引入通道注意力机制的SSD目标检测算法
2020-08-19张海涛
张海涛,张 梦
(辽宁工程技术大学 软件学院,辽宁 葫芦岛 125105)
0 概述
目标检测是计算机视觉和数字图像处理领域的热门方向,其在车辆识别、行人检测、无人驾驶等任务中均具有重要的研究价值[1-2],因此如何进一步提升目标检测性能一直受到国内外学者的广泛关注。早期的目标检测算法多数是以特征提取结合分类的模式,利用梯度直方图和支持向量机等分类器对特征进行分类。随着深度学习中卷积神经网络(Convolutional Neural Network,CNN)的提出和发展,学者们开始尝试使用深度学习技术实现目标检测[3],基于深度学习的目标检测算法具有良好的鲁棒性,且在检测准确率与检测速度上均有较大幅度的性能提升。
基于深度学习的目标检测算法主要分为two-stage和one-stage两类。two-stage检测算法是在提取出候选检测区域的基础上,通过分类和回归的方式进行目标检测。one-stage检测算法是直接通过回归的方式实现目标检测,其需要预先划定默认框,根据预测框、默认框和真实框之间的对应关系进行训练,典型代表为YOLO算法[4]和SSD(Signal Shot Multibox Detector)算法[5]。与two-stage检测算法相比,one-stage检测算法大幅提升了算法的时间性能。相比上述目标检测算法,SSD算法具有更高的检测精度和检测速度,但其对于网络的特征表达能力仍存在不足。为解决这一问题,文献[6]提出一种DSSD算法,该算法利用反卷积模块提高算法识别精度,虽然检测精度稍有提高,但计算过程复杂、检测速度慢,无法满足实时性要求。文献[7]提出DSOD算法,该算法利用DenseNet网络代替VGG网络,从预训练的角度对SSD算法进行改进,但是仍然无法解决目标检测精度较低的问题。
为解决原始SSD算法对于小尺度目标的检测能力不足、鲁棒性较差、定位效果不佳等问题,本文引入通道注意力机制,增强高层特征图的语义信息。基于膨胀卷积结构,通过对低层特征图进行下采样扩大其感受野,增加细节与位置信息,提高小目标检测精度。
1 相关工作
1.1 注意力机制
