基于环境视频语义的云制造资源描述
2020-08-21陈友玲吕松洋段克华
陈友玲,张 哲,刘 舰,吕松洋,段克华
(重庆大学 机械传动国家重点实验室,重庆 400044)
0 引言
随着经济的飞速发展,传统制造企业急需加速转型,云制造作为一种新型的智能制造模式,为传统企业的转型需要提供了新的思路,但云制造模式对企业信息共享程度要求较高,从而对企业资源的准确描述提出了挑战。因此,如何快速准确地对企业现有资源进行描述,已经成为大多数转型企业需要解决的问题。
由李伯虎院士等[1-2]提出的云制造是基于互联网的一种旨在提供制造服务、效率高且耗能低的新型智能制造模式,具备虚拟化、物联化等典型的技术特征;Fisher等[3]重新定义了云制造的新概念,认为云制造是一种面向服务的业务模型,用户可在云平台上共享制造资源和能力,分析并总结了其灵活、可扩展、多租户等特性。云制造凭借“分散资源的集中管理和集中资源的分散服务”的思想实现了“制造即服务”的目标,在该制造模式中,首先需要解决的是原始资源的语义描述。
目前,有关云制造资源的语义描述大多以本体为基础。杨琛等[4]采用本体技术对制造云进行描述并创立了复合制造本体,此外基于此建立了服务发现模型,推理了制造云的分解与组合,完成了制造云的智能搜索和自动匹配;Taieb等[5]基于本体和深度分布量化给定概念的下位子图,并使用一些与之相关的拓扑参数,提出了一种量化概念之间语义相似度的新方法,为人类判断和计算量度之间的相关系数提供了一种新的解决方法。在基于服务本体描述语言(Ontology Web Language for Services, OWL-S)的语义描述云制造服务方面,江萍等[6]基于本体描述逻辑提出了一种新的匹配方案,并详细阐述了该方案的各阶段,使查全率和查准率得到有效提升;Sánchez等[7]基于本体分析了适用于信息内容(Information Content, IC)计算的方法,并提出旨在更好地捕获语义的若干改进证据,以便在特定概念的本体论中进行建模;此外,江萍[8]建立了与导弹相关的领域本体,对比Web服务语义描述技术介绍了OWL-S技术;李孝斌等[9]针对现代智能匹配的需求,构建了基于服务建模本体的资源描述框架,并研究了该框架的支撑技术;Sánchez等[10]根据分类学的开发特征,提出一种新的基于本体的测量方法,并在一个通用环境下对该方法进行验证,结果表明该测量方法不仅提高了测量的精度,而且降低了测量的局限性;汤华茂等[11]通过构建资源的分布式语义描述模型,实现了对资源粒子的虚拟描述,同时创建了集成智能化的服务模型;薛建勋[12]创新性地从广义上重新定义了制造能力和制造资源,借助OWL本体语言设计了描述云制造资源的本体模型,并用实例验证了该模型的灵敏度和柔性;王海丹等[13]尝试提供一种云制造服务分类及描述的方法,从不同方面对云制造服务资源进行描述,并设计了本体模型;常关羽等[14]面向企业的需求,综合本体语义和Petri-net技术对业务流程进行了建模和验证。
此外,还有一些采用创新性的模型研究,杨琨等[15]由创新认知激励机理将设计方法语义化描述的服务和知识资源所形成的知识服务进行组织,完成了产品概念设计的辅助、激励作业;蔡敏等[16]基于语义描述构建了工作流过程模型,强调过程的影响,从而达到了全面增强时间管理的目的;Song等[17]提出了一种基于本体的自组织遗传算法用于进行文本聚类,并将聚合后的本体集合作为基于语料库的本体论依据,结合本体策略验证该算法能有效提高性能;秦飞巍等[18]针对特征模型不易检索重用的难题,基于本体提出了特征表示模型和新型本体映射方法,通过对特征信息进行语义描述,建立了基于本体的特征模型库,以支持参数化特征模型的检索重用;张星[19]分析了云制造环境下生产加工云的基本信息,建立了语义描述机制和模型,着重研究了服务体系架构,实现了服务的智能搜索和自动匹配;Sánchez等[20]针对云制造环境下语义描述的经典措施存在的过分依赖于分类学/本体论结构和适用性的问题,提出基于上下文和可扩展版本分类学知识进行IC计算,以避免措施的依赖性并最大限度地减少语言歧义;林廷宇等[21]对交互情景的各个事件进行了语义描述,解决了组合中的冗余和互斥的问题,实现了动态的组合;冯建周等[22]通过构建语义关系图,结合组合结构模型、搜索算法、最优的服务组合路径,解决了因图搜索中存在的搜索空间大导致的组合结构不易表达的难题;周竞涛等[23]提出语义网格服务的集成方法,完成了从网络语义互联逻辑集成架构向网格语义物理集成架构的映射。
