基于深度学习的地铁隧道衬砌病害检测模型优化
2020-07-27薛亚东高健李宜城黄宏伟
薛亚东 ,高健 ,李宜城 ,黄宏伟
(1.同济大学地下建筑与工程系,上海200092;2.同济大学岩土及地下工程教育部重点实验室,上海200092;3.中建丝路建设投资有限公司,陕西西安710000)
城市轨道交通是解决城市交通拥堵问题的有效方式.截至2018 年末,中国内地共有35 个城市开通城市轨道交通,总运营里程达5 766.6 km,排世界首位.城市轨道交通多采用地下隧道建设方式.由于建设条件、运营环境等复杂因素影响,隧道结构,特别是管片衬砌结构,不可避免在运营期间会出现多种病害,如:渗漏水、裂缝、掉块、管片错台、接缝张开、纵向不均匀沉降、管径环向收敛变形等[1-2].其中,较为常见的两种病害为裂缝和渗漏水.为确保隧道结构安全并保障地铁正常运营,传统隧道病害检测方法以人工为主,主要通过人眼或简单仪器检测[3],虽然技术要求低,但检测效果依赖于检测人员的经验与主观判断,检测效率与可靠性均无法满足现代地铁交通发展的需求[4].基于相机拍摄或三维激光扫描的隧道病害检测是发展的技术方向[5],目前已有国内外厂家研制出用于隧道病害检测的专用设备,可以获取隧道病害的图像.如何快速处理数量庞大的图像数据成为亟需解决的新问题.
传统的图像处理算法,如canny 算子、Otsu 算法,以及专门针对裂缝病害检测的算法[6-7]等,由于在实际应用中多依赖于手工调节参数,因此往往效率低,周期长,鲁棒性差,且病害检测准确率难以满足需要.鉴于此,国内外许多学者将深度学习方法应用于病害检测.深度学习(Deep Learning)是机器学习的一种方式,2013 年被麻省理工学院评为十大突破技术之一.深度学习模型在隧道结构病害检测任务上表现出优良的泛化能力和鲁棒性.
2017 年加拿大Cha 等[8]采用深度卷积神经网络对混凝土裂缝的识别进行了研究,在检测中结合滑动窗口可以检测任意大小的图像,并与Canny、Sobel两种边缘检测算子进行比较,验证了深度学习在混凝土裂缝识别上的优势.2017 年黄宏伟等[9]基于全卷积网络进行盾构隧道渗漏水病害图像识别,可有效消除干扰物的影响.2018 年薛亚东等[10]建立隧道衬砌特征图像分类系统,在现有的CNN 模型GoogLeNet 基础上,改进其inception 模块与网络结构,获得了准确率超过95%的网络模型,且对背景复杂条件下的图像处理更具鲁棒性.
已有研究成果表明,采用深度学习方法实现隧道病害检测相比传统图像处理方法高效且稳定,是未来发展的方向.但现有研究所采用的病害检测模型,均未结合隧道病害的特性.隧道结构病害具有其显著特征,如渗漏水有渗流效果,在重力作用下,常常会向下发展,而裂缝由于受力原因,多沿管片结构边缘发展.本文基于自主研制的快速移动式隧道扫描检测系统,采集了上海地铁 1、2、4、7、8、10、12 等线路区间的大量衬砌图像,建立了裂缝及渗漏水病害样本库,并利用K-means 聚类方法,从统计学上分析裂缝及渗漏水特征,基于定量分析结果对病害检测模型及参数进行优化.
1 病害特征
1.1 样本库的建立
深度学习模型训练过程,需从特定样本库中提取数据信息供网络训练学习.深度学习中常用的几类数据集,如 Microsoft COCO、PASCAL VOC、ImageNet、SUN Database 等,这些数据集均由复杂的生活场景中获取,种类多,数量大,具有代表性.然而,在隧道病害检测领域,裂缝和渗漏水有其独特的特征,且目前这一研究领域还未建立成熟的专属于裂缝和渗漏水的病害数据集.
通过自主研发的基于CCD 线阵相机的快速移动式地铁隧道结构病害检测系统(MTI),进行隧道衬砌表面病害图像采集.MTI 系统如图1 所示,由6 台CCD 线阵相机和12 个LED 光源组成,其环向扫描长度可达13 m,可实现高精度衬砌表观图像连续、快速扫描.目前为止,已针对上海市地铁 1、2、4、7、8、10、12 号线等进行了多次检测,采集了大量的隧道衬砌灰度图像.采集后的图像经过人工裁切、标注等一系列处理工作,构成了深度学习模型训练的数据集.

