RBAC中角色挖掘算法研究*
2020-08-14袁学斌李文萍刘生成李宗容张文倩
袁学斌,李文萍,刘生成,李宗容,张文倩
(1.国网青海省电力公司电力科学研究院,青海 西宁 810008;2.中国移动通信集团青海有限公司,青海 西宁 810007;3.国网青海省电力公司信息通信公司,青海 西宁 810000)
0 引言
基于角色的访问控制(Role based Access Control,RBAC)相比于传统访问控制有诸多优势,因其安全性、灵活性、可扩展性已成为目前应用最广泛的访问控制技术之一。构建RBAC的核心是角色的发现,发现角色的方法称为角色工程,其中将自底向上的角色工程方法简称为角色挖掘[1]。角色挖掘通过智能化方法在系统中将已存在用户-权限关系得到合适的角色[2],是如今访问控制中研究的重点。尽管角色挖掘研究已取得很多成果,但目前仍存在一些问题,如算法生成角色数较多,给系统实施和维护带来负担,角色挖掘算法精度低、运行效率低下等一系列问题,因此如何使算法高效且有效是一个具有研究价值的课题。
1 基于角色的访问控制
1.1 RBAC模型
RBAC模型有别于传统访问控制模型自主访问控制模型(Discretionary Access Control,DAC)和强制访问控制模型(Mandatory Access Control,MAC),通过角色将用户和权限进行逻辑隔离。RBAC模型中基本包含:角色集、用户集、权限集、角色-权限指派关系和用户-角色指派关系等基本元素,RBAC核心模型如图1所示。
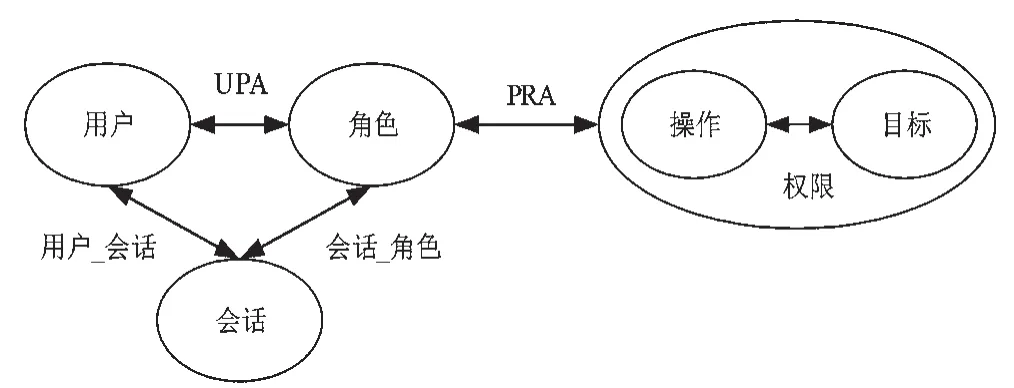
图1 核心RBAC模型
RBAC模型中用户得到角色,然后为角色分配权限,用户由此得到相应的权限[3],在RBAC模型中,角色是整个模型的关键,角色的本质就是权限集[4]。因此RBAC相比于传统的访问控制模型,更加符合各类组织的安全要求,应用更加广泛。考虑到角色间的分层关系对于提升RBAC安全性、实用性十分重要,RBAC中又可以分为层次RBAC模型,在层次RBAC模型中,考虑了角色分层(Role Hierarchy,RH)的概念,层次RBAC模型如图2所示。
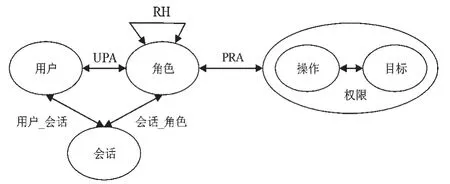
图2 层次RBAC模型
