条件变分时序图自编码器
2020-08-25陈可佳张嘉俊
陈可佳 鲁 浩 张嘉俊
1(南京邮电大学计算机学院 南京 210023)2(江苏省大数据安全与智能处理重点实验室(南京邮电大学) 南京 210023)(chenkj@njupt.edu.cn)
许多现实世界的数据(如蛋白质交互网络[1]、社交网络[2]、引文网络[3]等)都可以抽象为图的形式,以表示数据中对象之间的复杂关系.在传统的复杂网络分析中,网络特征的提取需要专家手动进行,很大程度上依赖于网络的类型、专家的经验和特定的任务类型.网络表示学习(也称为图嵌入)[4-5]旨在从网络中学得有效的低维向量表示,已出现了许多有效的算法[6-8]来捕获网络的拓扑结构信息.大多现有的网络表示学习算法假设网络中的节点和边固定不变.然而,现实网络通常是动态的[9],节点和边会在不同的时刻出现或消失.例如引文网络中论文的数量和引用关系均会随时间不断地累积.对动态网络进行建模时,应该考虑节点和边随时间的变化情况,通常的做法[10]是将动态网络表示为一系列的静态网络快照,分别计算每个快照网络下的嵌入表示,然后将所有快照下的嵌入对齐并映射到相同的向量空间中.为此,需要设计一个联合优化函数找到共同的嵌入向量,进行非凸和非线性优化问题.
目前,深度神经网络已在计算机视觉、自然语言处理等领域展示了其优秀的数据表示能力,并在静态网络表示学习中取得了巨大的成功[11-12].与基于矩阵分解和基于随机游走的方法相比,基于深度神经网络的方法更能有效拟合复杂的非线性目标函数,因而更适用于解决动态网络表示学习问题.Kipf等人[13]在变分自编码器的框架中使用静态的图卷积作为编码器、内积作为解码器指导隐层的表示学习.受该工作的启发,本文尝试在条件变分自编码器的框架下解决动态图嵌入问题,使用深度图神经网络聚合网络的结构、节点的属性和时序信息.我们首先使用边的时序信息改进传统的图卷积操作,得到时序图卷积模型,然后加入到条件变分自编码器框架中,训练得到网络的动态嵌入.其中,条件变分自编码器也可换为自编码器或变分自编码器.
本文的主要贡献包括4个方面:
1) 提出了一种能同时聚合网络结构、节点属性和时间信息的时序图卷积模型;
2) 时序图卷积作为编码器放置于自编码器或变分自编码器框架中,实现动态图嵌入;
3) 在此基础上进一步使用节点的邻域时序信息,实现条件变分时序图自编码器模型;
4) 不同类型网络数据集上的实验结果表明,本文提出的模型可以获得更有效的动态图嵌入表示.
1 相关工作
动态网络表示学习是一个具有挑战的问题,需要考虑网络随时间的演化结构.根据所采用的技术,已有的动态网络表示学习方法大致可分为4类:基于矩阵分解的方法、类skip-gram的方法、基于自编码器的方法和基于图卷积的方法.
基于矩阵分解的动态网络嵌入是将静态网络矩阵分解的思想引入动态网络,通过矩阵摄动理论逐步更新网络的嵌入表示.例如:DHPE模型[14]使用时间快照作为节点特征的采样粒度,将广义奇异值分解和矩阵摄动理论运用于邻接矩阵上,在保证节点高阶相似性的前提下,随着边的增加或删除及时更新节点的表示.
类skip-gram的动态网络嵌入是将整个网络视为语料,找到能表征网络演化的方法对语料进行采样,最后使用skip-gram模型[15]对语料进行训练.例如:CTDNE模型[16]将动态网络表示为一个连续时间网络,在时间序列限制下进行随机游走,得到的随机游走序列集合可视为静态网络下随机游走序列集合的子集.通过捕获连续时间下节点之间的依赖性,该模型有效解决了时间快照方法导致的精度损失问题.
基于自编码器的动态网络嵌入大多是对静态网络中的SDNE模型[17](即基于半监督深层自编码器的网络嵌入)的改进和扩展.例如:DynGEM[18]模型将动态网络拆分为不同的快照,对每个快照网络使用SDNE学到该时刻下的网络嵌入,后一时刻模型的初始化参数直接来自于前一时刻,从而加快了训练速度.随后,Dyngraph2vec[19]模型对此进行了改进,将先前一组(而不仅仅是前一时刻)快照网络的表示学习参数作为输入,得到下一时刻的网络嵌入,从而捕获每个时刻中节点之间的非线性交互关系以及多个时刻之间的交互关系.
基于图卷积的动态网络嵌入根据中心节点和邻居的动态关系,更新中心节点的表示.例如:DyRep[20]模型将网络划分为2个动态过程,即通信过程和动力学过程.通信过程描述的是2个节点之间的交互情况,越频繁表明关系越密切.动力学过程描述了网络的结构进化,记录新加入的节点和边.该方法使用了注意力机制,一方面根据通信频率衡量邻居节点的贡献度,另一方面捕获与中心节点可能交互的所有节点.HTNE[21]模型将Hawkes过程理论引入到模型之中,考虑到邻居节点对中心节点的影响会随时间衰减,来动态学习节点的表示.M2DNE[22]模型是对HTDE的一个改进,提出微观和宏观2个层次的动态性,在微观层利用注意力机制来更新中心节点的历史邻居节点的权重,在宏观层次检测图在下一时刻产生边的准确性,结合2层动态性学习节点的表示.
