结合知识图谱与双向长短时记忆网络的小麦条锈病预测
2020-07-25张善文王祖良
张善文,王 振,王祖良
(西京学院信息工程学院,西安 710123)
0 引 言
小麦条锈病严重影响了小麦的产量与质量,进行病害预测是病害防治的关键步骤。小麦条锈病是小麦病害中最容易发生、且发生范围广、影响较为严重的一种病害,其发生和发展与冬季温度、初春降水量、土壤温度和湿度等很多环境因素关系密切相关[1-2]。目前,有很多基于环境信息的小麦条锈病预测方法。张雪雪等[3]归纳和总结了作物病虫害预测模型,并对后续研究的关键问题和预测技术发展趋势进行了描述;陈万权等[4]分析了中国小麦条锈病的发生规律和原因,为作物病害预测提供了依据;聂臣巍[5]构建了一种基于贝叶斯网络模型的小麦条锈病预测方法,并在甘肃省东南部地区的2010-2012年的小麦条锈病数据库上进行验证,结果表明在小麦返青期至乳熟期的条锈病、白粉病、赤霉病和纹枯病的发生概率分别为62.92%、63.18%、79.48%和94.75%;刘伟昌[6]提出了基于灰色关联分析和模糊数学的小麦锈病发生模型,该模型对4月上旬及5月中旬小麦条锈病的预测结果与实际值吻合度达到 93.72%;姚晓红等[7]提出一种基于统计学方法的小麦条锈病的预测模型,其最高预测准确率为91%;Wang等[8]利用反向传播网络与不同的转移函数、训练函数和学习函数、径向基网络、广义回归网络和概率神经网络进行了小麦条锈病预测方法研究,结果表明,基于径向基网络的预测结果最好,预测率准确率为91%;李登科等[9]利用小麦条锈病发生的程度与气象条件的关系,预测小麦条锈病,在关中和陕南地区的最高预测率准确率分别为79.2%和82.8%。实际小麦病害预测数据来源于小麦生长的环境因子、农业类科研机构和企业的数据库、以及从农业类网站中抓取的大量小麦病害文本数据[10-11]。这些数据是海量、多源、异构、含噪声、冗余度大,且结构化、非结构化和半结构化并存的数据。由于上述传统的病害检测和预测方法没有充分利用这些数据之间相互联系和相互制约,所以实际预测准确率较低[12-13]。
如何从海量复杂的小麦病害相关大数据中提取有用的作物病害知识,是病害预测系统的关键问题[14]。知识图谱(Knowledge Graph,KG)能够从海量多源异构数据中抽取结构化知识[15-17],能够描述现实世界中存在的实体以及实体之间的关系[18],已被成功应用于智慧农业领域[19-20]。Liu等[21]从知识表示、提取、融合和推理4个方面分析了当前病虫害知识的构建方法,介绍了作物病害KG在专家系统、搜索引擎和知识问答系统中的应用,总结了作物病害KG中存在的问题和面临的挑战;王娟[22]采用案例推理方法构建了一个烟草病害防控模型,并在案例检索过程中结合 KG的思想,提高了病害检索的效率;夏迎春[23]开发了一种基于知识表示的农业病虫害知识问答系统,该系统包括知识问答模块以及作物病害KG展示模块,取得了较好的效果。
在大数据的推动下,深度学习已被成功应用于小麦病害预测中[24]。长短时记忆神经网络(Long Short-Term Memory, LSTM)是一种时间递归深度学习网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件[25-27]。LSTM 为解决作物病害预测问题提供了新的思路。Xiao等[28]利用Aprioro算法得到了天气因素与棉花害虫发生的关联规律,提出了一种基于LSTM的棉田病虫害预测方法,验证了LSTM网络在解决农作物病虫害预测问题上具有很大的优势。KG与LSTM结合能够发挥各自强大的优势[29]。为了提高小麦条锈病的预测准确率,本文提出了一种基于KG和双向长短时记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)结合的小麦条锈病预测方法,该方法利用KG能够将与病害相关的多源异构环境数据转化为低维连续的向量,保存KG中的语义信息,从而得到实体的向量表示,然后利用 Bi-LSTM 提取病害预测的深层次特征,最后利用大量观测样本对所提出的方法进行试验验证,以期为小麦条锈病预测系统提供参考。
