基于优化局部抑制的轨迹数据发布隐私保护算法
2020-08-19俞庆英王燕飞叶梓彤张双桂陈传明
俞庆英,王燕飞,叶梓彤,张双桂,陈传明
(安徽师范大学 a.计算机与信息学院; b.网络与信息安全安徽省重点实验室,安徽 芜湖 241002)
0 概述
随着GPS、Wi-Fi等定位技术以及存储技术的快速发展,大量移动用户的轨迹数据被搜集并存储[1-3]。轨迹数据包含着丰富的时空信息,对轨迹数据进行深入研究和分析已成为数据挖掘领域的一个研究热点[4-6]。可用性高的轨迹数据是有效轨迹数据挖掘的基础,研究者通过对轨迹数据的分析和挖掘,可以得到有价值的信息[7-8]。但是,轨迹数据也包含着移动用户的大量隐私信息,如果轨迹数据在发布前不进行保护处理,掌握背景知识的攻击者就可以通过分析轨迹数据从而推断出用户的隐私信息,例如身体状况、生活习惯和家庭住址等,甚至会给用户带来经济损失以及人身安全问题[9-11]。因此,如何保证所发布的轨迹数据不会泄露用户的隐私并且具有较高的可用性是一个急需解决的问题[12-14]。
目前,轨迹数据发布中的隐私保护方法研究已取得了一定的成果。文献[15]提出适用于RFID数据的LKC隐私模型,并设计一种有效的匿名算法以实现LKC隐私模型。该算法首先识别数据集中的最小违反序列集合,然后在每次迭代中用贪心算法对违反序列进行全局抑制,目的在于尽可能减少最大频繁序列的损失,从而提高数据的可用性。由于全局抑制导致大量数据损失,文献[16]在全局抑制的基础上引入了局部抑制,并提出了(K,C)L隐私模型以及实现该模型的算法。该算法由2个阶段组成,首先确定在轨迹数据集中违反给定(K,C)L隐私要求的所有序列,然后进行一系列的局部和全局抑制对轨迹数据集进行简化,同时保持尽可能高的数据效用。文献[17]提出可消除身份链接攻击、属性链接攻击和相似性攻击的PPTD算法,其为一种执行敏感属性泛化和移动点的轨迹局部抑制方法,该方法对轨迹的隐私等级进行划分,并通过敏感属性泛化识别临界轨迹数据记录,然后对轨迹进行局部抑制,通过MPSTD算法来识别剩余的关键轨迹数据记录,并从中消除多个移动点,使得匿名轨迹数据集中没有关键轨迹数据记录,并最小化信息损失。文献[18]在局部抑制和全局抑制的基础上引入了分裂的思想,并提出LSUP、GSUP、SPLIT和MIX 4种匿名算法,前3种算法分别采用局部抑制、全局抑制和轨迹分裂的方法,第4种算法采用抑制混合分裂方法来减少信息损失。
以上研究中采用的方法都是全局抑制联合局部抑制,无法解决全局抑制造成的数据损失率大的问题。为了在保证轨迹隐私保护水平较高的同时提高轨迹发布数据的可用性,本文提出一种满足(K,C)L模型的优化局部抑制方法,该方法仅使用局部抑制来进行轨迹隐私保护。
1 相关定义
定义1(轨迹) 轨迹是由一系列按时间戳排序的位置点构成的集合,如式(1)所示:
tr={ID,loc1t1→loc2t2→…→lociti→…→locntn}
(1)
其中,ID表示轨迹用户标识符,loci表示轨迹tr的第i个位置,ti表示轨迹tr的第i个时间戳,
本文研究的轨迹还包含敏感属性特征s,具体可见式(2):
tr={ID,loc1t1→loc2t2→…→lociti→…→locntn:s}
(2)
定义2(轨迹数据集) 由一组轨迹组成的集合称为轨迹数据集,记作T,如式(3)所示:
T={tr1,tr2,…,tri,…,trl}
(3)