上述文献均对云制造环境下的语义描述进行了深度探究,而且颇有成果。但目前语义描述的重点依然在本体模型上,基于本体的语义描述研究旨在对资源、服务进行高度的概括,并在概括的基础上逐层分解并进行详细的解释。虽然不乏相应的改进,但不难发现,依然存在资源描述实时更新缓慢和后续匹配的查全率、查准率及效率低下的问题。
为了更快、更准确地对资源和服务进行描述,本文首次引入环境视频(envideo)的概念,环境视频意指包含所处环境空间内容信息的视频数据。因此,相对传统的云制造资源的语义描述,环境视频的多地关联表示也为相似的环境场景的表达降低了工作量,且提高了云制造环境下资源匹配的效率。此外,视频语义描述意在对视频内容涉及的资源进行描述,具有对既定环境空间动态、实时和真实感进行表达的优势,不但符合现代人们直观感知和认知特点,而且在后续匹配方面更为客观、全面,对于智慧城市的建造及云制造的广泛推行具有重要意义。
1 环境视频语义模型的层次结构
环境视频内容变化的显示表示的重点在于将环境视频场景变化中的载体、驱动力和呈现模式3个关键因素及其相互关系具体化为具有关联性的环境实体和场景、对象行为和多层次事件对象,并依次抽象为相互关联的特征域、行为过程域和结果域3个层次。为使复杂环境视频中的不同视频能关联表示和推理,本文提出统一环境框架下的视频语义,该框架如图1所示。
(1)特征域(feature-domain) 环境实体和场景(Oen)作为特征对象,是环境变化的载体,环境实体既可以是具有改变自身状态能力的对象,也可以是不具有主动能力的对象,而场景通常表示为由各个不同的对象组成的状态相对不变的对象组,由条件(C)、实例(I)、语义(Sen)和关系(R)4种元素描述,即Oen=({C},{I},{Sen},{R})。其中:{C}约束表达Oen的环境范围、结构类型、状态等性质条件(二维图像、三维模型);{I}为{C}范围下的对象结构(栅格结构、真三维几何模型等);{Sen}表示Oef的语义描述所需的特征参量与附加属性,表达了Oen的变化条件和能力,通常由对象的特征语义和环境实现框架下的位置语义组成,位置语义由位置的相对或绝对描述、方位、拓扑及度量等主要要素构成,而范围、组成、色调、目的等位置的外延约束由此产生,在位置语义描述对象的空间分布及其关联表达的基础上,外延约束为事件的判断提供依据;{R}表示Oen和行为与多层次事件映射关系(state mapping)。
(2)行为过程域(behavior process-domain) 对象行为(Oob)是视频内容变化的主要来源,与环境实体的空间关系、状态等属性的变化相适应,也是视频语义解析与分析的元单元,包括关键状态(key state)、变化流程(variation process)、语义(semantics)及关系(relationship)4元素,即Oob=(KS(Oob),VP(Oob),{Sob},{R})。其中:KS(Oob)表示一系列生命周期关键状态的显形表达(开始、变化、停止状态等);VP(Oob)指实体对象行为产生的环境单元描述、表达式或有序离散点描述的对象运动轨迹、对象内部或对象间的关系变化轨迹,记为连续变化的非线性模型或离散变化的线性时间戳模型;{Sob}指Oob的行为变化、结果和影响的语义描述,由动作语义和轨迹语义组成,动作语义旨在描述对象行为类型和特点,强调特征如无参照的机加工件的切换、旋转等及操作人员的动作等动作描述,有参照的其他操作人员的靠近、通过、离开等动作描述;轨迹语义着重描述了行为的结果和影响,由轨迹特征语义(如车床的车削、钻头、车丝、滚花等)、轨迹地理语义(如加工对象、操作人员的移动路线)以及轨迹关系(如相交、平行等)组成。在视频对象依赖环境实体和场景的同时,环境实体和场景的特征语义描述也表现了对应实体的行为能力,因此需对实际应用中涉及的对象行为进行定义和分类。{R}指Oob和多层次事件间的聚合关系,聚合作用表现为:对象行为需按自身满足的语义关联要素推理并构建语义关联关系行为链,为多层次事件表达的实现提供理论基础。