RH中定义了角色之间的继承关系,如果角色R2的所有权限都包含在角色R1权限集内,则角色R2继承角色R1。层次RBAC可以避免同一权限在信息系统中的重复存储,降低了存储代价,提高了管理效率,同时也更加符合现实应用,得到了广泛应用。
1.2 角色挖掘
角色挖掘的研究工作始于2003年,在文献[5]中首次提出了角色挖掘技术,如今对于角色挖掘的研究正日益深入,现在已提出了众多算法并且很多已经应用于实际。角色挖掘中最主要的目的就是构建RBAC系统,随着该研究领域需求的日益重要,对于角色挖掘中很多重要问题有必要进行深入分析,其中最重要的就是角色挖掘算法的优化目标。
1.2.1 预备知识
首先给出角色挖掘算法中经常出现的概念:
USERS,用户集;数量为m;
PERMS,权限集;数量为n;
ROLES,角色集,数量为k;
UA⊆USERS×ROLES,指用户-角色分配关系m×k;
PA⊆ROLES×PERMS,指角色-权限分配关系k×n;
RH⊆ROLES×ROLES,指角色继承关系k×k;
UPA⊆USERS×PERMS,指用户-权限分配关系m×n;
RoleUsers(r)={u∈U|(u,r)∈UA},指赋予角色R的用户集合;
RolePerms(r)={p∈P|(r,p)∈PA},指角色R分配的权限集合。
1.2.2 角色挖掘数据来源
角色挖掘是将系统中已存在的用户-权限分配关系,通过智能化的方法转化为RBAC系统。图3中所示为将UPA数据通过角色挖掘技术得到候选的角色集,其中角色挖掘技术一般是指数据挖掘技术,所以在角色挖掘算法中,输入为UPA数据,输出为生成的角色集。
随着对角色挖掘研究的不断深入,在分析如今日益复杂的信息系统访问控制策略并生成角色时,现有的角色挖掘算法仍然存在很多问题和不足,如产生冗余角色多、角色精度低、算法效率低下等,给系统的部署、使用和维护带来诸多问题,具体问题如图4中所示,本文的研究也是为了解决其中一些关键的问题。

图3 角色挖掘

图4 角色挖掘关键问题
2 YMiner算法设计
2.1 GO算法
