基于深度森林的网络流量分类方法
2020-08-14王天宇王少尉
戴 瑾,王天宇,王少尉
(1. 南京大学金陵学院 信息科学与工程学院, 江苏 南京 210089;2. 南京大学 电子科学与工程学院, 江苏 南京 210023;3. 东南大学 国家移动通信研究实验室, 江苏 南京 210096)
随着Internet的发展,各种网络应用不断涌现,导致网络流量的复杂性快速增长[1]。网络流量复杂性的增加,本质上是网络中运行业务的复杂性不断增加而造成的。目前的网络业务主要来源于以下几个方面:一方面,随着生活和无线业务的互联网化,媒体、零售和金融等传统业务通过从线下搬到线上,逐步加入互联网;另一方面,随着人们学习生活需求的变化,不断有像慕课、电子支付和电子导航等新型的网络业务加入互联网;此外,随着5G时代的来临,大量基于增强移动宽带(enhance Mobile BroadBand,eMBB)的3D、超高清视频等大流量移动宽带业务,基于海量机器类通信(massive Machine Type of Communication,mMTC)的智慧城市、环境监测、智能农业等大规模物联网业务,以及基于超高可靠超低时延通信(Ultra-Reliable Low Latency Communication,URLLC)的无人驾驶、工业自动化等新兴网络业务将会充斥整个互联网。如何有效地从海量的网络数据中识别出应用类型,如何从流量数据中分析提取有价值的信息,已经成为人们关注的重要技术领域。因此,网络流量分类作为增强网络可控性的关键技术,在网络资源分配、流量调度和网络安全等诸多研究领域受到广泛关注[2]。
网络实际应用中流量数据具有结构复杂、数量庞大和属性随着网络状态动态变化的特性[3],机器学习算法在解决诸如此类规模大、复杂性高的网络流量分类问题中表现出先天的优势。目前研究使用的基于机器学习的流量分类方法主要包括支持向量机(Support Vector Machine,SVM)、卷积神经网络(Convolutional Neural Network,CNN)和 随机森林(Random Forest,RF)算法。在文献[4]中,作者采用了基于流的分析方法,使用SVM分类算法对动态端口和加密应用程序按流量进行分类,流量分类算法的精度为88.785%。文献[5]将流量分别处理为时间序列、图片和视频,模型训练前将网络流预处理成为灰度图,把CNN对图像识别的能力应用到网络流量分类中,其分类精度可达到93%。文献[6]提出将RF方法应用到网络流量分类问题中,随机森林通过综合多个决策树的预测和样本属性的随机选取,能较好地解决网络流量样本种类数量失衡而产生的过拟合问题。
