知识图谱在语义信息搜索准确率中的应用*
2020-08-11孙喜民
周 晶 孙喜民 罗 鹏
(国网电子商务有限公司 北京 100039)
1 引言
在传统模式下,搜索引擎都是根据页面相互间的链接关系进行页面分析,但不能表示页面包含的信息内容,因此无法对其中的页面信息进行提取与处理[1~3]。对信息的检索过程也是通过关键词分解与匹配来完成,不能深入理解与处理知识。由于互联网已从原先只包含网页超链接的简单文档万维网转变到了目前含有大量实体关系的数据万维网,从而使当前的互联网搜索引擎无法完全满足查准率、查全率与智能化的要求[4~8]。
智能信息的搜索需以知识理解与逻辑推理作为判断依据,在此基础上对各项检索内容与信息对象进行搜索分析[9]。相对于传统搜索模式,智能信息的搜索可以对搜索过程与相关结果实施智能化处理,并且广泛使用知识图谱与语义网等,可以更加准确、全面地表达出不同信息对象间的语义关系,从而准确理解用户发送的信息检索要求极其需要表达的信息对象含义,这就为搜索引擎创造了语意理解的功能并使其具备一定的推理能力[10~11]。
知识图谱最早是Google创造的一项互联网应用技术,可以进一步优化初始搜索结果,更加精确描述实体概念与属性,并使实体与概念间建立其更加明确的关系。从本质层面上分析,可以将知识图谱视为一个语义网络,是对不同知识集合的关联,是通过连接多种信息对象而构成的一个关系网,可以采用结构化语义来描述真实世界,具备从关系角度对问题进行分析的能力[12~15]。可以利用知识图谱来分析与信息搜索相关的复杂关系,并从语义层上理解用户的真实意图,从而有效提升搜索的效率。
2 知识图谱构建方法
2.1 知识图谱框架
通过设置合理的知识层次与知识概念映射方法,构建得到关于顶层知识本体与领域知识本体的架构。以本体分析工具为基础,集成地球环境知识本体(SWEET)、上层知识通用本体库(SUMO)等,根据地理信息标准规范知识构建得到时空方面的顶层知识本体,由此得到图1所示的地理信息知识本体图谱架构。

图1 面向地理环境应用领域的知识图谱框架图
2.2 基于RDF的信息资源
选择关于地理环境知识的图谱架构作为分析依据,利用分词、搜索引擎Lucene、语义框架Jena多种工具,建立多结构信息资源的语义标注、注册与索引。
以定制化方式对应用领域的各项数据信息进行搜集,之后采用半自动方法标注数据资源的信息,再自动索引数据资源的内容,得到关于资源描述框架(RDF)的语义信息。
2.3 语义信息存储管理
RDF都是使用开放的三元组结构,可以实现灵活扩展,并不太适合用于传统关系存储模型,此外还需能够支持数据检索与分析方面的功能。根据以上分析,我们通过列数据库分布式与扩展模型并引入列数据库扩展方法构建得到了语义信息的动态存储方法,可以采用分布式方法来管理所有数据资源,也可以实现语义信息的高效检索过程。
3 语义相似度计算模型
语义相似程度指的是不同概念词间的相互关联性,通常可以根据语义距离与语义相关性来评价语义相似度。计算语义相似度时可以选择的模型包括基于距离、内容或属性的语义相似度模型,得到的计算结果准确度也存在较大区别,主要取决于概念与知识的组织方式与准确性。利用知识图谱构建得到关于概念实例的映射关系以及跨域语义相似度分析模型,以此实现对智能信息的搜索分析。
在建立语义相似度分析模型的时候,需假定下述几项条件并确定计算方法。首先,知识图谱下层结构中的各项概念应比上层结构的概念更加详细与明确,并且概念差异性表现为深度增大而不断变小的情况,二元关系具有比继承关系更远的语义距离。
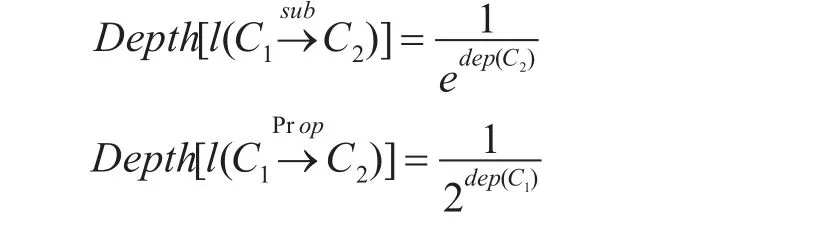
上式中的 dep(C1)和 dep(C2)对应各个不同节点位于知识图谱中的层次。
其次,为知识图谱各部位设置不同的节点稠密度,当细分得到的子节点数量增加后,子节点间语义距离将逐渐减小,同时相似度上升,否则各子节点的抽象性越高,相似性也越低。之后,定义节点。L以及与该节点存在继承关系或二元关系的连接节点c。所具有的密度权重,表示知识图谱包含此类连接。