然而,大部分的动态网络嵌入方法是无监督地学习网络结构的动态变化,得到了与任务无关的嵌入表示,该结果对于特定任务类型(如节点分类、链接预测等)可能并非最优.而且很多方法仅考虑网络拓扑结构的嵌入而忽视了节点自身属性对嵌入结果的影响.此外,采用划分时间快照的动态网络嵌入方法也不可避免地造成了信息的损失.
受到静态VGAE[13]模型的启发,本文提出一种条件变分时序图自编码器(conditional variational time-series graph auto-encoder, TS-CVGAE)模型,以及它的自编码器版本(TS-GAE)和变分自编码器版本(TS-VGAE).该类模型使用图卷积聚合了结构、属性、时序等多种信息,在连续时间网络中学习节点的动态嵌入.
2 基本定义
在详细描述本文算法之前,我们先给出动态网络、动态网络表示学习、自编码器、变分自编码器以及条件变分自编码器的基本定义.
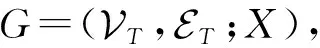
注意,在本文模型中节点的属性是固定不变的.但在有些应用领域中,节点的属性也可能随时间发生变化.此外,本文动态网络的定义中将节点之间的交互视为边,时间戳记录边出现的时刻.
图1的有向图表示一个动态网络的局部.2个节点之间箭头上的数值表示它们产生关系的时刻.例如节点v1和节点v2在时刻1交互,节点v2和节点v6在时刻4和时刻6均进行了交互.

Fig. 1 Local area of an entire dynamic network图1 动态网络的局部图
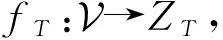
定义3.自编码器(auto-encoder, AE)[23].一种人工神经网络,可以自监督地学习输入数据的有效表示,包括编码器(encoder)和解码器(decoder)2个部分.编码器的任务是通过训练神经网络来学习输入数据的低维表示.解码器的任务是通过定义重构损失从隐层低维表示中生成一个尽可能接近输入数据的原始表示.
定义4.变分自编码器(variational auto-encoder, VAE)[24].VAE是AE的变种,假设隐变量服从高斯分布,编码器分别学习出高斯分布下的均值和方差,并使用这两者生成隐层向量表示Z,并采样得到隐变量,用于还原目标数据X.
变分自编码器不仅可以捕获结构和属性非线性相似性,还可以学习到数据的分布,适用于稀疏网络表示学习任务.但是VAE是一种自监督模型,没有考虑数据的额外信息.
定义5.条件变分自编码器(conditional varia-tional auto-encoder, CVAE)[25].CVAE在编码器和解码器中可以加入数据的标签或者其他先验知识作为条件,在条件概率c下对隐变量Z和数据X建模.
3 条件变分时序图自编码器
本文提出的条件变分时序图自编码器(TS-CVGAE)主要包含2个部分:1)采用时序图卷积作为编码器在同时聚合多类信息;2)采用内积(inner product)作为解码器来重建邻接矩阵.一般来说,序列化模型(如LSTM)能够较好地捕捉到图数据的动态变化,而图自编码器则可以较好地学习到网络节点的拓扑结构特性.
3.1 时序图卷积
动态网络中往往同时存在拓扑结构信息、节点属性信息和边的时序信息.本文提出了一种时序图卷积(time-series graph convolution network,TGCN)模型,即在图卷积的过程中同时聚合这3类信息,作为TS-CVGAE的编码器.
传统的静态图卷积操作[10]是为中心节点聚合其邻域节点的属性(例如简单的求均值操作),忽略了中心节点和邻域节点之间交互的时间信息.本文在图卷积操作之前,将中心节点的所有边按其出现的先后顺序(时间戳)对另一测的邻居节点进行排序.通过这一约束融入邻域的时序信息,作为模型的输入.从信息论的角度来看,网络中具有时序的节点序列集合是不含时序的节点序列集合的子集,即时序信息的加入将减少了嵌入的不确定性.
具体来说,TGCN分为3个步骤:
1) 根据网络中边的信息对每个中心节点的邻居节点采样,得到固定数量k-1个的邻居节点(加上中心节点本身一共k个采样点).目前,算法仅采样一阶邻居节点,未采样高阶邻居节点.如果采样数量达不到k-1,则放回后继续采样.如图2所示,中心节点v2的邻居节点有v1,v3,v4,v5,v6,其中v6被采样了2次.
2) 按边的时间戳对所有采样节点进行排序,使得新的邻居节点排在后面.例如:节点v2的时序邻居节点序列如图2右侧所示.
