基于注意力机制的眼周性别属性识别
2020-07-29何勇
【摘 要】性别属性是生物身份的一个重要信息,对于提升生物身份识别准确性有着重要的意义。眼周是人脸中判别性特征最丰富的区域,包含众多生物特征信息,文章以眼周區域作为识别载体,通过注意力机制加强可见光和近红外光源条件下的眼周特征信息,进而提升眼周属性识别的准确率,达到了较好的识别效果。
【关键词】眼周属性识别;注意力机制;生物特征分类;生物识别
【中图分类号】TP391.41 【文献标识码】A 【文章编号】1674-0688(2020)06-0113-03
0 引言
深度学习的发展促使各种技术爆发出极大的活力,目标检测、目标分割、目标识别等工程开始展露风采。图像识别可以看成模型认识图像内容的能力,让算法学会从图像中获得必要的信息,进而学会认识图像目标,是目标识别的最终目的。深度学习的发展得益于人们发现原有的特征提取方式存在诸多问题,比如特征提取不充分、理解不到位等,这样就无法给分类器一个很好的判别对象,导致识别准确率下降,这也是深度学习出现的必然原因,是一种科技技术的进化。Alex Krizhevsky[1]在分析特征提取方式后,提出以自己名字命名的Alex Net,在这之后的很多研究人员设计的CNN模型都是对Alex Net的变形或改进,识别效果也超出了人眼判断。VGG模型[2]拥有更宽、更深的网络结构,一般包含5组卷积操作,卷积中包含多个3×3大小的卷积,卷积核数目会不断递增,在每两组卷积操作之间采用Max-Pooling降维。
研究人员借助神经网络特征抽取性能良好的优势实现眼周图像中预测性别的任务。Juan Tapia等人[3]首先改进LeNet-5神经网络,然后提取近红外光下的眼周特征,最终得到性别分类结果,分类准确率达到83.00%。Kumar团队[4]研究多种生物特征方式,通过分析可见光和近红外光下的眼周图像,找到最具判别性的特征主要集中在眼球周边,主要有眼角、人眼轮廓和虹膜瞳孔等信息,选择特征提取性能更好的CNN网络强化然眼特征区域,可以有效地提升识别性能。
1 相关研究概述
人在理解图片的时候,会先被对比度明显的区域吸引,这些区域是图片特征聚集处。一张图片常常用R、G、B三通道表示,在经过卷积核处理以后,会生成新的特征分量用于表示图片,这个分量体现了各区域的重要性,表示各区域间的关联程度。
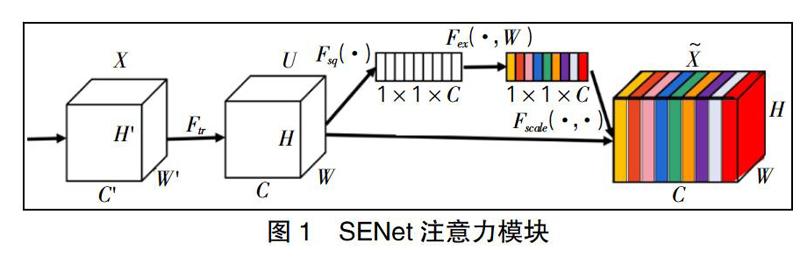
神经网络模型的特征提取能力可以通过改进网络结构得到提升,使用卷积层中的非线性卷积核提取特征,在经过下采样尺寸缩放以后可以捕捉到不同层次的特征表达,无需通过添加更多的监督学习方式进行优化。网络模型架构Inception[5]和VGGNets[6]表明通过加深网络深度可以有效提升特征提取能力,ResNets网络调整网络布局,使用跳跃连接加深各通道间的交流,进而提升深度网络的学习能力和表达效果。注意力模块通过对网络结构进行调整,提出采用注意力机制模块SENet[7]提升网络学习特征的表达。SENet注意力模块如图1所示。