目前的网络流量分类方法依然存在准确率不高、开销大且应用领域受限等问题。其中单一机器学习分类方法在复杂多变的网络环境下,分类性能往往会迅速下降。例如:SVM分类器更利于对线性属性的数据样本的处理,处理离散的、大规模的数据分类处理时,分类准确率低;CNN分类器擅长解决图像样本的分类问题,网络数据流需要经过烦琐的预处理过程生成图像,当网络层数过多时,会出现计算复杂度高、运行速度慢等问题。在文献[7]中比较了121个数据集上的数百个分类,结果表明基于RF分类器解决网络流量分类问题是最适合的方法,分类精度可达到94.1%,但RF在处理多分类、样本规模小、噪音较大的流量样本时,依然容易出现过拟合的现象。
针对上述问题,本文提出基于多粒度级联森林(multi-grained cascade Forest, gcForest)算法来构建网络流量分类器。 gcForest是一种决策树的深度监督网络算法,该算法采用多粒度扫描样本和级联多种分类器的设计思想,使分类模型不受样本数量规模和特征向量规模的限制[8]。gcForest在解决商品分类、手部运动识别、情感分类以及垃圾邮件发送者检测等多分类问题中均表现出了优越的性能[9]。
1 数据集
研究中利用了经典的Moore网络流量集训练和测试分类模型,它是Moore等采集并经过统计处理的剑桥大学的流量数据。Moore数据集曾被用于众多网络流量识别和分类等领域[10]。
1.1 定义
Moore_set网络流数据集是通过采集主干网上的数据,经过基于流的分析方法处理获得[11]。数据集中的样本数据包含了大量在会话规模尺度上统计处理网络层和传输层的消息生成的特征属性,包括流量持续时间的分布、流量空闲时间、数据包到达时间、数据包长度等。数据集中的每个样本均由一组统计信息和一个定义网络应用程序的类别来描述。
数据集中每一个样本都是以特征属性描述的一条完整的传输控制协议(Transmission Control Protocol,TCP)流。在Internet中,TCP流可以定义为在两个计算机地址之间传播的一个或多个数据包。TCP作为一种有状态的协议,对TCP流定义了明确的开始标志和结束标志。因此,研究者能够有效地从纷乱的网络数据包中提取出完整的TCP流,也称之为会话。进一步对TCP流中每个数据包提供的信息进行分类统计,统计结果就是标识流样本的特征属性。本研究中选用的Moore_set数据集,就是由剑桥大学的高性能网络监测器在不丢失数据包的情况下,全速率捕获和统计处理数据包而生成的完整TCP流的样本数据集合。该数据集中包含的11种不同应用类型的分布情况如表1所示。其中由于INTERACTIVE类型的样本在数据集中的数量太少,仅有3条流样本,无法正常参与训练,因此本文所使用的模型训练和测试的数据子集不包含此分类,实验中训练的是10种网络流量的分类模型。
在本问题中,流集合被定义为D= {d1,d2, …,dn,…,dN,},其中每个样本dn包含248个特征属性,N为基于流的数据样本的数目,N=24 863。定义类别属性集合C={c1,c2, …,cm,…,cM},其中M=11表示有11个不同的类别。流量分类问题可以定义为构造从流集合D到类别集合C的映射关系:cm=f(dn)。
