基于聚类算法的高速连续数据流 并行处理控制系统设计
2020-08-07刘敏黄维兰诗梅
刘敏 黄维 兰诗梅

摘 要: 传统的高速连续数据流并行处理控制系统运行过程中相对误差大,消耗内存高,为了解决这一问题,基于聚类算法设计了一种新的高速连续数据流并行处理控制系統。所提出的系统由功能层、数据源、接口层、数据层、资源层、应用层组成系统硬件结构,通过数据的获取、预处理、聚类处理和类别预测四步完成软件流程,软件在运行过程中需要应用聚类算法。为检验控制系统效果,与传统控制系统进行实验对比,结果表明,基于聚类算法设计的高速连续数据流并行处理控制系统在运行过程中相对误差极小,占用的内存少,系统运行效率高,并行处理控制效果好。
关键词: 控制系统设计; 聚类算法; 数据流并行处理; 聚类分析; 参数设置; 对比实验
中图分类号: TN876?34; TP301 文献标识码: A 文章编号: 1004?373X(2020)13?0114?05
Design of clustering algorithm based parallel processing control system
for high?speed continuous data stream
LIU Min1, HUANG Wei2, LAN Shimei1
(1. College of Mathematics and Information Science, Guiyang University, Guiyang 550005, China;
2. Guizhou Provincial Water Conservancy Research Institute, Guiyang 550001, China)
Abstract: The traditional parallel processing control system for high?speed continuous data stream has large relative error and high memory consumption. In order to solve this problem, a new parallel processing control system for high?speed continuous data stream is designed based on clustering algorithm. The hardware structure of the proposed system is composed of function layer, data source layer, interface layer, data layer, resource layer and application layer. The software flow is completed in four steps: data acquisition, pre?processing, clustering processing and classification prediction. The software needs to apply clustering algorithm in the running process. In order to test the effect of the control system, it was compared with the traditional control system in some experiments. The results show that the high?speed continuous data stream parallel processing control system designed on the basis of clustering algorithm has minimal relative error, high operating efficiency and good parallel processing control effect, and occupies less memory.
