融合优选图案的深度学习目标识别及定位技术
2020-07-28王立鹏张智苏丽聂文昌
王立鹏,张智,苏丽,聂文昌
(哈尔滨工程大学 自动化学院,黑龙江 哈尔滨 150001)
目标识别和定位在各研究领域应用广泛,如视频监控、自动驾驶等,并成为众多领域不可或缺的技术基础。多年来,学者们在目标识别方面多采用目标特征提取的方法,目标特征包括纹理特征、颜色特征、形状特征等[1-3],但基于上述特征的传统的目标识别方法,大多针对特定的识别任务,特别是在有用信息较少情况下,难以实现精准的识别效果;在目标定位方面,研究人员大多基于目标识别基础,如提取图像特征[4]等,通过尺度不变特征变换算法对图像特征检测和匹配[5],基于传统特征的目标定位精度不高。有些学者采用增加人工标识[6-8]的方式,强化图像特征并便于物标位姿计算,但此种方式仍然存在问题:一方面,依然在传统的目标特征基础上开展,无法摆脱前述问题;另一方面,人工标识一般采用角点等明显醒目形式,过于显眼的人工标识影响环境美观,实用性较差。
近年来,深度学习方法在计算机视觉领域发挥了巨大作用,出现众多优秀的卷积神经网络[9-13],相比传统的目标特征,极大提高了目标识别的鲁棒性和准确性[14],由于卷积特征更能够反映图像本质,深度学习在基于图像的目标检测及分类问题中取得显著效果,但不能完全解决此类视觉问题,这是由于:1)深度学习应用时往往需要足够多的训练样本,但目标可能存在遮挡、变形等一系列干扰因素,训练样本难以穷尽所有可能情况;2)需要一次性训练网络,训练后的网络难以动态扩充新类别物体;3)单纯利用深度学习方法,无法获得图像中的目标精确位置和姿态信息。
为解决深度学习在目标识别与定位方面的已有问题,同时提高视觉系统的实用水平,本文以Faster Rcnn网络[15]对优选图案的检测及分类问题为基础,研究构建环境中高实用性目标识别和定位的方法。提出具有针对性的图案可分类性评价方法和图案优选策略,并根据Faster Rcnn网络的各层级特点,从网络中获取卷积数据,量化优选图案评价结果,进而获得可用的优选图案数据库,增加目标识别的成功率。结合双目视觉系统,利用Faster Rcnn网络开展辅助优选图案识别和物标识别工作,通过开展试验,验证了本文算法的有效性、准确性和实用性。
