融合CRF与规则的老挝语军事领域命名实体识别方法
2020-08-19何阳宇易绵竹李宏欣
何阳宇,晏 雷,易绵竹,李宏欣,3
(1.中国人民解放军战略支援部队信息工程大学(洛阳校区),河南 洛阳 471003;2.昆明理工大学 信息工程与自动化学院,昆明 650500; 3.密码科学技术国家重点实验室,北京 100878)
0 概述
随着大数据时代的到来,互联网已经成为军事情报获取的重要来源,但海量冗杂的数据也带来了“信息过载”的问题,命名实体识别(Named Entity Recognition,NER)是解决这一问题的有效手段。“命名实体”是在第六届消息理解会议(MUC-6)上首次使用的,可以简单地定义为“任何一个可以被专有名称指代的事物”[1]。在这次会议上,命名实体识别也作为信息抽取(Information Extraction,IE)的子任务被提出[2],之后迅速成为大数据分析、文本意义理解、语义表示、知识管理等研究领域的关键技术之一。近年来兴起的以知识图谱为基础的智能检索,其核心单元即为实体。
命名实体识别即识别文本中的专有名称,并将其划分到预先定义的类别。按照技术手段可以分为基于规则的方法、基于统计的方法以及深度学习的方法[3]。最早出现的命名实体识别系统大多是基于规则的,从20世纪90年代开始,统计方法逐渐成为主流。常用的统计模型有支持向量机(Support Vector Machine,SVM)、最大熵模型(Maximum Entropy,ME)、隐马尔可夫模型(Hidden Markov Model,HMM)、条件随机场(Conditional Random Fields,CRF)等,这类模型通常将实体识别任务形式化为从文本输入到特定目标结构的预测,使用统计模型来建模输入与输出之间的关联,并使用机器学习方法来学习模型的参数。例如,隐马尔可夫模型将命名实体识别视为字符串分类问题[4],条件随机场模型则将实体识别转化为序列标注问题[5]。最近广受欢迎的深度学习也被应用到了命名实体识别任务中,目前主要的命名实体深度学习架构有两类[6]:一类是神经网络-条件随机场(NN-CRF)架构[7],在该架构中,卷积神经网络(CNN)和长短期记忆(LSTM)网络被用来学习每一个词位置处的向量表示,基于该向量表示,NN-CRF解码该位置处的最佳标签;另一类是采用滑动窗口分类的思想使神经网络学习句子中每一个N-gram的表示,然后预测该N-gram是否为一个目标实体[8]。深度学习的方法虽然省去了统计方法中特征选取的过程,但需要更大规模的训练语料。对于老挝语这种低资源语言,构建大型标注语料库所需的人力和物力成本短期内是暂时无法承受的,将大量未标注或少量人工标注的数据集用于训练老挝语命名实体识别的统计模型更符合研究现状[9],并且实践证明单纯基于统计的方法会使状态搜索空间非常庞大,加入一定的规则等先验性知识也是有必要的。
关于老挝语命名实体识别的成果较少,老挝国内几乎没有专门研究,仅有文献[10]借助命名实体识别来提升老挝语分词的效果,其中的实体识别部分主要是利用规则的方法对人名和地名进行识别。国内主要有昆明理工大学对此进行了研究,其成果基本都采用机器学习的方法[11-12],取得了一定的成果,但囿于语料规模和质量,其识别结果难以泛化[13-14]。如果直接移植到军事领域,准确率可能会大幅下降。此外,尽管其中加入了一些规则和特征,但存在制定不准确、覆盖不全等问题,这势必也会影响识别效果。
本文提出一种融合CRF和规则的老挝语军事领域命名实体识别方法。首先在分析老挝语军事领域文本的基础上,选取了词、词性、指界词、通名和词典等特征训练得到CRF模型,从而实现老挝语军事领域命名实体的自动识别。然后对输出结果中的错例进行分析,并通过人工制定规则来提升识别性能。
1 老挝语军事领域命名实体识别类型
命名实体识别任务通常针对人名、地名和机构名三大类专有名词,结合具体研究领域和任务,本文需在此基础上进行增改。经综合考量,最终将老挝语军事领域命名实体分为人名(PER)、地名(LOC)、军事机构名(ORG)、武器装备名(WE)和军用设施名(FAC)等类型。
从广义上来讲,人名包括本名、别名、乳名、笔名、艺名等,但本文仅识别本名,即人的正式姓名称谓;地名是指某一特定空间位置上自然或人文地理实体的专有名称,自然地理实体包括山、河、湖、海、岛等,而人文地理实体包括国家、省、市、县、村等,即通常所说的行政地名;军事机构名可再分为指挥机构、编制单位、科研机构、军工企业、教育培训机构和医疗机构等几大类;武器装备名是武装力量用于实施和保障战斗行动的武器、武器系统和军事技术器材等的名称,包括枪械、火炮、坦克、装甲战斗车辆、作战飞机、战斗舰艇、弹药、导弹、水雷等战斗装备以及雷达、声呐、通信指挥器材、军用测绘器材、野战工程机械、军用车辆、保障舰船、辅助飞机、情报处理装备、电子对抗装备等保障装备[15];军事设施名是指用于军事目的的建筑、场地和设备等的专有名称,主要包括指挥工程、作战工程、军用机场、港口、码头、营区、训练场、试验场、军用洞库、仓库、军用通信、侦察、导航、观测台站和测量、导航、助航标志、军用公路、铁路专用线、军用通信输电线路、军用输油输水管道等。本文结合老挝实际情况,以军事工程、军事基地、军事交通设施、各类场地和塔台站为重点识别对象。
2 老挝语命名实体识别的难点
老挝语命名实体识别既有所有语言面临的共同难点,也具有其独特的个性难点,对此进行剖析有助于后续研究,具体如下:
1)英语等西方语言单词之间一般都有空格,并且专有名称首字母需大写,因此其实体边界非常易于确定,只需完成实体分类任务即可。而老挝语却不具备这样的先天优势,其缺乏丰富的词形变化和明显的形态标志,并且没有天然的词边界,分词、浅层句法分析等过程都会影响老挝语命名实体识别的效果。
2)丰富的语料资源对于命名实体识别任务来说相当重要,这也正是老挝语的不足。研究力量薄弱、关注度低等原因造成了可供老挝语命名实体识别使用的语料极为匮乏,专门针对军事领域的电子化资源则几乎没有,唯一的解决办法就是通过多渠道自行构建。即便如此,因为命名实体是一个相对开放的集合,新的命名实体会不断涌现,规模再大的语料库也难以做到及时更新和完全覆盖。
3)部分实体拼写较为随意,尤其是外来词,有时甚至不符合老挝语的拼写规则,老挝国内也没有权威机构对此进行规范管理。