深度学习中的注意力机制在本质上与人类的选择性视觉注意力机制类似,即从众多信息中选择出对当前任务目标更关键的信息。在计算机视觉领域,注意力机制有多种表现形式,可以分为软性注意力和硬性注意力机制。按照注意力作用的特征形式,注意力机制又可分为基于项[8]的注意力机制和基于位置[9]的注意力机制。两种机制的输入形式不同,基于项的注意力机制需要输入包含明确项的序列,或者需要额外的预处理步骤来生成包含明确项的序列,该项可以是一个向量、矩阵或特征图。而基于位置的注意力机制是针对输入为一个单独的特征图,所有目标可以通过位置指定。基于位置的注意力机制因与任务相关,作用方法较直接并且已得到广泛应用,而基于项的注意力机制能够在不改变原有网络结构的前提下进行端对端训练,改进成本较低。
基于项的注意力机制在处理图片时使用CNN提取原图像特征,最后一个卷积层的输出结果可以产生L个向量,该向量对应原图中的维度区域D,即对应一个明确的序列a,具体为:

(1)
其中,L表示特征向量个数,D表示维度区域。采用基于项的注意力机制计算出当前时刻下每个特征向量ai所对应的权重,计算公式如下:
et,i=fatt(ai,ht-1)
(2)
(3)
其中,fatt表示使用多层感知机,ht-1表示上一个时刻的状态,et,i是一个中间变量,k是特征向量的下标。
在计算出权重后,基于项的注意力机制对输入序列进行选择得到选择后的项序列z。
(4)
其中,参数∅决定注意力机制是弱性还是强性。
1.2 SSD目标检测模型
SSD算法主要采用回归思想和anchors机制[10],其检测过程为在输入的检测图片的不同位置均匀进行密集抽样,获得不同尺度和长宽比的样本,然后经过特征提取后直接进行分类和回归。SSD算法利用不同卷积层的不同尺度特征图进行目标检测,较靠前的特征图用于检测小目标,较靠后的特征图用于检测大目标。
1.2.1 SSD网络结构
SSD算法的主网络结构是VGG-16,通过将最后两个全连接层改为卷积层并增加4个卷积层来构造网络结构,从而将前端网络产生的特征层进行不同尺度下的特征提取。SSD网络结构如图1所示。
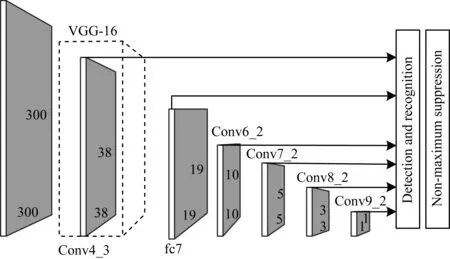
图1 SSD网络结构Fig.1 Structure of SSD network
SSD算法使用一个多层的特征图生成结构,通过分层方式学习语义信息,使得低层特征图能检测小目标,高层特征图检测大目标,利用不同尺度的特征图进行检测的方式可明显提升目标检测精度。
1.2.2 SSD检测过程
