视觉/惯性组合导航技术发展综述
2020-07-29张礼廉胡小平
张礼廉,屈 豪,毛 军,胡小平
(国防科技大学智能科学学院,长沙 410073)
0 引言
随着无人机、无人车以及移动机器人的井喷式发展,导航技术成为了制约无人平台广泛应用的瓶颈技术之一。在应用需求的牵引下,视觉/惯性组合导航技术,特别是视觉与微惯性传感器的组合,逐渐发展成为当前自主导航及机器人领域的研究热点。本文介绍的视觉/惯性组合导航技术侧重于利用视觉和惯性信息估计载体的位置、速度、姿态等运动参数以及环境的几何结构参数,而不包含场景障碍物检测以及载体运动轨迹规划等。
视觉/惯性组合导航具有显著的优点:1)微惯性器件和视觉传感器具有体积小、成本低的优点,随着制造技术的不断进步,器件越来越小,且成本越来越低。2)不同于卫星和无线电导航,视觉和惯性导航均不依赖外部设施支撑,可以实现自主导航。3)惯性器件和视觉器件具有很好的互补性,惯性导航误差随时间累积,但是在短时间内可以很好地跟踪载体快速运动,保证短时间的导航精度;而视觉导航在低动态运动中具有很高的估计精度,且引入了视觉闭环矫正可以极大地抑制组合导航误差,两者的组合可以更好地估计导航参数。
视觉和惯性组合导航技术近年来取得了长足的发展。孙永全和田红丽[1]从同步定位与构图(Simultaneous Localization and Mapping, SLAM)的角度对视觉/惯性组合导航技术的基本原理和标志性成果进行了详细分析。Huang[2]对基于滤波技术的视觉/惯性组合导航技术进行了全面的描述,特别是对滤波器的可观性和滤波状态的一致性问题进行了深入的探讨。Huang和Zhao等[3]对基于激光和视觉传感器的SLAM技术进行了全面的介绍,该文引用的文献十分全面,但缺乏基本原理的阐述。当前随着基于机器学习的视觉/惯性组合导航算法性能不断提高,部分算法已达到甚至超过传统的基于模型的组合导航算法性能。因此,非常有必要按照基于模型的算法和基于机器学习的算法对视觉/惯性组合导航技术进行详细的分析。
1 视觉/惯性组合导航技术发展简述
传统的基于视觉几何与运动学模型的视觉和惯性导航技术研究成果非常丰富。本文主要从纯视觉导航以及组合导航2个层次梳理相关工作。
纯视觉导航技术主要有2个分支:一个分支是视觉里程计(Visual Odometry,VO)技术;而另一个分支是视觉同步定位与构图(Visual Simultaneous Localization and Mapping,VSLAM)技术。Scaramuzza教授[4-5]对早期的VO技术进行了详细的介绍,并阐述了VO技术与VSLAM技术的区别与联系:VO侧重于利用连续图像帧之间的位姿增量进行路径积分,至多包含滑动窗口内的局部地图;VSLAM侧重于全局路径和地图的优化估计,支持重定位和闭环优化;通常VO可以作为VSLAM算法框架的前端。
目前,视觉里程计可以根据使用相机个数的不同分为单目、双目和多目视觉里程计。其中最具有代表性和影响力的主要有三种算法,分别是视觉里程计库(Library for Visual Odometry,LIBVISO)[6]、半直接单目视觉里程计(Semi-Direct Monocular Visual Odometry,SVO)[7]和直接稀疏里程计(Direct Sparse Odometry,DSO)[8]。这三种算法由于代码公开,易于使用,运动估计效果好,成为了研究者们广泛使用和对比的算法。
对于VSLAM算法,目前主流的方法可以分为两类:一类是基于滤波的方法;另一类是基于Bundle Adjustment的优化算法。这两类方法的开创性成果分别是Davison教授提出的Mono SLAM算法[9]和Klein博士提出的并行跟踪与构图(Parallel Tracking And Mapping,PTAM)算法[10]。在2010年国际机器人和自动化大会(IEEE International Conference on Robotics and Automation,ICRA)上,Strasdat的文章[11]指出优化算法比滤波算法的性价比更高,从此以后基于非线性优化的VSLAM算法就渐渐多起来。其中代表性的工作是ORB-SLAM[12]和LSD-SLAM[13],二者的主要区别是ORB-SLAM的前端采用稀疏特征,而LSD-SLAM的前端采用稠密特征。