Graph Optimisation(GO)算法由Zhang等提出[6],该算法将角色挖掘问题视为图优化问题,利用图优化技术来得到合适的角色集。GO算法首先将每个用户的权限集视为一个角色,以最小化角色数和边的数量为优化指标,对两个角色迭代进行处理运算,来得到新的角色。该算法输出结果为完整RBAC状态,包含角色之间的继承关系,图5所示为GO算法在某数据集生成的角色继承关系,是经典角色挖掘算法之一。
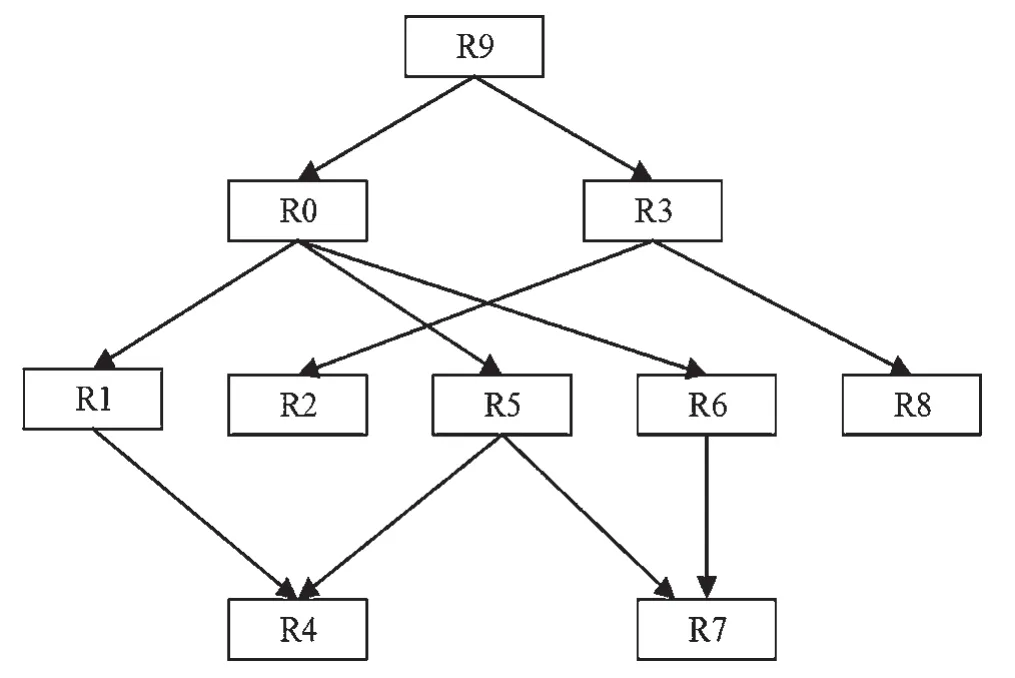
图5 GO算法生成的角色继承关系
2.2 GO算法缺陷
GO算法基于图优化理论,通过优化指标对初始角色集迭代进行交集运算,来得到新的角色,但是在算法设计方面仍有可以改进的地方,其最主要的问题主要有[7]:第一,GO算法以最小化边数和角色数为优化指标。将每个用户的权限集视为一个角色,得到初始角色集,之后根据优化指标对其进行角色间的处理,得到新的角色,这意味着其目标是最小化角色数、角色-角色继承关系指派成本、角色-权限的指派成本,并不考虑直接用户授权等成本,在角色挖掘领域中用加权结构复杂度来代表角色指派成本;第二,在对角色进行处理时不考虑角色间相似度。角色相似度是指两角色间的相似程度,相似度越大说明两角色含有的相同权限就越多,相似度为1则说明两角色含有相同的权限集。如果在角色生成时忽略了这一要素可能导致:(1)算法产生的角色不能准确反映实际需求,即角色集精确度低;(2)产生冗余角色,给系统实施和维护带来负担。因此有必要在角色合并时考虑这些因素。
2.3 角色相似度计算
在上文中讨论了角色相似度在角色合并时的重要性,本文中将角色相似度定义如下:
定义 2.1 权限相似度
权限相似度是指两个角色拥有的共同权限集与所有权限集之比[8]。即:
其中RolePerms(r1)是角色r1拥有的权限集,RolePerms(r2)是角色r2拥有的权限集。
定义2.2 用户相似度
用户相似度是指两个角色拥有的共同用户集与所有用户集之比[9]。即:

其中RoleUsers(r1)是角色r1拥有的用户集,RoleUsers(r2)是角色r2拥有的用户集。
定义2.3 角色相似度
角色的本质是权限的集合,因此角色间的相似度定义为:
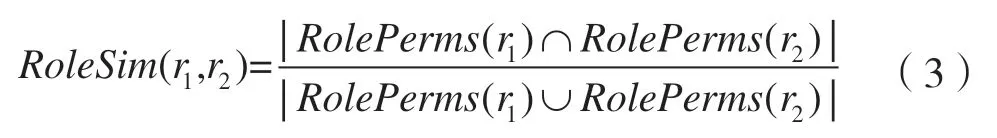
其中RolePerms(r1)是角色r1拥有的权限集,RolePerms(r2)是角色r1拥有的权限集。
2.4 加权结构复杂度计算