1 构建Faster Rcnn网络应用框架
1.1 Faster Rcnn网络流程
本文以Faster Rcnn网络为深度学习主网络框架,该框架由2部分构成[16],即分类网络和区域建议网络(region proposal networks,RPN),其中分类网络本文具体采用ZF(Zeiler &Fergus net)卷积网络。图1为本文中Faster Rcnn网络工作流程。
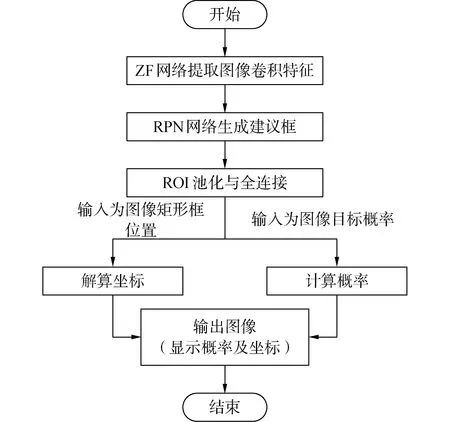
图1 Faster Rcnn网络工作流程图Fig.1 Flow chart of Faster Rcnn
本文Faster Rcnn的工作流程如下:使用ZF网络前5层提取输入图像卷积特征,由RPN网络利用图像卷积特征,生成建议框并完成删选工作,由分类网络利用建议框裁剪图像卷积特征,得到预测的目标特征区域,进行感兴趣区域(region of interest,ROI)池化并设置2层全连接层,计算概率并解算坐标,完成识别和定位工作。
1.2 ZF分类网络
ZF网络输入为224×224大小的三通道图像,网络的第1层首先经过96个不同滤波器的卷积,每个滤波器的大小均为7×7,横纵向的步长均为2,该卷积层的特征层经过ReLU激活函数、大小为3×3的池化以及归一化LRN,得到96个不同的、大小为55×55的特征图集合。其后的卷积层2~5层与上述操作类似,最后经由2个全连接层,将卷积得到的特征以4 096维向量形式输出,得到一个可识别N类目标的分类器。ZF卷积网络的结构图如图2所示,图中滤波器和特征图均为方形。
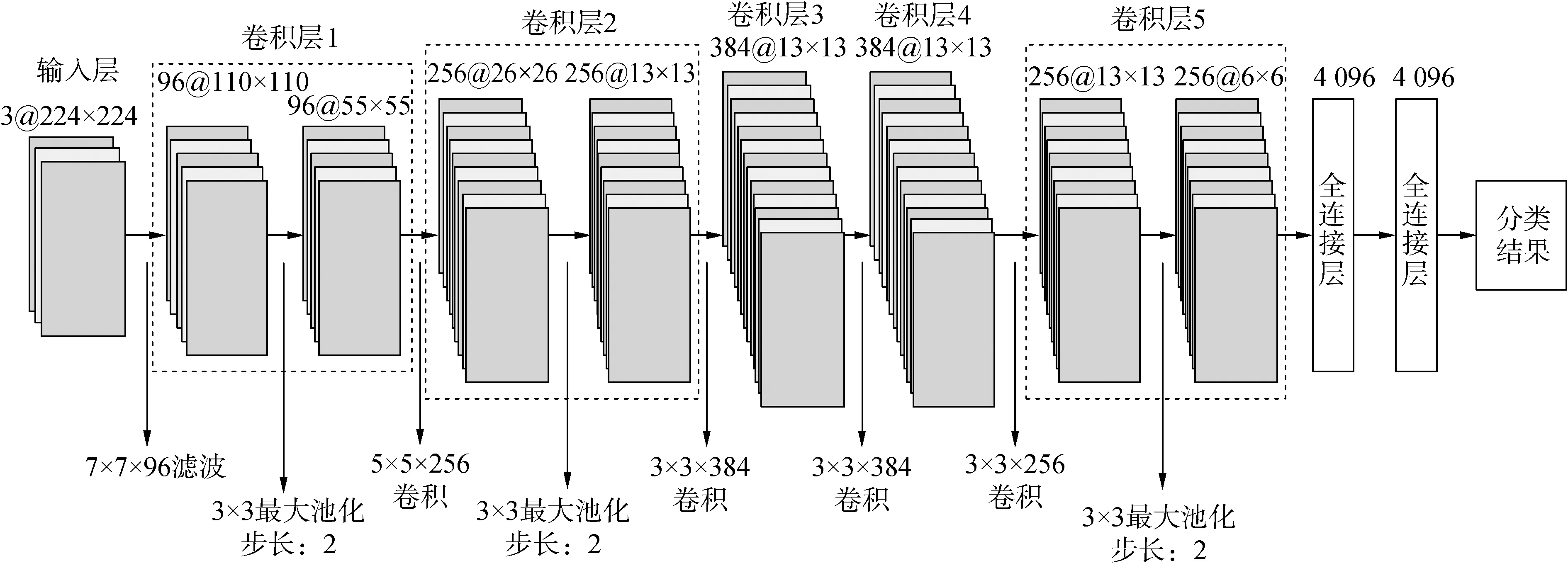
图2 ZF网络结构Fig.2 Structure chart of ZF net
1.3 区域建议网络
传统的生成建议框的过程在CPU上实现,但耗时较长,Faster Rcnn利用卷积神经网络直接提取建议框,这使得网络训练时间大大降低。RPN网络的原理是:利用图像分类的网络结构提取图像特征,进而选取建议框。RPN网络输入为任意大小的卷积网络得到的图像特征,输出为一组矩形的目标建议框及其得分,建议框生成原理可如图3所示。