其中,tri表示T中的第i条轨迹,l表示T中包含的轨迹条数,也可以用|T|表示,即|T|=l。
表1所示为一个包含敏感属性的轨迹数据集T的数据格式示例。

表1 原始轨迹数据集T的数据格式示例Table 1 Sample data format of original track dataset T
在轨迹数据集中,如果某个敏感属性值与一些位置点序列频繁地出现在同一条轨迹中,攻击者即使不能唯一地识别出受害者的轨迹,也可以从这些序列中推断出敏感值。下面举2个例子进行说明:
例1如表1所示,假设攻击者掌握了某用户曾经到过a1、d2和f63个位置点的背景知识,那么攻击者可以推断出该用户患有HIV的概率高达2/3≈66.7%,原因是同时包含a1、d2和f6的3条轨迹记录(tr1、tr5、tr8)中有2条都包含了敏感属性值HIV。
例2表1只是本文实验数据集的数据格式示例,该轨迹数据集共包含80 000条轨迹,但其中同时包含a3、e4和a53个位置点的轨迹仅有32条,而在这32条轨迹中敏感属性值为SARS的就有13条,如果攻击者掌握了某用户曾经到过a3、e4和a5这3个位置点的背景知识,那么攻击者可以推断出该用户患有SARS的概率就为13/32≈40.6%。
定义3((K,C)L隐私模型) 假定L为攻击者所掌握背景知识的最大长度,S是数据拥有者从轨迹数据集的敏感属性中挑选的敏感值集合,轨迹数据集T满足(K,C)L隐私模型当且仅当T中长度大于0且小于等于L的序列p符合以下2个条件[17]:
1)|T(p)|≥K,其中,T(p)指轨迹数据集T中包含p的轨迹集合,|T(p)|表示其中的轨迹条数,K是一个正整数。
2)对于任一s∈S都满足Conf(s|T(p))≤C,其中,0≤C≤1,Conf(s|T(p))是T(p)中包含s的轨迹所占比例。
定义4(频繁序列) 给定阈值E>0,若序列p在轨迹中出现的次数大于等于E,则称p为频繁序列。
定义5(最大频繁序列) 若序列p是轨迹数据集T中的频繁序列并且p的父序列都不是频繁序列,则称p为最大频繁序列,记作MFS(Maximal Frequent Sequence)[19]。
定义6(违反序列) 假定序列p的长度大于0且小于等于L,给定(K,C)L隐私模型,若序列p不满足定义3中的任一个条件,则称p为违反序列[15]。
定义7(最小违反序列) 若p为违反序列并且p的子序列中都没有违反序列,则称p为最小违反序列,记做MVS(Minimal Violating Sequence)[16]。
定义8(有效局部抑制) 对轨迹数据集进行局部抑制不会产生新的最小违反序列,则称该局部抑制为有效局部抑制[16]。
定义9(实例得分表) 设有实例q,其得分表是指通过抑制q可以消除的最小违反序列的数量与抑制q损失的实例个数之比,将得分记为Score(q),计算公式如式(4)所示:
(4)
其中,mvsLoss(q)是包含q的MVS个数,instanceLoss(q)是通过抑制q损失的实例个数。
定义10(轨迹损失率) 轨迹损失率是指经过隐私保护算法处理后数据集中减少的轨迹条数与原始数据集T中的轨迹条数之比,计算公式如式(5)所示:
(5)
其中,TrajectoryLossNum表示经过算法处理后减少的轨迹条数,OriginalTrajectoryNum表示原始数据集中的轨迹条数。
2 满足(K,C)L模型的局部抑制轨迹隐私保护
2.1 算法描述