SENet注意力模块将网络前半部提取到的特征进行压缩,将所有通道的特征值做平均池化,输出特征尺寸为1×1×C,接下来需要通过由两个全连接层构成的提取操作建立两个全连接层,分别为实现压缩通道和恢复原始输入通道,将C个通道按比例降低调整,然后扩充到原始输入通道数,Sigmoid最重要的特征是可以将特征值控制在[0,1]之间,通过学习训练获得了一组单维度向量,这个向量可以反映提取出的各区域特征的重要程度,向量维度和通道数一致,可以将这组向量和图像的通道相乘,激活其中对目标识别有益的通道。
2 基于注意力机制的眼周属性识别方法
基于通道域和空间域的注意力机制模型,是已经被证明能有效应对各种计算机识别任务的有效手段,但是生物特征识别是一种特殊的识别方式,对网络结构的简单调整,并不能应对所有的干扰,必须对生物图像有较深的了解,才能更好地发挥网络的作用。眼周图像拥有最复杂的特征区域,在多数情况下容易受干扰,通过分析眼周生物图像发现,人眼生物特征在多数光源和外界干扰条件下能保持稳定特征。
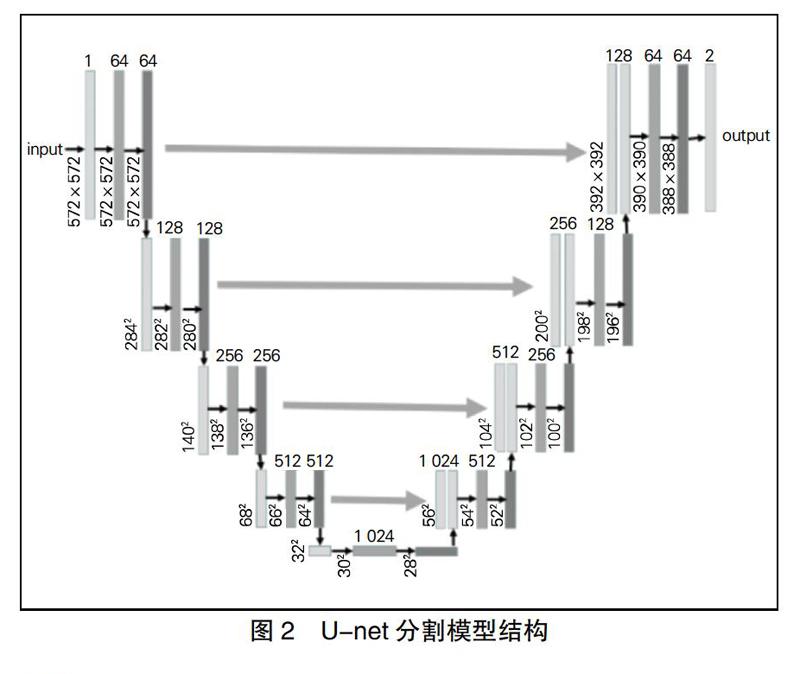
在之前研究人员的研究基础上展开论证与分析,要想实现更准确和更稳定的眼周属性识别,就需要在特征学习和匹配过程中强化对识别更有用的区域,将特征最稳定的区域分割出来作为网络另类的监督信息。图像分割通过对图像逐像素比对,可以找到目标所在位置和区域。图像分割指的是对图像上的每个像素点进行分类,找到目标像素所在位置和区域。U-net分割模型将眼周区域最具判别性的特征提取出来,通过添加注意力机制模型对这部分特征进行加强,同时削弱干扰特征的影响(如图2所示)。
U-net分割网络结构清晰,特征提取与VGG网络类似但不尽相同,不同之处是需要使用池化层变换图像尺度,上采样的过程是融合自特征提取对应通道的特征,拼接融合之前需要进行裁剪。U-net网络在医学类图像的处理效果较好,这主要是因为生物图像的尺寸区间分布不统一,U-net可以对任意尺寸的图片实现分割,在实现过程中,当对图像的某一块像素点进行预测时,需要该图像块周围的像素点提供周边信息,以获得更准确的预测。
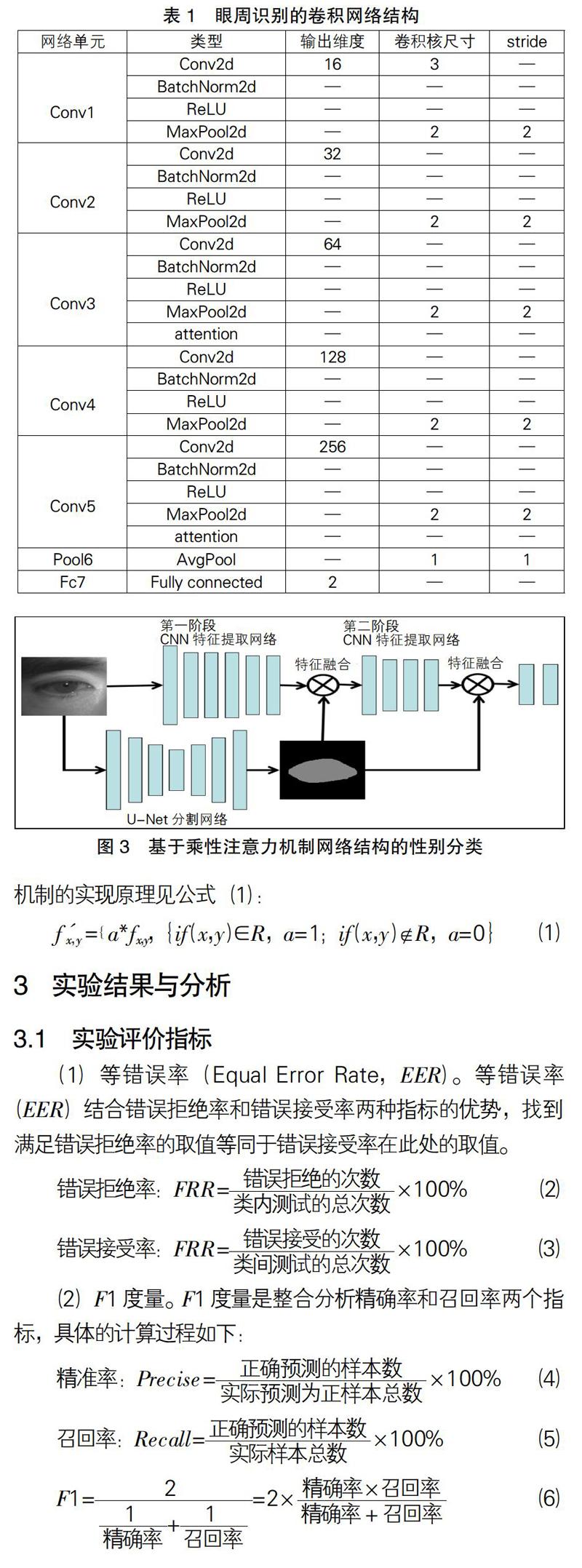
表1是本文采取的识别网络,由主网络和支网络两个部分构成,主网络的原理是使用传统的神经网络进行特征提取和识别,要对图像中的特征尺寸进行缩放,并且需要对通道个数进行变换;支网络对主网络进行修正,指导主网络保留特征区域较好的地方,支网络的主要构成是U-net分割模型,可以很好地提取特征区域,避免受干扰噪声的影响。