5)老挝语中存在大量缩略词,这些缩略词往往就是命名实体,其形式较为多样,很难总结出规则,且有时会出现多个命名实体对应同一缩略词的现象。军事领域具有特殊性,文本表达通常言简意赅,因此缩略词的使用更为常见。
6)根据不同的任务和目的,实体的类别不再局限于人名、地名和机构名,出现越来越多的开放类别实体,本文所要识别的“武器装备名”等就属于此种情况。为了提高识别精度,便于后续应用,实体划分的颗粒度也越来越小,如本文中的地名可被细化为国家、省、市、县、村等。

3 基于CRF的老挝语军事领域命名实体识别
3.1 条件随机场
条件随机场自2001年LAFFERTY等人[5]提出以来,因其简单的操作原理和良好的性能在自然语言处理等领域迅速受到了广泛欢迎。之后,MCCALLUM[16]率先将其用于命名实体识别。经过不断改进,其成为目前命名实体识别中最成功的方法[17]。它是一种用于分割和标注序列数据的概率化结构模型,在已知观察序列X的情况下,计算输出标注序列Y的条件概率P(Y|X)。
与隐马尔可夫模型(HMM)、最大熵马尔可夫模型(MEMM)等其他序列标注模型相比,CRF弱化了独立性假设,只需考虑已经出现的观察序列的特性,能够充分利用上下文信息,易于融合不同的特征,同时其在全局范围内进行参数优化和解码,避免了MEMM和其他判别式马尔可夫模型会出现的标记偏置(Label Bias)问题。CRF和MEMM之间的关键区别在于,MEMM使用每个状态的指数模型来确定当前状态的下一个状态的条件概率,而CRF则利用单个指数模型来计算整个标注序列和给定观察序列的联合概率。因此,在不同状态下不同特征的权重可以相互替换[5]。
CRF可以被视作一种无向图模型或者马尔可夫随机场[18]。从理论上来讲,只要在标注序列中表示一定的条件独立性,其图结构可以是任意的,但一般用来解决序列标注问题的是最为简单且常见的一阶链式结构,如图1所示。