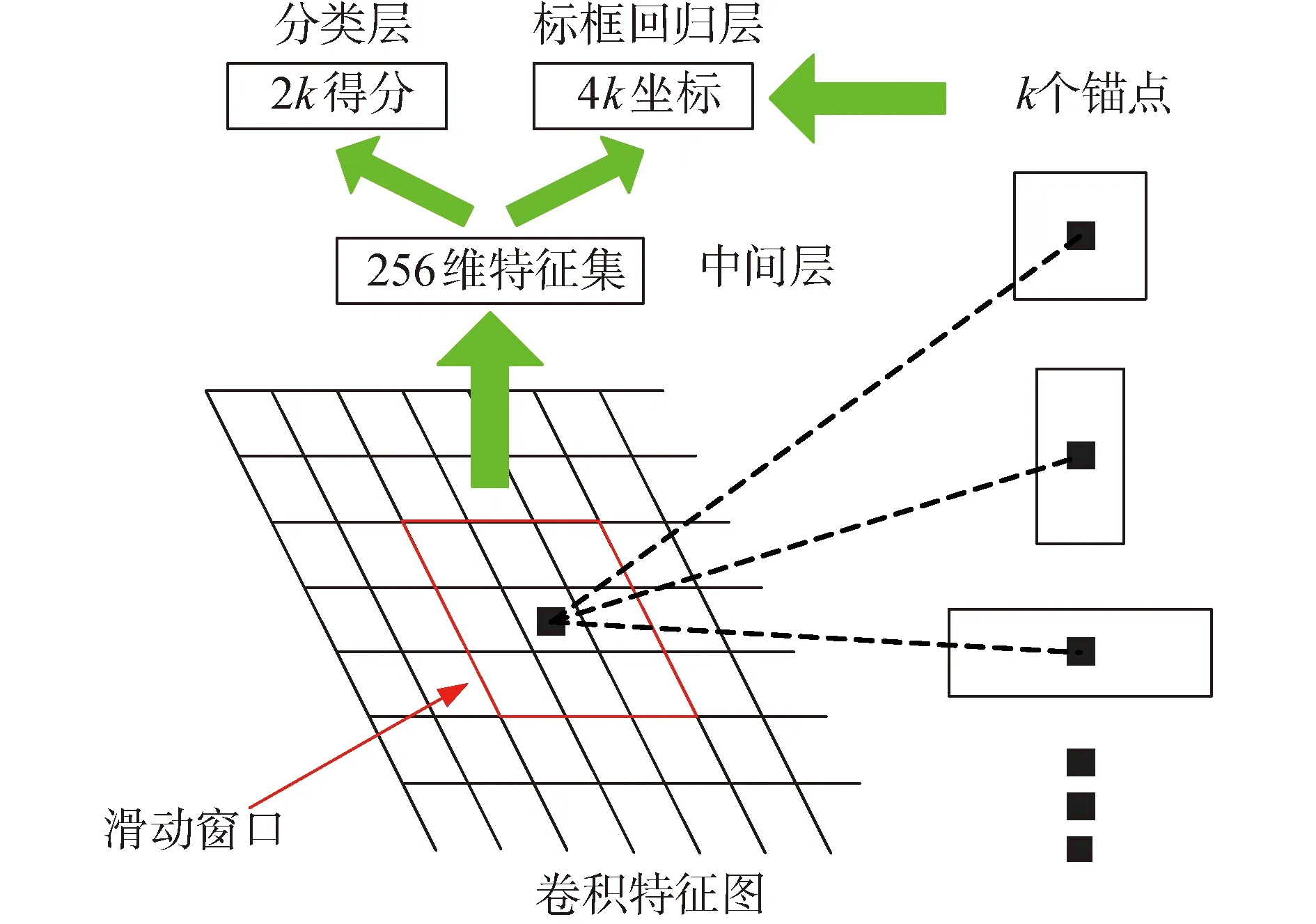
图3 建议框生成原理图Fig.3 Schematic diagram of suggestion box
在RPN网络的开端,使用一个方形滑动窗口,在滑动窗口划过特征集每一个位置时,都生成不同的建议框,每一点生成建议框最大个数为k,则每一点对应的标框回归器有4k个输出,分类层有2k个输出,生成的标框称为锚框。本文将尺度的大小n设为3,长宽比例设为3,则最终每一点生成9个锚点。若一个特征图集的大小为10×10,k取值为10,则最终会生成1 000个锚点。
2 辅助图案优选策略
本文将在给定初始图案集的基础上,设计辅助图案优选策略,提高优选图案集与环境其他目标以及图案集内部不同样本的可分类性,本节优选图案的过程采用ZF网络。
本文中装饰图案共计500个,该初始图案集色彩和形状较为多样,在实际应用中不影响环境的和谐,图4为初始图案集中的12张。

图4 初始图案集样例Fig.4 Examples of the initial pattern set
2.1 图案可分类性评价
本文提出图案“可分类性”的概念,为每个图案提供一种定量的衡量指标,该指标的物理意义为:对应的图案与其他图案(包括背景)的可区分的量化程度,当对应的图案代入深度学习网络时,该指标越大,表示对应的图案越容易被区分。“可分类性”量化指标,可通过小样本集训练试验获取,避免传统大样本训练方式工作量过于庞大的弊端。
在图2所示的ZF网络中,其最终输出为全连接层经过softmax函数归一化得到的分类概率,该概率是为了更显著区分分类效果,因而概率结果较为离散,不能很好体现出目标原本的分类趋势,归一化前后的数据对比如图5所示。
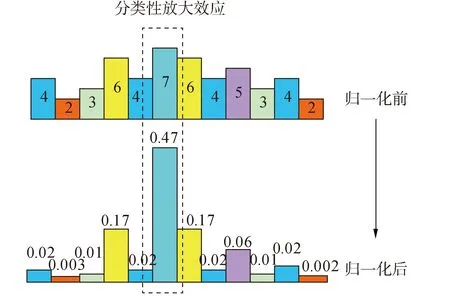
图5 ZF网络输出归一化前后对比图Fig.5 Comparison before and after normalization of ZF network
通过图5可看出,ZF网络归一化后的目标概率被放大,但是失去了归一化前概率趋势效果。本文改变ZF网络概率输出位置,采用归一化前的向量输出作为评价可分类性的数据来源,如图6所示。