图1 MTI 检测系统Fig.1 Tunnel inspection system
目前整理的数据集包含4 139 张图像,每张图像大小为3 000 像素×3 724 像素.病害检测任务中,需对样本库中每张图片进行标注,标注信息包括两部分:病害类别(裂缝、渗漏水)和位置信息.位置信息的标定采用一个长方形框(边界框,bounding box),长方形框要求完整地包含整个病害,同时要求非病害区域尽可能小.病害边界框采用左上角和右下角的两个坐标进行标定.
用LabelImg 工具完成病害图像标注.在数据集中,一张图像可能包含多个病害的标签图(ground truth).图2 展示了此类标签的部分示例.共得到5 496 组裂缝和渗漏水病害的ground truth 信息,其中裂缝2 946 组、渗漏水2 550 组.据经验,样本库中的4 139 张图片,3 000 张用于训练样本,其余的1 139 张作为测试样本.

图2 样本标柱示例Fig.2 Labeled defects samples
1.2 样本库特征分析
隧道衬砌裂缝和渗漏水与其它类型目标相比有其特定特征.为分析病害特征,首先针对样本库中的所有图片做定性分析,并基于病害标记得到的ground truth 信息对病害进行定量分析.图3 为采集的部分裂缝及渗漏水病害示例图.
首先对裂缝及渗漏水病害的尺度特征进行分析.经统计,裂缝及渗漏水标记的ground truth 面积(像素)分布结果见表1.其中,83.0%的病害面积处于(0,1× 106)区间内.裂缝和渗漏水面积在区间(0,1×106)上的分布如图4 所示,大致呈对数正态分布.病害面积处于区间(0,4× 105)的约占(0,1× 106)区间的67%.
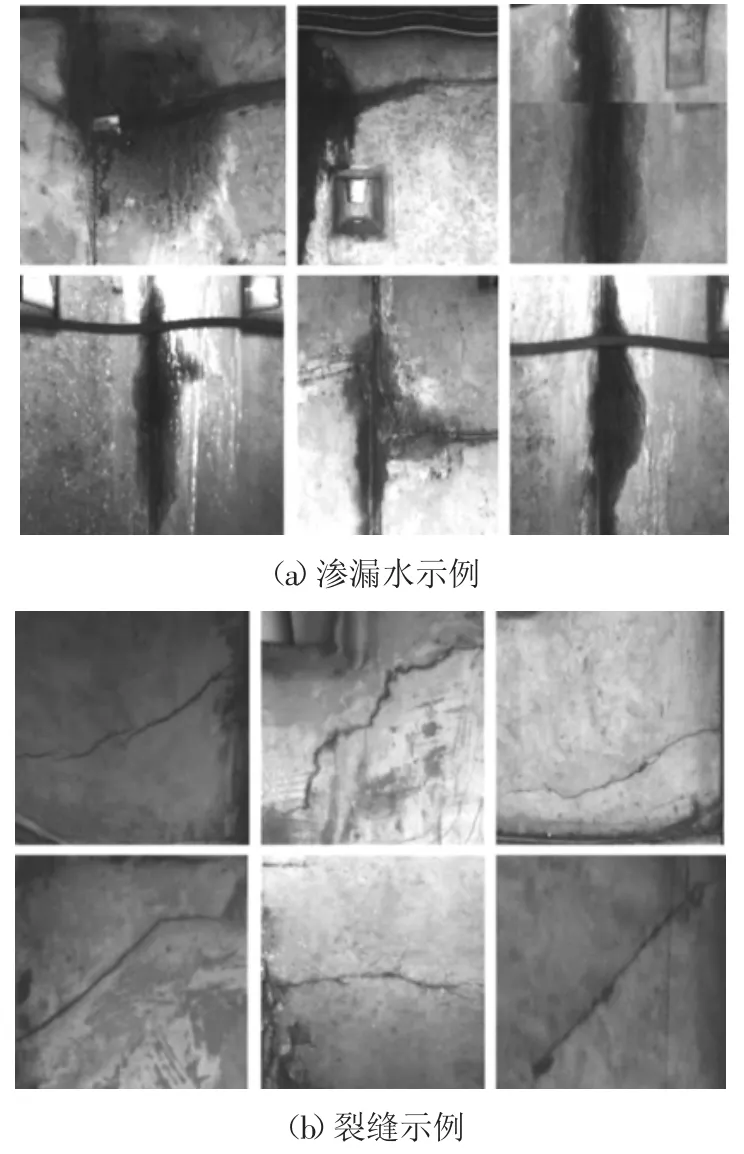
图3 病害样本示例Fig.3 Samples of defects

表1 裂缝与渗漏水面积统计分布Tab.1 Statistical of area of cracks and seepage

图4 (0,1×106)区间裂缝与渗漏水面积分布图Fig.4 (0,1 × 106)area distribution of cracks and water leakage
裂缝和渗漏水分别统计:2 946 个裂缝面积全部处于(0,4×106)区间内,其中约90%的裂缝处于(0,3× 105)区间内(表2);2 550 个渗漏水面积处于(0,8×106)区间内,其分布直方图见图5.渗漏水面积主要分布于(0,3 × 106)区间内,其中区间(0,1 ×106)内渗漏水占 64.2%,(1 × 106,2 × 106)区间内渗漏水占22.0%.