图1 条件随机场链式结构Fig.1 Chain structure of CRF
本文定义:X=x1,x2,…,xn为给定的观察序列,即由n个词组成的老挝语语料,Y=y1,y2,…,yn为输出的标注序列,即为被预测出的实体标注序列。那么,输出序列的条件概率可定义为:
(1)
其中,Z(X)为归一化因子,它可使所有可能状态序列概率之和为1,可由式(2)得出,tj(yi-1,yi,X,i)为转移函数,表示对于观察序列X在当前位置i及前一位置i-1上标注的转移概率,sk(yi,X,i)为状态函数,表示当前位置i的标注概率。以上两个函数统称为特征函数,都依赖于局部特征。在命名实体识别过程中,当满足特征模板条件时,取值为1,否则取值为0,λj和μk分别为tj和sk对应的权值,可以通过最大似然函数在模型训练集上估算出来。
(2)
在得出特征函数权值后,模型训练过程便基本完成。将观察序列X(即测试语料)输入此模型,概率最大的命名实体标注序列Y′便可通过维特比算法解码得出:
Y′=argmaxP(Y│X,λ)
(3)
3.2 特征选取
在利用CRF模型进行命名实体识别的任务中,最为关键的一步就是构建与待识别对象相关联的特征模板,它直接影响识别系统的性能。
在制定特征模板时,需要先确定“观察窗口”,即当前位置词的前后n个词及其标注所构成的上下文语境。窗口大小的取值相当重要,开口过大会增加计算成本,影响模板通用性,出现过拟合现象;而开口太小则可能遗漏重要信息。结合老挝语军事领域文本特点和老挝语语言规律,本文将窗口大小设置为5,即包括当前词及其前后各2个词。下面对所选取的各类原子特征进行阐释:
1)词特征:将词本身作为特征,记为Fwi(i=-2,-1,0,1,2)(下同),w0表示当前词,w-1表示当前词左边第1个词,w-2表示当前词左边第2个词,w+1表示当前词右边第1个词,w+2表示当前词右边第2个词。
2)词性特征:该特征也是与待标注词本身相关的特征,记为Fpi,pi对应wi的词性。


表1 老挝语命名实体通名(部分)Table 1 General names of named entities in Laotian(partial)