当然,任何纯视觉导航算法都存在无法避免的固有缺点:依赖于场景的纹理特征、易受光照条件影响以及难以处理快速旋转运动等。因此,为了提高视觉导航系统的稳定性,引入惯性信息是很好的策略。
视觉/惯性组合导航技术与VSLAM算法类似,主要采用两种方案:一种是采用滤波技术融合惯性和视觉信息;另一种是采用非线性迭代优化技术融合惯性和视觉信息。
基于滤波技术的视觉/惯性组合导航算法,可以进一步分为松组合和紧组合两种框架。文献[14-15]使用了卡尔曼滤波器来融合双目相机和惯性器件输出。作为一种松组合方式,组合中没有充分使用惯性器件的输出来辅助图像特征点的匹配、跟踪与野值剔除。2007年,Veth提出了一种视觉辅助低精度惯性导航的方法[16]。该算法使用了多维随机特征跟踪方法,其最大的缺点是跟踪的特征点个数必须保持不变。同年,Mourikis提出了基于多状态约束的卡尔曼滤波器 (Multi-State Constraint Kalman Filter,MSCKF)算法[17],其优点是在观测模型中不需要包含特征点的空间位置;但是MSCKF算法中存在滤波估计不一致问题:不可观的状态产生错误的可观性,如航向角是不可观的,但MSCKF通过扩展卡尔曼滤波(Extended Kalman Filter,EKF)线性化后会使航向角产生错误的可观性。为了解决滤波估计不一致问题,李明阳等[18]提出了首次估计雅可比EKF(the First Estimate Jacobian EKF,FEJ-EKF)算法;Huang等[19]提出了基于可观性约束的无迹卡尔曼滤波(Unscented Kalman Filte,UKF)算法;Castellanos等[20]提出了Robocentric Mapping 滤波算法。这些算法均在一定程度上解决了滤波估计不一致问题。
2015年,Bloesch等提出了鲁棒视觉惯性里程计(Robust Visual Inertial Odometry,ROVIO)[21],该算法利用EKF将视觉信息和惯性测量单元(Inertial Measurement Unit,IMU)信息进行紧耦合,在保持精度的同时降低了计算量。Indelman等基于EKF,综合利用了2幅图像间的对极约束和3幅图像之间的三视图约束融合单目相机和惯性器件[22]。基于相同的观测模型,Hu等给出了基于UKF的实现方法[23]。
近年来,基于优化的算法得到了快速发展。Lupton和Sukkarieh于2012年首次提出了利用无初值条件下的惯性积分增量方法来解决高动态条件下的惯性视觉组合导航问题[24]。文中采用了Sliding Window Forced Independence Smoothing技术优化求解状态变量。预积分理论的建立,使得基于优化的视觉/惯性组合导航算法得以实现。受此思想启发,Stefan等采用Partial Marginalization技术,通过优化非线性目标函数来估计滑动窗口内关键帧的位姿参数[25]。其中,目标函数分为视觉约束和惯性约束2个部分:视觉约束由空间特征点的重投影误差表示,而惯性约束由IMU运动学中的误差传播特性表示。该方法不适用于长航时高精度导航,因为没有闭环检测功能,无法修正组合导航系统的累积误差。2017年,Forster等完善了计算关键帧之间惯性积分增量的理论,将该理论扩展到Rotation Group,并分析了其误差传播规律[26]。该算法也未考虑闭环检测问题。同样基于预积分理论,沈劭劼课题组提出了视觉惯性导航(Visual-Inertial Navigation System, VINS)算法[27]。该算法具备自动初始化、在线外参标定、重定位、闭环检测等功能。ORB-SLAM的设计者Mur-Artal等利用预积分理论,将惯性信息引入ORB-SLAM框架,设计了具有重定位和闭环检测等功能的视觉/惯性组合导航算法[28]。关于预积分理论,目前还缺乏积分增量合并以及相应的协方差矩阵合并方法。因此,文献[28]去掉了ORB-SLAM中的关键帧删除功能。表1汇总了基于视觉几何与运动学模型的视觉和惯性导航技术的主要研究成果。
基于模型的视觉/惯性组合导航技术需要信噪比较高的输入数据,算法的整体性能不仅受制于算法的基本原理,还取决于参数的合理性与精确度。相对而言,深度学习神经网络能够通过大数据训练的方式自适应地调节参数,对输入数据具有一定的容错性,因此已有研究人员开发了一系列基于深度学习的视觉/惯性组合导航技术,并已取得一定成果。