本文提出一种满足(K,C)L模型的局部抑制轨迹隐私保护算法,主要包含2个步骤:
1)算法1,在对需要进行全局抑制的序列进行局部抑制操作后,计算可能会产生的最小违反序列。
2)算法2,利用局部抑制方法实现轨迹数据的匿名化操作。
本文算法的流程如图1所示。
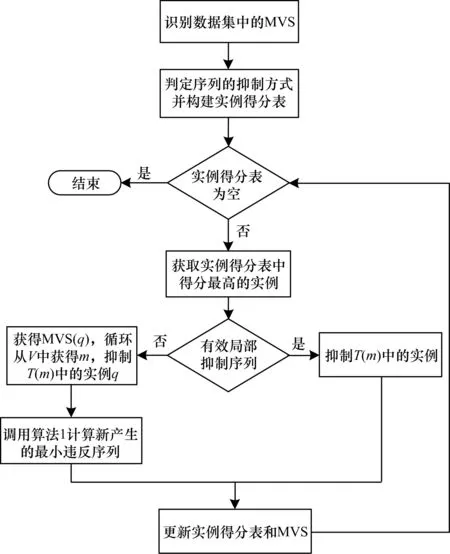
图1 本文算法流程Fig.1 Procedure of the algorithm in this paper
2.1.1 最小违反序列计算
将计算新产生的最小违反序列的算法记为GetNewMVS,算法思想如下:只有p既属于T(m)又属于T(q)-T(m)时,p才有可能成为新的最小违反序列[16]。算法伪代码如算法1所示。首先筛选出所有符合条件的实例(第1行),移除已经在MVS中的序列(第2行~第3行),然后将A中实例产生的所有长度不大于L并且包含实例q的序列存放入P中(第4行),并删除P中不包含实例q的序列(第5行),接着将在T(q)-T(m)中S的子集放入S1中(第6行),最后扫描T(q)-T(m),计算P中每个序列是否满足(K,C)L隐私模型,若不满足,则将该序列加入V1中(第7行~第15行)。
算法1GetNewMVS算法
输入原始轨迹数据集T,背景知识长度L,匿名数K,推断概率C,敏感值集合S,需要全局抑制的序列m以及实例q,最小违反序列集合MVS
输出新产生的最小违反序列V1
1.A←Find instances in both T(m) and T(q)-T(m);
2.V1←Extract all MVSs with length one;
3.Delete all non-q instances in V1from A;
4.P← All sequences with length ≤ L generated by natural connection of A
5.Delete the sequences without q from P;
6.S1←Scan T(q)-T(m) to find the subset of S;
7.for each sequence p in P do
8.Scan T(q)-T(m) to calculate T(p) and Conf(s|T(p)) for any s∈S1;
9.maxConf ←MAX(Conf(s|T(p)));
10.if T(p)>0 and (T(p)
11.if p ∉MVS then
12.Add newly generated MVS to V1;
13.end if
14.end if
15.end for
16.return V1;
例3设算法GetNewMVS的输入为表1所示的原始轨迹数据集T,L=2,K=2,C=0.5,S={HIV},m={b3→c7},q=b3,MVS={a1,b3→c7,d2→e4}。算法1的执行过程如下:
计算出T(m)={tr3},T(q)={tr1,tr3,tr4},根据算法1的第1行~第3行得到A={b3,d2,e8}、V1={a1};根据第4行~第5行,得到P={b3,b3→e8,d2→b3};由第6行可得S1=2;由第7行~第15行可得V1={d2→b3}。因此,执行算法1后对{b3→c7}进行局部抑制会产生新的最小违反序列{d2→b3}。
2.1.2 满足(K,C)L模型的优化局部抑制算法