表2 裂缝面积统计Tab.2 Statistical of area of cracks
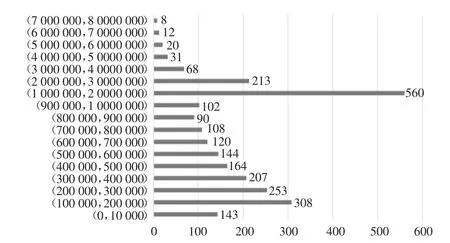
图5 渗漏水面积分布直方图Fig.5 Histogram of the area distribution of water leakage
高宽比同样是裂缝及渗漏水的重要特征之一.对样本集中裂缝及渗漏水的高宽比进行统计,处于(0,1)区间内的病害居多,大于10 的病害占比较小(图6).图7 为(0,1)区间内病害分布直方图,可知整个区间内病害高宽比分布较均匀,区间两端的病害占比较小.由此可以得出,隧道衬砌病害相比生活中的常见物体,其几何表现相对细长,后续分析中将考虑病害的几何特征与分布规律.

图6 裂缝与渗漏水高宽比分布直方图Fig.6 Histogram of defects aspect ratio distribution
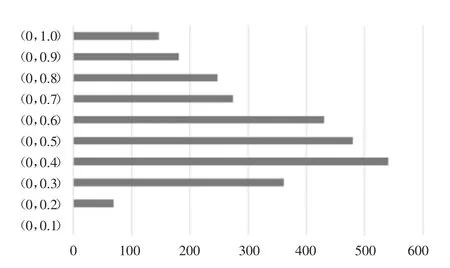
图7 (0,1)区间内裂缝与渗漏水高宽比分布直方图Fig.7 Histogram of defects aspect ratio distribution with in(0,1)
2 模型构成
2.1 Faster R-CNN 模型
在病害检测任务上,输入图像为完整的大尺度图像,文中采用的图片大小为3 000×3 724 像素.RCNN[11]系列算法核心思想是基于建议区域在整张图片上检测,选择可能为病害区域的候选框,进而通过卷积神经网络(Convolutional Neural Network,CNN)对每个区域提取特征,并利用分类器预测此区域中包含感兴趣对象的置信度,将问题转化为图像分类问题.
Faster R-CNN[12]模型可分为两部分.一部分为骨干结构(backbone architecture),另一部分为头结构(head architecture).骨干结构负责对整张图像进行处理,获得其特征图像(feature maps);头结构处理特征图像,获得候选区域并进行分类和定位.
如图8 所示,首先将整张图片送入CNN,进行特征提取,在最后一层卷积层生成卷积特征图,在此之后增加两个额外的卷积层,构造区域建议网络(RPN,Region Proposal Network);RPN 网络可直接预测出候选区域建议框,候选框数量限定为300 个.Faster R-CNN 是 RPN 和 Fast R-CNN 相结合的结构,同时共享了RPN 和Fast R-CNN 卷积层的参数,支持端到端的训练.
