次数先上升再下降的规律,尤其是在PGD数据上表现更为优秀.由此表明,使用影响函数和专家系统为神经网络提供特征值的方法,有效避免了精度跌宕的问题,更好地进行了神经网络参数优化,解决了当前直接使用神经网络训练造成结果大幅度震荡、参数无法收敛的问题.
为了使结果更加直观,本实验进行了算法可视化,结果见图5.由图5可见:在进行价值评估时,通过局面评估(如分块、形势判断等等)给出了基于专家系统的几个选点(红色标记).其中,图5 a左上1/4棋盘更多地利用了专家系统中的定式库,下1/2盘则更多地利用了棋局本身的特征;由于棋局复杂,图5 b给出了更多的候选点,这些候选点更多地由分块的价值评估得出.可视化结果进一步表明了专家系统和影响函数在选取特征值时的作用,在输入特征值后,DAN网络可以给出较好的评估结果.
4 小 结
本文针对传统围棋人工智能中使用蒙特卡洛方法、传统专家系统以及单纯人工神经网络中对局面判断的不足,提出基于价值评估——利用影响函数、模式库产生特征值,将特征值传递给DAN网络来搭建围棋局面判断模型,解决了传统局面对“势力”等隐形价值评估不准确,单纯人工神经网络耗时长、训练难度大的问题.实验证明,本文算法无须在大型且深入的搜索空间中进行交互训练(只需要200次左右的迭代)就可以得到相对较好的评估结果.下一步将改进神经网络部分结构进行落子预测,更精确地进行形势判断.比如,可以利用在计算机视觉中表现较好的残差网络,或是丰富现有的专家系统,以及更加丰富的围棋深度知识为形势判断提供更加精确的结果,以提高训练准确率.