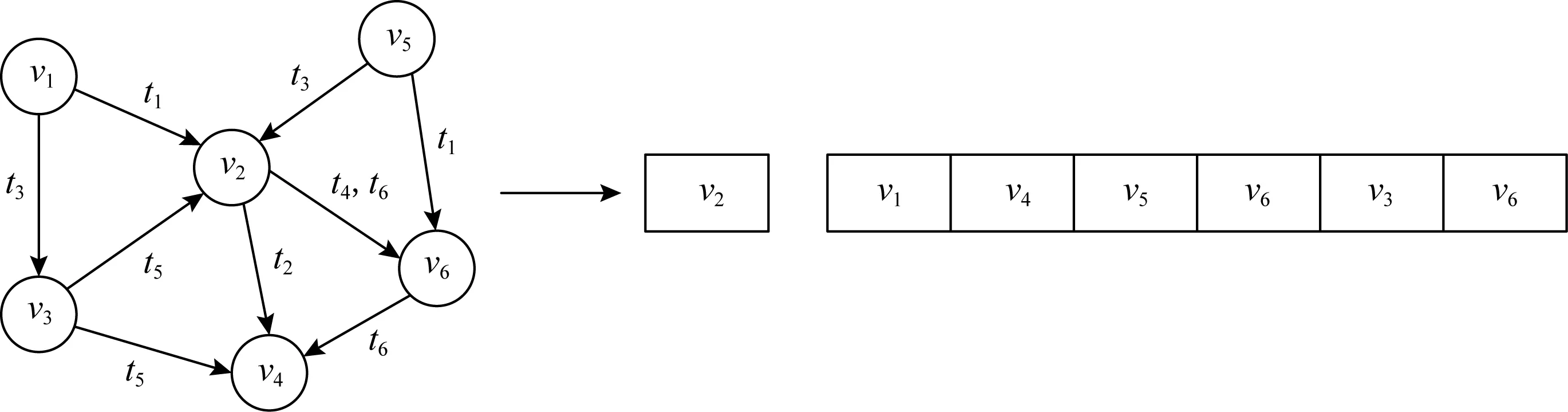
Fig. 2 Time-series neighborhood node sequence for node v2图2 为节点v2生成时序邻居节点序列
3) 将基于时序的邻居节点序列以及中心节点一同送入处理时序信息的运算模型(如本文使用LSTM[26]模型),以此聚合邻域的信息,得到中心节点的嵌入表示.
3.2 整体框架设计
本文使用条件变分自编码器框架,将拓扑结构作为自监督信息,将提取的时序信息作为条件,指导时序图卷积更好地实现编码,最终学习到节点的动态嵌入.图3为TS-CVGAE的整体框架图.
输入层包含了动态网络G中为每个节点采样得到邻居节点序列的集合.
编码器使用深度时序图卷积进行编码.本文模型采用了2层时序图卷积,形式化定义如下.
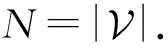
在条件变分自编码器中,编码器生成隐层变量的公式为
(1)
其中,q(zi|A,X,c)为后验概率,服从条件高斯分布(c为条件),即:
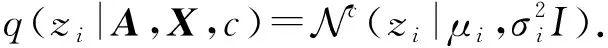
注意,在变分自编码器中,我们用的后验分布是标准高斯分布.
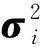
μ=TGCNμ(A,X,c),
(3)
logσ2=TGCNσ2(A,X,c).
(4)
最终,编码器使用了2层时序图卷积,即
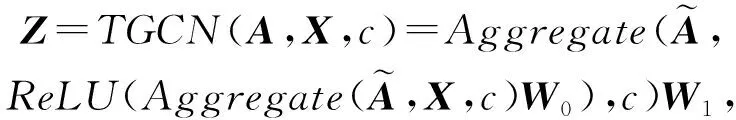
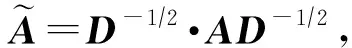
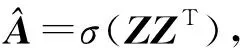
其中,Z是2层时序图卷积学得的嵌入矩阵,即Z=TGCN(A,X).
重构概率表示为
(7)
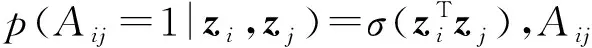
由于条件变分自编码器希望学到的隐层表示满足条件高斯分布,即:
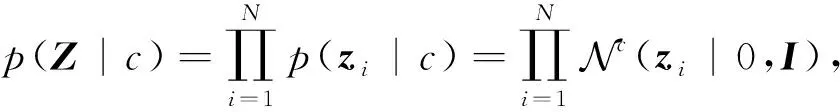
相当于数据加上了高斯噪声,使得模型更加鲁棒.
本文模型的损失函数最终形式化为
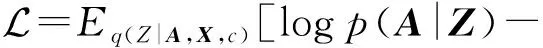
(9)
其中,KL [q(·)‖p(·)]计算q(·)和p(·)之间的KL散度.
算法1.TS-CVGAE模型的伪代码.
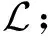
输出:嵌入矩阵Z.
