基于FastText和WKNN融合模型的警情智能下发
2020-08-07侯位昭齐幸辉宋凯磊韩志卓司佳刘勇
侯位昭 齐幸辉 宋凯磊 韩志卓 司佳 刘勇
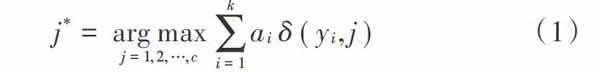

摘 要: 警情的下发效率直接关系到公安民警的出警质量,从而影响公安机关驾驭治安局势的能力和水平。在以往的警情下发中,一般只考虑地址位置的经纬度信息,这就导致在管辖范围界限模糊、经纬度定位不准确时,仍需手动下发警情,容易造成人力、物力的损失以及区域安全指数的降低。为了解决这个问题,文中创新性地将区域划分问题转化为分类问题,并综合考虑经纬度地理编码信息以及中文地名语义信息,提出基于FastText和WKNN的融合地址位置和文本相似性的警情自动下发方法。该方法融合了由FastText得到的地址词向量和根据地址解析服务得到的经纬度信息,将二者组成的地址多元要素作为加权KNN(WKNN)模型的输入来训练分类器。同时,WKNN采用sigmoid函数自适应地权衡在不同经纬度解析精度下地址位置坐标与词向量相似性的权重,提高了模型的鲁棒性。以某市历史警情下发数据为依托,实验结果显示警情下发准确率在91%以上,验证了该模型在某市经纬度不准确、新地址冷启动等警情下发场景中的有效性及高效性。
关键词: 警情自动下发; 融合模型; 信息融合; 权重权衡; 分类器训练; 模型验证
中图分类号: TN911.1?34; TP181; TP391 文献标识码: A 文章编号: 1004?373X(2020)13?0073?08
Intelligent police alarm issuing based on FastText and WKNN fusion model
HOU Weizhao1, QI Xinghui1, SONG Kailei1, HAN Zhizhuo1, SI Jia1, LIU Yong2
(1. The 54th Research Institute, China Electronics Technology Group Corporation, Shijiazhuang 050081, China;
2. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China)
Abstract: The issuing efficiency of the police alarm is directly related to the response effect of public security police, which accordingly influence the ability and level of the public security organs to control the security situation. In the past police alarm issuing, only the latitude and longitude information of an address location has been taken into account. Therefore, it has led to manual police alarm issuing when jurisdiction boundaries are obscure, and latitude and longitude positioning is inaccurate, which is prone to cause the loss of manpower and material resources, and the reduction of regional safety index. In view of the above, the regional division pattern is innovatively transformed into the classification one. In addition, the latitude and longitude geocoding information and the semantic information of Chinese geographical names are taken into account comprehensively, and the FastText and WKNN (weighted K?nearest neighbor) based automatic police alarm issuing method is proposed, which fuses the address word vector got by FastText and the latitude and longitude information got by address resolution service. The address multivariate elements formed by the two are used as the input of weighted KNN (WKNN) model to train the classifier. At the same time, the WKNN with sigmoid function is used to adaptively weigh the weights of address location coordinates and the word vector similarity at different latitude and longitude resolution accuracy, which improves the robustness of the model. The experimental results (which take the historical data of police alarm issuing of a certain city as an example) show that the accuracy of the police alarm issuing is higher than 91%. It verifies the validity and efficiency of the model in situations of inaccurate longitude and latitude and cold start of new address.