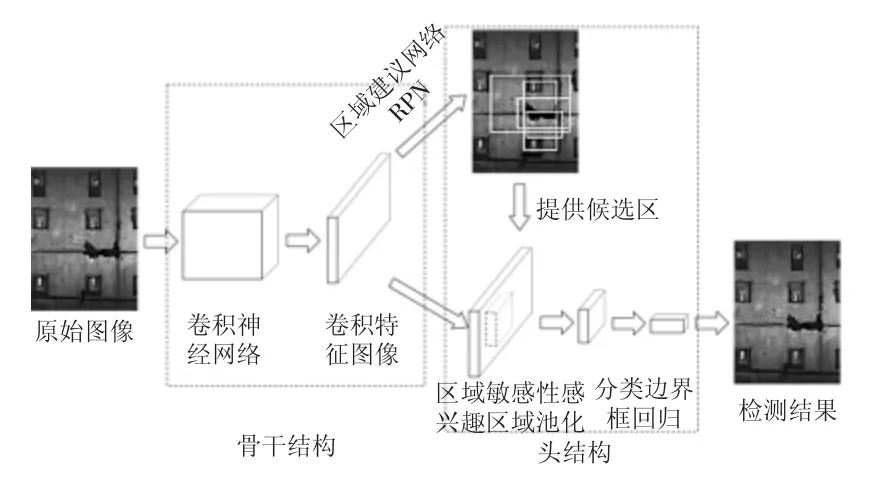
图8 Faster-R-CNN 模型结构示意图Fig.8 Flow chart of the Faster-R-CNN model
2.2 区域建议网络及Anchor Box
区域建议网络是预测目标建议区域候选框的一种方法,它可以接受任意大小的图像作为输入,输出一系列的矩形候选框,每一个候选框都附带一个目标得分(object score),目标得分的大小反映了每个矩形候选框中涵盖的内容属于检测目标的概率.通过设定某一目标得分阈值,可获得一定数量的矩形候选框.
要处理的图像首先经过卷积神经网络骨干结构,运算得到卷积特征图像,其大小和维度为p×q×n,其中p、q 分别为卷积特征图像的高和宽,n 为卷积特征图像的维度,如图9 所示.
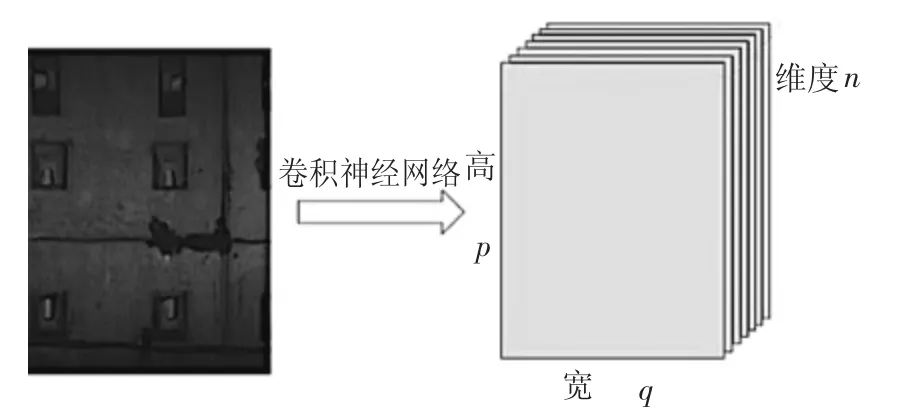
图9 深度卷积特征的提取Fig.9 Deep convolution feature extraction
在提取的卷积特征图像上,采用一个矩形图框(anchor box,图10)进行滑动完成目标检测.anchor box 包含两个属性,高宽比和尺度,它们决定了anchor box 的个数.对于n 维的卷积特征图像,k 个不同的anchor box,每一次滑动都会产生k 个n 维的低维向量(图10).
He 等[12]在Faster R-CNN 物体检测模型中给出了建议的9 类anchor box.其中,包含3 类不同大小的尺度(1282,2562,5122),和 3 类不同的高宽比(1 ∶1,1 ∶2,2 ∶1).anchor box 参数设置受检测目标特征影响,并对后续的分类和回归两个过程的计算精度及速度均有一定影响.本文的处理对象主要针对隧道衬砌表面病害,即裂缝和渗漏水.由前文分析结果可知,病害样本库中病害的形态与尺寸具有统计特征,可以据此改进模型以提升效果.
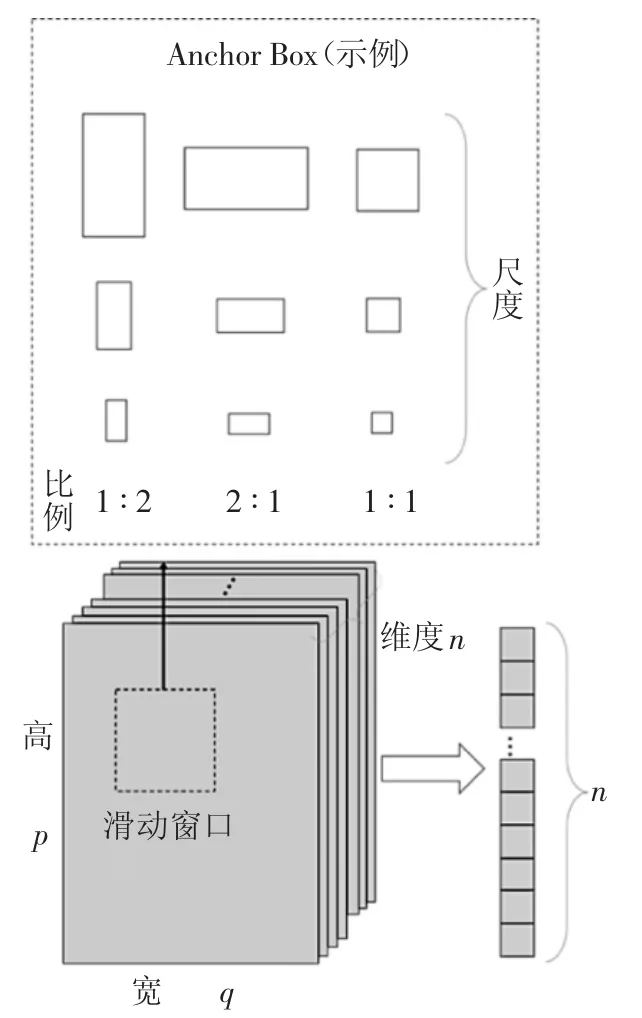
图10 区域建议网络的anchor boxFig.10 anchor box of RPN
3 模型改进
3.1 区域建议网络与anchor box
区域建议网络的任务包含两部分,前景或背景的分类以及边界框的回归.如图11 所示,虚线矩形框代表一个前景目标的anchor box,实线矩形框代表目标的真实值,边界框回归处理即是寻找一种映射关系,使得anchor box 与真实窗口尽量接近.