Ian Molloy[10]等人基于前人提出的角色挖掘算法,提出使用加权结构复杂度(Weighted Structure Complexity,WSC)来综合衡量角色指派成本和角色挖掘算法性能。在该评价指标中给出权重因子
W=<WR,WUA,WPA,WRH,WD>,WR,WUA,WPA,WRH,WD
是所有非负有理数集合;给定系统状态五元组<ROLES,UA,PA,RH,DUPA>,ROLES为角色集,UA为用户-角色指派关系,PA为角色-权限指派关系,RH为角色层次关系,DUPA为进行角色指派后对用户进行权限指派,||表示集合的基数,RBAC加权结构复杂度函数定义如下:
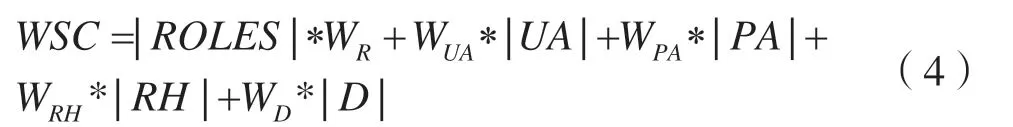
WSC中通过对五元组设置不同的权重,可得到不同的RBAC状态,充分考虑了RBAC的所有关系。当W=<1,1,1,1,1>时,表示希望得到一个完整RBAC系统成本。在公式(4)中如不考虑DUPA因素,此时WSC只考虑前四个因素,当WSC作为角色挖掘算法评价标准时,一般不考虑DUPA。
2.5 算法全局优化函数计算
GO算法将最小化角色数和边数作为最优化函数,本文提出的最优化函数中使用WSC,来降低算法角色权限指派成本;同时在产生新角色时考虑角色相似度,得到全局最优化函数,计算如下:

本文中最优化函数是一个多目标优化问题,从公式(5)可知,本文算法的优化目标是最小化WSC,是为了减少指派成本,同时最大化两角色间的相似度,这是为了考虑角色优化时的情况。其中a取值在0和1之间,是一个权重因子,可根据实际需要进行调整。在公式(5)中当a的值取0时,此时全局优化函数L只考虑加权结构复杂度;当a的值取1时,此时全局优化函数L考虑角色间的相似度。
2.6 YMiner算法
GO算法在设计时因没有考虑角色相似度、角色指派成本等因素,导致算法存在生成角色集精度低、冗余角色多等问题。本文针对GO算法存在问题,设计新的算法全局优化函数,得到新的算法YMiner(YM),在YM算法中,处理角色间关系时考虑角色权限集之间的四种情况,分别为:第一,两角色权限集相同;第二,一个角色权限集是另一角色权限集的超集;第三,两个角色有共同权限集;第四,两角色间的权限集无任何关系。在YM算法中处理完角色间的不同的情况后更新角色状态,得到最终的角色集合,算法的流程如图6所示。