相对于传统语义描述时仅针对单个的实体和场景来说,多层环境视频语义资源描述框架旨在对整个制造资源、制造流程及制造结果进行描述,对整个制造过程的把控较强,后续基于语义相似度对制造过程中的实体和阶段进行相似排序,一旦中间环节出现问题能灵敏感知,在现有情况下迅速启动最优方案,因此适用于时限要求精确和制造环境及制造流程相似的制造场景。与其优势对应,多层环境视频语义资源描述方法在存储环节之前增加了语义相似度排序的过程,因此会相对增加计算量。此外,对于制造流程相差较大的某些制造场景来说,相似性较低,发生事故时匹配替代的可能性较小,其中间环节替代性较差,优势不明显。
2 环境视频数据的多层次表达
按视频内容的改变、对象行为的改变及对应环境的改变划分基础研究对象,可将环境视频分为环境视频帧、环境视频镜头和环境视频镜头组3个层次,其中各层次的定义范围和结构特点如下:
(1)环境视频帧(Oef) 是环境视频数据最基础的结构和数据变更的分析单元,表示为Oef=({I},{C},{Sef},{R})。其中:{I}为静态图像中和编码格式相对应的实体对象,分别分离提取相对动态变化的环境实体和相对静态不动的场景实例化为前景和背景图像;{C}为数据的基本属性(分辨率、帧率、码率、编码格式等);{Sef}主要负责对图像的物理特征(成像参数、时刻、姿态、摄像方位等)及可选相关图像的分离规则等的语义描述,与特征域内各对象的相对应;{R}为环境视频镜头和环境视频镜头组与Oef间状态的映射关系。
(2)环境视频镜头(Oes) 令环境视频数据结构化的动态单元。过程域中的Oes表达式为Oes=(AP(Oef),KS(Oef),{Ses},{R})。式中:AP(Oef)为基于状态映射关系与相似性划分后数据的环境视频帧的有序序列,且该序列中的帧的语义项{Sef}和实例化条件{C}的取值相似;KS(Oef)是AP(Oef)中语义项极值的一个环境视频帧或具有相互不相关性最大的多个环境视频帧;{Ses}包含对摄像机镜头外部以及解析出的镜头内容中一系列对象行为的语义描述,与行为过程域中对象相对应;{Ses}为在时间的约束下Oef能够表现出更高维度信息的语义描述,如某时间段内的语义等;{R}体现环境视频镜头组与Oef在由AP(Oef)规定的聚合规则下的聚合关系。
(3)环境视频镜头组(Oesg) 表现为特定规则下动态发展形成的有序视频镜头集。与传统单摄像头存储的物理上连续的视频场景实体对比,环境视频镜头组为一组支持不同摄像机记录实体对象及其运动轨迹的连续动态且符合逻辑规律的环境视频镜头[24]。针对事件域的Oesg表示为:Oesg=({RL},{P(Oef)},{Sesg},{R})。式中:{RL}为支持关联多地环境视频镜头规则库的子集;{P(Oef)}表示{RL}条件约束下遵循Oes-Oesg及Oes-Oesg递归嵌套聚合规则的环境视频镜头集合,与基于相似性数据Oef与Oes间划分不同的是Oes与Oesg间的聚合借助于环境视频语义的关联推理得以实现;{Sesg}综合描述了Oesg内容语义,表现了{P(Oes)}中{Ses}的关联表示所能表达到的更高层次的含义,与事件域的对象对应;{R}体现了Oesg对Oes的控制约束,这些约束大体分为两大类:①环境视频各场景间的时空约束(多分辨率、多视角和多视点等);②环境视频场景对象间的时空约束(对象间的时空拓扑关系以及事件间语义关系(原因影响、反馈与包含等))。至于实例应用方面,语义关联关系需要通过对各环境视频镜头、环境视频镜头组的视频内容进行推理和判断获得。此外,将环境视频镜头与环境视频镜头组进行关联映射是对实体资源进行多层次的语义描述的前提,换而言之,在实例应用中环境镜头组实例取决于多层次描述实例。特定结果语义描述涉及的一组镜头对象聚合表示的内容与储存该结果镜头组相对应,聚合后的环境镜头组不仅可以用于实现对各时空尺度内不同实体资源进行动态实时的语义描述,还可以实现不同时空尺度的相同实体资源进行相同的表达,有助于实现异地资源的无差异描述。此外,因时空分辨率不同,摄像机对同一资源内容细节的层次表达的多镜头组的成像会有所不同。