Keywords: control system design; clustering algorithm; data stream parallel processing; clustering analysis; parameter setting; contrastive experiment
0 引 言
随着互联网技术的迅速发展,给人们生活带来众多便利的同时,也产生了越来越多的数据,这给数据价值的挖掘提出了重大的挑战。聚类算法是一种具有广阔前景的海量数据挖掘工具,然而数据量的剧增也给聚类算法及其对应的处理系统提出了更高的要求,传统单机环境已经难以满足现代数据处理应用的需求。
作为一种高技术、高效率的计算机处理手段,在对数据或网络信息进行采集、处理、分析、调控的过程中,并行处理能够有效缩短延迟时间,提高运算速度,换句话说,就是在各类投入的资源上进行重叠覆盖以提高并行度的方式来实现系统效率的升级。
本文基于聚类算法对高速连续数据流并行处理控制系统硬件和软件框架进行设计,根据设计框架阐述了基于聚类算法的高速连续数据流并行处理控制系统的工作流程。实验结果证明该系统具有对高复杂度数据的计算能力和数据处理的实时性,通过实验验证了该高速连续数据流并行处理控制系统设计的可行性。
1 高速连续数据流并行处理控制系统基本框架设计
与分类算法相比,聚类算法是一种无监督学习,根据样品的相似度,将相似的样本自动归入同一类别中。在数据训练之前并不知道数据会分为几个类簇,同一个簇中的数据对象会保证最大的相似度。如图1所示,按照使用场景和适用类型的不同,聚类算法可以分为使用划分聚类、使用模式聚类、使用层次聚类、使用网格聚类等,不同的聚类算法适用于不同的应用领域。
在并行处理过程中采用多单元同步工作的机制,同时在不同的处理单元中输入数据,在相同的时间内将处理时间成倍缩小,实现系统的快速处理。而处理单元的数量和所执行任务的并行度都会对并行处理控制系统的加速比产生直接的影响,其中,任务的并行度对系统的性能产生制约,而当任务并行度固定的情况下,处理单元的数量越多,加速比越大,直到达到上限。并行处理控制系统涉及到紧耦合技术、直接存储器存取技术、共享存储技术、高效缓存技术等。
面对高速连续数据流,传统的串行处理手段在计算资源和时间约束上具有局限性,难以适应海量数据。如图2所示,将聚类算法应用于高速连续数据流并行处理控制系统中,可增强系统的灵活适应性,对小数据元素和大数据元素集合都保持高效的聚类效果。系统对数值型和非数值型的数据都能处理,具有处理不同数据类型的能力。系统不需要用户输入过多的额外参数,降低了用户使用的负担,并且该系统可以避免因数据输入顺序对结果造成的影响。现有的并行处理控制系统更擅长于低维数据的处理,本文中聚类算法的应用,使系统对高维度的数据仍具有高处理能力。对于噪声数据问题,系统能够较好地甄别,确保结果的质量。
现有的并行处理控制系统对任务进行管理时,通常利用设置分时指标的模式。在系统进入到正常工作模式后,每一个节点都能实现数据的更新处理。数据的更新借助消息点播的形式,消除原始数据并向其他节点发出通知。在并行处理控制系统的实际工作中,一定要保证在数据更新时不会产生信息活锁的情况。
如图3所示,基于聚类算法的高速连续数据流并行处理控制系统主要由数据源、数据层、接口层、资源层、应用层和功能层构成。系统从数据源获取数据信息,通过接口层进行并行数据的导入和导出,在数据层完成数据的预处理和集群协调服务,并进行聚类算法的计算和存储。在功能层完成对系统的流程、安全、任务、集群、元数据的管理和监控。
数据源和接口层中的网络数据爬取构成了网络数据获取模块。聚类模块是将数据源中的输入数据通过接口层传递至数据层中的数据库,转化为数据向量进行归一化,再进行算法分解,建立聚类模型。将输入数据进行簇的评定后,然后进入数据集的应用层,在完成所需功能的同时,对数据进行存储和前台展示。当输入数据异常时,系统会自动进行异常检测,判断系统是否进入故障模式,最大程度上维护系统的正常运行。
2 高速连续数据流并行处理控制系统运行流程设计
并行处理控制系统能够快速、高效地对输入的海量数据进行处理,总体上可以分为数据的获取、预处理、聚类处理和类别预测四步。采集后的数据进入预处理数据阶段后,会对数据中的缺失值进行补充,对数据进行归一化处理。然后利用聚类算法对数据进行分类,最终对未知数据的类别进行预测。