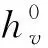

④ 从G中得到节点v的一阶邻居集Nt(v);
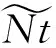
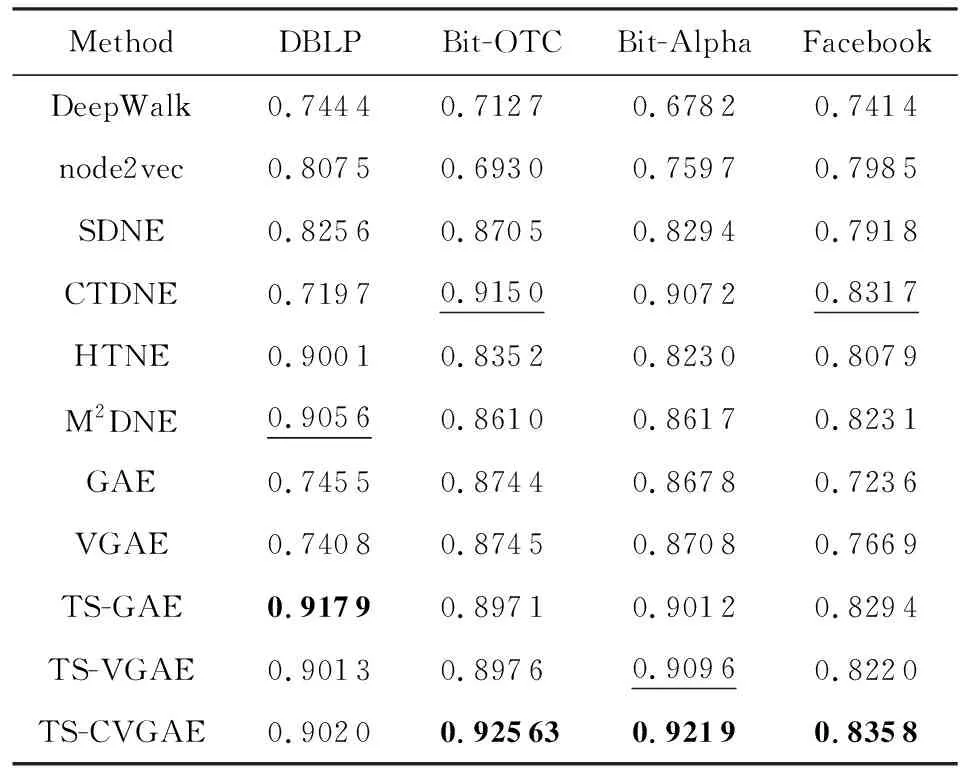
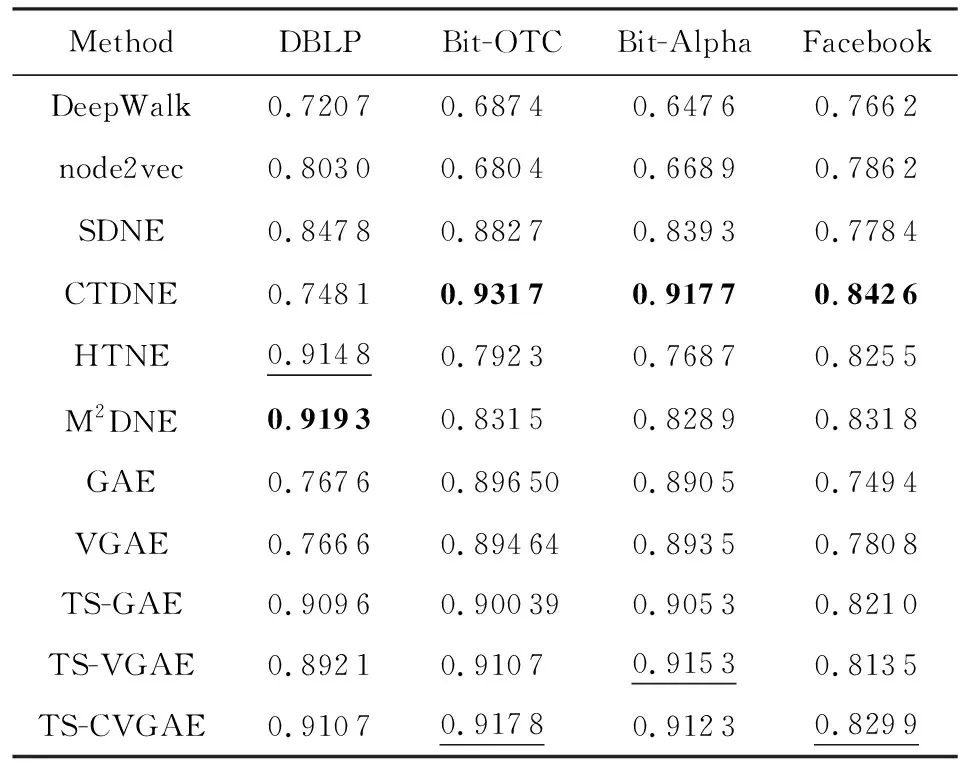
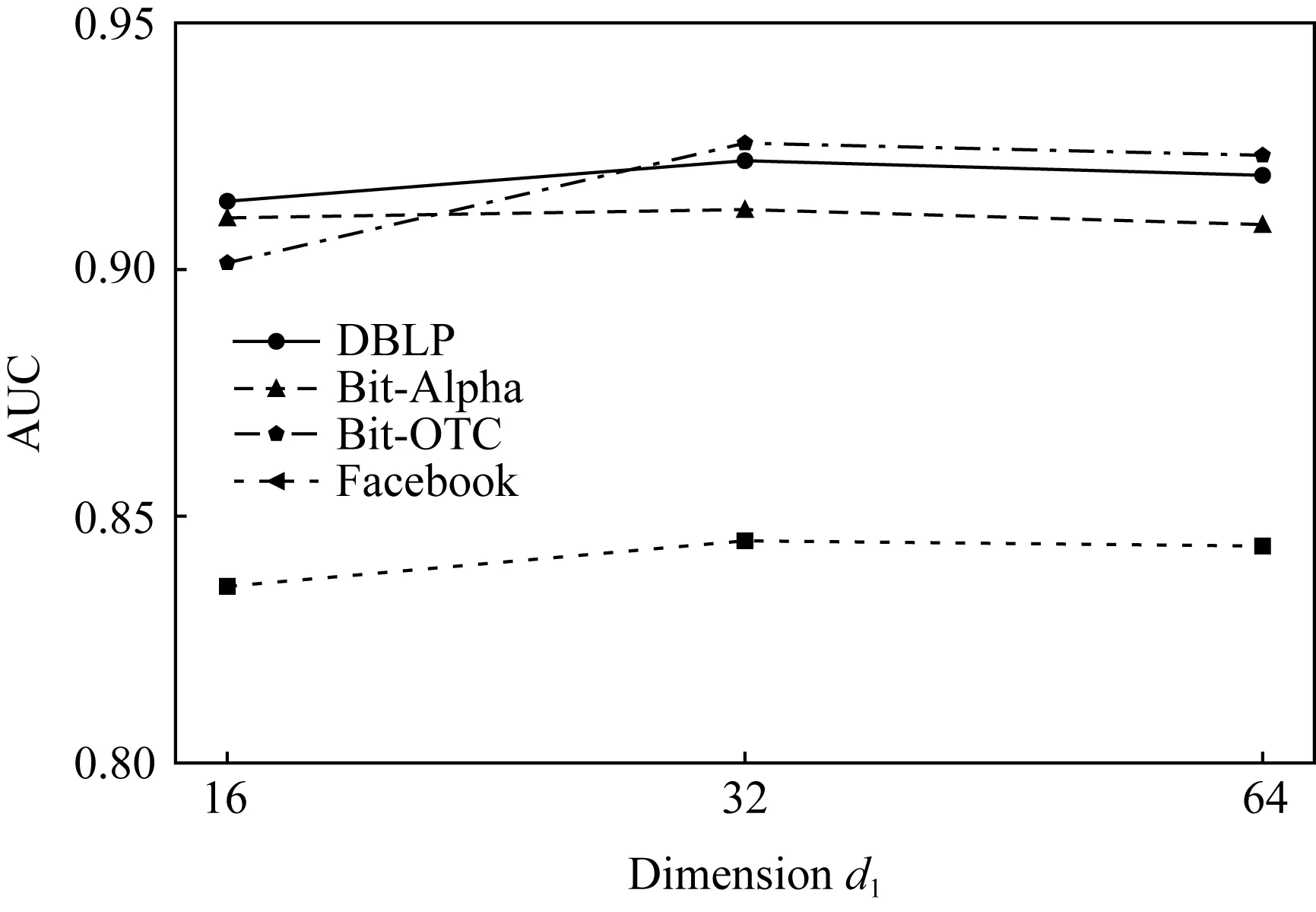
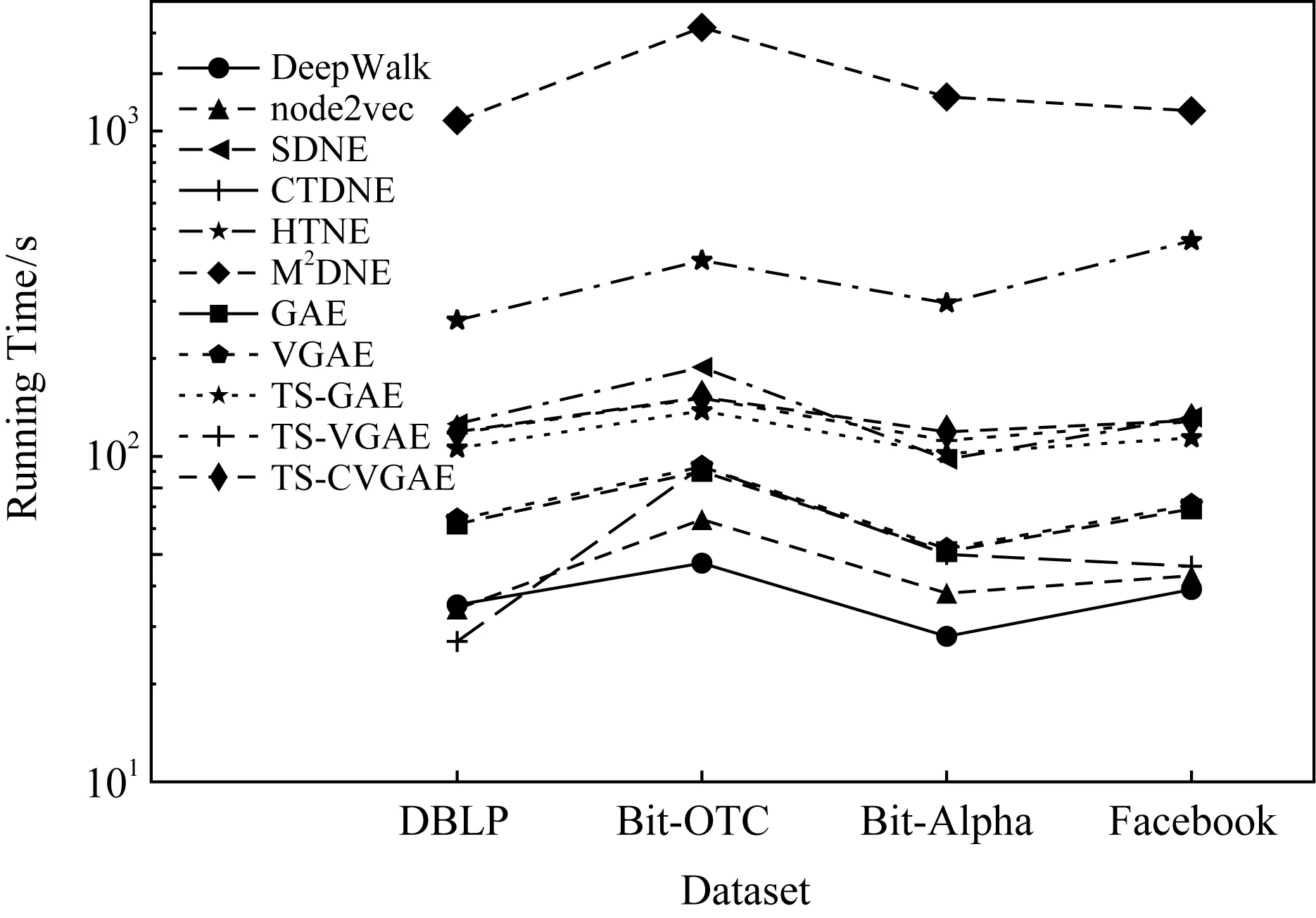
⑥ if |Nt(v)| /*如果数量达不到,则进行有放回抽样,使得|Nt(v)|=k-1*/ ⑧ end if end for end for 根据式(9)计算损失函数; 我们将本文提出的动态网络嵌入方法与传统静态网络嵌入方法、采用自编码器或者图卷积的动态网络嵌入方法进行了链接预测实验,间接地比较各方法的嵌入效果. 实验采用了4个带有边的时间戳的现实网络数据集,分别为:Bitcoin-OTC(1)http://snap.stanford.edu/data/soc-sign-bitcoin-otc.html,Bitcoin-Alpha(2)http://snap.stanford.edu/data/soc-sign-bitcoin-alpha.html,DBLP(3)http://konect.uni-koblenz.de/networks/dblp_coauthor和Facebook(4)http://konect.uni-koblenz.de/networks/facebook-wosn-wall. Bitcoin-OTC和Bitcoin-Alpha数据集分别来自不同的比特币交易平台的用户网络.由于在各类交易平台上比特币用户是匿名的,为了降低交易风险和避免欺诈,网络中的用户之间需进行信用评分(范围从-10~10).这2个数据集的节点为用户、边为用户之间的评分关系、评分时间跨度约为5年.其中,Bitcoin-OTC网络含有5 881个用户节点,共产生了27 373个评分关系;Bitcoin-Alpha网络含有3 783个用户节点,共产生了17 907个评分关系. DBLP数据集为计算机领域的论文合作者网络.网络中的节点为作者,边为作者节点之间的合作发表关系.实验从2001—2016年之间的数据中采样了5 000个作者节点,共产生了11 762个合作关系. Facebook数据集包含了在线社交网络中用户的互动行为.