多层次环境视频语义模型结构借助统一建模语言(Unified Modeling Language,UML)[25]进行构建。其中,环境视频数据中3个递进聚合的粒度(环境视频帧、环境视频镜头及环境视频镜头组)分别表达从EnvideoStructure衍生来的3个重要成员CEnvideoFrame、CEnvideoShot和CEnvideoGroup。为了成功对这些对象类成像信息和实际数据进行描述,摄像机元数据和实际图像编码的附加类(CSimpleImage、CViewpoint、CCanera等)需明确定义,相关信息不仅是体现实际环境视频数据的基础,而且是后续推理判断各环境视频场景关联表示的基础。其中至关重要的是,为对环境视频进行语义描述,将已有的环境视频数据映射出的视频语义层次(环境实体和场景、实体对象行为和多层次资源描述)分别表示为从InnerSemanticObject[26]衍生来的3个重要成员CEnEntity、CObject Behavior、CHierarchical Result。此外,对环境场景内对象内容进行语义描述的特征语义类(CProperty Semantic)、位置语义类(CLocation Semantics)、动作语义类(CAction Semantics)及轨迹语义类(CTrajectory Sementics)进行规范描述是描述环境视频语义的前提。为此,本文重新设计了支持多环境视频内容和环境语义,以CEnReference Trans为母类的统一时空语义框架作为环境视频语义类的关键变量。
传统云制造环境下的资源语义描述是针对单个实体的逐层抽象映射,而环境视频语义是对整个资源环境的描述,数据规模大幅增长,对相应的技术也提出了较高要求,该语义描述方法涉及的应用技术主要包括视频分析技术和储存技术。
视频分析技术分为特征处理、语义分析、信息描述和视频检索4个主要部分。特征处理用以分析视频的特点以及组成结构,系统地选择、建立、论证能够有效反映视频内容的低层特征,从而能够对视频内的对象、场景以及高级情感语义进行分析,可以采用颜色特征、纹理特征以及形状特征进行处理;语义分析是基于图像理解、计算机视觉、模式识别等基础算法,采用适合视频语义的识别及理解模式,可以在低层与高层语义之间建立合理、普适的映射关系模型;视频信息描述与编码是基于已有标准进行视频的描述编码,并在评价标准的基础上进行标注;视频检索是视频语义分析的主要应用之一,视频检索工具的选择范围也比较广泛。
目前普遍通用的是精确识别且储存较大的视频识别摄像头,不同于更新滞后需对某一信息长时间储存的语义描述信息,视频语义信息的基本特点是动态实时更新,在规定的任务时限内及时更新,基本满足数据存储需求。因此,相关主要技术已较为成熟,可以为本文描述方法提供技术支撑。
3 实例分析
本文以实例场景作为视频数据来源进行视频语义的模拟分析,采用所提的环境视频语义模型实现对特定的视频数据的实时动态元数据描述和关联表达。实例数据选用Flexsim7.5模拟的简化某生产车间场景的实体对象,采用编号依次为O-01至O-17的实体对象,分别代表整个实体场景中的各设备及工作人员。
生产车间视频数据的多层语义描述要素主要由3部分构成:①特征域,以环境视频帧为基本分析单元,将3大类特征要素,即人员(管理者、操作者及后勤保障者等)、设备(加工设备、移动设备和仓储设备等)和环境构成(空间大小和结构)从动态实时变化的环境视频中解析出来。依据开放地理空间信息联盟(Open Geospatial Consortium,OGC)中室内多维位置信息标识语言(Indoor Geospatial Multidimensional Language,IndoorGML)标准对场景环境单元进行描述,囊括了特定时间内室内各物体的位置、联通等三维关系及室内各物体的包含关系等语义关系,为后续各实物的位置和轨迹语义的表达提供可靠来源。②行为过程域,按图像像素域的物理特征(光学和视觉等)及图像压缩域编码规则的相似性阈值分解出特定实物行为改变的环境视频镜头,并解析该实物的“合法”性行为(符合既定命令及要求的行为域)和“非法”性行为(不符合既定命令及要求的行为域)。③结果域,针对整个场景的紧急命令和紧急事件等,将与该命令和事件有关的镜头聚合成符合特定逻辑关系的环境视频镜头组。具体结构如表1所示。