将满足(K,C)L模型的优化局部抑制算法记为TPL-Local,其伪代码如算法2所示。第1行首先调用文献[17]算法获取MVS,第2行判断所有最小违反序列的抑制方式,并根据定义9计算各序列得分,第3行初始化V1,第4行~第20行选择ds中得分最高的实例q进行抑制,循环上述过程,直至实例得分表为空。第5行~第16行根据q的抑制方式采取相关的操作,若q为局部抑制,则抑制T(m)中的实例q;若q为全局抑制,则将所有包含q的最小违反序列加入到V2中,调用算法1计算出新产生的最小违反序列V1,对V2中的所有最小违反序列m,抑制T(m)中的实例q,并将V1加入到原MVS中。第17行~第18行更新MVS,并重新计算V1中所有序列的抑制方式和得分,第19行将V1的实例加入ds中。重复上述操作,直至实例得分表为空。
算法2TPL-Local算法
输入原始轨迹数据集T,背景知识长度L,匿名数K,推断概率C,敏感值集合S
输出满足(K,C)L模型的轨迹数据集T′
1.Obtain MVS by calling MVS algorithm presented in literature[17];
2.Perform GetNewMVS algorithm to determine the suppression mode of all sequences in MVS and build ds;
3.V1← ∅;
4.while ds≠∅ do
5.Select an instance q with the highest score in ds and get its MVS;
6.if q is a local suppression instance then
7.V2←the sequence m1which contains q and meets T(m1) == T(m); //m1∈MVS
8.Suppress all instances of q in T(m);
9.else
10.V2←MVS(q);
11.Calculate new MVS V1generated from V2by Algorithm 1;
12.for each sequence m∈V1do
13.Suppress all instances of q in T(m);
14.end for
15.Add V1to MVS;
16.end if
17.MVS←MVS-V2;
18.Update Score(q′) if q′ in V2;
19.Add all instances of V1to ds;
20.end while
21.return the processed T as T′;
例4设算法TPL-Local的输入为表1所示的原始轨迹数据集T,L=2,K=2,C=0.5,S={HIV}。算法2的执行过程如下:
根据算法2的第1行得到表1中的最小违反序列MVS={a1,b3→c7,d2→e4};由第2行可得实例{a1}的抑制方式为局部抑制,实例{b3,c7,d2,e4}的抑制方式均为全局抑制,ds={a1,b3,c7,d2,e4}中的实例得分值分别为0.333 3、0.333 3、0.200 0、0.142 9和0.250 0;由第4行可得ds≠∅;第5行选择实例得分表中分数最高的实例进行抑制,其中得分最高的实例为q={a1},m={a1};第8行对{a1}进行局部抑制;第17行删除已经被抑制的序列m,得到MVS={b3→c7,d2→e4};第18行更新实例得分表,得到ds={b3,c7,d2,e4}中的实例得分值分别为0.333 