基于注意力机制的眼周性别属性识别实现方式是输入图像要先经过CNN提取特征,这样可以得到目标的底层特征信息,但CNN在无监督情况下的特征提取是无差别的,会给人眼特征的抽取带来较多的噪声干扰,网络深度越深,提取到的图像特征就越少,丢失的可用来识别的信息也会减少。设计在第三个单元提取特征后加入监督性的语义分割信息,即支网络提取出来单通道的0和1二值语义通道,预测目标区域的权重值为1,非目标区域的权重值为0,这样可以消除掉大部分噪声。经过修正图像,保证可以过滤掉更多的噪声,最终经过多个全连接层输出属性识别的结果(如图3所示)。乘性注意力机制的实现原理见公式(1):
=a*fx , y,{if (x,y)∈R,a=1;if (x,y)R,a=0}(1)
3 实验结果与分析
3.1 實验评价指标
(1)等错误率(Equal Error Rate,EER)。等错误率(EER)结合错误拒绝率和错误接受率两种指标的优势,找到满足错误拒绝率的取值等同于错误接受率在此处的取值。
错误拒绝率:FRR=×100% (2)
错误接受率:FRR=×100% (3)
(2)F1度量。F1度量是整合分析精确率和召回率两个指标,具体的计算过程如下:
精准率:Precise=×100%(4)
召回率:Recall=×100% (5)
F1==2× (6)
3.2 实验结果和实验分析
眼周性别属性识别的实验是在可见光和近红外两种光源条件下进行,主要包括可见光条件下的数据集V1,近红外数据集CS1,CS2。每种数据集分别进行了少量的人眼分割标注来进行人眼分割。对比试验是在识别网络CNN和加入乘性注意力机制网络中进行,分析不同场景下网络性能的好坏,采用等错误率(EER)和F1度量指标评定各个网络性能。
由表2可得,在可见光条件下,经过乘性注意力机制改进的特征提取网络,在等错误率和F1度量方面都有着不错的表现,这主要是由于增加了识别的网络中重要特征的关注度,因而提升了识别效果。
由表3可得,在近红外条件下的人眼图像特征表现单一,加入注意力机制并不会对识别效果的提升有太大的帮助。
4 结语
眼周图像包含丰富的识别特征,除了已知的虹膜和巩膜以外,人眼的其他特征也可以作为辅助特征进行识别。在深度神经网络基础上加上注意力机制可以应对不良条件下的识别,分析不同注意力机制条件下的特征加强方法,发现最佳的眼周属性识别方法。
参 考 文 献
[1] Krizhevsky A,Sutskever I,Hinton G E.Advances in neural information processing systems[C].Imagenet classification with deep convolutional neural networks,2012:1097-1105.
[2]Chatfield K,Simonyan K,Vedaldi A,et al.Return of the devil in the details:Delving deep into convolutional nets[J].arXiv preprint arXiv:1405.3531,2014.