网络中的节点为用户,边为用户之间的留言关系.实验从2005—2009年之间的数据中采样了5 000个用户节点,共产生25 380个留言关系. 由于有些数据集的节点存在原始属性而有些并不存在,为了公平比较,我们均使用单位矩阵I代替节点的属性矩阵X. 比较方法包括经典的静态网络表示学习方法(DeepWalk和node2vec)、采用自编码器或者图卷积的静、动态网络表示学习方法(SDNE,GAE,VGAE,CTDNE,HTNE和M2DNE)以及本文方法的变体(TS-GAE和TS-VGAE). 1) DeepWalk[6]是最经典的静态网络表示学习方法,先根据随机游走产生若干节点序列,然后将序列送入到Skip-Gram模型学习节点的表示. 2) node2vec[7]是对DeepWalk的改进,结合了深度优先(DFS)和广度优先(BFS)2种搜索策略.基于DFS游走到达节点的概率和基于BFS游走到达节点的概率不同. 3) SDNE[17]使用深度自编码器对节点间的一阶和二阶相似性进行建模,采用重构损失捕获二阶相似性,采用拉普拉斯特征图计算直接相连节点表示的差值来捕获一阶相似性. 4) CTDNE[16]是动态网络表示学习方法,按时间序列进行随机游走,即游走序列中下一条边的时间大于当前边的时间,然后将得到的序列送入Skip-Gram模型学习节点的表示. 5) HTNE[21]方法按照时间顺序选取一定数量的历史邻居信息,通过Hawkes过程理论计算不同时刻的历史邻居节点对当前节点的影响力,学习节点的低维表示. 6) M2DNE[22]方法是对HTNE的改进,通过引入注意力机制来计算不同的历史邻居对中心节点的影响,并结合下一时刻预测边的准确性,共同学习节点的低维表示. 7) GAE[13]是静态图自编码器,使用图卷积做编码器,可以同时抽取网络中拓扑结构信息和节点属性信息,在解码器中使用内积运算来预测网络的关系. 8) VGAE[13]是GAE的变分自编码器版本,两者的不同在于GAE使用的是基础自编码器框架,而VGAE使用的是变分自编码器框架. 9) TS-GAE是本文TS-CVGAE方法的自编码器版本,使用了2层时序图卷积作为编码器,但未使用时序监督信息. 10) TS-VGAE是本文TS-CVGAE方法的变分自编码器版本,同样使用了2层时序图卷积作为编码器,未使用时序监督信息. 对于TS-CVGAE,TS-VGAE,TS-GAE,VGAE和GAE方法,实验使用Adam[27]优化方法进行200次迭代训练,学习率为0.01.