图11 前景目标的anchor box 和真实值Fig.11 Ground truth and anchor box
用 A =(xa,ya,wa,ha)表示 anchor box,其中的 x,y,w 和h 分别表示矩形框中心点坐标与框的宽和高.用 G=(x*,y*,w*,h*)表示前景目标的真实值,则映射为f(xa,ya,wa,ha)=(x*,y*,w*,h*).将anchor box 的窗口变换为目标的真实窗口,其变换方式为平移和缩放.
将anchor box 的中心点平移至目标真实窗口的中心点,其变换公式见式(1)和式(2),其中dx(A)和dy(A)为横纵坐标相应的平移变换.

将anchor box 的宽和高进行缩放,使其与真实值相同,其变换公式见式(3)和式(4),其中dw(A)和dh(A)分别为宽和高相应的缩放变换.

由公式(1)~(4)可知,边界框回归的过程中,需要学习的是dx(A),dy(A),dw(A),dh(A)4 个变换.当anchor box 和目标的真实值相差较小时,可以认为是一种线性变换.通过上述公式,可以获得边界框回归的平移量 tx、ty和尺度因子 tw、th,其计算公式见式(5)至式(8).
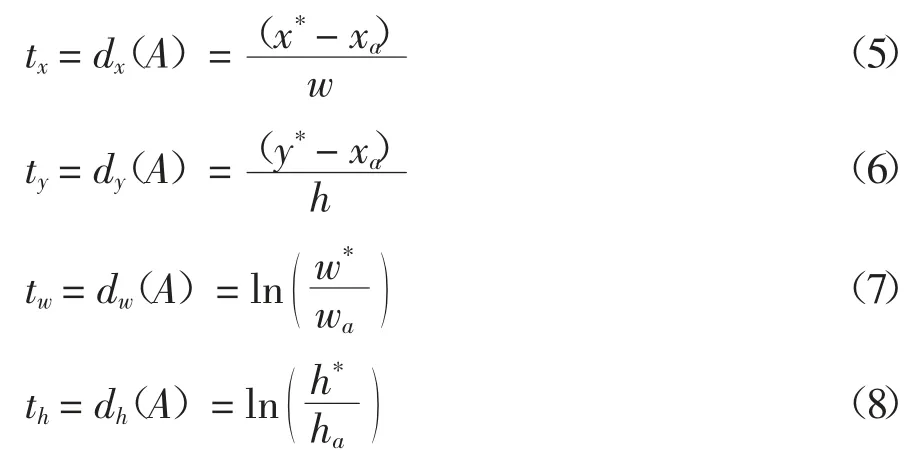
上述平移量和尺度因子作为区域建议网络中边界框回归损失函数的参数.
对于边界框的回归,其损失函数如式(9)所示.
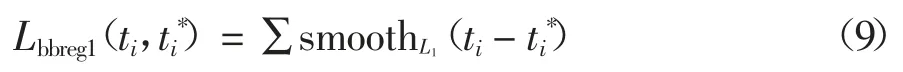
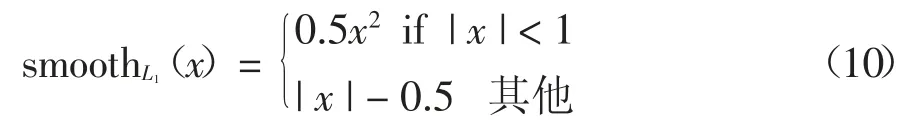
其中 x,y,w,h 分别为矩形区域中心的横纵坐标、宽及高.变量x,xa,x*分别指网络预测的边界框、anchor box 的边界框、目标的真实边界框(y,w,h 类同)的 x 坐标.
若anchor box 的边界框与目标的真实边界框越接近,即 wa、ha与 w*、h*的值相差越小,由公式(7)(8)可知,尺度因子tw、th趋近于0,损失函数会更小,说明拟合程度也越好.
3.2 anchor box 尺度参数修正
根据前文对裂缝、渗漏水样本库的定量分析可知,裂缝及渗漏水病害面积分布基本可由三个区间覆盖,分别为(0,4×105)、(4×105,1×106)、(1×106,8×106).由此,可以得到病害面积所处量级的主要分布区间.
通常图像检测所用数据集的图片比病害数据库中图片(像素)要小得多,如PASCAL VOC 数据集中,图片的像素尺寸大小不一,尺寸大约在512×512,像素偏差不超过100.因此,在做病害检测前,需根据病害数据库中的图片信息,对图像检测模型中的anchor box 尺度这一参数作出修正,由原先的(1282,2562,5122)修正为(5122,1 0242,2 0482),分别与前文所述的三个区间相对应.为验证参数修正的准确性及有效性,下文通过控制变量的试验方法进行模型试验.
3.3 anchor box 比例值修正
采用K-means 聚类算法,基于裂缝及渗漏水病害的高宽比数据库进行聚类分析,以聚类结果为基础对病害检测模型中的anchor box 比例值进行修正.
K-means 算法[13]属于硬聚类算法,它是根据数据类别中心的目标函数进行聚类,其中,目标函数是数据点到类别中心广义距离和的优化函数.
对于给定的一个包含n 个d 维数据点的数据集X = {x1,x2,…,xi,…,xn},其中 xi∈Rd,假定聚类数目为K,需将所有数据对象划分为K 个独立子集C={ck},k=1,2,…,K.每个子集 ck有一个类别中心 μk.通常情况下,选取欧氏距离作为相似性和距离判断准则,计算类内各点到 μk的距离平方和 J(ck):