[3]Tapia J,Rathgeb C,Busch C.Sex-Prediction from Periocular Images across Multiple Sensors and Spectra[C].2018 14th International Conference on Signal-Image Technology & Internet-Based Systems(SITIS).IEEE,2018:529-535.
[4]Smereka J M,Kumar B V K V.What is a" good" periocular region for ecognition[C].2013 IEEE Co-
nference on Computer Vision and Pattern Recognition Workshops.IEEE,2013:117-124.
[5]X Zhang,S Huang,X Zhang,et al."Residual Inception:A New Module Combining Modified Residual with Inception to Improve Network Performance[C].2018 25th IEEE International Conference on Image Processing(ICIP),Athens,2018:3039-3043,doi:10.1109/ICIP.2018.8451515.
[6]H Jun,L Shuai,S Jinming,L Yue,et al.Facial Expression Recognition Based on VGGNet Convolutional Neural Network[C]. 2018 Chinese Automation Congress(CAC),Xi'an,China,2018:4146-4151,doi:10.1109/CAC.2018.8623238.
[7]Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C].Proceedings of the IEEE conference on computer vision and pattern recognition,2018:7132-7141.
[8] Ronneberger O,Fischer P,Brox T.U-net:Convolutional networks for biomedical image segmenta-
tion[C].International Conference on Medical image computing and computer-assisted intervention.Springer,Cham,2015:234-241.
【作者简介】何勇,男,湖南工业大学计算机学院硕士研究生,生物特征识别算法工程师,研究方向:生物特征识别。