这5种方法均使用2层图卷积,每层的嵌入维度分别为32和16(即VGAE和GAE所在论文[13]中的设置).DeepWalk,node2vec和CTDNE方法使用各自论文中提供的标准设置,即每个节点进行10次长度为80的随机游走,窗口大小为10.SDNE方法也使用Adam优化方法进行200次迭代训练,学习率为0.01,2层的嵌入维度分别为1 000和16.HTNE和M2DNE方法的参数使用原文实验的设置,即负采样数量为5,历史邻居数量为5,M2DNE方法的平衡因子为0.4,进行学习率为0.01的200次迭代训练.为了公平比较,所有方法的最终输出嵌入维度均设置为16. 本文在4个数据集上分别进行了链接预测任务来评估各个模型的性能.比特币网络的预测目标是2个用户是否会产生信用评分,合作者网络的预测目标是2个作者是否会合作,社交网络的预测目标是2个用户是否会留言互动.实验随机选择50%的数据集作为训练数据集,20%作为验证数据集,剩余做为测试数据集. 当模型学到节点的嵌入表示后,我们计算每个节点对的内积并排序作为最后的预测结果.我们采用AUC(area under ROC)[28]和AP(average precision)[29]作为方法的评价指标. 表1和表2分别汇总了所有方法在4个数据集上的链接预测AUC值和AP值.其中,黑体数值表示对应方法在当前数据集下表现最优,加下划线的数值表示对应方法在当前数据集下表现次优. Table 1 Link Prediction in AUC indicator表1 链接预测的AUC指标值 Table 2 Link Prediction in AP indicator表2 链接预测的AP指标值 实验结果表明:2种经典的静态网络表示学习方法DeepWalk和node2vec的性能是最低的.SDNE要优于前两者,验证了图自编码器的有效性,不过该方法将整个邻接矩阵作为自编码器的输入,未能学到时序信息,因此总体性能要低于动态图表示学习方法.CTDNE在比特币网络和社交网络中的表现较好,其AP值甚至高于本文的方法,但在DBLP合作者网络中的表现较差,说明该方法对网络的类型较为敏感.基于节点影响力的HTNE与M2DNE在DBLP数据集中表现较好,可能的解释是,如果2个作者的共同合作者在某一个领域更具有影响力,那么2个作者合作的机会明显增加.GAE和VGAE方法的链接预测结果要低于对应的TS-GAE和TS-VGAE.例如在Bitcoin-Alpha数据集上,TS-VGAE的AUC值要比VGAE高出近4%.这验证了本章提出的时序图卷积操作的有效性.在DBLP数据集上,TS-VGAE的AUC要比VGAE高出12.6%.