表2 老挝语实体识别指界词示例Table 2 Examples of Laotian entity recognition boundary words
5)词典特征:表示为Fdi,英、汉语等的命名实体识别研究已证明这一特征具备高度预测能力,尤其是针对地名等规模相对稳定的实体类型非常有效。本文主要通过以下3个渠道构建常见词词典,即现有资源、网络爬虫和基于Word2vec的相似词推荐。
现有资源包括《老汉-汉老军事词典》[20]和老挝国家统计局出版的《2017统计年鉴》[21]等。前者是目前国内唯一的老挝语军事领域词典,共收录1.4万余词条;后者对老挝主要山脉、河流以及省、县、村等行政单位进行了统计。
网路爬虫主要针对老挝人民军官网、老挝国防部官网以及维基百科老挝语版涉及军事的页面信息。前两个网站内有专门介绍军队组织架构等方面的内容,可直接提取存入词典。对于维基百科的爬取,只针对页面标题,因为维基百科每一个页面几乎都是对该页面标题的解释,而每一个标题多数情况下都代表一个实体。
基于Word2vec的相似词推荐的原理是训练语料生成词向量(Word Embedding)文件,然后以向量间的余弦距离(Cosine Distance)度量词语之间的相似度。可利用现有资源和网络爬虫获得的实体作为种子词集进行相似词推荐,为保证质量,将推荐阈值设定为5,其余过程不再赘述。
将以上3个渠道获取的实体词条汇总后,根据准确性、广泛性和相关性原则,需要删除重复项、非名词词语、名词化的动词和形容词以及领域相关性较低的词,最终形成的常见词词典共包含5 134个实体词条。
根据上述各原子特征,本文依次进行组合叠加,构成如表3所示的特征模板。
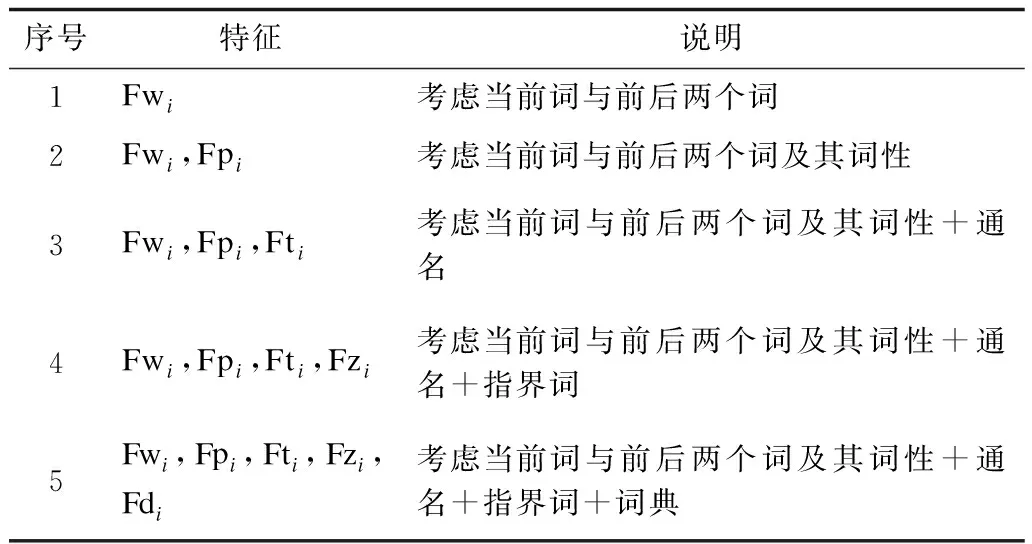
表3 老挝语军事领域命名实体识别组合特征模板Table 3 Combined feature templates of named entity recognition in Laotian military field
4 实验结果与分析
4.1 语料获取及处理
老挝语目前还没有公开的命名实体标注语料,本文实验所采用的语料均为精通老挝语人士手工构建,主要来源为老挝人民军、老挝国防部等官方网站以及老挝通讯社KPL、ABClaosnews等老挝语主流网站的军事类新闻,语料规模约为22.5M。将这些语料进行分词和词性标注等预处理后,由人工按照表4所示方法进行实体标注,然后使用标签集BISO对实体进行编码表示,B表示实体的首词部分,I表示实体的非首词部分,S表示单个词构成的实体,O表示非实体。本文5个类型实体对应的标签分别为{BPER,IPER,SPER,BLOC,ILOC,SLOC,BORG,IORG,SORG,BWE,IWE,SWE,BFAC,IFAC,SFAC,O}。最终经过处理获得实验所需语料,其中,4/5作为训练语料,1/5作为测试语料。

表4 老挝语命名实体人工标注示例Table 4 Examples of named entities manual labeling in Laotian
4.2 结果分析
为综合评价系统性能,模型训练完成后,将准确率(P)、召回率(R)以及F测度值(F-measure)作为评价指标进行测试,具体定义分别为:

(4)

(5)
(6)
本文针对不同的组合特征进行了5组实验,以对比各个特征对识别结果的影响,如表5~表9所示。
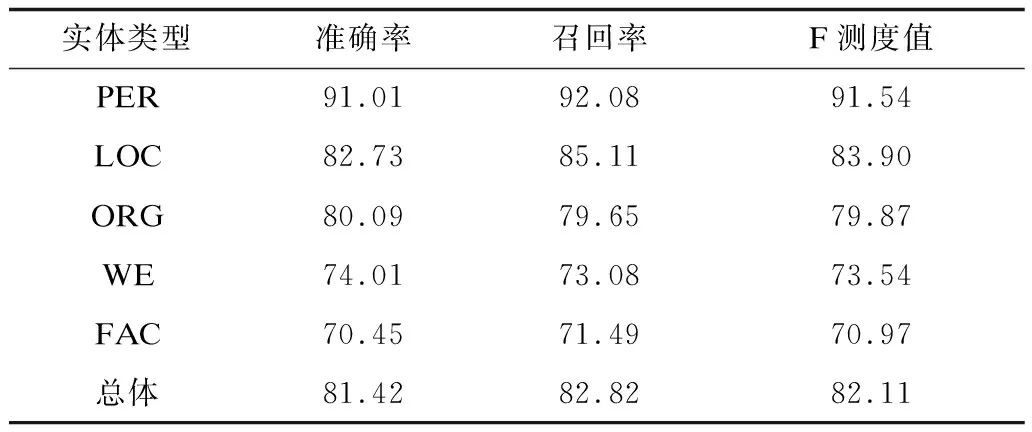
表5 基于组合特征1的识别结果(实验1)Table 5 Recognition results based on combined feature 1 (experiment 1) %

表6 基于组合特征2的识别结果(实验2)Table 6 Recognition results based on combined feature 2 (experiment 2) %