使用深度学习神经网络替换传统算法中的个别模块是较为直接的算法设计思路,如利用深度学习神经网络实现里程计前端中的特征点识别与匹配。Detone等[29]提出了SuperPoint算法,该算法首先使用虚拟三维物体的角点作为初始训练集,并将特征点提取网络在此数据集上进行训练;对经过训练的网络在真实场景训练集中进行检测得到自标注点,并将标注有自标注点的真实场景图像进行仿射变化得到匹配的自标注点对,从而得到了最终的训练集;随后使用对称设计的特征点识别网络,将特征提取器读入的原始图像经过多层反卷积层转换为特征点响应图像,响应区域为相邻帧图像匹配特征点的位置。几何对应网络(Geometric Correspondence Network, GCN)[30]则是利用相对位姿标签值构建的几何误差作为匹配特征点空间位置估计值的约束;随后使用多视觉几何模型结合低层特征提取前端网络得到的匹配特征点,求解载体的运动信息。此类低层特征提取前端易于与传统实时定位与建图系统相结合,并且较为轻量,可植入嵌入式平台进行实时解算。
另一种思路是使用深度学习神经网络实现从原始数据到导航参数的整个转化过程。Kendall团队基于图像识别网络GoogleNet[31]开发了一种基于单张图像信息的绝对位姿估计网络PoseNet[32]。首先,搭建绝对位姿回归数据集,配合高精度姿态捕捉设备,为单目相机拍摄的每一帧图像标注绝对位姿标签值;然后使用多层全连接层替换GoogleNet的多个softmax层,并构成位姿回归器,回归器的输出维度与使用欧拉角表示的位姿维数相同;通过长时间的训练,PoseNet能较为准确地将训练数据集图像投影为对应位姿标签,然而没有额外的几何约束,网络收敛较为困难。Wang等在位姿估计网络中引入相邻帧图像信息,构建基于深度学习的单目视觉里程计DeepVO[33],为了能够同时处理相邻两帧图像的信息,将FlowNet[34]网络的主体作为视觉特征提取器,并使用输入窗口大于1的长短时记忆(Long Short Term Memory, LSTM)网络联合时间轴上相邻多帧图像的高层信息,以此来优化里程计短时间内的估计精度;最后使用全连接层综合图像高层信息,并转化为相邻帧图像的相对位姿估计值。实验结果表明,DeepVO相对于早期基于模型的视觉里程计LIBVISO[6]性能具有一定提升,同时与同类型算法[35]相比,也有明显的性能提升。
与基于模型的视觉/惯性组合导航技术类似,为了提高导航算法的自主性与抗干扰能力,研究人员在基于深度学习的视觉导航技术中引入惯导数据,并为其设计单独的网络来提取有用的数据特征。牛津大学的Clark团队设计了一种端对端的视觉/惯性组合里程计网络VINet[36],使用双向光流提取网络FlowNet-Corr[34]提取相邻帧图像的高层特征,使用单层全连接层对图像高层特征进行压缩,并使用多节点LSTM网络处理两帧图像间的惯性信息;随后将两种数据的高层特征在单维度上进行结合,构成视觉/惯性信息融合特征;最后使用全连接层将融合特征投影至SE(3)空间中,得到相对位姿估计值。VINet在道路与无人机数据中都显示出较为优秀的性能,同时为基于深度学习的组合导航技术提供了基础模板。
陈昶昊于2019年提出了基于注意力模型的视觉/惯性组合里程计网络Attention-based VIO[37],网络的基本框架与VINet类似,但视觉特征提取器使用更为轻量的FlowNetsimple[34]卷积层,以此来提高网络运行效率。借鉴自然语言处理领域的注意力机制,使用soft attention和hard attention两种注意力网络剔除融合特征中的噪声高层特征,从而加快训练收敛,提高网络性能。表2汇总了基于机器学习的视觉/惯性组合导航技术的主要研究成果。

表2 基于机器学习的视觉/惯性组合导航技术Tab.2 Learning based visual-inertial integrated navigation
在国内,清华大学、上海交通大学、浙江大学、哈尔滨工程大学、国防科技大学、北京航空航天大学、北京理工大学、南京航空航天大学、西北工业大学、电子科技大学、中国科学院自动化研究所等高校和科研机构的多个研究团队近年来在惯性/视觉组合导航领域开展了系统性的研究工作,取得了诸多研究成果[38-44]。
2 基于模型的视觉/惯性组合导航技术
基于模型的视觉/惯性组合导航技术的通用结构示意图如图1所示。

