融合知识图谱与用户评论的商品推荐算法
2020-08-19汤伟韬余敦辉魏世伟
汤伟韬,余敦辉,2,魏世伟
(1.湖北大学 计算机与信息工程学院,武汉 430062; 2.湖北省教育信息化工程技术中心,武汉 430062)
0 概述
随着互联网的快速发展,电子商务系统得到了广泛应用,其中的商品信息不断扩增,随之也带来了信息过载的问题。为解决该问题,商品推荐[1-2]应运而生,其通过分析用户过往的购买记录或商品的受欢迎程度等信息,推断用户的喜好并为用户推荐他们感兴趣的商品。
知识图谱[3]是一种基于图的网络数据结构,其由多个节点和边构成,其中,实体作为节点,关系作为边,以多个<头实体,关系,尾实体>的三元组形式存储在知识库中。知识图谱作为大数据时代的产物,是物品与物品之间关系的最有效的表现方式,并且其能够融合多源异构信息,因此,越来越多的学者将知识图谱应用于推荐算法中[4]。
知识图谱的图结构能够体现用户评论之间的商品网络结构信息,因此,本文提出一种融合知识图谱与用户评论的商品推荐算法。结合知识图谱分析每个用户评论,提取商品特征及其对应的情感词,根据情感词计算商品特征得分。将知识图谱融入到商品相似度矩阵的计算中,在随机游走模型中输入相似度矩阵以分配特征权重,在此基础上,通过商品特征分数和特征权重计算商品推荐价值,根据商品推荐价值进行Top-k推荐。
1 相关工作
推荐算法主要分为协同过滤算法、基于内容的推荐算法和混合推荐算法。
1)协同过滤算法将某个用户感兴趣的物品推荐给和该用户兴趣相似的用户。文献[5]通过将信息熵和双聚类引入到协同工作中,提取局部密集评分模块从而提高推荐效率。文献[6]提出一种基于可信数据和用户相似度融合的“斜率一”算法,但是该算法没有考虑商品本身信息对结果的影响,受限于评分数据稀疏和冷启动问题。
2)基于内容的推荐算法为用户推荐与他喜欢的物品相似的物品。文献[7]将概率模型与经典的基于内容的过滤推荐算法相结合,文献[8]提出一种基于内容的加权粒度序列推荐算法,但是上述2种算法受物品内容信息提取技术的制约,推荐效果一般。
3)混合推荐算法将多个推荐算法进行组合,以发挥各自优势。文献[9]在ConvMF中加入双嵌入层,更加注意物品的侧面信息,文献[10]考虑用户行为数据和社会关系的互补性,但是上述研究增加了复杂度,运行时间成本较高。
近年来,基于用户评论的推荐算法相继被提出。文献[11]进行用户评论主题挖掘,其引入情感因素,构建主题情感混合模型,并结合用户评分进行推荐,据此提出一种基于用户评论的个性化产品推荐算法。文献[12]在情感分类辅助任务中引入格外监督信息,以降低推荐任务的学习难度,通过在2个任务间共享短语的表示,使推荐任务更好地理解情感短语的语义。文献[13]提出一种正则约束方式,对评论文本信息与模型的融合方法进行深入研究。基于用户评论的推荐算法同时结合了用户特性与商品特性,获取的商品细粒度信息准确度高,避免了用户评分数据稀疏性的问题。但是,现有的多数研究重点关注对评论文本的自然语言处理,孤立地处理单个评论而忽略了评论之间的网络结构信息。
综上所述,协同过滤算法主要探究用户之间以及商品之间的关系,但没有深入研究用户和商品本身所具有的许多信息。大部分基于用户评论的推荐算法虽然将评论融入到用户和商品的关系中,但其关注文本处理而忽视了评论与评论之间可能存在的网络结构。本文通过知识图谱构造评论之间的网络结构,利用该网络结构挖掘用户评论所富含的信息,从而进行商品推荐。
2 融合知识图谱的商品特征提取
在用户对商品的评论中,需要提取用户关注度高的商品特征及其对应的情感词。多数商品特征提取方法都是独立地分析单个评论文本而忽略了评论之间的联系。因此,本文将知识图谱融入到商品特征提取算法中,将多个商品的多个评论联系在一起进行讨论。