Keywords: automatic police alarm issuing; fusion model; signal fusion; weight balance; classifier training; model verification
0 引 言
随着人工智能时代的到来,如何探索一种准确而实用的警情自动下发机制,缩短警情出现到出警的时间周期,提高公安民警的出警质量和效率[1],成为公安行业内亟待解决的问题。
文献[2]设计出智能警情自动识别群发系统,将接收到的警情信息经过字符识别、自动寻址处理后,群发到各治安卡口、对应案发辖区派出所和流动巡逻警力。但是在某市的警情下发过程中,缺乏“派出所管辖范围”的基础数据,同时,某些地区地理信息系统不完善,存在地名不规范、经纬度定位不准确等问题。因此,上述算法并不适用于某市的警情下发场景。在某市的警情下发场景中,实现警情自动下发的前提是实现管辖区域范围的自动划分及解决中文地名相似性度量的问题。
近年来,区域划分问题被越来越多的学者所关注。文献[3]提出了城市功能区划分的聚类算法,通过该算法得到的凸包存在重合交叉的情况,仍需要在凸包功能区的基础上进行人工删除或融合功能区。文献[4]提出了通过计算重心点距与最远点距的大小进行边界提取,然而这种算法对于曲率变化较大的点云效果不佳。
文献[5]将基于边长比约束的边界追踪算法应用于离散点数据区域的边界提取,对边界进一步细化内缩,获取更准确的边界。此外,文献[6]采用基于堆栈的回溯机制实现对参考点边界的搜索。然而上述算法计算复杂度较高,不满足海量数据的实时响应。
综上,鉴于某市派出所管辖范围边界不规则,包含离群点等特点,本文创新性地将区域划分问题转化为分类问题,综合考虑经纬度地理编码信息以及中文地名语义信息,提出基于FastText和WKNN的融合地址位置和文本相似性的警情自动下发方法。该方法融合了由FastText得到的地址词向量和根据地址解析服务得到的经纬度信息,将二者组成的地址多元要素作为加权KNN模型的输入来训练分类器。
当新警情到达,首先根据警情中文地址信息调用百度地图API获取地址经纬度、置信度信息,并根据置信度自适应设置经纬度相似性与中文地址文本语义相似性的权重;同时,借助jieba分词将中文地址切分,并查询基于FastText分类器训练出的词向量库,得到地址的向量化表示;然后将所得的经纬度、置信度、中文地址词向量输入WKNN区域划分算法,得到派出所ID,并最终下发给对应派出所。
采用凸包算法作为对比实验,以某市历史警情下发数据为依托,实验结果显示派出所的管辖范围的凸包图交叉重叠的现象严重,并且效果受异常离群点的影响较大,而FastText?WKNN算法绘制的区域无交叉,能够较好地处理离群点,且对新地址具有一定的发现能力,警情下发准确率在91%以上,能够实现警情的精准自动下发。
1 相关工作
1.1 加权KNN(WKNN)相关工作
文献[7]针对训练样本的不规则性,分析了相似度权重的KNN 算法,并将该算法应用于网络舆情的识别实验中,实验结果表明:KNN 算法用相似度作为权重,充分考虑了相似度属性对分类结果的影响,能够有效提高舆情识别质量。文献[8]针对KNN算法精度受[k]值选取影响较大的问题,提出了一种使用BP神经网络来优化KNN算法的改进算法,降低[k]值选取对算法精度的影响,同时提高分类准确率。另外,文献[9]提出了利用属性值对类别的重要性进行改进的KNN算法(FCD?KNN),定义两个样本间的距离为属性值的相关距离,此距离有效度量了样本间的相似度。
理论分析及仿真实验结果表明,FCD?KNN算法较传统KNN及距离加权?KNN的分类准确性要高。
本文在上述研究的基础上,采用WKNN区域划分算法归纳历史下发数据的隐含规律。WKNN算法适用于处理类域交叉或重叠较多的大数据分类问题[10],在边界凹陷程度较大的区域,能更精确地描绘出原始模型的轮廓,同时,对离群点具有较强的抗干扰性[11]。
1.2 FastText相關工作
在文本处理领域,文献[12]提出利用编辑距离度量中文地名文本相似性,同时,借助形近字库解决错别字问题。但是该相似性的度量未考虑语义相似性,同时依赖于分词的准确性,不适用于某市地名不规范的场景。另一种思路为借助词袋模型或向量空间模型[13],将词向量化,但是词袋模型仅考虑了词频等统计信息,同样不能考虑上下文语义,并且维度过高。