这说明对于稀疏的网络,基于时序的聚合对于节点嵌入的影响更大.VGAE和GAE方法的链接预测性能相当,TS-VGAE和TS-GAE也没有显著差异.例如对于合作者网络DBLP和社交网络Facebook来说,TS-GAE的AUC值稍高于TS-VGAE,而在信用评价网络Bitcoin-OTC和Bitcoin-Alpha上则是TS-VGAE的性能略好.这说明变分自编码器未显示出绝对的优势.TS-CVGAE方法在大部分的数据集中获得了最优的AUC值,除了在DBLP数据集上略低于TS-GAE方法,说明在学习中加入邻域的时序监督信息能够改进节点的嵌入结果.在AP指标上的比较结果(如表2所示)也得到了类似的结论. 总体来说,本文方法在4个数据集中均取得较优的预测性能,说明其受网络拓扑结构的影响更小,能够适应不同类型的网络. 本文还分析了TS-CVGAE模型中时序图卷积的输入节点序列数k对最终链接预测结果的影响.我们分别测试了当k=3,5,7,9时4个数据集上链接预测结果的AUC值,如图4所示: Fig. 4 AUC values of TS-CVGAE under different parameters k图4 不同参数k下TS-CVGAE的链接预测AUC值 实验结果表明:尽管不同的网络中节点的稀疏程度不同(Bitcoin-OTC的平均度为10.1,Bitcoin-Alpha的平均度为7.2,DBLP的平均度为4.7,Facebook的平均度为10.2),但大多是在k=7的时候获得较好的结果(除了Facebook数据集中,k=9比k=7的结果略高).这说明,本文模型在不同数据集下的表现是相对稳定的.k值过小对于大部分节点无法充分地聚合邻居信息,而k值过大则可能过采样了邻居节点而造成多余的噪声.此外,从时序的角度来看,当序列跨度过长时,时间过于久远的邻居节点对信息聚合的作用过小,也会导致性能的下降. 由于本文TS-CVGAE模型采用了2层时序图卷积,我们令每层的嵌入维度分别为d0和d1. 我们首先观察d1=16时,d0的变化对TS-CVGAE的链接预测AUC值的影响. 如图5所示,当固定d1=16时,d0取值为128或者64时TS-CVGAE模型的性能更优.这说明加入时序信息后,模型的复杂度应相应提高,以充分学习网络的动态嵌入. Fig. 5 Impact of embedding dimension d0 on AUC values图5 嵌入维度d0对于AUC结果的影响 随后,我们固定d0=128,观察d1的变化对TS-CVGAE的链接预测AUC值的影响.