SSD算法通过VGG网络获得6种不同尺度的特征图,其大小分别为(38,38)、(19,19)、(10,10)、(5,5)、(3,3)、(1,1),在所获得的特征图上均设置一系列固定大小的默认框,但不同特征图所对应的默认框大小不同,每个特征图上选取默认框的计算公式为:
(5)
其中,k表示特征图数目,Smin表示最底层的默认框占输入图像的比例,通常取0.2,Smax表示最高层的默认框占输入图像的比例,通常取0.9。由于默认框的宽高比主要采用r={1/3,1/2,1,2,3},因此每个默认框的宽高计算公式如式(6)和式(7)所示:
(6)
(7)
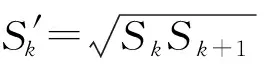
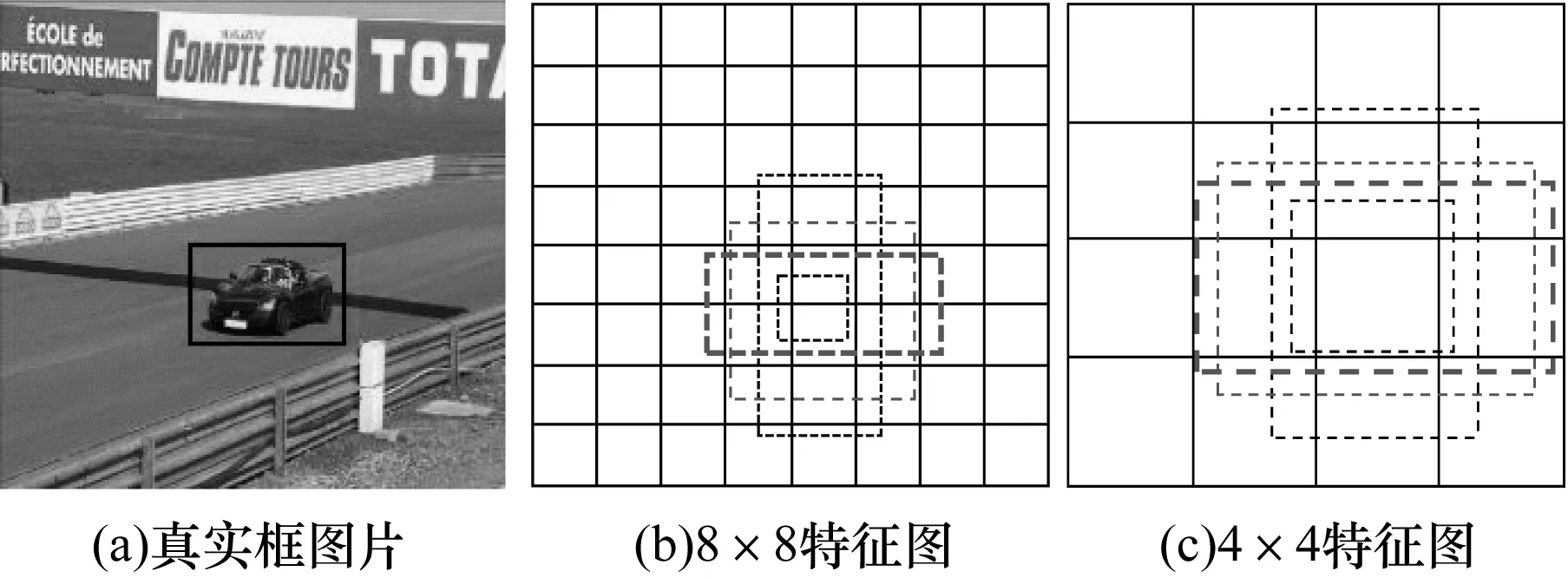
图2 SSD默认框和真实框在不同尺度特征图下的对比Fig.2 Comparison of SSD default box and real box under different feature maps
基于上述方法,SSD算法会获得大量的正负样本,通过比较IOU值的大小来获取真实目标框。但由于真实目标框的数量远少于默认框的数量,为保持样本的平衡性,SSD算法采用hard negative mining方法对负样本进行抽样,按照置信度误差进行排序,选取误差小的作为正样本,并以1∶3的比例形式来获取正负样本。
在确定训练样本后,需要对算法损失函数进行计算。与一般目标检测模型的目标损失函数相同,SSD算法的目标损失函数分为默认框与目标类别的置信度损失以及相应位置回归的损失两部分,具体为:
(8)
其中,Lconf表示置信度损失,Lloc表示位置损失,N为与真实框所匹配的默认框个数,x表示匹配结果,c和l分别表示预测结果的类别置信度和位置信息,g是真实框,参数α用于调整位置损失和置信度损失之间的比例,在默认情况下设置为1。
置信度损失函数的计算公式为:
(9)
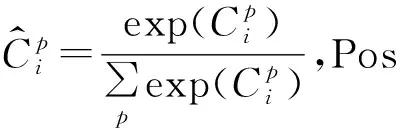
位置回归损失函数的计算公式为:
(10)
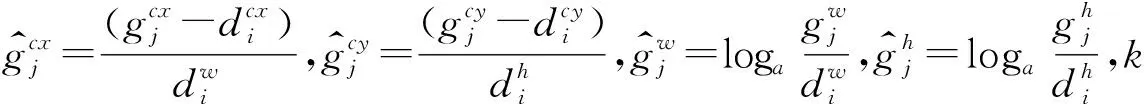
1.2.3 SSD目标检测性能分析
SSD算法选取网络结构中不同尺度的特征图,对这些特征图生成不同尺度的候选框,并以回归的方式得出目标的类别置信度和候选框与真实值之间的方差。SSD算法中不同尺度特征的卷积感受野不同,在高层卷积层感受野大、分辨率低、语义信息充足,可用于识别相对较大的目标,而低层卷积层感受野小、分辨率高,可用于识别相对较小的目标。