聚类算法会将所有的数据元素划分入簇中,相似度的度量方法有很多种,例如:欧氏距离度量、余弦距离度量、谷本距离度量、皮尔逊相似度度量等,本文采用余弦距离度量的方法进行计算。建立两个[n]维向量[A=(a1,a2,…,an)]和[B=(b1,b2,…,bn)],余弦距离对绝对数值并不敏感,只是在方向上对向量的差别进行区分,由式(1)进行计算得到两个[n]维向量[AB]之间的余弦距离[d]。当[d]为0时,距离最近;而随着[d]的增大距离不断增加。
应用聚类算法的初期是要人为选择聚类中心,初始簇中心的距离要尽量远,具体流程如图4所示。首先在数据集中随机选取一个点作为第一个簇心,将数据集中的每个数据对象[i]根据式(1)计算该数据对象和簇中心的距離[di]。从距离[di]值较大的数据对象[i]中选取一个新的簇心,重复求取数据对象和簇中心的距离[di]和选取新的簇心。当达到设定的[k]个簇心时停止选取,完成数据的聚类分类。
聚类算法分析需要进行评价,聚类的评估通常会分为内部和外部评估两个部分。内部评估指标采用簇内方差和来评估表示使用过程中训练之内的数据,应用式(2)进行计算完成。外部评估采用[F]?measure指标,组合查全率[R]和查准率[P]的基本思想,利用式(3)计算使用训练数据之外的数据。
式(2)中:[E]为平方误差函数;[Xij]表示第[i]个类簇中第[j]个样本,[i]为1~[k]中的第[i]个类簇,[j]为1~[n]中的第[j]个样品;[mi]为第[i]个类簇中的聚类中心;[ni]为第[i]个类簇中的样本数。在式(3)中,[P]为查准率,[R]为查全率,计算求得的[F(i)]为外部评价[F]?measure指标。
当今社会已经被数据包围,将聚类算法应用于高速连续数据流并行处理控制系统,系统具有较高的容错性,能够在部署机器很廉价的状态下进行高速率数据访问,适用于处理高速连续数据流。
如图5所示,本文中基于聚类算法的高速连续数据流并行处理控制系统能够支持达到几百GB的大型文件,系统由数百台以上机器组成,具有高故障率,但是能够快速应对机器故障。系统进行数据访问的形式是管道流,更侧重于数据吞吐量。在系统中一个文件被写入后,会简化为一致性模型,并不能够被修改。系统进行数据访问时需要毫秒级的数据响应,具有实时性。
在进行高速连续数据流的并行查询和处理中,数据分布策略会直接影响系统的运行效率。高速连续数据流并行处理控制系统中各个位置产生的可能性均等,换句话说,由于聚类算法的加入,在对高速连续数据流进行并行处理时,处理任务会平均分配给不同的节点。数据的处理以道集为单位,有助于提高数据流的读写速度。
当系统对一个进程中高速连续数据流中的所有数据信息进行实时记录的同时,还可以进行超时状态查询。超时时间设置可以有效避免整个并行处理控制进程中产生竞争条件。如图6所示,系统聚类分析后进行是否并行处理运行检查,若系统并行处理开启,则设定超时时间为0;若发现未进行并行处理,超时设定开启,设定超时时间为2倍的串行时间2[t],并返回重新进行聚类分析。在系统运行时,并行状态的竞争几率出现较低,设定明显优于串行设定。完成超时设定后,将对系统数据库进行数据处理,这样能够大大缩减系统工作时间,尽可能地提高效率。
3 实验研究
3.1 实验目的
为了检验所提的高速连续数据流并行处理控制系统的有效性,设计如下实验进行验证。设置相关实验参数,对比现有的数据流并行处理控制系统和所提系统,记录下不同系统的相对误差值和系统的运行状态参数,比较系统精密度,根据对比结果分析不同系统的处理控制效果。
3.2 实验参数设置
设置实验参数如表1所示。
3.3 实验方法
根据表1中的参数进行实验,选取现有的数据流并行处理控制系统和所提系统在相同的外界环境下,分别对同一组高速连续数据流进行处理,记录两个系统的测量结果,并分析实验结果。
3.4 实验结果与分析
1) 系统精密度结果
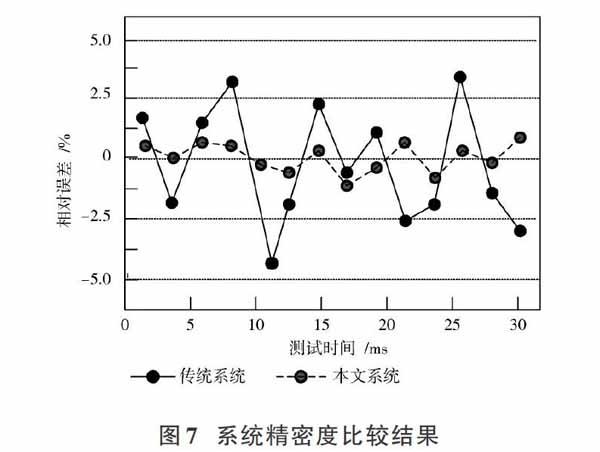
如图7所示,将传统数据流并行处理控制系统和本文基于聚类算法的高速连续数据流并行处理控制系统的相对误差进行计算,进行系统精密度的表征实验。通过观察发现:在30 ms测试时间内,传统数据流并行处理控制系统的相对误差大多分布在-2.5%~2.5%之间,有少量数据大于±2.5%,但全部分布在-5.0%~5.0%之间;在本文基于聚类算法的高速连续数据流并行处理控制系统的相对误差测试中,数据基本都分布在-1.25%~1.25%之间。也就是说,聚类算法的引入降低了高速连续数据流并行处理控制系统的相对误差,提高了系统的精密度和可靠性。
2) 系统的运行状态结果
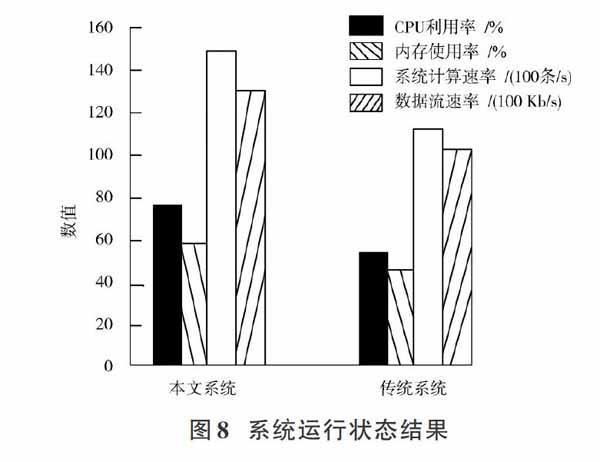