聚类目标是各类总的距离平方和J(C)最小.
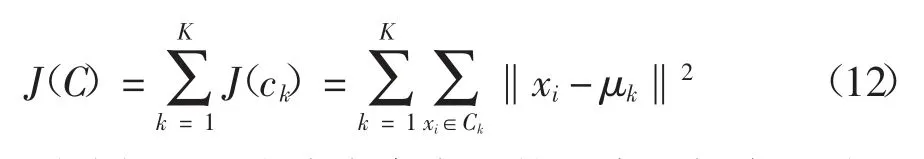
裂缝与渗漏水病害高宽比的聚类分析中,关注病害的高、宽两个维度,聚类结果与anchor box 框的大小无关,而与滑动窗口的对应区域和前景目标真实值的图形交并比(Intersection-over-Union,IoU)有关,不能简单采用欧氏距离作为聚类分析相似性和距离判断准则.
IoU 为两个图像的交集和并集之间的比例,即IoU=A∩B/A∪B,如图12 所示.

图12 图形的交并比Fig.12 Intersection-over-Union
在模型训练过程中,区域建议网络根据IoU,将anchor box 获得的样本分为三类:当图IoU 大于0.7时,标记为正样本;小于0.3 时,标记为负样本;介于两者之间时,标记为无效样本.在训练过程中正样本和负样本均参与训练,无效样本不参与训练.
为选取具有高IoU 得分的目标框,采用如下距离度量:
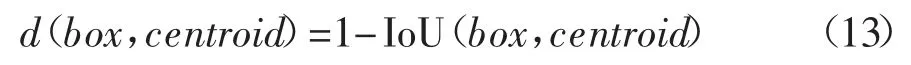
为合理确定K-means 聚类的K 值,提出使用簇内误方差(sum of the squared errors,SSE)[14]作为聚类分析的目标函数,其计算公式见式(14).

其中:Ci表示第 i 个簇;p 是 Ci中的样本点;mi是 Ci的质心(Ci中所有样本的均值);SSE 是所有样本的聚类误差,代表了聚类效果的好坏.随着聚类数K 的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,误差平方和SSE 逐渐变小.
对裂缝与渗漏水病害高宽比数据集进行聚类分析,以 SSE 作为聚类分析的目标函数,K 值取(1,9),得到SSE 和K 的关系图见图13.由图13 可知,转折点对应的K 值为3,即K=3 时更接近真实聚类数.因此,聚类分析时取K=3,从统计学上得到3 种更接近病害目标真实值的高宽比:ha/wa.
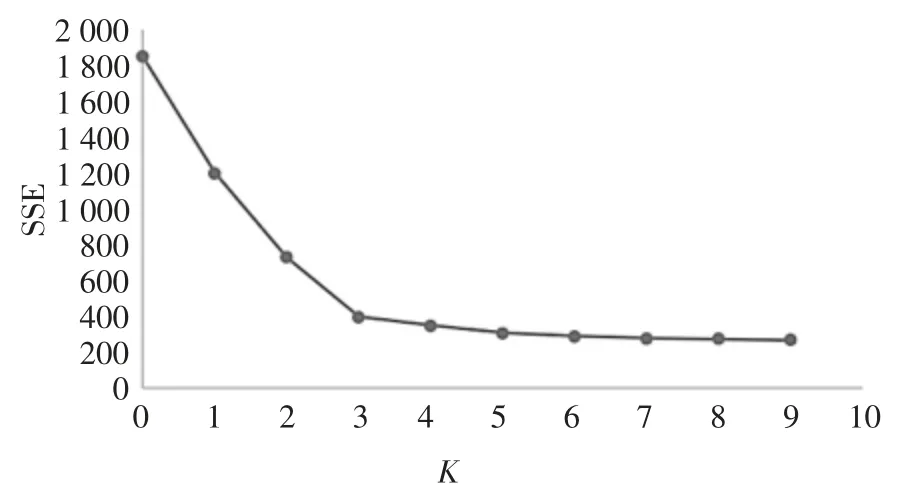
图13 病害高宽比数据集SSE-K 曲线图Fig.13 Curve of SSE vs K
距离度量采用式(13),则各点到聚类中心的距离平方和具有如下关系:
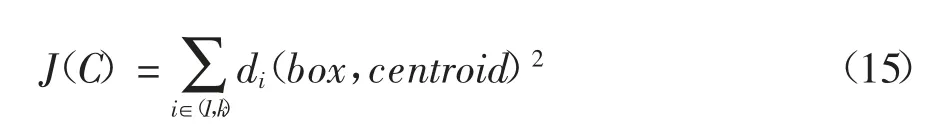
聚类目标是使各类总的距离平方和J(C)最小,K-means 聚类算法如图14 所示.