卷积层感受野的计算公式如下:
SRF(t)=(SRF(t-1)-1)×S+k
(11)
其中,S表示步长,k表示滤波器尺寸大小,SRF(t)表示第t层卷积层感受野大小。
对于识别小目标的低层特征图,其感受野较小且特征非线性程度不够,无法训练到足够的精确度,而对于识别中大型目标的高层特征图,其感受野较大,但分辨率低,容易出现目标漏检等情况。
2 基于通道注意力机制的SSD目标检测
2.1 引入通道注意力机制的SSD网络
SSD算法检测精度较高是由于其应用不同卷积层以获得不同尺度的特征图,为提升SSD算法精度,需改进目标漏检情况并提升算法鲁棒性,因此本文进一步增强了高层特征图的语义信息。
全局平均池化是一种特殊的池化操作[11],将特征图所有像素值相加求平均得到一个数值,使用该数值表示对应的特征图,而通道注意力模块对于特征图上的重要特征具有很强的表征能力,因此选择将两种方法相结合应用于SSD算法。首先通过对各层特征图的全局平均池化操作获得各个通道的全局信息,然后使用ReLU非线性激活函数和Sigmoid激活函数对各通道间的相关程度进行建模,最后将原特征通道的信息与建模后的权重进行加权处理。通过该结构,网络可以获得包含重要信息的特征并有选择地抑制无关特征。
注意力模块的操作过程主要包含3个部分,分别为全局池化、激活和特征加权。对输入的X(维度为C×H×W,其中C、H、W分别表示特征图的通道数、长度和宽度)进行全局池化操作,得到长度为C的一维数组,具体的计算公式如下:
(12)
其中,(i,j)表示在大小为H×W的特征图上横纵坐标分别为i和j的点,输出Z是长度为C的一维数组。
激活过程是对各通道间的相关程度进行建模,具体计算公式如下:
S=Sigmoid(W2* ReLU(W1Z))
(13)
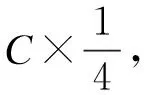
通过对式(14)进行特征加权操作,将原始的输入X替换为经过注意力模块获得的特征X′,并引入到原网络结构中进行目标检测。
X′=X*S
(14)
2.2 引入通道注意力机制的SSD算法流程