本文将商品作为知识图谱中的实体,商品的特征作为商品实体的属性,情感词作为属性值,将该规则关联到知识图谱中并进行研究。
2.1 基于语义约束LDA的商品特征和情感词提取
从评论文本中有效地提取商品特征和情感词并获取特征级别的情感倾向,是商品评论细粒度情感分析的关键。文献[14]根据中文商品评论文本的特点,从句法分析、词义理解和语境相关等多角度获取词语间的语义关系,然后将其作为约束知识并嵌入到主题模型中,提出一种语义关系约束的主题模型SRC-LDA,以实现语义指导下LDA的细粒度主题词提取。本文将通过SRC-LDA对商品i的某条用户评论所提取出的特征组成的集合,定义为评论中的商品特征集合CFi={cf1,cf2,…}。
2.2 基于知识图谱的商品特征融合
通过SRC-LDA从用户评论中提取商品特征,需要与商品知识图谱中的商品特征进行融合,并对商品知识图谱进行补全。某商品在知识图谱中可能存在以下2种情况:
1)知识图谱中存在特定商品所对应的实体
在该情形下,将知识图谱中商品实体i的属性所组成的集合定义为知识图谱中的商品特征集KFi={kf1,kf2,…},取评论特征集和知识图谱特征集的交集作为暂时确定的最终商品特征集Fi={f1,f2,…},如下:
Fi=CFi∩KFi
(1)
但是,仅取两者的交集是不够完整的,原因是知识图谱中的商品特征不完整,可能存在评论中是特征的词而知识图谱中还未收纳,因此,需要在该集合中找出确实是特征的词并补全到知识图谱中,定义待补全特征集为:
RFi=CFi-KFi
(2)
在得到待补全特征集RFi后,需要将真正表示特征的词从中提取出并加入到最终商品特征集Fi中。针对商品i的评论有若干条,每条评论可得到一个RFi,将所有评论的RFi组合在一起,合并相同的元素,同时记录特征f、特征出现的次数fn以及包含该特征的评论数fc,得到词仓库为:
WWH={(f1,fn1,fc1),(f2,fn2,fc2),…}
(3)
参考TF-IDF[15]中依据词频来计算词的重要程度的思想,本文构建一种基于词频的模型WTF-IDF,并将其应用于词仓库集合中。设一共有n篇用户评论,定义特征词频为:
(4)
逆向集合频率为:
(5)
词总权重为:
WTF-IDF=WTF×WIDF
(6)
根据WTF-IDF的值进行排序,取值最大的λ个词作为补充词形成补充词集SFi={sf1,sf2,…},将该词集补充到最终商品特征集中,即:
Fi=(CFi∩KFi)∪SFi
(7)
2)知识图谱中不存在该商品所对应的实体
在该情形下,KFi为空集,最终的商品特征集就为评论中的商品特征集:
Fi=CFi
(8)
在得到最终商品特征集Fi后,需要对知识图谱进行实体和特征补全。若该商品原先不在知识图谱中,将实体补全进知识图谱中,补全过程注意特征消歧[16]。然后将知识图谱进行特征集补全,即更新KFi=Fi。
3 商品推荐价值计算
将商品对用户群体的利用价值定义为商品推荐价值。在得到用户群体真正关心的商品特征集合后,分析商品特征的得分和权重,然后根据特征得分和权重计算商品推荐价值。
3.1 基于情感词的特征得分计算
在通过SRC-LDA得到商品特征对应的情感词后,根据情感词库中情感词对应的正面情感、中性情感和负面情感3种情况设置不同的得分,如表1所示。

表1 情感词语得分情况Table 1 Scores of emotional words
不同用户对同一商品特征往往会表现出不同的情感,此外,用户评论的时间也是一个重要的衡量因素,近期的评论应当更具价值。假设此刻的时间为nt,评论时间为ct,最大时间差Δt=nt-ctmin,β为时间差比,则定义时间参数为:
(9)