以图6网络归一化前的输出为数据源,并设计评价函数以量化图案的可分类性,假设选定图案集类别数量为N,增加1个背景类别,网络包括N+1个输出,本文设计可分类性评价函数Fcls如下:
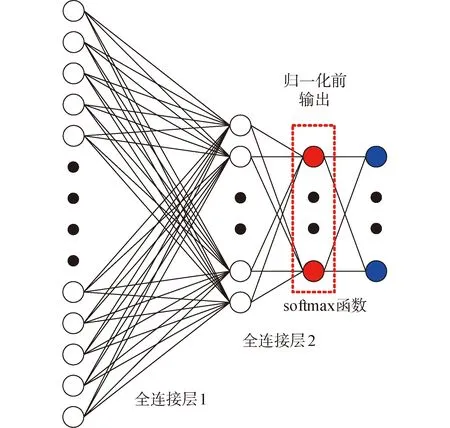
图6 可分类性评价数据源示意Fig.6 Data source of classification evaluation
(1)
式中pr和pN+1为样本网络和背景网络输出概率。
由式(1)可知,该评价函数将图案分类概率非线性映射到指数函数上,并通过放大倍数增大相应图案分类概率与其他图案和背景分类概率的差距。评价函数可以有效得抑制背景对目标的影响,当训练数据有限情况下,仍能评估每一个图案的可分类性。
2.2 图像变换模拟数据集
考虑到难以获取各种环境下原始图案集的海量样本,本文采用仿真手段模拟不同拍摄状态下的图片,增加图片库的多样性。对图案所在平面开展透视变换,包括背景色变换、亮度变换、图像尺度变换、透视角度变换,以此模拟现实环境中不同景物颜色、光强、距离、视角的拍摄效果,以其中一张图片为例,仿真生成的图片库部分效果如图7所示。

图7 仿真模拟生成的图片库Fig.7 Partial effects of images from the simulations
通过对图案随机变换后,本文得到500类图案的训练数据库,每类图案包含150种变换图片集。训练集中增加一类用以表示图案集合之外其他物体或区域的样本,这里选取在生活环境中不同位置、角度拍摄的图片作为背景图片,对每一幅图片随机截取出若干位置框作为候选背景,背景图案共计300张,部分背景图案如图8所示。

图8 截取背景图片Fig.8 Intercept background image
2.3 深度网络预训练评测优选
基于前文介绍的图案可分类性评价方法以及仿真模拟图片库,进一步开展图案集优选工作,利用深度学习框架Caffe[17]来训练ZF网络,图案和背景共计501类,训练次数为50 000次,学习率为0.001。