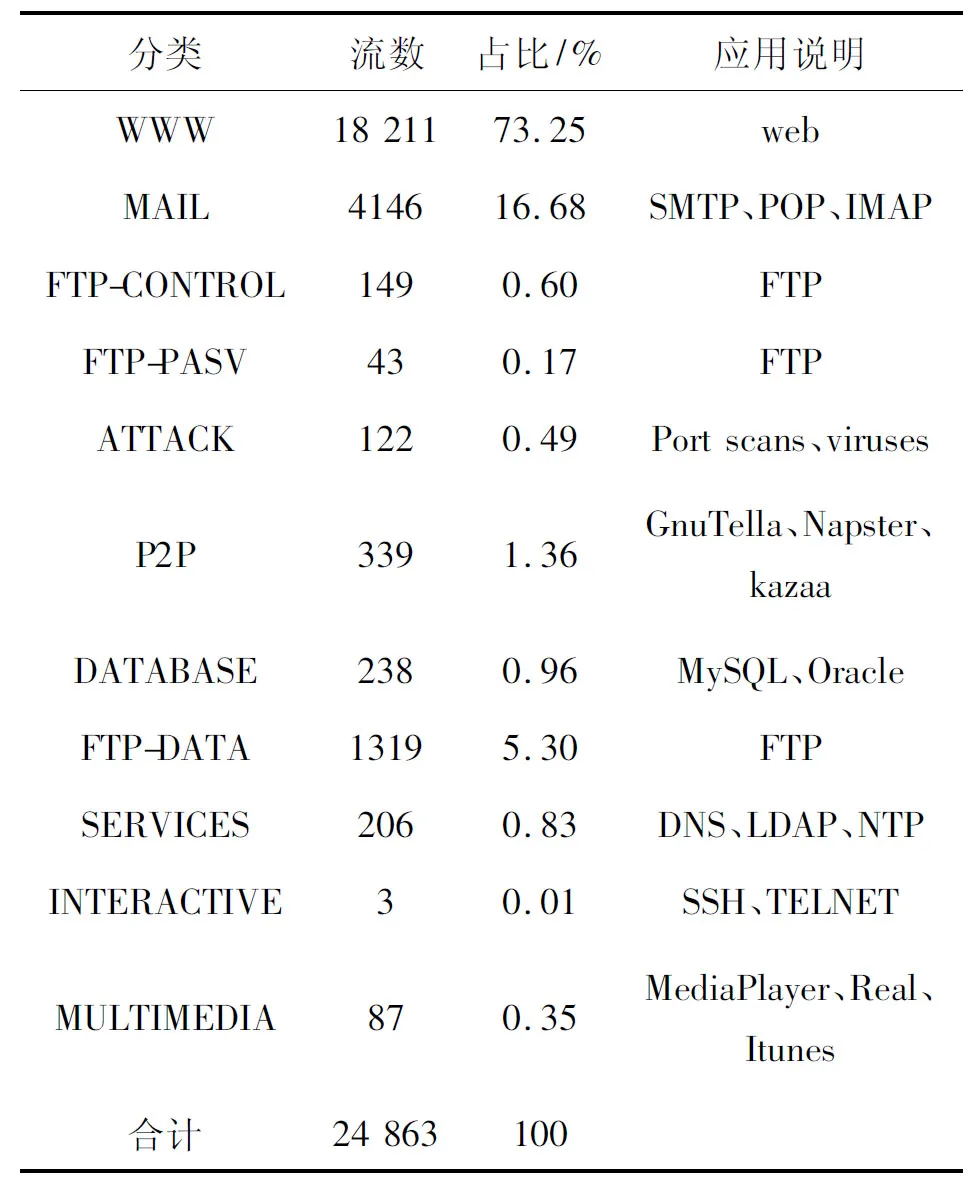
表1 TCP流数据集的应用类型分布
1.2 特征选取
在监督分类的机器学习中,无关和冗余的特征属性往往会给分类的准确性带来负面影响。通过选择出能高度区分不同流类别的特征向量来降低样本维度,对于模型训练的速度以及分类的准确性是至关重要的。因此,本文采用人工选取加算法测试的方法从Moore_set的248个特征属性中选出13个特征属性用于分类模型的训练和测试,样本的特征属性及描述如表2所示。
2 模型描述
本文提出的网络流量分类器是基于gcForest深度机器学习算法,其核心思想是优化的决策森林。算法所采用的多粒度扫描和级联森林两种关键技术在流量分类中发挥了重要的作用。gcForest分类器组织结构如图1所示。
2.1 级联森林
在gcForest算法中,森林是由决策树构成的决策树森林,即森林中的每棵树都是由决策树的节点分裂生长而成,每个决策森林中又包含了许多棵决策树。其中决策树的种类和棵数是算法的超参数,可根据解决问题的规模进行适当的调整。在解决本文中的流量分类问题中,可设置为4个决策森林:2个随机森林和2个完全随机森林。

表2 选取的流特征属性及其描述
级联森林拥有多个网络层,每个森林将产生一个类向量,分别代表检测的网络应用的分布概率,如图1所示。在这个网络流量分类问题中,每个森林会产生一个10维的类向量,每层输出的结果和原始输入属性相连接构成了级联森林下一层的输入。训练过程中,层级将会不断深入,直到某层触发终止条件,停止层级的增长。终止条件为达到所需精度或达到最大层数。在最后一层上,gcForest算法计算求得四类向量的平均值,并从中选出概率最大的类作为最终的分类结果。由此可见,这种级联机制可以实现样本特征向量的跨层级处理,且层数根据计算规模自动调整,有效减少了算法的复杂度。
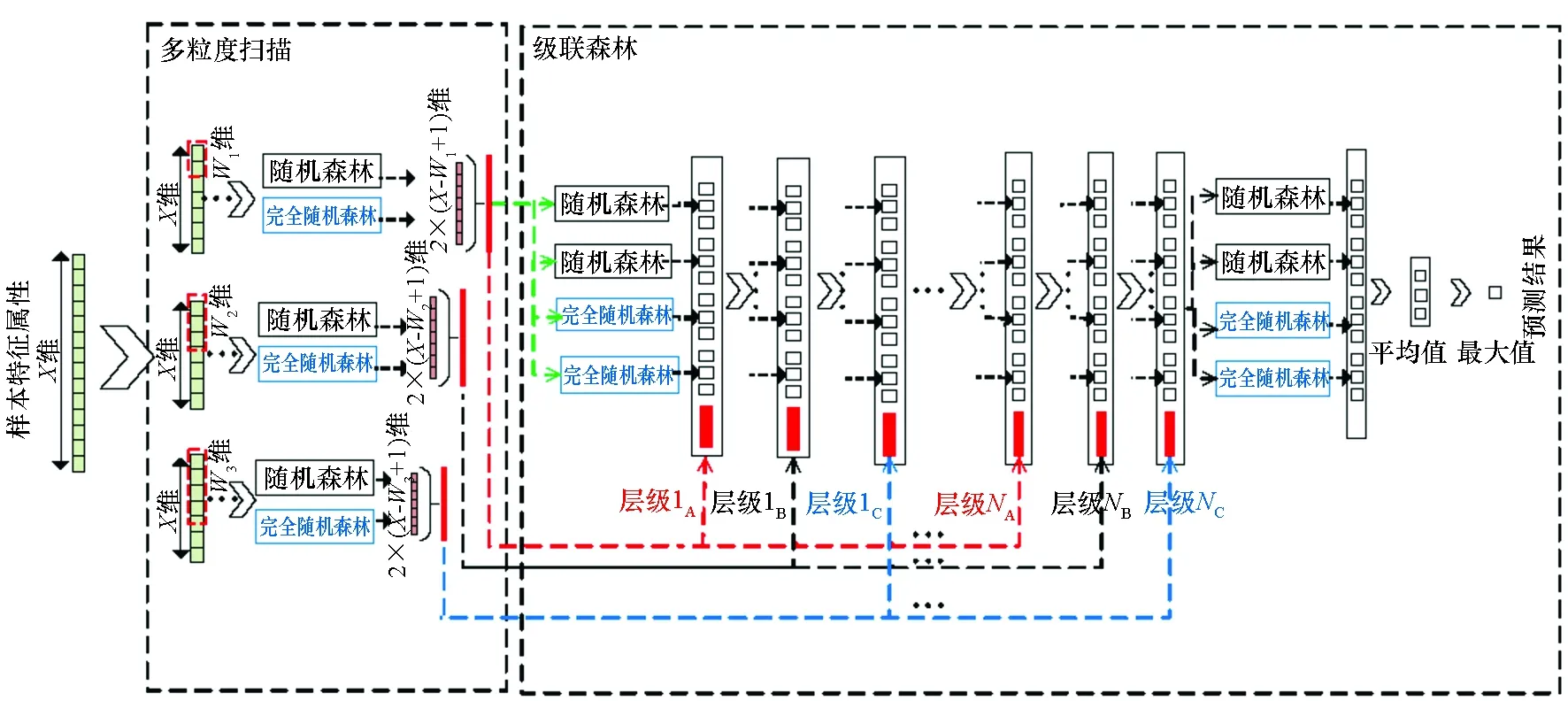
图1 gcForest结构Fig.1 Constructure of gcForest
2.2 多粒度扫描
在深度学习模型的启发下,gcForest还利用多粒度扫描技术对级联森林进行增强。多粒度扫描是在模型中引入了类似卷积神经网络的多个滑动窗口。如图1所示,在一个具有多分类能力的深度森林分类器中,输入一个完整的X维样本,首先通过长度为W的滑动窗口进行采样,得到X-W+1个W维特征向量的子样本集合;随后子样本集合分别送入完全随机森林和普通随机森林进行训练,每个子样本从每个森林中分别获得一个长度为分类个数的概率向量;然后把每层所得所有森林的结果拼接在一起,得到该层输出。gcForest通过多粒度扫描,实现了对同一个样本不同规模的局部特征的选取,有效地增强了样本的维度和样本特征属性之间的关联。
3 实验结果和分析