图7、图8、图9所示分别为YM算法中在处理不同角色集情况时的处理方法。图7所示为处理两个角色拥有相同权限集时的情况。如果两个角色拥有相同权限集,则根据角色相似度计算公式,则相似度为1,此时删除其中一个角色,剩下一个角色的用户集是处理前两角色用户集之和。将两个角色合并为一个角色将改善优化指标,减少了角色数量,并且减少边的数量,这种情况将有效降低加权结构复杂度,有利于降低优化指标。
图8所示为处理一个角色权限集是另一角色权限集的超集时的情况,此时创建一条从超集权限集角色到子集权限集角色的链接,保留超集到除子集对应权限的链接,删除超集到其他权限的链接,此时拥有超集权限的用户不直接得到子集权限,而是间接通过得到子集角色得到权限。当进行上述操作时,角色数没有发生变化,对优化指标可能没有影响。
图9所示为处理两个角色拥有相同权限集的情况,此时创建一个包含公共权限集的角色,此角色的用户集是两个父角色用户集的并集;之后分别创建两条父角色到子角色的边,以显示角色间的层次关系;最后新创建的角色的权限集是原来两个父角色权限集的交集。当进行上述操作时边数可能会降低,有利于降低优化指标。

图6 YMiner算法流程图
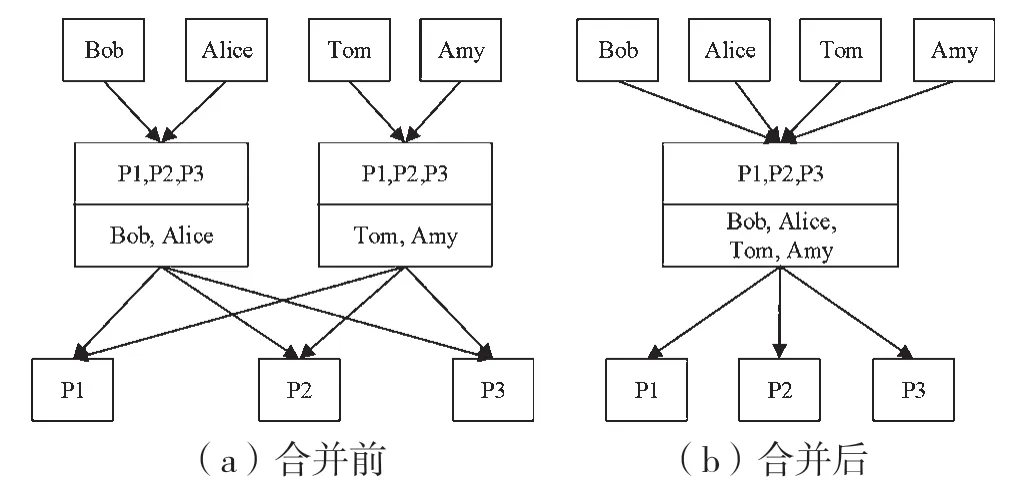
图7 两角色拥有相同权限集

图8 一角色权限集是另一角色权限集超集
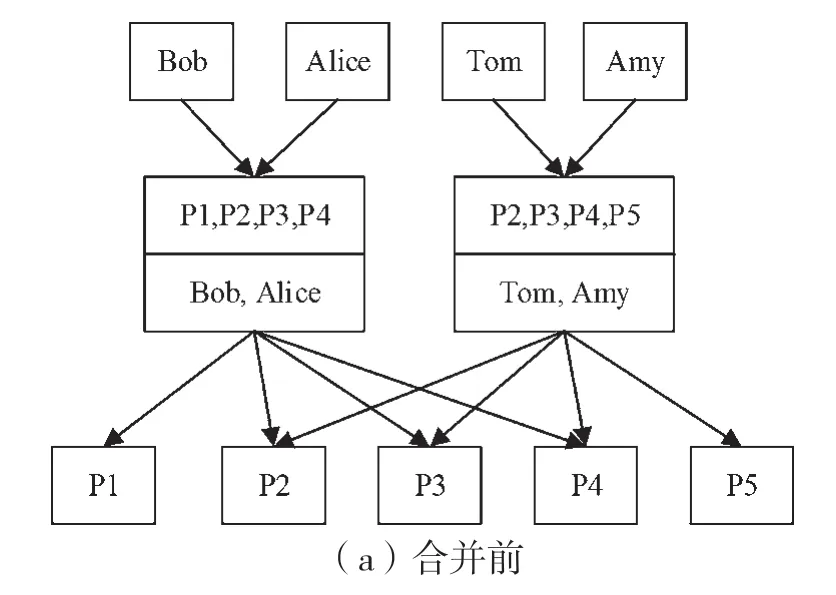
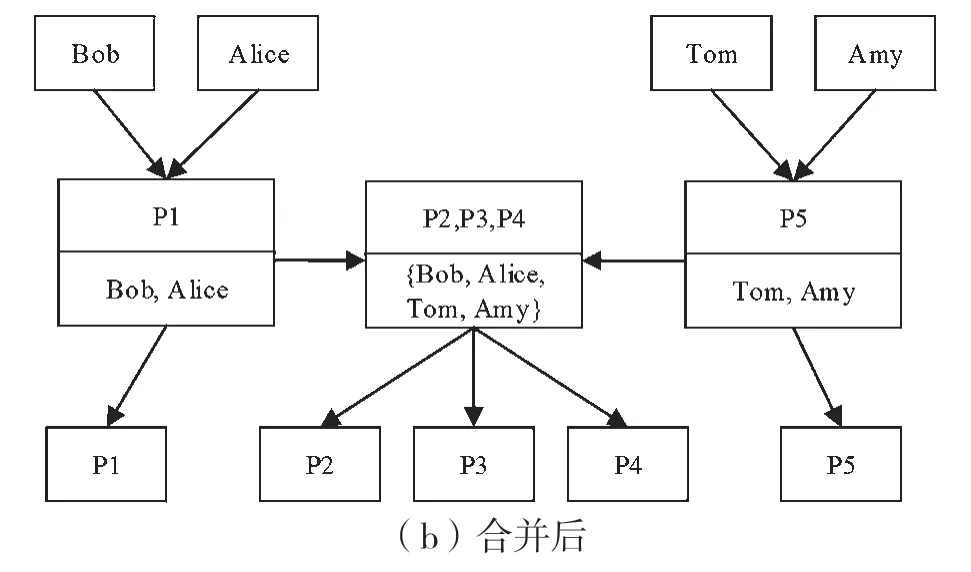
图9 两角色拥有相同权限集
第四种情况两角色权限集不存在任何关系时,对两角色不做任何处理。
YM算法具体如下:
YM算法
输入:用户集USERS、权限集PERMS、用户-权限指派关系UPA
输出:最终的角色集ROLES
1:使用角色生成方法将UPA数据生成初始角色集
2:whilethere can be more mergesdo
3:从初始角色集中选择两个角色R1和R2
4:if(两角色R1和R2权限集相同)
5:处理相等情况
6:end if
7:计算全局最优化函数L1=(1-a)*WSC
+a*RoleSim
8:if(一角色权限集是另一角色权限集子集)
9:处理子集情况