将传统数据流并行处理控制系統和本文基于聚类算法的高速连续数据流并行处理控制系统的运行状态进行统计比较,从CPU利用率、内存使用率、系统的计算速率和数据流速率几个方面进行比较,结果如图8所示。
传统的数据流并行处理控制系统CPU利用率约为55%,内存使用率约为49%,系统的计算速率约为1.1万条/s,数据流速率达1.01×[104] Kb/s。本文基于聚类算法的高速连续数据流并行处理控制系统CPU利用率约为78%,内存使用率约为60%,系统的计算速率约为1.5万条/s,数据流速率达1.3×[104] Kb/s。通过比较发现:本文的高速连续数据流并行处理控制系统的CPU利用率和内存使用率都高于传统数据流并行处理控制系统,能够有效提高系统的利用率,从而提高系统工作效率,并且本文基于聚类算法的高速连续数据流并行处理控制系统所适用的数据流速率高于传统的数据流并行处理控制系统,并且本文系统的计算速率也高于传统系统。总的来说,本文基于聚类算法的高速连续数据流并行处理控制系统的性能优于传统的数据流并行处理控制系统。
3.5 实验结论
传统的数据流并行处理控制系统和本文基于聚类算法的高速连续数据流并行处理控制系统都能够对高速连续数据流进行并行处理,但是与传统的数据流并行处理控制系统相比,本文基于聚类算法的高速连续数据流并行处理控制系统的性能更加优异,能够适应于更高的数据流速率,工作效率和系统精密度更高。
综上所述,本文基于聚类算法建立的高速连续数据流并行处理控制系统的综合性能较优,系统的处理控制效率更高,相对误差很小,因此,精密度更高,数据流速率更快,具有很高的应用优势。
4 结 语
随着互联网技术的不断发展,网络数据的规模和应用范围也在不断扩大,人们应用中的数据信息在范围、规模上都不断扩大,海量数据在时间和空间上十分复杂,聚类算法能够适应于海量高维数据。聚类分析根据对象之间的相似性将数据对象集合进行分簇,保证统计分簇项中的数据尽可能相似。高速连续数据流的数据规模非常庞大,对这类数据的分析是后期数据处理的基础条件,而数据价值需要结合多种技术才能得以实现。聚类数据面对指数式增长,应用并行处理控制系统同时对多个数据分簇项进行处理,提高了对高速连续数据流的处理速度。
本文研究的基于聚类算法建立的高速连续数据流并行处理控制系统具备很高的应用优势,但是该系统缺少更多的实际操作经验,一些潜在问题尚不明朗,这些问题将在未来阶段进行进一步研究和探讨。
参考文献
[1] 莫徽忠.基于数据流聚类算法的网络异常检测系统设计[J].柳州职业技术学院学报,2017,17(3):99?103.
[2] 万新贵,李玲娟,马可.分布式数据流聚类算法及其基于Storm的实现[J].计算机技术与发展,2017,27(7):150?155.
[3] 陈羽中,郭松荣,郭昆,等.基于时态密度特征的改进数据流聚类算法[J].小型微型计算机系统,2018,39(1):64?68.
[4] 张辉,王成龙,王伟.分布式实时日志密度数据流聚类算法及其基于Storm的实现[J].中国新通信,2017(6):71?73.
[5] 魏子衿,肖丽.改进顶点聚类方法的并行核外模型简化算法[J].计算机工程与应用,2018,54(13):181?190.
[6] 米滢.一种基于小波概要的数据流量子聚类算法[J].计算机应用与软件,2017,34(5):288?292.
[7] 何亮亮,王晓东.基于初始信息素和二次挥发的改进蚁群算法[J].西安工程大学学报,2018,32(6):739?744.
[8] 曾志武,蔡明.基于Spark Streaming的增量协同过滤算法[J].软件导刊,2018,17(6):88?91.
[9] 王静,王春梅,智佳,等.面向有效载荷高速数据流的数据处理方法[J].计算机工程与设计,2017,38(4):941?945.
[10] 李莉.基于云计算平台Hadoop的并行k?means聚类算法设计研究[J].网络安全技术与应用,2017(12):46?47.
[11] 骆金维,曾德生,郭雅,等.时序数据并行压缩速率改进技术研究[J].电子设计工程,2018,26(20):98?101.
[12] 李林,鲁才,唐志梁,等.基于数据流聚类策略的GPU码书初始化算法[J].计算机应用研究,2017,34(2):426?430.
[13] 李晓峰.云平台中大数据并行聚类方法优化研究仿真[J].计算机仿真,2016,33(7):327?330.