近年来词向量被越来越多学者关注[14?16],通过训练语言模型得到词向量,使得词向量的相似性能够表示词语语义的相似性,例如,Mikolov等人提出word2vec[17],它通过训练神经网络语言模型,将词转化成词向量,文本内容的处理便转化为向量空间中的向量运算。通过向量空间上的相似度表示文本语义上的相似度。
与word2vec类似的FastText技术目前已经有效地应用于英文标签预测和情感分析中[18],FastText获得的性能与基于深度学习的方法接近,而且速度更快,无论是训练速度还是测试速度,FastText模型比深度学习模型快几百倍,将训练时间由数天缩短到几分钟[19]。另外,FastText与word2vec的本质区别体现在h?softmax的使用上。word2vec模型最终得到词向量是在输入层得到,输出层对应的h?softmax产生的向量最终都被抛弃。 FastText则充分利用了h?softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者[N]个)[20]。
文献[21]从视频监控防控目标的角度出发,把对视频监控系统防控目标分类的问题转化为短文本分类问题,并采用FastText模型实现了对北京市一类视频监控系统防控目标的详细分类。视频监控系统防控目标的分类问题主要是通过防控目标的名称进行区分。实验结果显示分类具有较高的准确性,且效率较高。在本研究中,考虑到警情自动下发情景可转换为中文短文本分类问题,本文利用FastText文本分类算法[22]得到某市警情下发领域中文地址词向量库,利用地址词向量库度量中文地名语义相似性,降低经纬度信息不准确造成的负面影响,提高模型预测精度。FastText算法适用于大型数据,具有高效的训练速度,能使训练模型在使用标准多核CPU的情况下10 min内处理超过10亿个词汇[23],这满足了警情自动下发中对高时效性的要求。
2 基本原理
2.1 基于经纬度信息的WKNN区域划分算法
在传统的KNN算法中,测试数据的[k]邻居是等权的,然而在实际中,各个[k]近邻对测试标签的贡献显然不同,而这种贡献往往与距离有关。加权KNN算法准则如下[24]:
式中:[c]表示类别个数;[j]表示样本标签;[ai]为[k]邻近样本[(x0i,y0i)]的权重;[δ(m,n)]为指示函数,当且仅当[m=n]时值为1,否则为0。
令[di]表示待预测点到最邻近的[k]个点中第[i]个样本点的距离,则基于距离的加权KNN(WKNN)算法的权重如下所示:
理论上地址经纬度信息能唯一表征某地址,但通过实验分析,单纯依赖地址经纬度信息的WKNN区域划分算法,在某些区域预测精度极度下降,这是由于在该区域经纬度坐标点对应的真实值的基准参考值存在误差,为警情精准下发埋下隐患。因此,本文在地址经纬度编码信息的基础上,引入中文文本相似性,用于挖掘警情推送中文地名特征规律。本文采用FastText文本分类模型获取词向量,以此度量中文地名的语义相似性。一种很自然的算法是尝试直接利用FastText分类模型实现地址自动下发。
2.2 FastText文本分类算法
为降低经纬度解析误差对警情下发精度的负面影响,本文在地址经纬度编码信息的基础上,引入中文文本语义信息。采用FastText文本分类模型获取词向量,用词向量度量中文地名的语义相似性。
针对[N]个文本分类问题,FastText算法以文本[n?gram]特征为额外输入特征,用于保持词序信息;使用softmax函数计算各类的概率分布,并最小化负对数似然函数,公式如下[25]:
式中:[xn]包含词袋特征与[n?gram]特征;[yn]为文本类别标签;[A]和[B]为权重矩阵。
用[m]表示类别个数,[d]为文本表示的特征维度,传统线性分类器的计算复杂度为[O(md)]。FastText使用基于Huffman树的层级softmax,将树的每个节点与根节点到该节点的概率关联。若某节点位于[l+1]层,其父节点为[nl,…,n2,n1],则与之关联的概率如下:
同时,借助层级softmax,FastText将计算复杂度降为[O(dlog2m)]。