10:计算处理后全局最优化函数L2=(1-a)
*WSC+a*RoleSim
11:if(L2>L1)
12:then
13:撤销子集操作
14:else
15:L2=L1
16:end if
17:end if
18:计算当前的全局最优化函数L1
19:if(两角色拥有共同权限集)
20:处理交集情况
21:计算处理后全局最优化函数L3
=(1-a)*WSC+a*RoleSim
22:if(L3>L1)
23:then
24:撤销交集操作
25:else
26:L1=L3
27:end if
28:end if
29:end while
30:return Roles
3 实验结果
在本节中,将上节中所得YM算法和另外四种经典角色挖掘算法在真实数据集上通过加权结构复杂度和算法运行时间进行对比实验,来说明其性能,这四种算法分别为HP Role Minimization (HPr),HP Edge Minimization (HPe),Complete Miner(CM),GO。其中HPr算法主要目标是找到最小角色集,HPe算法的主要目标是最小化角色间边的数量,CM算法的时间复杂度呈指数增长,不合适使用于数据量很大的情况。本文的实验环境如表1所示。

表1 实验环境
3.1 真实数据集
本实验使用的真实数据集总共包括七个数据集,相关数据如表2所示,这些数据集被经常用于各类角色挖掘算法的对比实验。

表2 真实数据集
其中,|users|代表用户数,|permissions|代表权限数,|UPA|代表用户-权限分配关系中1的个数;|Density|代表数据中1的个数占总数的比例。数据集APJ和EMEA是从惠普公司网络的思科防火墙中抽取得到[11],这些数据描述了公司授权的外部用户对于企业内部资源的访问情况;Healthcare数据集来源于美国退伍军人管理局;Domino数据集是从Lotus软件用户访问数据中获得;University数据集是从某大学得到的访问控制数据;数据集Firewall1和Firewall2是从防火墙监测点得到的访问控制数据。
3.2 算法评价标准
(1)加权结构复杂度。在上文中已经对WSC进行了详细介绍并给出了计算方式,当四元组取不同值时,在RBAC系统中评价标准不同,算法结果不同。当W=<1,0,0,0>时,算法的目标最小化角色数;W=<0,1,1,1>时,算法的目标是最小化边数;W=<1,1,1,1>时,算法的目标是最小化边数和角色数,WSC已成为角色挖掘算法的主要评价标准之一。