3.1 gcForest分类模型
在本实验中,采用了人工选取特征结合模型测试的数据预处理方法。根据常用TCP流量统计特征预选出17个特征属性,逐一剔除特征属性构建训练数据集,输入gcForest算法训练模型并测试分类准确率。当某项特征属性去除后,准确率没有变化或有微弱的上升,表明它属于冗余、相关性极弱的特征,可以剔除。数据集经过预处理后,剔除了4个特征属性——pure_acks_sent_serverTOclient、pure_acks_sent_clientTOserver、mss_requested_serverTOclient和mss_requested_clientTOserver,最终确定在样本中引入了server_port、client_port、actual_data_ pkts_clientTOserver、duration等13种特征属性,详细内容见表2。
实验训练数据利用Moore_set的 24 863个样本,从中选出25%的样本共6226条网络流用于gcForest算法分类模型训练和测试数据子集, 其中4980条网络流用于模型训练,占数据子集的80%;剩余的20%(包含样本1246条网络流)作为测试集,用于模型的精度测试。样本集中包含了WWW、MAIL、DATABASE、FTP-DATA等10种网络应用类别。
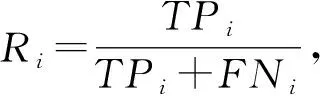

表3 各类样本的查全率和查准率
3.2 模型性能
在相同测试集上,将gcForest分类器同传统的SVM和RF分类器在分类正确率和测试时间两个方面进行了比较,如表4所示。实验设备采用主频1.6 GHz 的Intel Core i5-8250U处理器,内存容量4.0 GB的单机。实验数据显示,基于RBF核函数的SVM的准确率为49.14%;基于线性核函数的SVM的准确率为88.17%;RF的准确率是96.15%;gcForest准确率最高,为96.36%。 然而,gcForest分类模型在线预测1000条流量数据的时间为0.902 s,计算速度低于基于线性核函数的SVM分类器和RF分类器,但略高于基于RBF核函数的SVM分类器。
实验结果表明,尽管在测试时间的效率上gcForest分类器没有表现出绝对的优势,但就模型分类准确率而言,gcForest流量分类器远高于传统的SVM单分类算法,甚至比目前公认最适宜解决流量分类问题的RF算法的性能更好。

表4 不同分类模型的性能比较
4 结论
对网络流量进行准确的识别是网络资源分配和网络安全保障的重要依据,也是提高网络应用服务质量的重要手段。为了进一步提高网络流量识别的正确性和稳定性,提出基于gcForest的网络流量分类方法,并在Moore数据集上进行了训练和测试,最终结果表明该分类器对网络流量分类的整体准确率达到了96.36%,网络流量分类的性能好于传统SVM和RF机器学习分类方法。