表7 基于组合特征3的识别结果(实验3)Table 7 Recognition results based on combined feature 3 (experiment 3) %
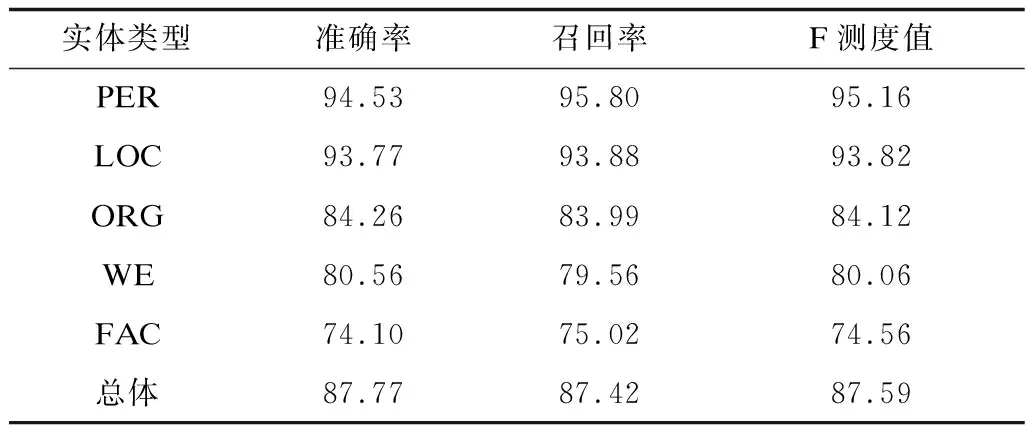
表8 基于组合特征4的识别结果(实验4)Table 8 Recognition results based on combined feature 4 (experiment 4) %

表9 基于组合特征5的识别结果(实验5)Table 9 Recognition results based on combined feature 5 (experiment 5) %

4.3 基于规则的后处理
完成基于CRF模型的实体识别之后,本文对错误识别结果进行了分析,尝试加入适当的先验性知识,即能够表达语言确定性的规则,以期能够进一步提升系统性能。部分规则描述如下:
1)人名规则:造成人名错误识别的原因是当上下文无明显特征时,将临近的词作为人名的一部分或者将人名的一部分归入其他词,这可以通过词长LPER(即音节数量)规则来处理。本文以随机搜集的500个老挝人名为样本,进行音节数量的分布统计,如图2所示。从图2可以看出,老挝人名词长一般介于3~8之间,其中以5和6居多,占样本总数的84.6%,因此可制定人名识别规则为3≤LPER≤8。

图2 老挝人名词长分布Fig.2 Word length distribution of Lao name

4)武器装备名规则:武器装备名绝大部分是以其型号结尾,而型号主要由大写英文字母、阿拉伯数字、罗马数字和符号“-”“+”等要素构成,同时规定有无通名等价。
5)军事设施名规则:军事设施名面临的识别难点同样是人名和地名的嵌套现象,因此可采用与机构名类似的规则。
规则制定完成后,选择上述识别结果最好的实验5作为基础,利用规则进行后处理,结果如表10所示。与前5个实验的总体识别结果对比如图3所示。

表10 加入规则后的识别结果(实验6)Table 10 Recognition results after adding rules (experiment 6) %

图3 老挝语命名实体识别总体结果变化趋势Fig.3 Change trend of overall results of Laotian named entity recognition
可以看出,加入规则后的系统实体识别能力有了较为显著的提升,其中机构名、武器装备名和军事设施名的准确率、召回率和F测度值均提高了4个到5个百分点。由此证明了融合CRF和规则的方法具有可行性和有效性,可以在一定程度上弥补CRF模型的不足。
5 结束语
本文采用融合CRF和规则的方法对老挝语军事领域命名实体识别进行了研究。通过分析领域实体特点,选取词、词性、通名、指界词和词典等特征进行组合作为CRF模型的特征模板,利用测试语料进行测试,并对测试结果进行错例分析,人工制定具有针对性的规则进行后处理,进一步提升识别效果。实验结果表明,该选取特征可有效解决老挝语军事领域命名实体识别问题。由于目前没有公开的老挝语大型实体标注语料库,本文所用语料库为自行构建并且初次使用,语料的规模和质量还需进一步加强,下一步将尝试引入迁移学习技术[22]和自学习技术[23]来解决老挝语资源缺乏的现状,同时将对军事文件名、军事活动名等更多类别的军事领域实体识别进行研究。