假设通过SRC-LDA求得某商品特征fi的情感词集为Efi={e1,e2,…},加入情感词得分s和时间T后,计算考虑时间的每个特征情感词的得分为:
es=s×T
(10)
情感词集转变为Efi={(e1,es1),(e2,es2),…},则该特征的总得分v定义为所有情感词得分es的n分位数。最后,商品特征集可更新表示为带特征得分的商品特征集Fi={(f1,v1),(f2,v2),…}。
3.2 KCRW特征权重分配
对于特征集合中的不同特征,需要分析其重要程度,即为每个特征分配权重。复杂网络中的随机游走模型[17]在克服数据稀疏性问题上能够取得良好的效果,其可以看作一个描述随机游走者访问顶点序列的马尔可夫链。文献[18]指出当游走达到稳态后,每一个节点被访问的概率可作为该节点的权重表示。但是,一般的随机游走模型将每个转移概率设置为定值,未考虑到不同商品具有不同相似度的特点。因此,本文将基于商品特征向量的商品相似度与基于知识图谱的商品相似度的加权作为随机游走中边的权值,构造转移概率矩阵,通过随机游走来传递商品间的影响关系,从而确定特征的权重。知识图谱中的随机游走策略如图1所示,其中,实线为关系边,虚线为游走路线。

图1 随机游走策略示意图Fig.1 Schematic diagram of random walk strategy
3.2.1 融合知识图谱的商品相似度计算
融合知识图谱的商品相似度计算分为2个部分:
1)基于商品向量的商品相似度sim
前文将每个商品以商品特征集Fi的形式来表示,Fi中仅包含该商品具有的特征元素,本节改进商品的表示形式,定义商品i的向量表示为:
Ii=(I1,I2,…)T
(11)
(12)
将所有商品表示为式(11)的向量后,用Pearson相关系数计算商品相似度:
(13)
2)基于知识图谱的商品相似度sim′
知识图谱中的商品实体之间的关系边同样可以表示商品的相似度。知识表示方法TransE[19]将知识图谱嵌入到低维向量空间中以进行计算,基于TransE的变种方法TransM[20]在嵌入的同时还可以表示出实体之间关系边的权重大小,该参数在一定程度上反映了商品在知识图谱网络结构中的相似关系。在知识图谱中,对于三元组
(14)
(15)
其中,Δr表示含有关系r的所有三元组,hr表示关系为r的三元组的所有头商品实体,tr表示关系为r的三元组的所有尾商品实体。基于TransM可得知识图谱的关系边权重,关系边权重可表示商品相似度:
(16)
结合基于商品特征向量的商品相似度与基于知识图谱的商品相似度,最终定义2个商品的加权相似度为:
(17)
Sim越大表示商品x与商品y越相似。
3.2.2 基于随机游走模型的特征权重分配
通过Sim可得任意2个商品之间的相似度,构建商品相似度矩阵如下:
(18)
(19)
令最大值元素为max,最小值元素为min,将所有元素进行0-1归一化:
(20)
将得到的商品相似度矩阵S作为概率转移矩阵并输入到随机游走模型中,第m次随机游走时的商品游走概率向量为Pm=(P1,P2,…)T,Pi指第i个商品的游走概率,则对应的随机游走策略为:
Pm=(1-θ)·P0+θ·S·Pm-1
(21)
其中,θ为阻尼因子,表示游走项到达某一商品节点后继续向后游走的概率,1-θ即表示下一次游走后返回初始商品节点的概率,阻尼因子θ一般取0.85[21]。经过多次的迭代随机游走,每个商品的游走概率逐渐趋于稳定,最终的商品游走概率向量为Pm。
在实际中,游走的节点对象是商品,而希望得到的却是特征向量f=(wf1,wf2,…)T,wfi指第i个特征的权重,因此,需要在商品和特征之间建立一层转化关系。商品i的向量为Ii=(I1,I2,…)T,设一共有n件商品,则可得到总商品矩阵为:
(22)
商品游走概率向量的实质就是商品的权重,而商品的权重又与特征的权重直接关联,因此,理论上商品游走概率向量也可以表示为特征权重的加权,即商品i的游走概率Pi可以表示为:
(23)
特征权重向量可表示为:
f=(I′)-1×Pm
(24)
最终的商品特征集可更新表示为带得分和权重的集合Fi={(f1,wf1,v1),(f2,wf2,v2),…}。
3.3 商品推荐价值计算算法
对于商品i,求得该商品的特征权重和特征得分后,根据其特征集Fi可计算推荐价值为:
(25)
求得所有商品的推荐价值后,根据推荐价值从大到小进行Top-k排序,分数高的商品应当更受到用户群体的喜爱,因此,推荐序列中的前k个商品给用户。
商品推荐价值计算(KCRW)算法描述如下:
算法1KCRW算法
输入商品i的特征集合Fi={(f1,v1),(f2,v2),…}
输出商品推荐价值序列
1.for each 商品i:
2.表示出商品向量Ii=(I1,I2,…)T
3.for each 商品i:
4.for each 除商品i以外的商品j:
6.构建相似度矩阵S
7.计算商品游走概率向量Pm=(1-θ)·P0+θ·S·Pm-1
9.计算特征权重向量f=(I′)-1×Pm
10.for each 商品i:
11.特征集合更新为Fi={(f1,wf1,v1),(f2,wf2,v2),…}
13.return 商品推荐价值序列
3.4 算法时间复杂度分析
假设一共有n个商品,每个商品包含m个特征。KCRW算法步骤1~步骤2的时间复杂度为O(n),步骤3~步骤5的时间复杂度为O(m·n2),步骤6~步骤7的时间复杂度为O(n2),步骤10~步骤12的时间复杂度为O(n)。综上,KCRW算法的时间复杂度为O(m·n2)。
4 实验结果与分析
4.1 实验设置
本文实验数据集包含用户评论和知识图谱2个方面。在用户评论方面,本文爬取的数据来自淘宝、天猫商城和京东商城这3个全球大型电商平台,其中涵盖了5 000个商品总共100 000条用户评论,每个商品平均约有20条用户评论。在知识图谱方面,本文选取1.4亿中文通用知识图谱思知(ownthink),数据以<实体、属性、值>、<实体、关系、实体>混合的形式存储在apache-jena-fuseki服务器中。
4.2 评价指标
实验使用准确率(Precision)、召回率(Recall)以及F值(F-Score)3个指标[22]进行评价,各指标的计算公式分别如下:
(26)
(27)
(28)
其中,TP指用户喜欢且推荐了的样本,FN指用户不喜欢但推荐了的样本,FP指用户喜欢但没被推荐的样本。
准确率反映了推荐算法的推荐水平,表示将用户喜欢的物品推荐给用户,而用户不喜欢的物品则不推荐。召回率反映了推荐算法所推荐的物品占用户真正喜欢的物品的比重。F值是准确率和召回率的加权平均。将数据集以6∶4划分为训练集和测试集进行实验。实验硬件环境:处理器型号为Intel®CoreTMi7-8550U CPU @ 1.80 GHz 1.99 GHz,内存为16 GB;实验软件环境:Python3.7.5,JDK-13.0.1,apache-jena-fuseki-3.13.1。实验参数设置如表2所示。

表2 实验参数设置Table 2 Experimental parameters setting
4.3 结果分析
4.3.1 特征参数确定
设定商品数量为5 000,评论数量为100 000,特征参数确定如下:
1)补充量λ和时间差比β的联合确定
设置嵌入维度k为200,探究不同λ和β下的准确率、召回率和F值,结果如图2所示。
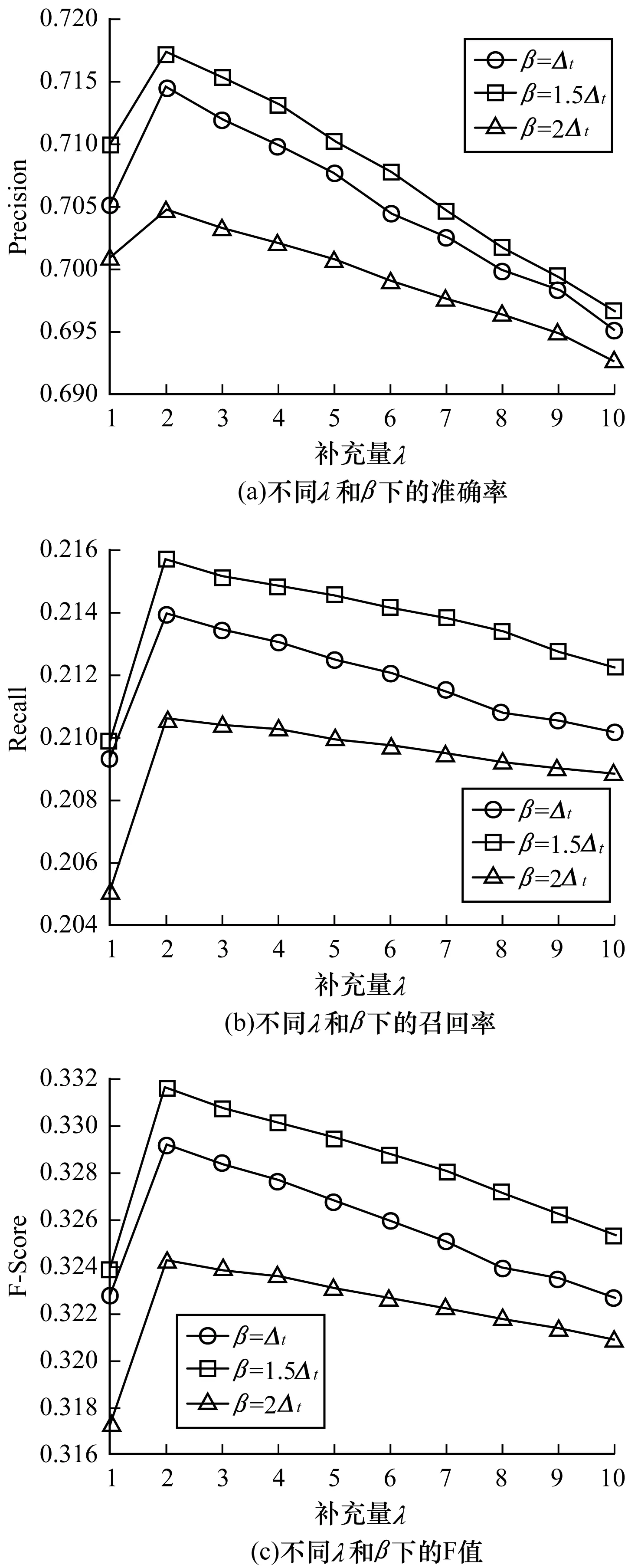