图1 基于模型的视觉/惯性组合导航技术通用结构示意图Fig.1 Scheme of model based visual-inertial navigation technology
2.1 基于模型的纯视觉导航算法
基于模型的视觉导航算法是指以多视图几何等数学模型构建的VO和VSLAM算法。
(1)视觉里程计原理
载体在运动过程中,可以通过与其固联的摄像机获取图像流。由于载体运动,同一个静止的物体在不同帧图像中的成像位置将发生变化。根据摄像机的成像几何模型,可以利用同一物体在不同帧图像中成像位置的关系,恢复出相机在拍摄图像时的位置和姿态变化量。然后,将相邻帧图像的位置和姿态变化量进行积分,可以推算出摄像机运行的轨迹,如图2所示。

图2 多视图几何示意图Fig.2 Scheme of multi-view geometry
摄像机的成像模型是从多视图中恢复出载体运动参数的基础。常用的相机模型包括透视模型(perspective model)、全景模型(omnidirectional model)和球形模型(spherical model)等。摄像机模型可以通过观察棋盘格或二维码等特征固定且尺度大小已知的物体进行离线标定。
视觉里程计根据特征利用的方式可以分为间接法和直接法两类。间接法通过最小化同一特征在不同图像中的位置投影误差来解算摄像机的运动参数;而直接法则基于光度(灰度)不变假设,通过最小化同一特征在不同图像中的光度误差来估计摄像机的运动参数。
间接法视觉里程计首先需要建立特征匹配关系,然后根据特征匹配对之间的坐标关系,解算出相机的运动参数。设载体在运动过程中,摄像机拍摄了n幅图像,表示为I1∶n={I1,…,In};同时,在导航环境中有m个特征,特征的空间坐标为p1∶m={p1,…,pm} ;第j个特征在k时刻拍摄图像中的坐标为zk,j=πk(pj),其中πk表示相机在k时刻的投影模型,其与相机的成像模型和相机的位姿相关。
首先,通过特征匹配算法建立特征之间的对应关系{zk,j↔zk+1,j},间接法视觉里程的运动估计可以表示为最小化如下误差函数的过程
(1)


图3 重投影误差示意图Fig.3 Scheme of reprojection error
与间接法不同,直接法视觉里程计则通过最小化光度误差估计摄像机的运动参数。通常,同一特征在短时间内拍摄的多幅图像中,其光度基本不变,并且摄像机在短时间内的位姿变化较小,同一特征在相邻帧图像中的成像位置变化不大。据此,直接法视觉里程计通过迭代优化算法在状态空间中进行搜索,使得同一特征在不同图像中的像点光度误差最小,从而解算得到摄像机运动参数,具体优化目标函数为
(2)
其中,Ik(pj)和Ik+1(pj)分别表示同一特征在相邻帧图像中的光度。若直接法里程计在运动估计过程中使用了整幅图像的像点光度,则为稠密视觉里程计算法;若仅使用部分像点光度,则为稀疏视觉里程计算法。由慕尼黑工业大学开发的DSO算法[8]就是一种稀疏直接法视觉里程计。
除直接法与间接法里程计外,Forster等还提出了一种半直接法视觉里程计[7]。在SVO中使用了直接法进行运动解算,同时采用了间接法来估计特征的三维坐标,建立局部地图。

(2)闭环优化与构图
视觉里程计是一种路径积分方法,因此具有累积误差。闭环优化是广泛使用的一种用于修正视觉里程计累积误差的方法。闭环修正依赖于构建的环境地图,其基本原理是:载体在移动过程中,将观测的视觉特征与地图中的视觉特征进行匹配,并通过匹配关系解算出载体在地图中所处的位置和姿态。由于建图误差和视觉里程计累积误差的影响,通过里程计估计的摄像机位姿与通过闭环检测估计的摄像机位姿之间具有差异,通过建立数学模型可以同时对里程计累积误差和建图误差进行修正。闭环优化与构图可以描述为一个最大后验概率(Maximum A Posteriori, MAP)问题,具体表达式为
(3)
其中,X表示摄像机在整个运动过程中的位置和姿态构成的状态向量;L表示所有特征在参考系下的位置向量的集合;Z表示特征在摄像机图像中的成像点位置的集合;U表示里程计测量的运动参数。在大范围的导航应用中,式(3)中包含的状态量较多,因此需要对优化算法进行合理设计才能满足算法的实时性需求。目前,广泛使用的建图与闭环优化工具有G2O[45]、GTSAM[46]和Ceres[47]等。
2.2 基于模型的视觉/惯性组合导航算法
基于滤波技术和基于非线性迭代优化技术是视觉/惯性信息融合的两种典型方式。