图14 K-means 聚类算法Fig.14 K-means clustering algorithm
基于标记得到2 946 组裂缝和2 550 组渗漏水病害的ground truth 信息,采用K-means 聚类算法进行聚类分析.
采用两种聚类方案.一种是对训练样本中的裂缝和渗漏水数据分别聚类分析,另一种是对训练样本中的裂缝和渗漏水同时进行聚类,即由5 496 组裂缝及渗漏水数据聚类分析得到接近两种病害目标真实值的anchor box.聚类分析结果见表3.
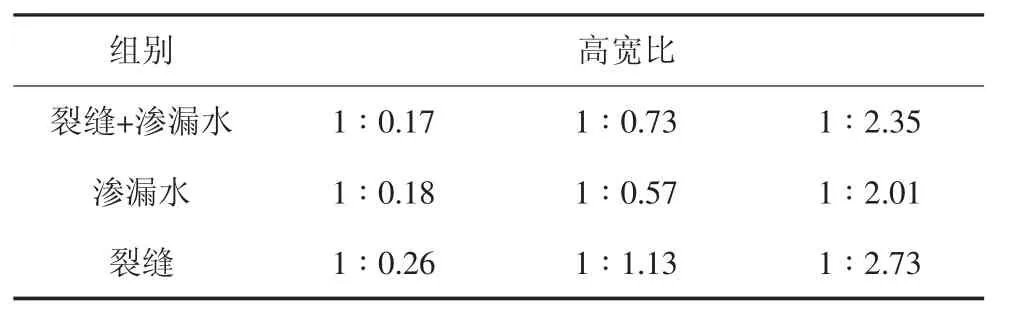
表3 聚类分析结果Tab.3 Cluster results
4 深度学习软硬件配置
4.1 深度学习硬件配置
本研究的深度学习硬件配置为:
核心处理器:Intel Core i7-5820K CPU;
图形处理器:三块GeForce GTX 1080,每块显卡的显存8 GB,总共24 GB;内存:64 GB.
4.2 深度学习软件配置
深度学习的软件环境配置为:编程语言python2.7.12、并行计算架构 CUDA8.0、基于 GPU 的加速库cuDNN5.0 和深度学习框架Caffe[15].
5 病害检测实验设计与模型训练
5.1 实验设计
实验设计主要考虑两个方面:一是评价利用K means 聚类算法对anchor box 参数的修正对检测效果的影响;一是考虑裂缝与渗漏水几何形态特征差别较大,将裂缝和渗漏水分别独立建立样本库,比较分析混合训练与独立训练的利弊.共设计了6 类不同的检测模型方案,(见表4).