在警情推送场景中,中文地名的“近义”特指空间位置、行政区划级别、从属派出所的相似度,如同一派出所管辖的地址[a1]和地址[a2]被视为相近词,从属于同一个乡的村被视为相近词。
FastText分类模型的训练过程如图1所示,由此可得警情自动下发领域的中文地址词向量库。但是FastText专注于文本分类,依赖于历史下发数据的丰富度,当新到地址与历史库中已下发地址描述差异较大时,下发精度将显著降低。
因此,本文提出基于自适应权重的WKNN算法,综合考虑地址坐标相似性与中文地址语义相似性,构建派出所管辖范围,同时解决经纬度不准确、地址冷启动等问题。
2.3 自适应FastText?WKNN算法
相似性的度量对WKNN分类精度至关重要。本文为减少真实数据的不可靠性对预测的影响,提出融合地址位置信息和文本信息的自适应相似性度量准则,并采用基于sigmoid函数的自适应权值[w]:
式中:[α]为百度地图接口返回的参数“地址理解度”,用于度量地址编码解析服务的准确度,分值越大,地理编码服务对地址理解程度越高。在[α≥90]时,解析误差100 m内概率为89%,误差500 m内概率为96%,当[α>90]时,认为百度地图接口返回的经纬度较为精确,此时,地理坐标相似性占有的权重较大,[w>0.5];相反,[α≤90]时,认为百度地图接口返回的经纬度存在误差,此时,中文地名相似性占有的权重较大,此时,[w<0.5]。基于上述非线性权重,可得到综合考虑地理坐标相似性、中文地名相似性自适应权重度量准则:
式中:[LSim]表示位置坐标相似性,用于度量地址经纬度编码信息的差异;[TSim]表示文本相似性。
基于FastText构建的词向量用于度量中文地址语义相似性。显然,位置坐标相似性的权重随着地址经纬度解析精度的增大而增大,进而提高模型的鲁棒性。
值得注意的是,自适应FastText?WKNN基于自适应相似性[AdaSim]获得最邻近的[k]个邻居,并参考基于距离的WKNN对近邻使用如下加权准则:
WKNN是一种基于懒惰学习实例的算法,没有离线训练阶段。本文使用[D]和[T]分别代表训练样本库和测试样本库的大小。完成[d0]与训练样本库中的所有样本的相似性计算需要[O(DV)],相似性的排序需要[O(Dlog D)]。因此,总运行时间为[O(T(Dlog D+DV))]。
3 某市警情自动下发的FastText?WKNN模型的设计与实现
3.1 某市警情自动下发模型
本文为减少经纬度误差对警情推送精度造成的负面影响,提高模型对新地址的预测能力,综合基于文本语义相似性的FastText分类算法与WKNN区域划分算法,从而构建警情自动下发的自适应混合模型。
警情自动下发算法流程如下所示:当新警情到达,首先根据警情中文地址信息调用百度地图API获取地址经纬度、置信度信息,并根据置信度自适应设置经纬度相似性与中文地址文本语义相似性的权重;同时,借助jieba分词将中文地址切分,并查询基于FastText分类器训练出的词向量库,得到地址的向量化表示;然后将所得的经纬度、置信度、中文地址词向量输入WKNN区域划分算法,得到分类结果,在这里将派出所ID作为标签,最终根据分类结果下发给对应派出所即可。
算法1:融合地理位置和文本相似性的FastText?WKNN算法
Input:a training set D of size m*1
Its label set L of size m*1
a test set to be predicted T of size n*1
parameter: n?gram,echo,l,k
Output: FastText_WKNN model
Function_FastText_WKNN (L,D,T, n?gram,echo,l,k):
Preprocessing of D,L and T;
Empty set Lnglat,Fasttext, W
for address in D:
Get_lnglat(address,ak)→(lng,lat)
Get_comprehension(address,ak) →
Get_jieba(address) →S={a,b,c…}