(1)基于滤波技术的信息融合算法
基于滤波技术的信息融合算法主要考虑以下3个方面的问题:滤波器状态变量的选取、状态方程和观测方程的建立以及滤波算法的选取。
首先是滤波器状态变量的选取,常见的方式是将当前时刻的惯性导航参数、邻近n帧图像对应时刻的载体位姿参数以及这些图像所观测到的特征的空间位置参数加入到状态变量中。当前时刻惯性导航参数通常包含IMU的位置、姿态、速度和陀螺、加速度计的零偏等,其定义如下
(4)
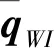

(5)

其次是状态方程和观测方程的建立。由于通常假设场景是固定的,即特征点的空间位置变化率为0,因此系统的状态方程只与载体的运动参数有关。
典型的系统状态微分方程如式(6)所示
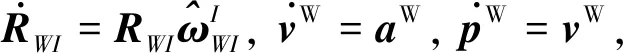
(6)

关于滤波器的选取,最常见的有EKF[17-18,20-22]和UKF[19,23,40-41,43],二者都是在卡尔曼滤波器(Kalman Filter, KF)的基础上发展起来的。EKF通过偏导数得到雅可比矩阵,将状态方程和观测方程线性化,从而解决视觉/惯性融合中的非线性问题。为了克服EKF中高阶导数省略问题和雅克比矩阵计算难的问题,UKF按一定间隔和概率在状态空间中选取采样点(sigma points) 的方式,代入状态方程和观测方程,预测和更新状态值及其对应的协方差矩阵。
由于计算量的限制,一般不会将全局地图中的特征空间位置参数加入滤波器状态变量中,因此基于滤波技术的视觉/惯性组合导航算法通常无法构建全局地图,不支持闭环检测与优化。
(2)基于优化技术的信息融合算法
为了实现迭代优化算法框架下的视觉/惯性导航信息融合,必须解决惯性约束和视觉约束的统一表示问题。对于视觉信息,关键帧之间的位置和姿态约束可以通过它们共同观测的图像特征之间的匹配关系来确立。而对于惯性信息,2个时刻间的位置和姿态约束可以通过2个时刻间的陀螺和加速计测量信息来建立。在视觉/惯性组合导航系统中,当前时刻的关键帧位姿参数是在前一时刻关键帧的位姿参数基础上,利用陀螺和加速度计测量值递推得到。由于关键帧的位姿参数属于迭代优化的状态变量,在优化过程中,每一次迭代都会改变,所以由前一时刻关键帧的位姿参数递推得到的当前帧的位姿参数,需要重新利用两帧之间的陀螺和加速度计测量值推算,处理效率非常低。为了避免该问题,需要设计一种不依赖于积分初值的惯性积分增量计算方法,使得在迭代优化过程中,前一时刻关键帧位姿参数变化之后,可以根据积分增量快速更新当前时刻的关键帧位姿参数。

图4 基于迭代优化技术的视觉/惯性组合导航示意图Fig.4 Scheme of visual-inertial integrated navigation based on iterative optimization
惯性预积分技术应运而生[24],其核心思想是定义位置、姿态和速度积分增量,使得积分增量与积分初值无关。从系统的运动学模型式(6)出发,可以得到关键帧[ti,tj]时刻间的位姿参数与惯性测量值之间的关系为
(7)
其中,g是重力矢量,η是加速计测量噪声,n是积分时段内惯性传感器的采样个数。从式(7)可以看出,tj时刻关键帧的位姿参数与ti时刻关键帧的位姿参数以及[ti,tj]时刻间的惯性测量值有关。为了消除ti时刻关键帧的位姿参数的影响,定义ti和tj时刻关键帧之间的状态变量增量计算公式如下
(8)
式中,Δtij=tj-ti。从式(8)可以看出,惯性积分增量ΔRij、Δvij、Δpij仅与[ti,tj]时刻间的陀螺测量值ω和加速度计测量值a有关,与积分的初值Ri、vi和pi无关。
通过预积分对惯性信息进行预处理之后,就可以建立统一视觉约束和惯性约束的优化目标函数。以VINS为例,其目标函数具有如下形式[27]
(9)
其中,3个残差项依次是边缘化的先验信息、IMU测量残差以及视觉的观测残差,X是待优化的状态向量,包含关键帧的相机位姿、特征的空间位置、惯性器件的零偏等。
当然,一个完整的视觉/惯性组合导航系统还包含系统初始化、闭环修正与优化等。此处不再赘述,感兴趣的读者可以查阅文献[25-28]。
3 基于机器学习的视觉/惯性组合导航技术