经ZF网络训练后,利用式(1)的评价函数,可得到图案可分类性的量化数值,量化数值存在以下2种情况:1)正确类别的概率远高于其他类别的分类特征直方图,如图9(a)中类别序号为150的概率情况,该类图案可作为本文优选后的辅助图案;2)正确类别的概率与其他类别的概率区分不够显著的分类特征直方图,如图9(b)中类别序号为342的概率情况,此类图案将作为淘汰的图案不被优选。
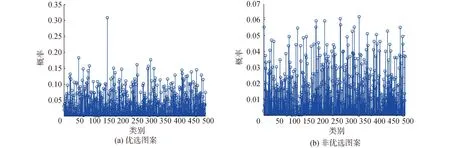
图9 各类别概率图Fig.9 Probability graphs of the figures
按照上述方式,从500张候选图案中优选出16张可分类性最强的图案作为优选图案,详见图10。

图10 优选后的16个图案Fig.10 16 patterns after preferred
2.4 基于优选图案的可分类实际效果分析
放置优选后的辅助图案,在不同状态下拍摄形成训练样本集,本文共拍摄5 000个样本图片,其中选择4 000个作为训练集,另外1 000个作为测试集,训练集准确率为90.6%,测试集准确率为85.7%。
将优选出的辅助图案和其他图案放置于一起,在不同背景和角度下拍摄,识别效果如图11所示。
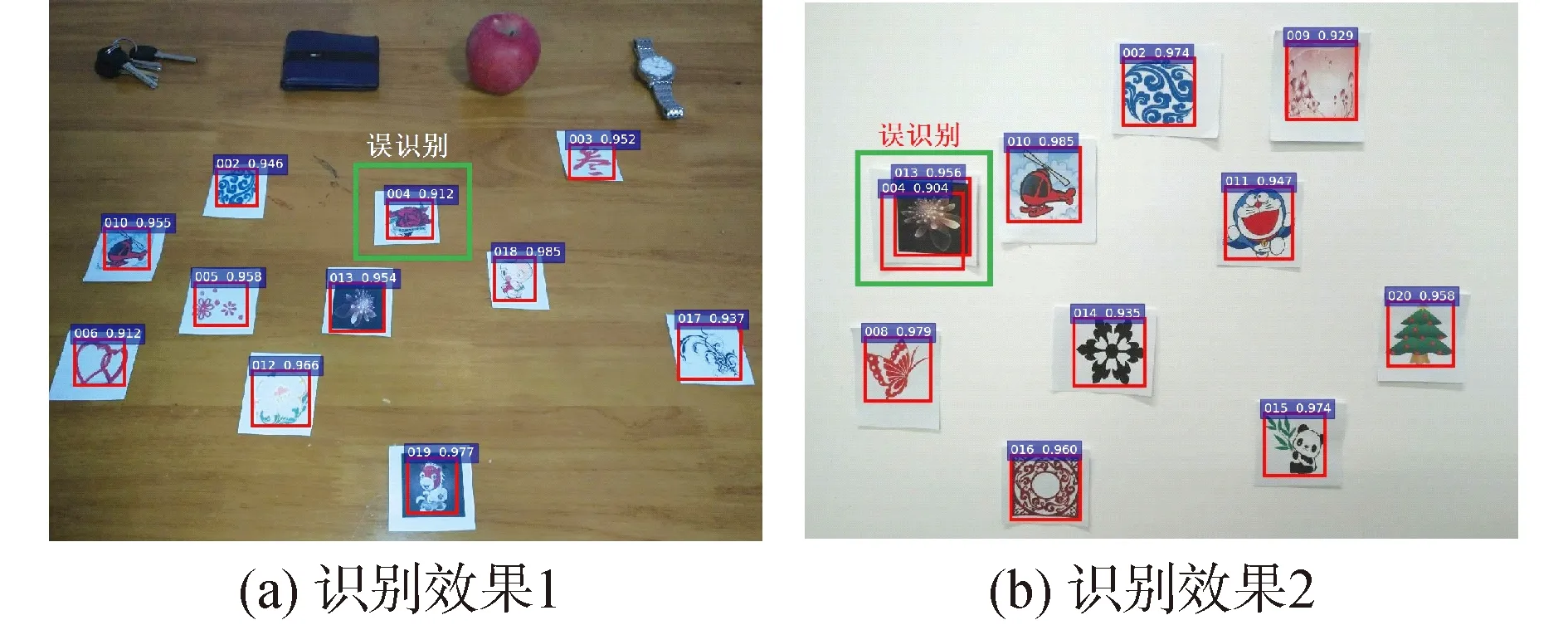
图11 图案识别效果Fig.11 Effect of pattern recognition
如图11所示,多数图案可以被正确识别,但仍存在误识别现象,进行30组识别实验,优选后的辅助图案和非优选图案的误检次数如表1所示,可见优选后图案在复杂环境下具有更高的识别率。

表1 图案识别统计表Table 1 Statistical table of pattern recognition
3 基于优选图案的双目Faster Rcnn识别与定位
3.1 基于优选图案的未知目标分类
将融合优选图案的物体置于不同场景环境中,根据优选图案和物体的对应关系,可确定不同场景环境下的物体类别,不同场景环境下的优选图案识别效果如图12所示。

图12 优选图案识别效果Fig.12 Optimized pattern recognition effect