(2)算法运行时间。WSC提供了一种统一的评价标准来评价角色挖掘算法,但是在算法分析中算法运行时间同样重要。在本文实验的综合评价中加入算法运行时间,通过多种评价标准可以更全面、更综合的对算法进行评价。
3.3 实验结果分析
本文将YMiner算法与另外四种经典角色挖掘算法,在加权结构复杂度、算法运行时间等指标下分别进行对比实验,作详细对比分析。将每个算法在不同数据集上得到的结果进行升序排序,之后将该算法在所有数据集上的排名进行综合排名,得到Ranking,根据Ranking可非常直观判断算法性能,具体计算方式如下:如当W=<1,0,0,0>时,算法CM在七个数据集上结果分别为1,2,3,2,5,5,4,Ranking=(1+2+3+2+5+5+4)/7=3.14,Ranking的值越小说明该算法在这项比较中综合性能越好。
表3是W=<1,0,0,0>时的实验结果,此时f(τ,W)=|ROLES|*WR,算法的目标是产生角色数最少。表中第一列是数据集名称,后序列是各算法在不同数据集产生的角色数。在上文中提到HPr算法优化目标是最小化生成角色数,在生成角色最少这一指标上表现非常出色,GO算法的结果也表现突出,YM算法同其他算法相比明显减少了产生的角色数量,同时YM算法产生角色数相比GO算法平均少4.3%,CM算法设计时最大缺点便是生成角色数众多,实验结果说明了这一特征。
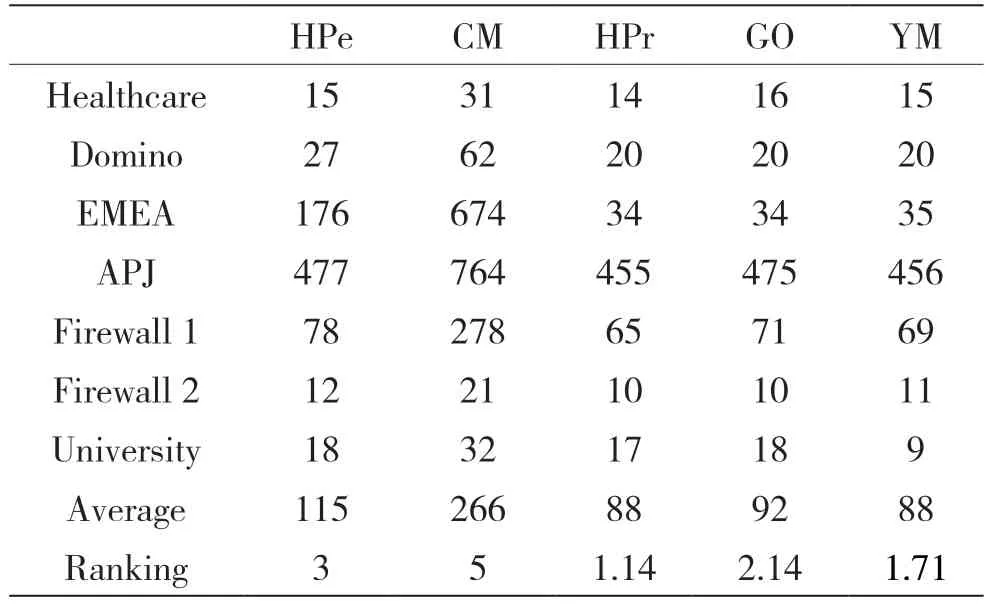
表3 W=<1,0,0,0>,即算法的目标是角色数最少
表4是W=<0,1,1,1>时的实验结果,此时f(τ,W)=|UA|*WUA+|PA|*WPA+|RH|*WRH,此时算法的目标是产生的边数最小。HPe算法的主要目标是最小化角色间边的数量,从上述实验数据便可说明这一特点;YM算法产生边数相比GO算法平均少15.9%,YM算法在小数据集上表现优异,但在大数据集Domino、EMEA、APJ上不如小数据集优异,需进一步分析和改进。
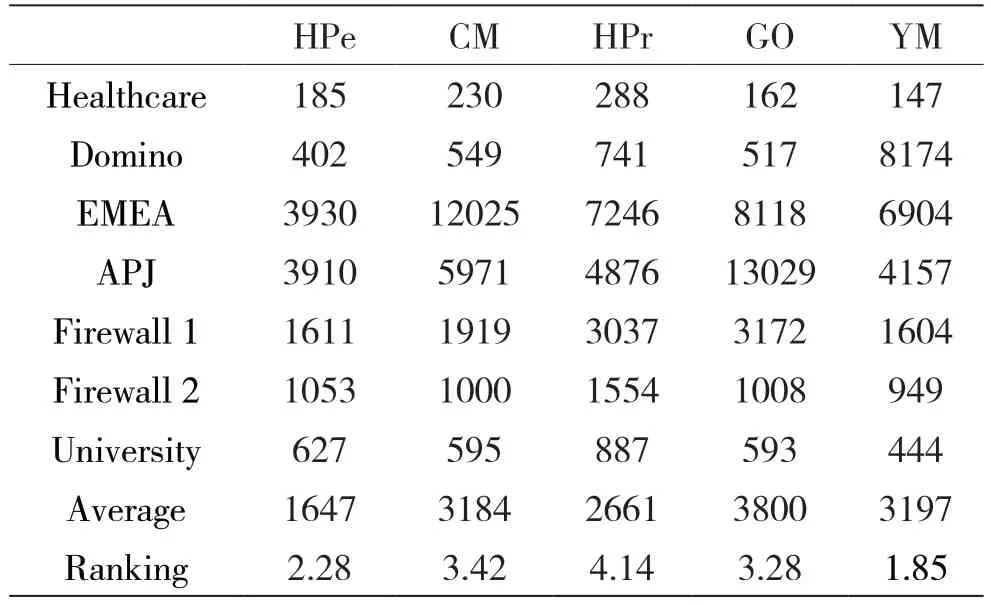