3、0.200 0、0.142 9和0.250 0;第19行将V1中的实例加入到ds中,因为V1为空,ds不变,由第4行可得ds≠∅,所以循环没有结束,再由第5行可得q={b3},m={b3→c7},因为q的抑制方式为全局抑制,由第10行可得V2={b3→c7};第11行获取因局部抑制q产生的新的最小违反序列集合,可得V1={d2→b3};第12行~第14行对所有包含q的MVS进行局部抑制;第15行将新产生的最小违反序列加入MVS中,可得MVS={b3→c7,d2→e4,d2→b3};根据第17行可得MVS={d2→e4,d2→b3};第18行~第19行更新实例得分表,可得ds={d2,e4,d2,b3}中的实例得分值分别为0.142 9、0.250 0、2.000 0和0.500 0。循环执行上述操作,直至匿名化的数据集中没有最小违反序列。对表1中的轨迹数据集执行算法2后产生的结果如表2所示。
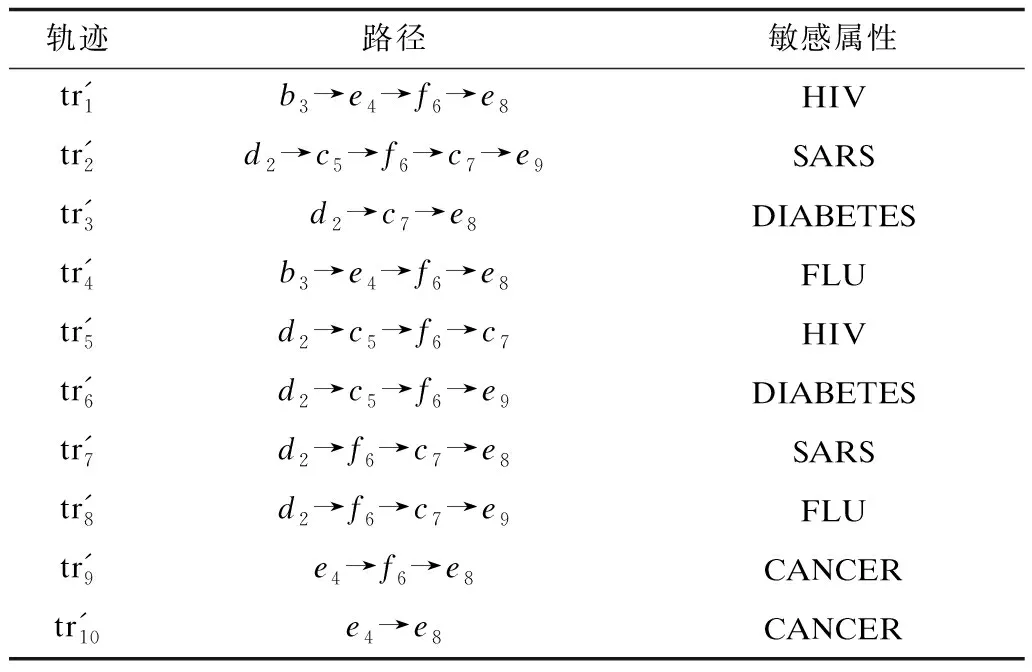
表2 满足(K,C)L模型的轨迹数据集T′Table 2 Track dataset T′ satisfying (K,C)L model
2.2 算法分析
2.2.1 复杂度分析
本文算法的时间复杂度共包含2个部分:
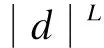
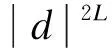
2.2.2 安全性分析
文献[16]已证明当且仅当T中不包含最小违反序列时一个轨迹数据集满足(K,C)L模型。本文算法对文献[16]算法进行改进,文献[16]中的全局抑制是抑制所有实例,局部抑制仅抑制引起隐私泄露的实例。定义原始轨迹数据集为T,数据集中的最小违反序列集合为MVS,本文算法通过将轨迹数据集T包含q的所有需要全局抑制的最小违反序列V1进行局部抑制,更新序列的抑制方式,并将删除q后产生的新最小违反序列V2加入到最小违反序列集合中,一次抑制操作后的T′相当于一个新的轨迹数据集,而其最小违反序列为MVS-V1+V2,新产生的最小违反序列V2的抑制方式有3种情况:
1)产生的最小违反序列都是有效局部抑制。
2)产生的最小违反序列都是无效局部抑制。
3)产生的最小违反序列既有有效局部抑制,也有无效局部抑制。
最好的是第1种情况,通过一次局部抑制可以改变实例q的抑制方式,减少实例q的损失;最差的是第2种情况,产生的最小违反序列仍然都是无效局部抑制,重复上述操作,直至T中没有包含q的最小违反序列。因此,本文算法得到的轨迹数据集仍满足(K,C)L模型。
3 实验验证
3.1 实验环境与数据集
本文实验采用合成数据集City80K[15-16,20]来测试数据的实用性损失。City80K是模拟拥有26个板块的大都市中80 000个行人一天24 h移动轨迹的数据集,其中包含5种敏感属性值,实验选择其中的一种作为敏感值[16]。所有对比算法用MATLAB语言实现,运行在Intel i7-5500U CPU(3.0 GHz)、8 GB内存、7200RPM 1 TB硬盘的工作站中,操作系统为Window 10。
3.2 衡量标准
损失率是衡量轨迹数据集实用性的重要参数,本文从实例、MFS和轨迹3个方面衡量实用性损失[16],具体如下:
1)在实例损失方面,使用式(6)进行衡量:
(6)
其中,N(T)是原始数据集中实例的总数,N(T′)是经过算法处理后数据集中实例的总数。
2)在MFS损失方面,使用式(7)进行衡量:
(7)
其中,U(T)是原始数据集中MFS的总数,U(T′)是经过算法处理后数据集中MFS的总数。本文使用文献[19]中的MAFIA算法计算MFS。
3)在轨迹损失方面,使用式(8)进行衡量:
(8)
其中,P(T)是原始数据集中的轨迹数目,P(T′)是经过算法处理后数据集中的轨迹数目。
3.3 结果分析
为了充分研究TPL-Local算法的有效性,本文将TPL-Local算法与文献[16]中的KCL-Local算法进行比较。
3.3.1C值对数据损失的影响
图2所示为2种算法在不同的C值下实例损失率、MFS损失率以及轨迹损失率情况,其中,L=3,K=30,E=800。由图2可以看出,实例损失率、MFS损失率以及轨迹损失率均随着C值的递增而先减小后趋于稳定。C值递增造成最小违反序列数目递减并趋于稳定,被抑制序列的个数递减并稳定,因此,实例损失率、MFS损失率和轨迹损失率先递减后稳定。当C值较小时,最小违反序列以全局抑制的方式为主,2种算法的损失率相似,随着C值的增大,最小违反序列数目减少并且局部抑制序列增多,被抑制的序列个数减少并稳定。2种算法相比,本文TPL-Local算法有效减少了实例损失,因此其损失率更低。
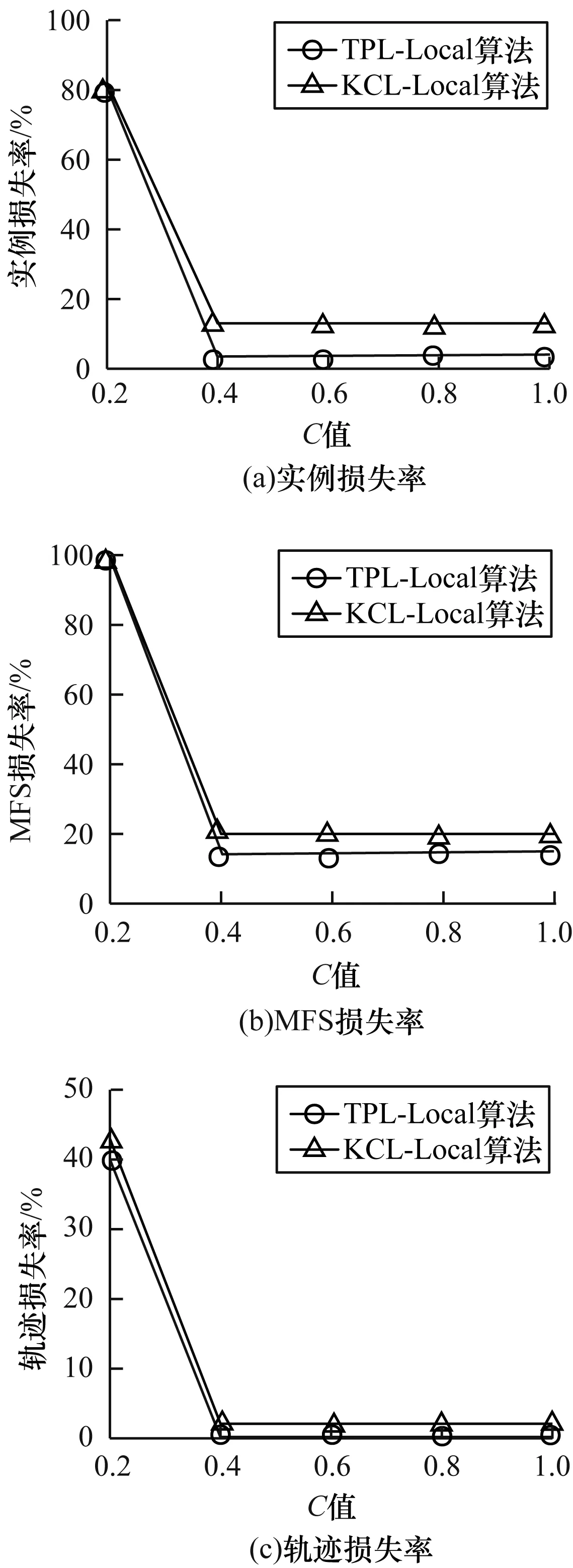
图2 C值对数据损失的影响Fig.2 Effect of C value on data loss
3.3.2K值对数据损失的影响
图3所示为2种算法在不同的K值下实例损失率、MFS损失率以及轨迹损失率情况,其中,L=3,C=0.4,E=800。由图3可以看出,实例损失率、MFS损失率和轨迹损失率均随着K值的增大而增大。因为K值的增大造成最小违反序列和全局抑制序列增多,所以被抑制的序列增多,数据损失率也会相应增加。当K值较小时,最小违反序列以局部抑制的方式为主,2种算法的损失率相似,随着K值的不断增大,全局抑制序列与被抑制的序列均增多。2种算法相比,本文TPL-Local算法有效减少了实例损失,因此其损失率更低。

图3 K值对数据损失的影响Fig.3 Effect of K value on data loss
3.3.3E值对数据损失的影响
图4所示为2种算法在不同的E值下MFS损失率情况,其中,L=3,C=0.4,K=40。由图4可以看出,KCL-Local算法的MFS损失率随着E值的增大先增加后减小,本文算法的MFS损失率先减小后增加。本文算法以局部抑制影响全局抑制的方法有效减少了实例损失,因此,其MFS损失率更低。
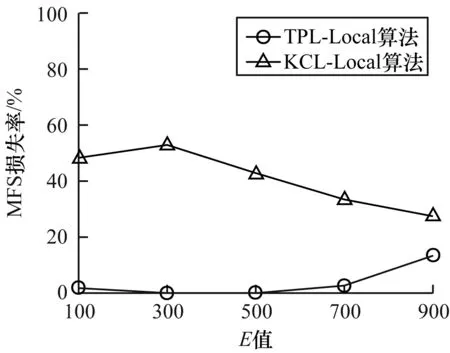
图4 E值对MFS损失率的影响Fig.4 Effect of E value on MFS loss rate
4 结束语
本文提出一种满足(K,C)L模型的优化局部抑制轨迹隐私保护算法TPL-Local,其采用以局部抑制代替全局抑制的方式实现轨迹数据的隐私保护,从而降低轨迹损失率、实例损失率和MFS损失率。实验结果表明,TPL-Local算法的数据损失率性能优于KCL-Local隐私保护算法。后续将在保证隐私保护算法高效性的同时进一步提高数据可用性。