本文提出多种优选图案混合编码方法,增加目标识别类别,根据不同图案的组合列写出编码表。如采用2个图案为一组编码,可扩展为256类物体的标识。图13中,9号和10号优选图案组合表示传真机,1号和6号优选图案组合表示摄像头。

图13 图案组合应用Fig.13 Pattern combination application
3.2 双目Faster Rcnn网络识别与定位方法
本文通过训练深度学习网络,先对目标进行分类,当视觉系统接近目标并能识别其上优选图案标识时,依据优选图案计算目标的准确位置及姿态。
3.2.1 双目Faster Rcnn的目标粗检测
本文通过双目视觉系统,实现对目标三维位置的估算,双目视觉系统左右通道共用一个训练完成的深度学习网络,针对左、右通道图像各自进行一次目标检测,并将检测结果进行匹配,计算其三维位置,图14为本文所用的双目相机实物图。

图14 双目相机Fig.14 Binocular camera
以左通道中机器人的检测框为模板,利用模板匹配在右通道中找到该机器人对应位置,并将该位置与右通道利用深度学习找出的位置框计算重合度,若重合度大于一定阈值,则证明是同一机器人。
3.2.2 优选图案的三维定位
在目标粗检测确定大致位置后,在目标上粘贴优选图案,利用模板匹配和双目视觉原理可得到目标较为精确的三维位置和姿态信息,在机器人表面粘贴2张优选图案。利用霍夫变换提取位置框内的直线,提取得到很多间断的短直线(如图15(a)所示),将距离接近且斜率相似的直线合并,求解出相邻直线的交点坐标,进一步解算图案的中心点坐标(如图15(b)所示)。通过模板匹配,在右通道中找到对应的图案,采用与左通道相同的方法确定出该通道图案中心坐标。
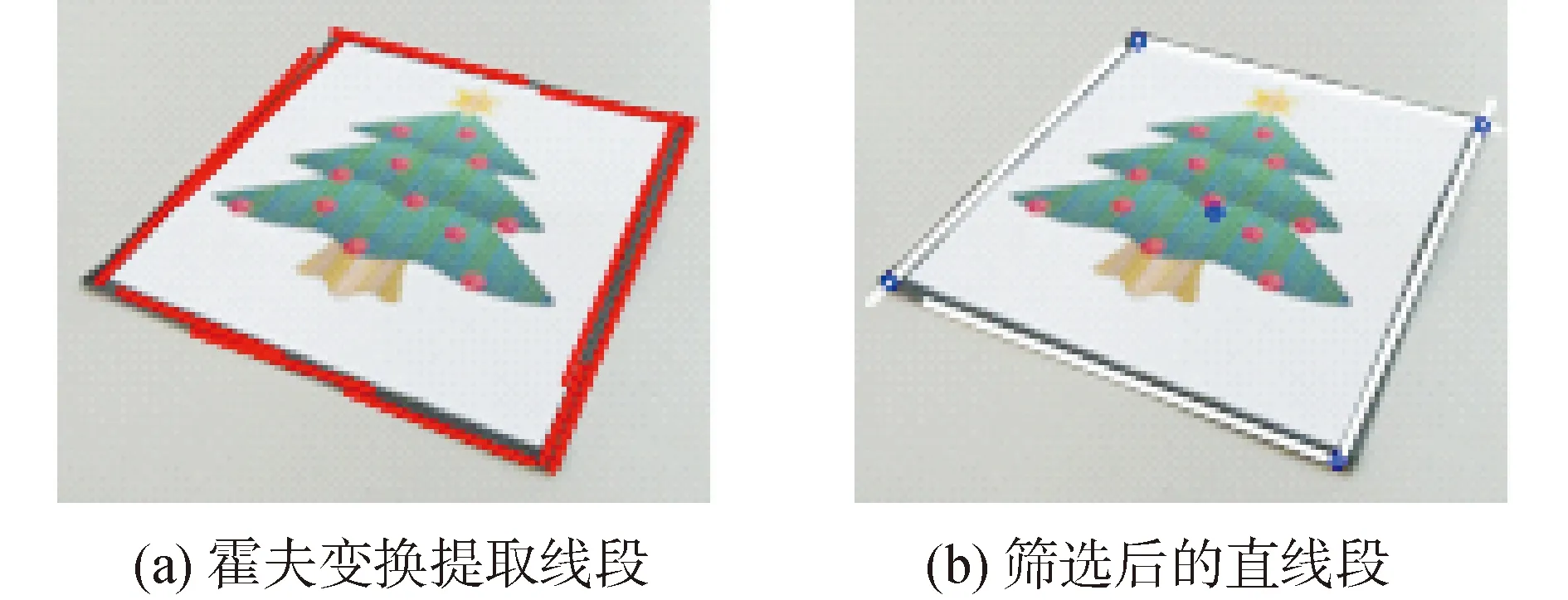
图15 霍夫变换求解过程示意Fig.15 Solution process by Hough Transform
目标姿态角计算原理如图16所示:坐标系原点Og设定于试验房间的墙角处,设2个图案中心点分别为A和B,利用双目视觉原理可以得到A到相机的距离LAD以及B到相机的距离LBE,A、B点到相机连线与水平面夹角分别为θ1和θ2,2个图案中心点AB间的实际距离Dab,通过三维立体几何并利用下式可求解目标姿态角γ:

图16 目标姿态角计算原理图Fig.16 Schematic diagram of calculating attitude angle
(2)
3.3 目标定位试验与分析
本节开展4组机器人处于不同位置和姿态的4种工况的定位试验,选取双目相机和机器人的不同的位置和姿态,试验效果如图17所示的4种工况,统计解算的目标位置和姿态数据,列于表2和表3,本文4种工况的试验数据,在0.6 s之内完成。

图17 不同条件的试验效果Fig.17 Effects of experiment under different conditions

表2 目标位置统计结果Table 2 Statistics results of target positions m
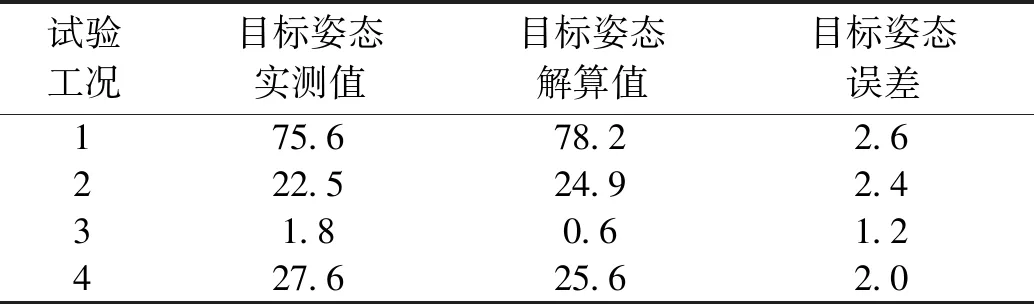
表3 目标姿态解算结果Table 3 Statistics results of target attitudes (°)
从表2和表3中数据可以看出,在本文算法开展的试验中,目标位置偏差的坐标最大值为0.04 m,目标姿态偏差的最大值为2.6°,可见本文算法对目标的定位精度较高。
4 结论
1)通过实际试验验证,本文优选图案的方法,提高了目标的可识别性及其定位精度,同时当系统实现了优选图案集的高精度识别时,图案集可在后续应用中动态被赋予其他含义,与各类未知物体相关联,视觉系统可在无需重新学习的情况下不断扩充其识别范围。
2)本文融合优选图案的深度学习方法的可扩展性强,优选图案策略可进一步形成标准体系,为服务机器人、辅助智能系统的应用提供很好的借鉴意义,将图案识别结果与基于目标本身的识别结果以及其他先验知识相融合,减小外界主观因素的干扰,可极大加速视觉系统的实用过程。
3)本文结合深度学习和双目视觉的方法,可在实现目标有效识别的同时,进一步实现目标的高精度位置和姿态解算。
本文基于优选图案来增强智能系统认知环境的策略,在实用中易受到人为恶意伪造目标的影响,因此在安全性和可靠性要求较高的作业场合下应用受限,作者将在后续研究中,重点解决本文方法在上述环境下应用受限的问题。