对于目标检测任务而言,特征提取网络对于不同物体所关注的关键特征区域不同,如果在训练初期就以同样的关注程度对待每一个特征图,则会增加网络收敛所需的时间,并且定位精确和分类准确是互相影响的,但目标检测算法更受益于精准分明的特征。同时,由于通道注意力机制引入的参数量并不影响算法实时性,并且获得了平均精度均值(mean Average Precision,mAP)的提升,因此采用通道注意力机制是较好的选择。引入通道注意力机制的SSD算法流程如图3所示。
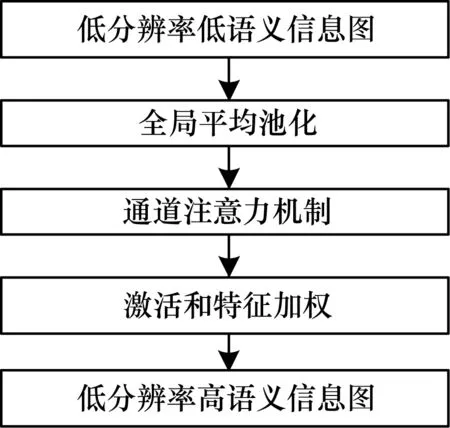
图3 引入通道注意力机制的SSD算法流程Fig.3 Procedure of SSD algorithm with channel attention mechanism
2.3 引入膨胀卷积结构的SSD网络
考虑到传统SSD算法使用低层特征图检测小目标的效果不理想,为获得更充足的语义信息,本文采用膨胀卷积[12]对特征图进行下采样,将高维特征映射成低维输入,膨胀卷积的示意图如图4所示,其中,卷积核大小为3×3,步长为1,膨胀系数为1。

图4 膨胀卷积示意图Fig.4 Schematic diagram of dilated convolution
膨胀卷积又称空洞卷积,属于下采样操作[13-15]。在卷积神经网络中经常使用的下采样操作有pooling和膨胀卷积两种。pooling是通过减小图像的尺寸来增大感受野,该操作会导致图像细节信息的损失,因此,本文选择用膨胀卷积来代替pooling操作,膨胀卷积不仅不会损失细节信息,而且会增大感受野,使经过卷积操作的特征图中的特征元素获得更多的全局信息[16-17]。
普通卷积的运算公式为:
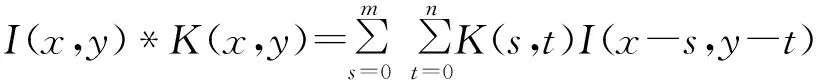
(15)
其中,I(x,y)表示卷积前的图像在点(x,y)上的值,K(s,t)表示一个卷积核,大小为m×n。
膨胀卷积的运算公式为:
(16)
其中,l表示膨胀因子,*表示膨胀卷积的运算符号。
本文选择Conv3_1层进行膨胀卷积,卷积核为3×3,stride为2,pad为2,膨胀系数dilation为2。Conv3_1经过膨胀卷积获得大小为38×38×512的特征图,将其与Con4_3进行特征融合再次进行卷积,以获得符合要求的特征图,并使用该特征图进行位置预测。
改进后的网络结构低层特征图具备更全面的细节信息以及更强的位置信息,改进结构如图5所示。引入膨胀卷积的结构使得低层特征图感受野变大,细节信息增多,进一步提升了小目标的检测性能。
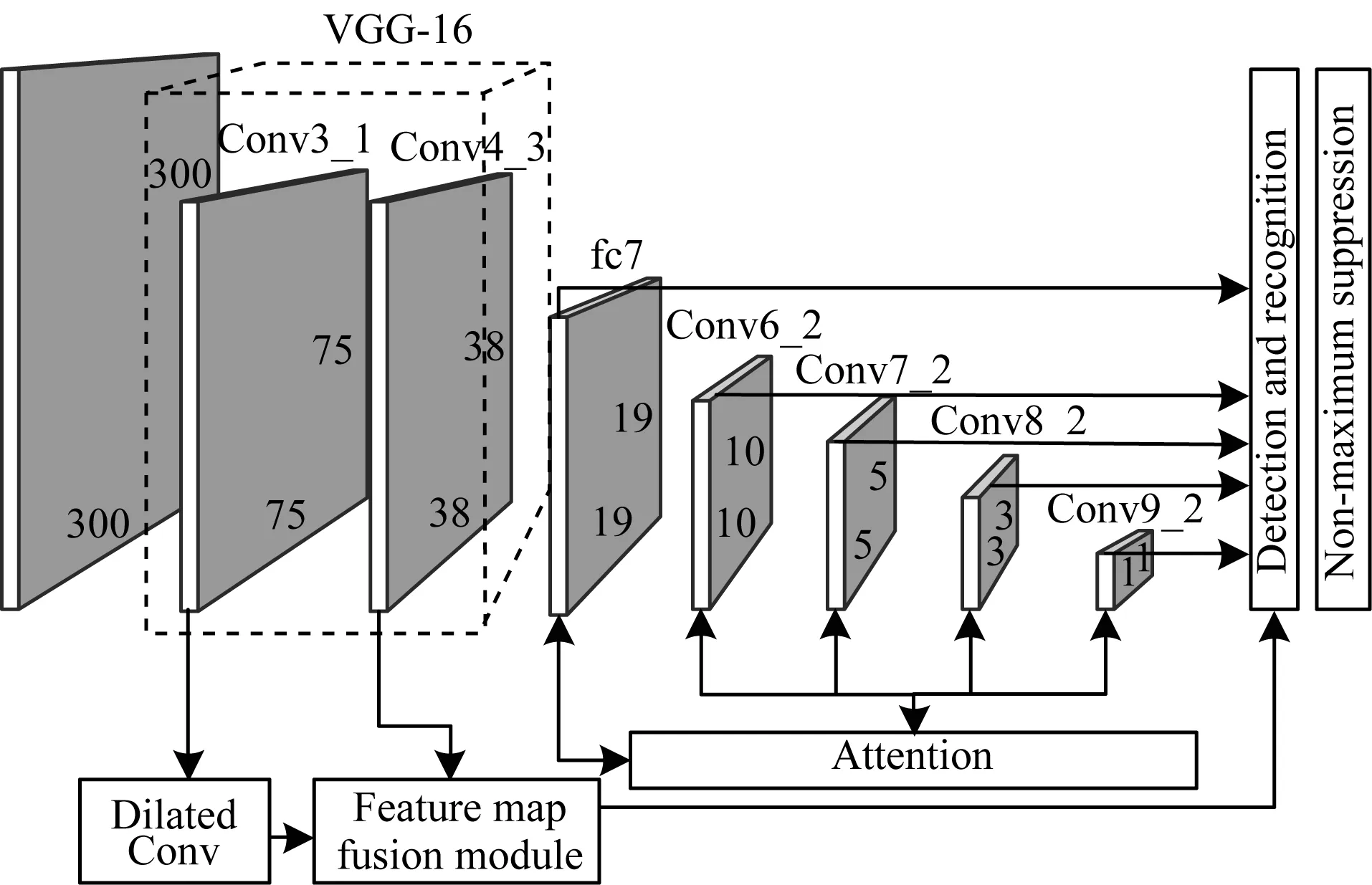