如图6所示,当d1=32时TS-CVGAE模型的性能更优. Fig. 6 Impact of embedding dimension d1 on AUC values图6 嵌入维度d1对于AUC结果的影响 不过,为了和GAE和VGAE方法保持一致,本文在进行比较实验时还是选用了d0=32,d1=16的设置. 本文还比较了各个方法在4个数据集上学得网络嵌入结果时的运行时间.由于DeepWalk,node2vec和CTDNE均是基于随机游走策略生成序列输入Skip-Gram模型进行训练,在运行时间上相差不多.SDNE是把整个图输入深度自编码器训练,运行时间与节点的个数、自编码器的层数有直接的关系.HTNE与M2DNE是基于时间序列对历史邻居进行采样,所以邻居节点的数量、负采样的数量、时间戳的数量对模型的运行时间均有影响.GAE和VGAE采用图卷积作为编码器,运行时间低于SDNE,但要高于DeepWalk,node2vec及CTDNE.本文提出的3个模型均采用了时序图卷积,与简单图卷积比需要更多的训练参数来学习时序信息,因此运行时间略高于GAE和VGAE.总体来说,本文方法与SDNE方法的运行时间相当,但远低于HTNE和M2DNE的运行时间. Fig. 7 Running time comparison of all methods in 4 datasets图7 4个数据集上所有方法的运行时间比较 本文提出了一种基于时序图卷积和条件变分自编码器的动态网络表示学习方法TS-CVGAE.该方法改进了经典的图卷积模型使其能够提取邻域的时序信息,并将其作为编码器加入条件变分自编码器的框架中,实现了对动态网络的嵌入.在4个现实网络数据集上的对比实验结果表明:与现有的经典图嵌入方法以及基于自编码器的动态图嵌入方法相比,TS-CVGAE均取得了最优的链接预测结果.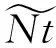
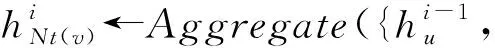
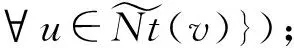
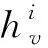
4 实 验
4.1 实验数据
4.2 比较方法
4.3 实验设置
4.4 链接预测结果比较
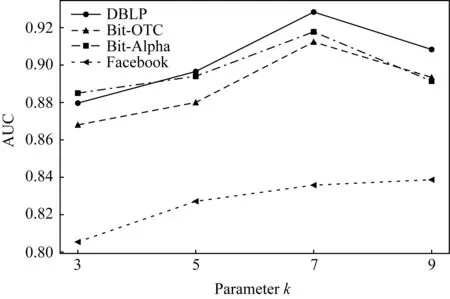
4.5 超参数k分析
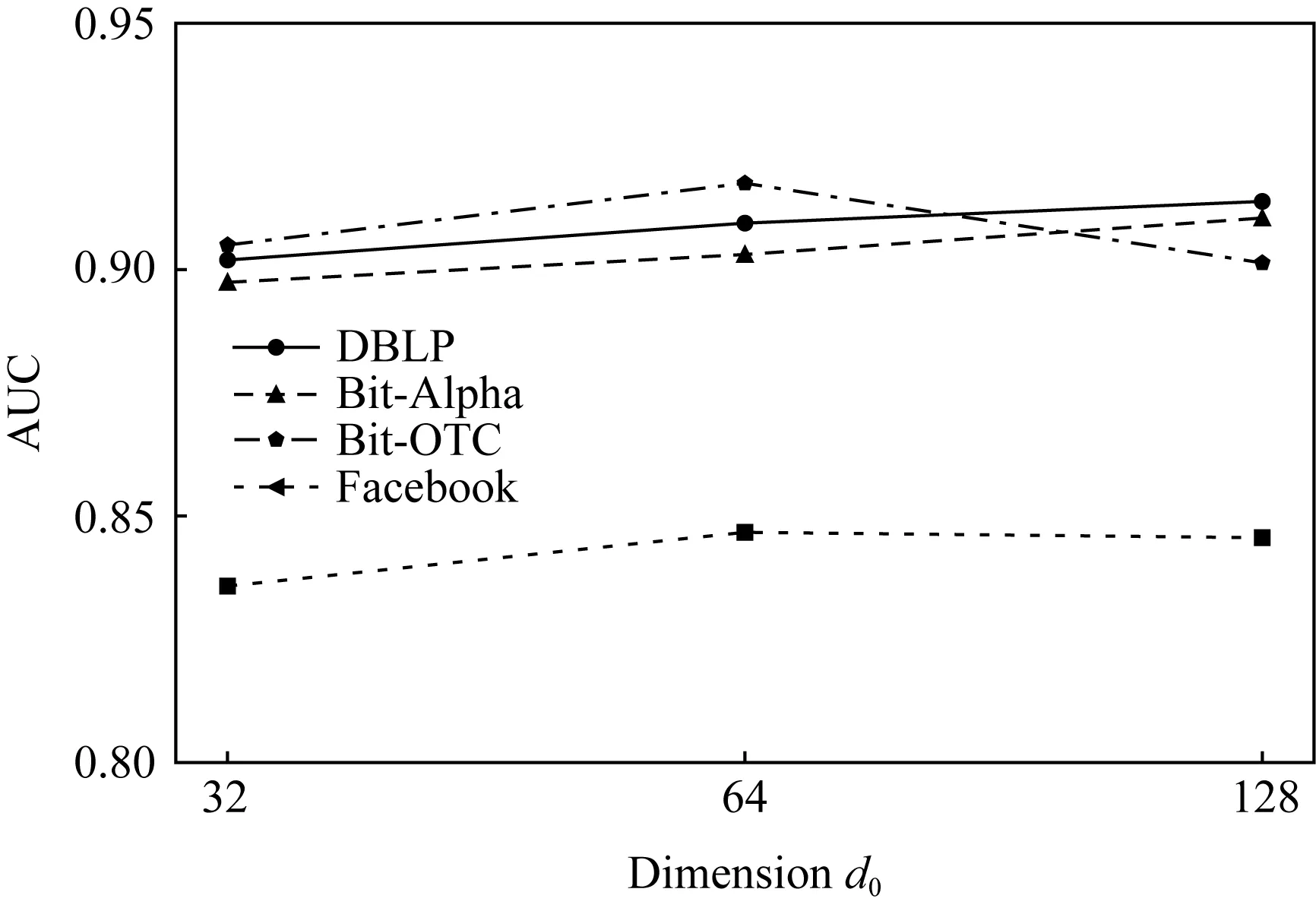
4.6 嵌入维度d分析
4.7 运行时间比较
5 总 结