图2 不同λ和β值下的实验结果Fig.2 Experimental result under different λ and β values
从图2可以看出,随着补充量λ的提高,准确率、召回率和F值开始逐渐递增后来逐渐减小,当λ=2时达到峰值。因此,将最佳的补充量λ设置为2。此外,当时间差比β取1.5Δt时,准确率、召回率和F值相对较高,再增大β时准确率明显下降。
2)嵌入维度k的确定
已确定最佳补充量λ为2,最佳时间差比β为1.5Δt,探究不同k下的准确率、召回率和F值,结果如图3所示。

图3 不同k值下的实验结果Fig.3 Experimental result under different k values
从图3可以看出,随着嵌入向量维度k的提高,准确率、召回率和F值开始逐渐递增,在k=200时达到峰值,然后逐渐减小。因此,将最佳的嵌入向量维度k设置为200。
4.3.2 算法有效性验证
确定参数的最佳值后,补充量λ设为2,时间差比β设为1.5Δt,嵌入维度k设为200。将本文推荐算法与基于知识图谱的推荐算法(KG)[23]、协同过滤算法(CF)[5]、基于内容的推荐算法(CB)[7]和混合推荐算法(MX)[9]的推荐效果进行比较,分别探究在商品数量和评论数量变化时准确率、召回率和F值的变化情况,以验证本文推荐算法的有效性。
1)探究评论数量对算法性能的影响(商品数量设定为5 000)。从图4可以看出,随着评论数量的增多,本文算法的准确率、召回率和F值都在不断上升,准确率在评论数量大于40 000后明显优于其他3种算法,并且召回率和F值一直高于其他3种算法,本文算法相对其他算法的性能提升比率如表3所示。

图4 不同评论数量下的实验结果Fig.4 Experimental result under different number of comments

表3 本文算法相对其他算法的性能提升比率1Table 3 The performance improvement ratio 1 of the proposed algorithm compared with other algorithms %
2)探究商品数量对算法性能的影响(针对每个商品随机取10条评论)。从图5可以看出,随着商品数量的增多,本文算法的召回率在不断增大,F值趋于稳定,算法的准确率、召回率和F值一直高于其他3种算法,性能提升比率如表4所示。
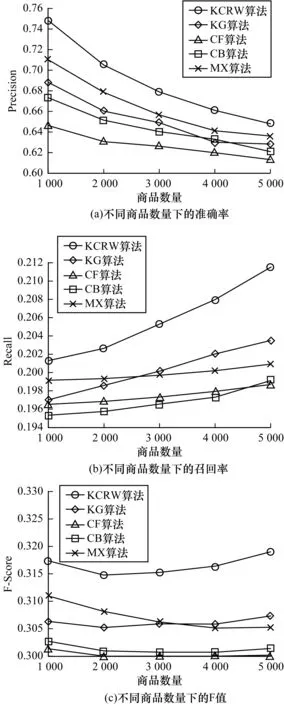
图5 不同商品数量下的实验结果Fig.5 Experimental result under different number of commodity

表4 本文算法相对其他算法的性能提升比率2Table 4 The performance improvement ratio 2 of the proposed algorithm compared with other algorithms %
5 结束语
本文提出一种融合知识图谱与用户评论的商品推荐算法,以商品特征作为研究对象使推荐更加准确。利用知识图谱的网络结构关联所有评论文本以挖掘商品特征信息,从而更充分地利用商品内部信息,然后进行知识图谱补全以避免数据稀疏问题。在随机游走模型中的相似度矩阵构建中结合知识图谱,使模型的准确性进一步提高。实验结果表明,本文商品推荐算法能够取得较好的推荐效果。用户评论和知识图谱之间还有很多待挖掘的内容,如评论中的隐语义部分含有大量的商品隐含特征,这些特征对于分析用户偏好具有较大作用。下一步将通过知识图谱来挖掘用户评论中的隐含信息,以提高推荐系统的准确性和有效性。