Get_FastText(S,n?gram,echo) →Q={q,w,e…}
Get_weight( ,sigmoid) →w
Lnglat.append((lng,lat))
Fasttext.append(Q)
W.append(w)
Get? WKNN_Model(Lnglat,FastText,W,L,k)
Sent T to WKNN_Model
for each state i ∈{1,2,…,n}
Output the classification of T(i) →r
Results.append(r)
Get_ accuracy(Results) →accuracy
If accuracy>0.9:
//模型訓练完成
return FastText_WKNN_Model
else:
adjust n?gram,echo,l,k
Function_FastText_WKNN (L,D,T,n?gram,echo,l,k)
3.2 数据预处理
首先通过数据预处理解决原始数据中的异常点、不一致等问题。
在选择数据时,针对经纬度误差造成的异常点问题,当“地址理解度”低于给定阈值时,说明该点为异常点,则将其删除。
对于历史记录中相同地址警情下发到不同派出所的不一致情况,本文选择时间最新的为基准,即此时仅保留最新的下发结果。
此外,构建某市专有地名字典库,同时,利用jieba分词对地址数据切分,转换为FastText所要求的数据格式。
3.3 模型参数选择
在实验中,首先获得中文地址名的经纬度,同时使用FastText获取地址名的词向量。将经纬度和词向量作为WKNN模型的输入,地址的从属派出所ID为类别标签,训练WKNN模型。
使用百度的地理编码服务获得中文地址的经纬度,地址结构越完整,地址内容越准确,解析的坐标精度越高。该服务返回结果参数如表1所示。
在这里使用comprehension字段作为地址解析结果准确与否的判断标准。当解析误差较大时,经纬度这一特征的有效性降低,甚至可能会带来噪音。因此,当comprehension字段的值较低时,降低经纬度这一特征的权重,同时提高词向量特征的权重。在实验中根据式(6)自适应设置权值。
在FastText算法训练得到的中文地址词向量库中查询得到的词向量作为后续WKNN模型输入的一部分。在FastText分类器训练中,学习率[lr]、传递完整数据集的次数[echo]和词序列窗口大小[n?gram]等参数对模型性能有很大影响。虽然[n?gram]值越大,模型越能表示词顺序信息,但是同时会降低模型训练效率。本文权衡耗时与精度,选择合适的[n?gram]值,同时,采用5折交叉验证算法选取合适[lr]与[echo]值。
使用经纬度及词向量多元特征来训练WKNN模型,在模型训练过程中,[k]值的选取十分重要。若[k]值较大,可以减少学习的估计误差,但是学习的近似误差会增大,致使与输入实例较远的训练实例也会对预测产生影响,使预测产生错误,并且[k]值增大模型的复杂度会下降。此外,[k]越小,分类边界越是非线性,越是灵活,但也越容易过拟合,同时,学习的估计误差会增大,预测结果对近邻的实例点较敏感。本文采用5折交叉验证算法选取合适的[k]值。
另外,在WKNN模型中,如果一个样本最接近的[k]个邻居里,绝大多数属于某个类别,则该样本也属于这个类别。指定投票权重类型为“distance”,即本节点所有邻居节点的投票权重与距离成反比,越近的距离权重越高,在一定程度上避免了样本分布不平均的问题,减少了噪音污染的影响。
4 实验结果
本节以某市警情自动下发为例,通过与基于凸包算法模型、基于文本语义相似性的FastText模型和依赖经纬度的WKNN模型进行推送精度与效率对比,验证了本文提出的FastText?WKNN模型具有较高的有效性和高效性。
4.1 实验数据及实验环境
本文选取某市9万条警情下发历史数据,原始数据属性包括警情ID、警情地址及下发派出所编号ID。
实验环境及功能说明如表2所示。
4.2 实验结果
在实验中,通过调用百度地图API获取历史警情地址的经纬度信息,分别采用凸包及WKNN算法构建各个派出所的管辖范围。
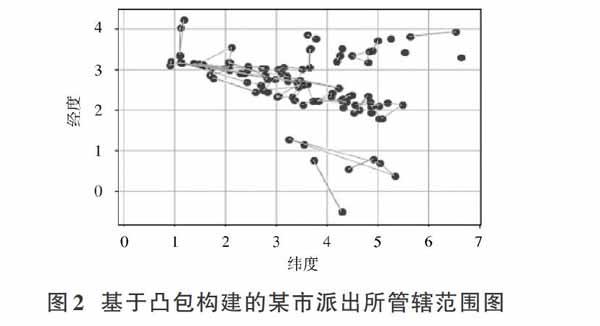