表1 生产车间模拟视频监控三要素
表2所示为该生产车间模拟视频监控场景在某一时段内可能的包含人员活动的若干车间内的环境视频镜头,主要描述了该场景涉及的实体对象关联分析所需的位置和轨迹语义。由表2描述可得:该组环境视频镜头主要保留了该生产车间内两名操作员工和若干操作设备的生产环境所涉及的行为,其中搬运工07和搬运工08的轨迹语义表明他们的工作活动范围、生产产品种类及工作量等。对于设备来说,自身的工作情况则由产出物品的位置语义和轨迹语义来体现,同时可以根据操作员和各设备的工作量来预测任务的分配情况与执行情况的匹配程度,进而为云制造环境下各种资源匹配的合理性和精确性提供实时动态可靠的数据来源。
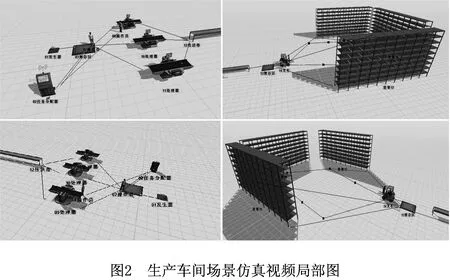
结合表2中生产车间内场景在统一时空框架下的位置语义,该组环境视频镜头中生产车间环境场景视频局部图如图2所示。模拟监控视频描述了一段时间内某一生产车间内的3种产品经由分配后先暂存于03号暂存区,再经由两名搬运工搬运至各自对应的处理器上,进而经过传送带传送至13号暂存区,最后通过叉车移至各自货架上的活动过程。环境视频镜头记录的各场景实体、位置及轨迹数据,是对任务命令的执行、完成情况以及现有可用资源进行实时有效语义描述的主要依据。本案例通过对动态实时的各环境视频数据进行处理,模拟描述了某一时间段生产车间内不同实体对象的生产活动。

表2 生产车间模拟视频实例的语义描述
实际应用中的制造资源构成的场景涉及到的实体单元通常较多,因此,视频规模一般也较大。针对该情况下的计算效率本文分两个角度解释:
(1)对视频语义描述的结果而言,该描述方法意在对视频内部的所有制造资源进行描述,但对特定企业来说,并不是所有企业的制造资源都参与制造任务,触发制造事件。针对闲置的资源,状态较单一,可以保留其更新状态直至其状态发生改变。因此,为降低计算效率,在中间过程环节可以截取部分必需的制造过程进行计算,尽可能地减少无效计算。
(2)该描述方法适用于多地视频的关联统一表达。在对异地实体资源进行视频语义描述的基础上,各环境视频帧、环境视频镜头和镜头组由空间、时间、对象(人、设备及环境单元等)等多维语义信息灵活地运用于时空语义一体化的高维索引构建中,有助于建立动态实时的资源云池及海量监控视频搜索任务的关联约束。在后续存储环节会将关联约束的视频统一储存组成具有某种特定功能的视频集,在既定的任务需求下,匹配时仅需搜索既定的视频集,以避免整个资源池的匹配搜索,极大地缩小资源云池内的搜索范围,显著提高后续云环境下视频语义的计算和资源匹配的效率。
4 结束语
本文针对传统云制造环境下资源语义描述方法单一且静态的局限性,创新性地提出一种基于视频特征提取的特征—行为过程—结果的多层次环境视频语义描述模型,该模型的创新点包括:①通过对环境视频内容变化的表达,综合考虑环境视频数据和内容变化的基本维度,实现了视频数据和场景的描述与映射规则的统一;②打破了传统云制造环境下的现有资源“理想最优”的局限,为匹配计划的可靠执行提供了支撑,为云制造的后续各环节的有序高效进行提供了保障;③将环境资源语义与视频内容语义有效结合起来,支持多地视频数据语义描述的关联表示,降低资源语义描述工作量的同时,提高了语义描述的效率。通过实例表明:模型不仅实现了多地环境视频内容和环境的语义映射,而且实现了视频面向云制造环境下动态实时数据特征和多视频间的关联性表达的功能,并基于此完成了对全生命周期内多阶段任务完成情况的感知和理解,进而建立视频语义资源云池及视频搜索任务的关联约束,从而提高了各云制造单元的动态实时描述的复杂关系的计算能力与表达效率。此外,环境视频语义描述的实行将大大降低云制造资源云池的构建难度,为云制造在广大企业的推广运用奠定了基础。
未来将在现有模型的基础上,综合考虑云制造环境下各用户间环境视频语义关联表示的各项指标、阈值和计算模型,为云制造环境下分布式环境视频大数据的语义关联的自适应、高效存储管理及关联检索等进一步的实际应用提供定量的基础理论支撑。