表4 W=<0,1,1,1>,即算法的目标是边数最少
表5是W=<1,1,1,1>时的实验结果,此时f(τ,W)=|ROLES|*WR+|UA|*WUA+|PA|*WPA+|RH|*WRH算法目标是产生角色数和边数最小。GO算法的优化指标为最小化角色数和边数,上述实验结果验证了GO算法的这一特点;因为YM算法在优化指标中考虑了角色指派后对用户进行权限指派,导致此项结果算法产生角色数和边数多于GO算法,不过与其他算法相比,性能表现依然出色。
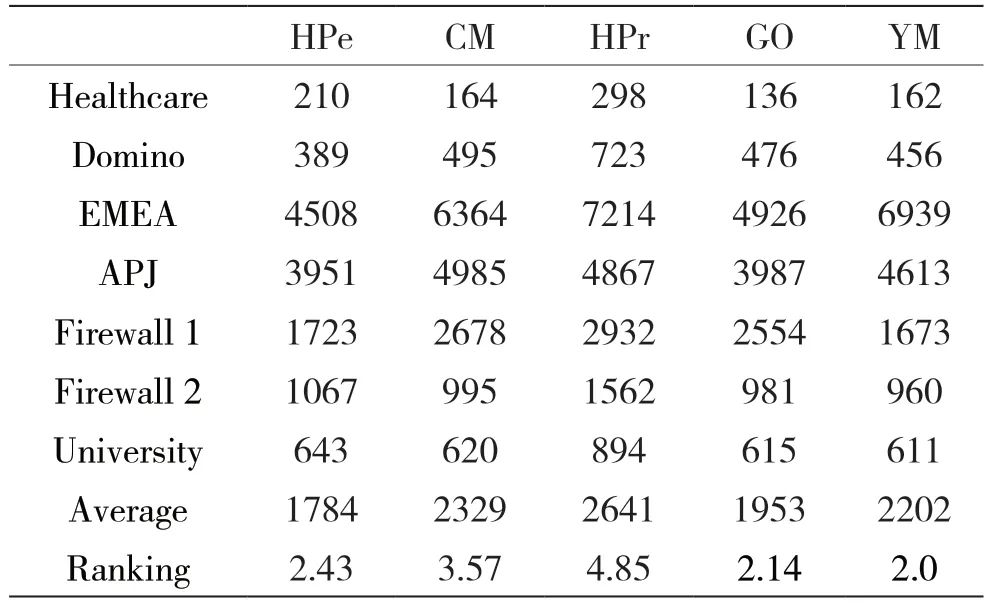
表5 W=<1,1,1,1>,即算法目标是最小化边数和角色数
表6是算法运行时间对比,从上述数据中可以明显看到,YM算法在各个数据集上运行速度最快,其他算法则运行效率相差不大,YM相比其他算法运行效率得到极大提升,这是因为YM算法在设计时考虑了角色间相似度,这有助于在后续步骤角色处理时大幅提高效率,进而提升算法运行效率。
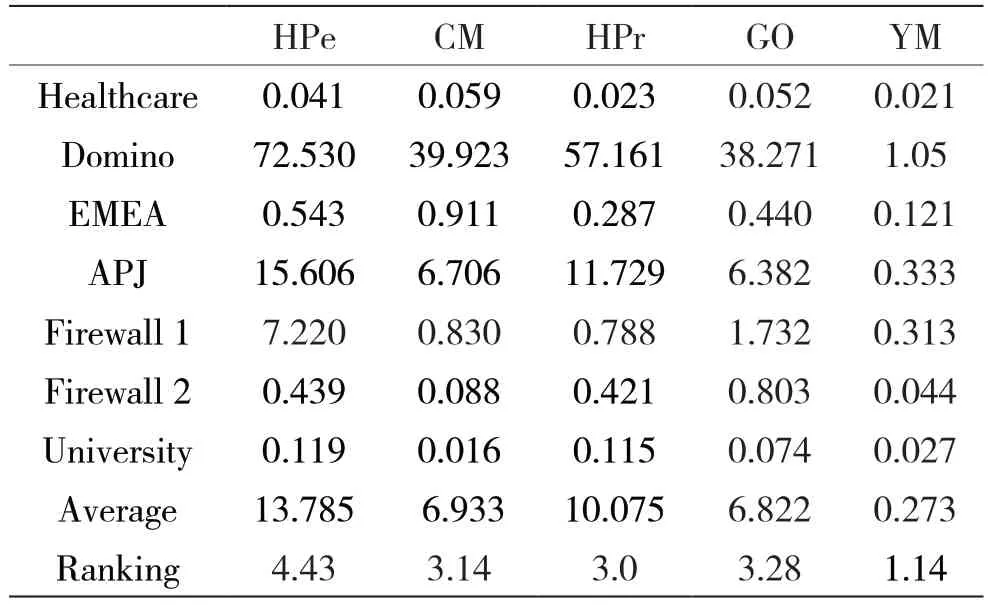
表6 算法运行时间(单位:秒)
总结:表3、表4、表5、表6中给出了YM算法在不同评价指标下在真实数据集上的实验。在产生角色数方面,平均比GO算法少4.3%,比其他算法均有不同幅度的减少;在产生边数方面比GO算法平均低15.9%;在最小化边数和角色数方面,YM算法在小数据集上优于GO算法,但在大数据集上性能欠佳,需进一步分析和改进;在算法运行效率方面,YM算法相比其他算法大幅提升,这也是YM算法将WSC和角色相似度作为优化函数的优点。经过不同算法评价指标下的综合比较,本文设计的YM的综合性能相比GO算法及其他算法均有明显的提升,这为以后YM算法的持续改进和实际应用打下坚实的基础。
4 结语
在本文中,首先介绍了RBAC,之后详细解释了角色挖掘概念,总结了目前角色挖掘算法研究中存在的一些难点。通过介绍GO算法,指出其存在的问题,针对GO算法在设计时存在的缺陷,本文设计了新的算法全局优化函数来改进,并在真实数据集上与其他四种角色挖掘算法进行对比实验,结果说明了本文设计算法的优异性能。由于个人研究能力和时间的限制,仍有一些问题有待后续改进完善,如没有考虑生成角色的精确度,没有考虑角色之间的约束关系等,值得进一步的研究。