图5 改进的SSD网络结构Fig.5 Structure of improved SSD network
2.4 特征图融合模块
特征图融合方式[18]主要有两种,加性融合和级联融合,其中级联融合计算量小、精度高,因此本文采用级联融合方式,具体的特征图融合过程如图6所示。
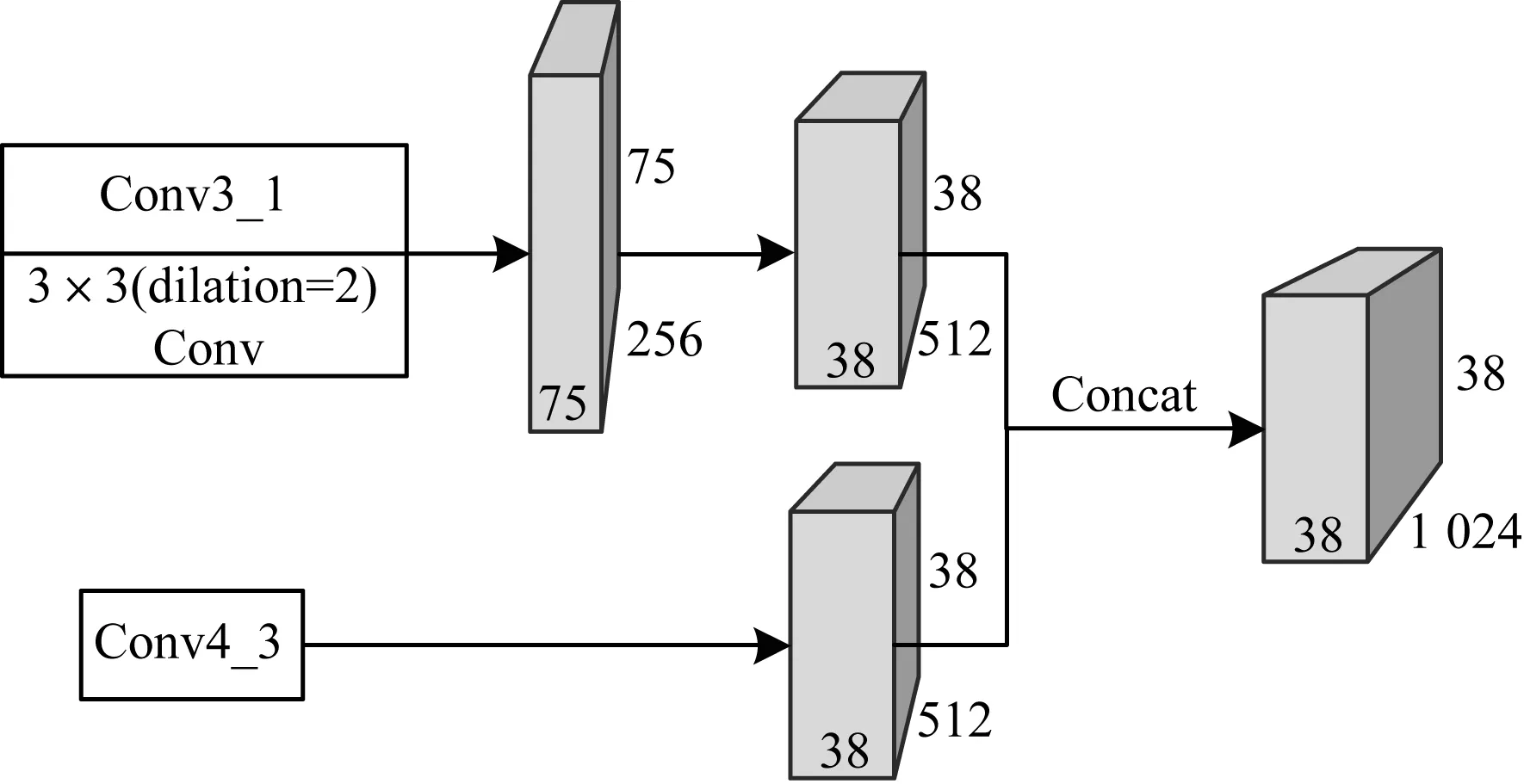
图6 特征图融合过程
3 实验结果与分析
实验所用数据集为PASCAL VOC数据集[19-20],该数据集包括20个类别,即aero、bike、bird、boat、bottle、bus、car、cat、chair、cow、table、dog、horse、mbike、person、plant、sheep、sofa、train、tv,共27 088张图片。本文使用PASCAL VOC 2007和PASCAL VOC 2012数据集进行训练,PASCAL VOC 2007数据集进行测试,以Tensorflow框架为基础并利用图像处理器(Graphics Processing Unit,GPU)进行加速运算,实验环境为Intel®CoreTMi7-8750H CPU@2.20 GHz处理器,8 GB内存,Nvidia GeForce GTX 1050Ti显卡。
在目标检测中,通常采用mAP指标对精度进行评估。基于原始SSD模型[21],设置输入图像的分辨率为300×300,Batch size为8,初始学习率为0.000 1,先迭代800 00次再将学习率降至0.000 01迭代100 000次,得到最终的网络模型。对比原始SSD算法(输入图像分辨率为300×300)、DSSD算法(输入图像分辨率为321×321)以及本文算法的实验结果如表1所示。

表1 3种目标检测算法在20个类别下的检测精度对比Table 1 Comparison of the detection accuracy for three target detection algorithms at twenty categories
从检测结果可以看出,本文提出的引入注意力机制和不同层级特征融合的SSD目标检测算法在mPA上比原始SSD算法提高了2.2%,对比结果如图7所示。
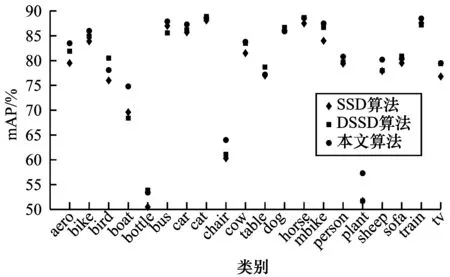