图2 地理环境应用知识图谱的形态与关系
各节点比如下:

通过结合应用信息量分析方法与知识图谱计算方法,使动态概率估计与固定知识结构相互结合,从而对不同概念的相似性进行客观表达。知识图谱所包含的概念词汇信息取决于该词在文献集里的出现频率。根据D.Lin提出的信息量度量方法可以发现,两个概念词的相似度取决于两者具有共同含义的信息量和总信息量相比所得的结果。知识图谱里的.与c,共同含义指的两者间的共享父节点cn,如下所示:

示该文档所包含的词汇总数,words(c)代表概念。同义词与入口词构成的集合,同时还应专门指出,概念出现于文献集中的概率还要加上文献中这一概念子类的出现概率。由此可以得到:
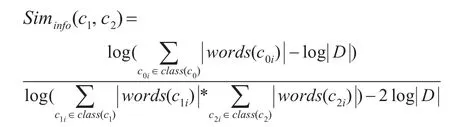
根据知识图谱对语义与搜索对象的信息相似度分析方法,除了需要考虑知识图谱的属性、层次位置、定义密度各项信息以外,同时还要结合数据集的自身特征,对实际客观原貌进行模拟分析,采用并行训一算架构可以完成分解任务的过程,促进训一算效率的显著提升。
4 搜索准确率分析
从“国家地理网”与“中国台湾网”等多个网站上分别收集了约1000篇关于地理信息的文档进行测试,同时保留未做标记的文本资料,其中每篇文档含有的字数平均为2000左右,通过分词处理后得到约1600个,根据给出的智能信息搜索方法,分别从查准率与查全率两个方面比较了信息搜索准确率的情况,具体见图3。
采用普通智能搜索方法,关于B的概念可以扩展查询到包括上位概念与子概念的所有文档,并且在上位概念文档中还可以发现存在和B没有关联性的文档,查询到兄弟节点F与G对应的各个文档,将会引起搜索漂移的现象,由此导致查准率下降的现象。选择图3的信息内容作为研究例子,可以看到查询结果产生了B,通过检索得到文档概念集合是{B,C,D,E,A,F,G},之后计算出查准率是(100^5)/(10^6+30)=56%,查全率是(100^5)/(10^6)=83%。
采用的智能搜索模型是在添加用户反馈的条件下,将查询信息输入后再进行语义分析,使领域关键字B被映射至本体概念,再扩展查询所得结果,因为子节点属于父节点概念细化的结果,所以可以进行准确的子节点扩展查询。以父节点实施扩展时,得到的文档中有部分和B兄弟节点存在关系,所以可以采用扩展算法的兄弟概念和文档建立匹配关系,并从返回结果数据中剔除关于F与G的条口;之后再扩展得到B的紧密属性,根据索引策略可知匹配得到的文档中没有形成B,但形成了关于B的密切文档,所以可能和B存在较大的关联。结合图3给出的信息可以发现,查询结果中存在B,未将其添加到新型智能搜索引擎中时,可以检索得到如下的文档概念集合{B,C,D,E,A},由此得到查准率是600/(400+100+200)=86%,查全率是600/600=100%。因此,分别选择原型智能搜索系统和Lu-Gene全文检索系统实施测试,得到图4所示的实验测试结果。
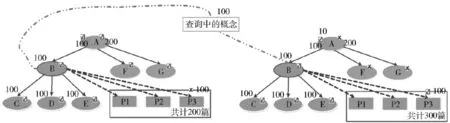
图3 信息搜索准确率提升对比示意图
用户在开展实际应用的过程中所关注的内容通常表现出明显的相似性,因此智能搜索系统可以根据这些用户提供的反馈信息对各项需求内容进行记录与分析,也可以进行多次反馈迭代,使系统搜索查准率获得显著提升。

图4 搜索准确率对比图
5 结语
1)通过设置合理的知识层次与知识概念映射方法,构建得到关于顶层知识本体与领域知识本体的架构。并结合应用信息量分析方法与知识图谱计算方法,使动态概率估计与固定知识结构相互结合,对不同概念的相似性进行客观表达。
2)从“国家地理网”与“中国台湾网”等多个网站上分别收集了约1000篇关于地理信息的文档进行测试,得到查询结果中存在B,得到查准率86%,查全率100%。用户在开展实际应用的过程中所关注的内容通常表现出明显的相似性,可以进行多次反馈迭代,使系统搜索查准率获得显著提升。