首先,通过Graham扫描法构建凸包,所建立的社区边界示意图如图2所示,横坐标为纬度,纵坐标为经度。
从图2中可以看出,派出所的管辖范围的凸包图交叉重叠的现象严重,并且效果受异常离群点的影响较大。
此外,调用Python scikit?learn机器学习库中的KNN算法实现基于WKNN的区域划分。在实验中,采用交叉验证算法选出误差率最小的模型,其对应的[k]值为3。
基于WKNN的区域划分效果示意图如图3所示,横坐标为标准化的警情地址纬度值,纵坐标为标准化的警情地址经度值。
图3表示历史警情所下发的不同派出所编号,不同颜色区域表示不同派出所的管辖范围。可以看出,WKNN算法绘制的区域无交叉,能够较好地处理离群点。
模型依赖的经纬度和地址解析的精确性决定了模型的性能,因此为了提高模型的性能,本文引入基于文本相似性的FastText模型,在实验中发现[n?gram]值取1时达到最佳性能。但文本相似性的计算过于依赖历史数据库,当一条地址为全新的地址时,FastText模型的效果较差。
为克服以上算法的局限性,提出融合地理位置和文本相似性的FastText?WKNN模型,并使用交叉验证算法对比实验来验证模型效果。
本节将某市的数据按照不同县划分为8个数据集,分别为A,B,C,D,E,F,G和H,其中E,F,G和H为热点区域,各个区域的总数据如表3所示。
对每个数据集按照9∶1随机划分为训练集与测试集,各区域警情推送精度及时间如表4所示。
不同区域地址理解程度如表5所示。地址理解程度与WKNN模型准确率的关系如图4所示。
由图4可知:二者在热点区域E,F,G,H 4个区域的经纬度解析准确率都较高,且两者精度相近;在非热点区域A,B,C,D 4个区域FastText?WKNN模型的精度明显高于依赖于经纬度的WKNN模型。这是由于在热点区域通过百度地图API获得的经纬度较为准确,而在非热点区域经纬度定位存在较大的误差,从而导致下发准确率低。此外,FastText分类器的计算效率高于WKNN模型,这是由于对于多分类标签(如派出所组织ID)众多的场景,FastText利用层级softmaxt,显著降低计算复杂度,表明FastText对中文文本分类具有较好的适用性。
同时,为了比较模型对于新地址的预测能力。以E区域为例,调整测试集与训练集的比例进行测试,其中测试数据占比越大,说明新地址越多,实验结果如图5所示。
由图5可以看出,随着测试数据占比的增大,基于文本语义相似性的FastText分类预测精度显著降低,而WKNN区域划分算法预测精度仅略微下降。这是由于FastText分类模型依赖于历史下发数据的丰富度,当新到地址与历史库中下发过的地址描述差异较大时,下发精度将明显降低。而所提FastText?WKNN模型克服了这一弊端,对历史数据库的依赖度大幅度降低,不论是在热点区域还是非热点区域,下发准确率都能达到90%以上。在训练集占比0.2和测试集占比0.8的情况下,对新地址依然保持较高的发现能力。实验结果证明,在警情下发业务情境下,本文提出的FastText?WKNN模型能获得较好的实验结果。
综上所述,单独一种基于文本语义相似性的FastText分类模型或WKNN区域划分模型都不能同时适用于非热点区域经纬度不准确、新地址冷启动等警情下发场景。针对上述不足,本文提出基于地址多元要素的FastText?WKNN模型,该模型集成WKNN模型对新地址的预测能力,同时,引入FastText的分词能力,将地址词向量作为地址多元要素的一部分输入到模型中,通过这种方式减小在非热点区域经纬度误差造成的负面影响,从而能够实现警情的精准自动下发。
5 结 语
本文提出基于FastText和WKNN的融合地理位置和文本相似性的警情自动下发模型,采用sigmoid函数权衡地址位置坐标及中文地址文本语义相似性的权重,提高模型的鲁棒性,并通过实验验证该混合模型在某市经纬度不准确、新地址冷启动等警情下发场景具有有效性及高效性。
未来将综合警员经验、警情类别、交通状况等多种因素,实现融合泛在态势的警情精准推送,实现在节省手工下发人力的同时,合理分配任务,提高警员任务完成率。
注:本文通讯作者为宋凯磊。
参考文献
[1] 吴泉源,张宁玉.4S技术与公安预警信息系统[J].遥感技术与应用,2000,15(4):232?236.