图7 PASCAL VOC 2007测试集上3种目标检测算法的mAP对比Fig.7 Comparison of the mAP for three target detection algorithms on PASCAL VOC 2007 test set
此外,为检验算法的实时性[22-23],本文对比了传统目标检测算法及本文算法的检测速度,具体检测结果如表2所示。本文算法在检测精度上超过了同类型的检测算法,检测速度也相对原始SSD算法有了较大幅度的提升,在实时性和精确度方面达到了更好的平衡。

表2 在PASCAL VOC 2007测试集上5种目标检测算法的检测速度对比Table 2 Comparison of the detection speed for five target detection algorithms on PASCAL VOC 2007 test set
为更加直观地评价本文算法,图8给出PASCAL VOC数据集下的部分实验结果,其中,第1列为传统SSD算法的实验结果,第2列为DSSD算法的实验结果,第3列为本文算法的实验结果。针对小目标,以图8(a)为例,本文算法成功检测出了更多的小目标;针对遮挡目标,以图8(b)为例,本文算法成功定位出被遮挡目标的位置并检测出该目标的类别;针对目标漏检的情况,以图8(c)、图8(d)为例,本文算法明显比传统算法识别更加精确,并且对识别出的目标给出了准确的定位以及更高的类别置信度。可以看出,对于传统SSD算法没有检测出的目标,本文算法能实现更加有效的检测。此外,本文算法还可在一定程度上检测到遮挡目标,进一步提高了算法鲁棒性。

图8 3种目标检测算法的检测结果对比Fig.8 Comparison of detection results of three target detection algorithms
4 结束语
基于传统SSD算法存在鲁棒性差、定位精度低等问题,本文提出一种引入通道注意力机制的改进SSD目标检测算法。引入膨胀卷积结构,将不同层级的特征图进行融合,增大低层特征图的感受野,提升算法整体检测性能。实验结果表明,改进的SSD算法具有较好的小目标检测性能,并且大幅提升了算法鲁棒性。下一步将研究注意力机制的工作机理,在优化高层特征的基础上,实现低层特征图与高层特征图的充分融合,并在尽可能不增加算法计算量的情况下提升实时性,以更直观的形式呈现算法在不同数据集下的检测效果。