深度学习神经网络是机器学习概念的重要分支,具有参数学习与非线性模型拟合的能力,利用深度学习解决组合导航问题,实质上是使用神经网络对原始数据与导航参数之间的关系进行建模,并通过长时间训练来优化模型的参数。为了增强深度学习网络的可解释性,需对网络不同功能模块使用不同种类的网络进行建模。图5所示为基于深度学习的视觉/惯性组合导航技术的通用结构示意图。

图5 基于机器学习的视觉/惯性组合导航技术通用结构示意图Fig.5 Scheme of learning based visual-inertial navigation technology
3.1 前端网络
(1)视觉特征提取器
与基于模型的组合导航技术类似,基于深度学习的导航技术也存在前端,即处理原始数据的模块。针对图像这种高维度的信息,需从中捕获高层特征来解析相机运动信息。

(10)
文献[33,37]使用单输入的光流估计网络 (FlowNetSimple)[34]的卷积层部分搭建视觉特征提取器,并将网络的输入层通道数设置为6,接收时间轴上相邻两帧的RGB图像。为了能对相邻图像的高层信息进行更充分的解析,文献[36]使用双输入的光流估计网络(FlowNetCorr)[34]的卷积层部分搭建视觉特征提取器,为前后两帧图像分别构建卷积神经网络,解析2张图像中的高层特征,并使用correlate操作融合两帧图像的高层特征。FlowNetCorr的层数较多,训练成本较大,因此在基于深度学习的视觉里程计中一般选用FlowNetSimple的卷积层部分搭建视觉特征提取器。上述两种视觉特征提取器依据成熟的卷积神经网络进行设计,同时Dosovitskiy 等[34]已公开这两种卷积神经网络的预训练参数,有利于开发基于视觉信息的深度学习导航技术。然而FlowNetCorr与FlowNetSimple都属于层数较多的卷积神经网络,参数量较大,其中FlowNetCorr参数占磁盘空间149M,FlowNetSimple占148M,因此这两种卷积神经网络不适用于包含深度信息的全导航参数估计算法。针对此问题,文献[49-50]设计了仅由6层卷积核构成的视觉特征提取器,并且使用均值池化操作将视觉高层特征直接压缩为6维度的相邻图像帧位姿;但较少的层数也导致提取器的解析能力较弱,在深度以及位姿估计任务中的性能也有一定局限性,训练收敛速度较慢。
(2)惯性信息特征提取器


(11)
文献[36-37]使用惯性信息与图像的融合特征进行姿态解算,实验结果表明,添加惯性信息的里程计网络收敛较快并且测试精度较高。为了进一步提高里程计的解算精度,文献[37]设计了两种注意力网络,注意力网络输出与原始数据高层特征同尺寸的权重掩膜,并通过改变特征元素的相对大小,从而调整网络的训练方向,规避噪声特征对网络性能的影响。文献[37]的实验结果表明,基于深度学习的惯导信息特征提取器在多种惯导信息噪声的环境下也具有较为稳定的性能。然而由于深度学习神经网络参数对于训练数据具有一定的依赖性,对于不同场景数据的泛化能力较差,这限制了基于深度学习的特征提取器的应用范围。文献[52]使用迁移学习的方法,找到不同场景中惯导数据的共有特征并结合其物理模型,在没有标签数据的情况下,利用低精度的手持设备数据也能得到精度较高的位姿解算结果。
原始数据的高层特征,需使用位姿回归器将高层特征投影至标签空间中。常见的位姿回归器由多层全连接层组成,全连接层的输出通道数与位姿估计值的形式有关。现阶段基于深度学习的视觉里程计都采用欧拉角来表示姿态,因此一般将位姿回归器中最后一层的全连接层设置为6[33,37],也可以将位姿回归的过程解耦,分别设置3维度的位置回归器与姿态回归器。
(3)深度估计网络
除了提取原始数据的特征以外,前端还需给出当前视角内特征点的深度信息。基于模型的视觉/惯性组合导航技术使用多视觉几何模型联合相邻帧图像的匹配特征点,求得相对位姿以及无尺度的特征点深度值。然而,在纹理缺失以及光线较暗的部分,特征点识别算法失效导致无法得到较为准确的深度值。深度学习神经网络通过前向传播直接得到原始图像像素点对应的深度值,同时设计具有几何约束的误差项来校正神经网络参数,从而提高深度估计的精度。文献[50,55-56]构建了类U-NET的深度估计网络,使用多层卷积神经网络构建特征提取器,其中文献[54-55]使用主流的PackNet和ResNet网络作为特征提取器,在训练前使用预训练参数进行初始化,便于训练的收敛;随后使用深度解码器将特征提取器解析的图像高层特征变为与原图尺寸一致的深度估计值,深度解码器由多层反卷积层构成,同时将特征提取器输出图像的不同层次的特征输入到深度解码器对应的反卷积层中,强化深度估计图像的多尺度细节。为了提高深度估计网络的性能,现有两种思路:1)改进网络的结构,例如将网络的高低特征联结[50,55-56],增强输出的深度图像质量;2)在设计误差函数时添加约束条件,例如文献[55]引入时空最小误差,剔除在连续两帧图像中因相机旋转而移出视场范围的像素点,避免了在计算重投影误差时出现局部异常极大值的现象;文献[56]则在总误差中引入极线误差,使得网络能够充分利用相邻帧的点线特征,从而增强网络性能。