表4 检测模型方案Tab.4 Test models
5.2 训练方法
本文所用的模型采用两条计算路线,骨干结构卷积层内的卷积核在不同的计算路线上可能存在不同损失函数梯度方向,导致无法共享网络权重.在模型的训练中,采用交替训练方法,即先训练区域建议网络,而后用区域建议网络得到的候选区域训练病害检测方法,并交替训练,不断迭代.
在病害检测模型训练中,使用已训练好的卷积神经网络模型对骨干结构进行权重初始化.模型迭代训练过程中采用动态学习率策略.优化采用随机梯度下降算法.
5.3 模型评价标准
5.3.1 检测结果的评价
检测率(detection rate):表示测试集中检测得到的正确结果数量和实际的结果数量的比值.在最终的结果检测中,设定0.8 作为阈值,当检测结果得分超过阈值则输出该检测结果.
检测准确度(detection accuracy):表示病害检测结果得分的平均值.检测准确度反应了该方法的识别能力.
5.3.2 检测效率的评价
训练时间(training time):表示检测模型整个训练过程所用的时间.
检测效率(detection efficiency):指检测每张图像需要花费的时间.
5.4 模型检测结果
模型训练完成后,对测试数据集上含有裂缝和渗漏水的目标进行检测.测试集包含1 139 幅图像,其中病害目标共有1 867 个.表5 是Model1~Model6各模型的训练测试过程中各指标的结果对比.
图16 展示了部分病害检测结果(矩形框).
由Model1&2 检测结果对比可知,优化后的VGG16 网络在同一数据集上的准确率为80.91%,高于优化前的VGG16(75.81%),提升了6.73%.此外,训练时间缩短了10 min,平均单张图片测试时间也有略微缩短,一定程度上加快了检测效率.
由Model2&4&6 检测结果对比可知,优化后的裂缝检测模型对裂缝平均检测率为77.28%,优化后的渗漏水检测模型对渗漏水平均检测率为85.25%,与同时进行裂缝和渗漏水检测的模型(分别为71.8%,84.28%)相比较均有提升.
Model1&5、Model2&6 的检测结果对比,渗漏水和裂缝单一检测模型较两种病害同时检测的模型检测率更高,效果更佳.因此如果工程对检测准确度要求很高时,可以考虑对裂缝和渗漏水分别独立检测.这一方案的不足之处在于需要训练两个模型,会增加一定时间成本.

表5 各模型训练测试结果Tab.5 Model training and test results

图16 检测结果示意图Fig.16 Examples of defects detection
5.5 模型鲁棒性检验
鲁棒性和适应性代表了模型的泛化能力.为了验证本文模型的泛化能力,对衬砌图像做出如下处理:病害位置的变化、病害尺度的变化、病害图像的高斯模糊以及病害的不规则变形.
在图17 所示的图像中,图像大小均为3 000 ×3 724 像素,包含了两条裂缝,通过提取不同裂缝病害位置的图像进行验证.结果表明,无论病害位置如何移动,本方法均可正确检测.

图17 不同位置病害检测结果Fig.17 Detection results with different defects location
在图18 所示的图像中,图像大小经过了不同尺度的图像变换,图像大小从左到右分别为3 000 ×3 724 像素、1 700 × 2 000 像素、1 200 × 1 450 像素,每张图像含有一处相同的渗漏水病害.检测结果表明,在不同尺度的图像中,本方法均可正确检测,同时其检测率均较高.

图18 不同尺度病害检测结果Fig.18 Detection results with different defects size
在图19 所示的图像中,对图像进行高斯模糊处理,图像从左到右模糊半径分别为0、5、8.可以发现,每张图像都包括了两条裂缝,一条裂缝宽度较宽,相对明显,另一条裂缝宽度较窄,相对模糊.经过模糊半径为5 的高斯模糊后,窄裂缝几乎肉眼难以分辨,本方法仍然可以将其检测出来,而经过模糊半径为8 的高斯模糊后,本方法仅检测出一条裂缝.检测结果表明,在相对模糊图像中,本方法具有良好的适应性.

图19 高斯模糊图像的病害检测结果Fig.19 Detection results of Gaussian Blur images
在图20 所示的图像中,图像从左到右分别为原始图像,纵向拉伸图像和横向拉伸图像,从视觉效果上看,经过变形的病害特征图像具备了不同的形态特征,对于本方法,均可正确检测.检测结果表明,对于不规则变形的图像,本方法具有良好的适应性.

图20 横纵向变形图像的病害检测结果Fig.20 Detection results with different aspect ratio
5 结 论
本文利用快速检测盾构隧道衬砌病害的深度学习方法,在现有的卷积神经网络物体检测模型VGG-16 基础上对模型进行修正,根据手动建立的裂缝、渗漏水病害数据集,并设计了6 种不同试验条件下的Faster R-CNN 检测模型,分别进行病害检测计算,以此验证模型参数修正的正确性与必要性,并对模型的鲁棒性进行验证.得出结论如下:
1)在现有Faster R-CNN 检测模型基础上进行修正,并对修正后模型的有效性、准确性和训练难易程度进行了评估;通过控制变量法,对3 组参数修正前后的模型检测结果进行比较.结果表明参数修正后的模型检测准确度有明显提升.
2)通过对不同检测模型计算结果对比分析得出,裂缝和渗漏水的单一检测模型比同时检测两种病害的模型准确度更高,但会增加一定时间成本.
3)此外,本文计算所采用的数据集仅有4 139 张图片,图片数量略少,参数修正后对隧道衬砌病害的检测效果仍不能真正达到高准确度,仅有80.91%.可以考虑扩充病害数据库,增加模型的鲁棒性及准确度.