[2] 王锐,陈里,彭功民,等.智能警情自动识别群发系统:CN103456147A[P].2013?12?18.
[3] 窦智.城市功能区划分空间聚类算法研究[D].成都:四川师范大学,2010.
[4] 刘立强.散乱点云数据处理相关算法的研究[D].西安:西北大学,2010.
[5] 黄先锋,程晓光,张帆,等.基于边长比约束的离散点准确边界追踪算法[J].武汉大学学报(信息科学版),2009,34(6):688?691.
[6] 吳怀军,孙家广.基于回溯的参考点边界搜索算法[J].计算机研究与发展,1998,35(6):562?566.
[7] 郑伟,王若怡,马林,等.KNN算法在舆情领域中的应用研究[J].中国管理信息化,2019,22(6):157?158.
[8] 路敦利,宁芊,臧军.基于BP神经网络决策的KNN改进算法[J].计算机应用,2017,37(z2):65?67.
[9] 肖辉辉,段艳明.基于属性值相关距离的KNN算法的改进研究[J].计算机科学,2013,40(11A):157?159.
[10] 耿丽娟,李星毅.用于大数据分类的KNN算法研究[J].计算机应用研究,2014,31(5):1342?1344.
[11] GOLENBIEWSKI J, TEWOLDE G. Implementation of an indoor positioning system using the WKNN algorithm [C]// 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC). Las Vegas, NV, USA: IEEE, 2019: 397?400.
[12] 向雯婷,郭旦怀.基于地名相似度算法与空间场景相似性评价的地址规范化研究[J].科研信息化技术与应用,2013,4(1):67?73.
[13] 李静,林鸿飞,李瑞敏.基于情感向量空间模型的歌曲情感标签预测模型[J].中文信息学报,2012,26(6):45?50.
[14] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [EB/OL]. [2015?11?28]. http://www.doc88.com/p?9925363440847.html.
[15] COLLOBERT R, WESTON J. A unified architecture for natural language processing: deep neural networks with multitask learning [C]// Proceedings of the 25th International Con?ference on Machine Learning. [S.l.]: ACM, 2008: 160?167.
[16] MNIH A, HINTON G. A scalable hierarchical distributed language model [EB/OL]. [2016?01?25]. http://www.doc88.com/p?7038917089758.html.
[17] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [EB/OL]. [2015?11?09]. https://wenku.baidu.com/view/36ffa6ac76c66137ee? 0619aa.html.
[18] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification [C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain: Association for Computational Linguistics, 2017: 427?431.
[19] ALESSA A, FAEZIPOUR M, ALHASSAN Z. Text classification of flu?related tweets using FastText with sentiment and keyword features [C]// 2018 IEEE International Conference on Healthcare Informatics (ICHI). New York, NY: IEEE, 2018: 366?367.
[20] LJUBE?I? N. Comparing CRF and LSTM performance on the task of morphosyntactic tagging of non?standard varieties of South Slavic languages [C]// Proceedings of the Fifth Workshop on NLP for Similar Languages, Varieties and Dialects. New Mexico, USA: Association for Computational Linguistics, 2018: 156?163.
[21] 王艺杰.基于Fasttext的防控目标分类实现[J].中国公共安全(学术版),2018(1):29?32.
[22] BOJANOWSKI P, GRAVE E, JOULIN A, et al. Enriching word vectors with subword information [J]. Transactions of the association for computational linguistics, 2017, 5: 135?146.
[23] JOULIN A, GRAVE E, BOJANOWSKI P, et al. Bag of tricks for efficient text classification [C]// Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics. Valencia, Spain: IEEE, 2017: 427?431.
[24] BENSAFI N, LAZRI M, AMEUR S. Novel WkNN?based technique to improve instantaneous rainfall estimation over the north of Algeria using the multispectral MSG SEVIRI imagery [J]. Journal of Atmospheric and Solar?Terrestrial Physics, 2019, 183: 110?119.
[25] BALODIS K, DEKSNE D. FastText?based intent detection for inflected languages [J]. Information (Switzerland), 2019, 10(5): 161.