3.2 特征优化
特征优化环节对应基于模型的视觉/惯性组合导航技术中的非线性优化模块,该模块利用前端提取的低层特征以及里程计估计的位姿参数构建几何误差函数,使用特定的非线性优化算法降低误差函数值,以此得到优化的导航参数。同样地,特征优化环节也设计了特定的网络来优化前端网络得到的数据特征或者导航参数估计值。
借鉴传统SLAM窗口优化的思想,文献[33,36-37]在视觉特征提取器的最后一层卷积层中添加LSTM网络,以综合前后多帧原始数据的高层特征,优化当前时刻的高层特征。上述过程如式(12)所示,其中flstm的每一时刻都引出隐藏变量,使得经优化的特征与未优化特征的尺寸保持一致。
(12)
同时LSTM网络采用多层次级联设计,并添加多个节点以增加网络的解析能力。然而,此类算法属于端对端优化算法,不具有可解释性。为了能在优化原始数据高层特征的过程中考虑到几何模型的因素,文献[49-50,53-55]在总误差中设计了重投影误差,耦合了深度估计网络与位姿估计网络参数的优化过程。然而,以上工作都仅将重投影模型体现在总误差函数中,没有构建显示的网络结构对重投影模型进行求解,网络设计依旧欠缺一定的可解释性,因此很难确定网络是否拟合出了图像像素值、深度与相对位姿之间存在的重投影模型;同时从以上文献的算法性能验证实验可以看出,以上算法相对于端对端的里程计或者深度估计网络的性能并没有显著的提升,这从另一个侧面说明了以上算法在构建网络时并没有充分利用重投影模型原理。鉴于此,Tang 等[57]构建了可微重投影约束层(BA-Layer),对重投影模型的每个参数进行显示建模,从而对输出的导航参数进行优化。分别设计了基础深度生成网络以及多尺度特征提取网络,将时间上相邻的一组图像代入基础深度生成网络得到每一帧图像的深度图像族,并使用与深度图像族对应的可微系数,将深度图像族加权组合为深度估计值图像;同时使用多尺度特征提取网络得到图像帧的高层特征,随后构建特征级的重投影误差,并代入BA-Layer层中进行优化。BA-Layer层根据前一时刻的状态优化量计算雅克比矩阵、正规方程、阻尼系数以及海森矩阵,进而得到状态量的变化量,从而得到当前时刻的状态优化量。为了确保BA-Layer层的可微性,固定了特征级重投影误差的优化步数,同时使用多层全连接层将特征级重投影误差转化为阻尼系数。从实验结果来看,相比于使用光度重投影误差与几何重投影误差的位姿估计方法,该文设计的相对位姿估计网络的旋转角与平移矢量测试精度更高。首先,这说明BA-Layer能对重投影误差进行有效建模。其次,文献提到使用几何重投影误差的位姿估计方法在室内环境中可能无法进行有效的特征匹配,光度重投影误差则会增加优化函数的非凸性,导致优化算法对初值设置较为敏感。相比较而言,BA-Layer使用经卷积神经网络解析的高层特征进行导航参数的求解,相比于特征点、光流等底层特征,高层特征具有较高的稳定性,因此算法的鲁棒性较好。此外,卷积神经网络具有较强的非线性拟合能力,可以在训练过程中对状态初值进行隐式估计,不需要人为指定。
Chen等[58]则提出了一种基于深度学习的卡尔曼滤波算法DynaNet。该算法首先假设视觉/惯性组合里程计是一个马尔科夫过程,即当前时刻的状态量与前一时刻的状态量有关,并且能用线性模型来描述状态传递过程。DynaNet算法使用LSTM网络估计状态传递矩阵以及协方差传递误差,并使用卷积神经网络得到视觉/惯性原始数据的高层特征以及测量误差;随后构建卡尔曼滤波方程,经过迭代得到当前时刻的状态量估计值;最后结合状态量的标签值构建训练误差,经过多轮训练得到精度更高的状态量估计值。相比于Tang 等的工作,DynaNet使用深度学习神经网络重构线性卡尔曼滤波方程,但鉴于深度学习具有强大的非线性拟合能力,DynaNet的状态传递矩阵估计网络也能对位姿求解过程进行建模。从实验结果来看,DynaNet的位姿解算精度高于基于模型的ORB-SLAM[12]以及基于深度学习的VO-Feat[50],这证明了经过精心设计的深度学习网络具有超越基于模型的导航算法的能力;同时也说明了使用深度学习重构传统卡尔曼滤波模型能有效提升深度学习框架求解位姿问题的能力。
3.3 闭环优化与建图

(13)
在得到经过优化的绝对位姿之后,需结合关键帧的深度信息构建全局的三维立体模型,然而基于重投影误差估计的关键帧深度值不具有全局一致的尺度,因此还需设计更多的几何约束使得网络在长时间的训练过程中逐渐恢复关键帧的尺度。Guizilini 等[54]提出了在训练误差函数中添加训练数据集中的速度标签,使得相对位姿估计网络输出的相对平移量具有与标签值一致的尺度。Bian 等[61]则使用深度估计网络同时估计参考帧与目标帧的深度,随后使用匹配特征点对应的空间点坐标构建投影误差。
4 视觉/惯性组合导航技术的典型应用及发展趋势
视觉/惯性组合导航技术是机器人、计算机视觉、导航等领域的研究热点,在国民经济和国防建设中取得了广泛的应用,但也面临着诸多挑战。
4.1 视觉/惯性组合导航技术的典型应用
国民经济领域,在无人机、无人车、机器人、现实增强、高精度地图等应用的推动下,视觉/惯性组合导航技术取得了快速发展。例如Google的Tango项目和无人车项目、微软的Hololens项目、苹果的ARKit项目、百度无人车项目、大疆无人机项目、高德高精度地图项目等大型应用项目都成立了视觉/惯性组合导航技术相关的研究小组,极大地促进了视觉/惯性组合导航技术在国民经济中的应用。以Google的Tango项目为例,其导航定位核心算法是基于滤波框架的MSCKF算法;微软的Hololens项目则是以KinectFusion为基础的SLAM算法。
国防建设领域,由于视觉/惯性组合导航技术不依赖外部人造实施,在卫星拒止环境中有着重要的应用价值。例如美国陆军研发的一种新型联合精确空投系统采用惯性/视觉组合导航技术解决高精度定位问题。嫦娥三号巡视器也采用视觉与惯性组合实现定姿定位。李丰阳等[62]总结了视觉/惯性组合导航技术在地面、空中、水下和深空等多种场景中的应用。
4.2 视觉/惯性组合导航技术的未来发展趋势
视觉/惯性组合导航技术取得了广泛的应用,但在复杂条件下的可靠性还有待加强,其未来的发展主要体现在以下4个方向:
1)提升信息源的质量。首先是提升惯性器件(特别是基于微机电系统(Micro-Electro-Mecha-nical System,MEMS)工艺的微惯性器件)的零偏稳定性和环境适应性等性能指标;其次是提升视觉传感器的光照动态适应性、快速运动适应性等性能指标;此外,还可以引入更多的传感器,如磁传感器、超声波传感器、激光雷达等,提升复杂条件下组合导航系统的综合性能。
2)提升信息融合算法的水平。视觉和惯性信息各有特点,不同条件下信息的质量也不尽相同,需要设计智能的信息融合机制。目前的算法大多是基于静态场景假设,但在实际应用中,场景都有一定的动态性,动态环境下的视觉/惯性组合导航是提升复杂条件下导航可靠性的重要研究方向。此外,目前基于滤波的信息融合算法仍然存在滤波状态发散或者状态收敛到错误值的情况,需要对系统的可观性进行分析,提升状态估计的一致性。对于优化框架的信息融合算法,目前的预积分理论还有待完善,特别是在SLAM的地图管理中删除关键帧时,与关键帧相关的积分增量及对应的协方差需要合并,目前还缺乏协方差合并方法;而且基于BA的优化算法计算量较大,对于大尺度的闭环优化,计算耗时太久,存在错失闭环优化的情况,急需提升BA算法的效率。
3)发展新的导航理论。大自然中许多动物具有惊人的导航本领,例如:北极燕鸥每年往返于相距数万km远的南北两极地区;信鸽能够在距离饲养巢穴数百km远的地方顺利返回巢穴。模仿和借鉴动物导航本领的仿生导航技术逐渐成为了导航领域研究的热点。胡小平等[63]对仿生导航技术进行了全面的总结。此外,随着多平台集群应用的普及,利用组网编队中平台间导航信息交互来提升位置、速度、姿态等参数估计精度的协同导航技术方兴未艾。谢启龙等[64]从无人机、机器人、无人水下潜航器、导弹4个应用层面梳理了协同导航技术的国内外发展现状。
4)扩充导航系统的功能。目前的视觉/惯性组合导航侧重于导航参数的估计,对于引导和控制等关注较少。随着机器学习技术在视觉/惯性组合导航领域的应用,可以将机器学习在环境理解、避障检测、引导控制等方面的成果融入到导航系统中。