1 材料与方法
1.1 数据与预处理
关中地区条锈病春季平均始见期时间为2月4日,最晚为5月21日,数据采集约为140d,采集地点依次为宝鸡、西安、咸阳、渭南等地。小麦条锈病相关资料来自陕西省植物保护总站,采集陕西省关中地区各市2010-2017年小麦条锈病的环境信息;气象资料来自陕西省气象信息中心,采集2010-2017年陕西省8个市气象站上年10月-第二年 5月气温、降水量、相对湿度等资料,各个单项数据项为 5 d采集的数据平均值作为小麦种植区气象资料序列。为了能够精准预测,选择与小麦条锈病发生影响最大的因素进行试验,包括土壤的最低湿度、最高湿度、平均湿度和温度、空气最低湿度、最高湿度、平均湿度、平均温度、雨日、降雨量、光照日数、平均风速、平均风向、平均风力、最低蒸发量、最高蒸发量、平均蒸发量等用于构建小麦条锈病KG。该KG由2010-2017年的小麦条锈病的相关数据抽取而成。共取得60 000个实体。
除了以上实际数据外,利用Python编程语言编写的语料采集工具从中国农业信息网、兴农网、蔬菜网以及百度百科等多个语料库中抓取关于小麦条锈病的 300个词条作为语料,并将这些语料使用GBK编码的形式进行文本文件存储。由于直接获取的词条为非结构化文本,难以直接对其数据进行利用。因此使用自然语言处理的开源工具 LTP中的使用分词、词性标注和依存句法这3个模块对语料进行预处理,得到的结果以标注文件XML的格式进行存储。
在KG构建过程中,使用一种上下混合模式的构建方法。该方法融合了自底向上和自顶向下 2种构建方式,通过不断迭代优化,最终生成满足要求的领域知识图谱。对于 KG模式层设计不仅采用通常的自顶向下的构建方法,而且与自底向上的构建方法相融合,形成一种自顶向下为主,自底向上为辅的优势互补的构建过程。所构建小麦病害KG其基本元素为气候因素、发病原因、治理方案、发病症状、发病地区、传播途径和相关数据等,具体包含60 000个实体,从中抽取出86 500条具体的实体关系,知识实体关系图谱示例如图1所示。
1.2 小麦条锈病知识图谱构建
小麦病害KG是根据小麦病害实体、实体间关系相互连接起来所形成的一种网络结构。三元组是KG的一种通用表示形式,可将KG中的每一条小麦病害知识直观表示为<头实体,关系,尾实体>。小麦病害实体(头实体或尾实体)作为KG中最基本的元素,主要由病害、环境信息、症状、防治手段、部位等构成;关系存在于不同的头实体或尾实体之间,主要包含类别、病害表现、病因、发病原理、预防措施、农药作用等。小麦条锈病KG构建过程:首先对病害检测知识和元数据知识进行表达,以实体联系方式将病害检测知识和元数据知识进行有效组织和管理;然后利用病害知识和元数据进行本体层构建与实体层构建,包含数据获取与处理(清洗、融合等)、本体层构建、实体层构建等过程;最后构建 KG。图 2a为小麦条锈病KG构建流程图,图2b为构建的KG的一个实体实例。
本文通过动态映射矩阵嵌入到模型学习 KG中实体和关系的低维特征向量。其过程描述为:首先将实体和关系映射到不同的空间中,为每个实体和关系定义两个向量,一个表征实体或关系,另一个用来构造动态映射矩阵;然后利用词向量计算工具word2vec将每个三元组中的头实体、尾实体和关系转换为低维特征向量,三元组中的关系是从实体集的头实体到实体尾实体的语义表达。设头实体、关系和尾实体的向量分别表示为h、r和t,通过不断调整h、r和t,使(h+r)尽可能与t相等,即h+r≈t;最后通过使用2个投影矩阵Mrh和Mrt将头实体h和尾实体t分别投影到关系空间,并将每个关系的投影矩阵分解为两个向量的乘积,得到得分函数:
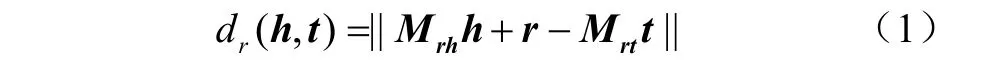
式中 Mrh=+ Im*n和 Mrt= rptp+与实体和关系均相关,通过向量运算转换,rp、tp和hp都是映射向量,Im*n是单位矩阵,dr(h,t)为约束对实体和关系建模。
基于动态映射矩阵嵌入模型的 KG的知识嵌入过程如图 3所示。首先提取小麦条锈病描述文本中的病害特征词;然后构建KG;再将KG中的知识转化为低维连续的特征向量;最后将病害特征向量与相关知识实体进行匹配,根据得分函数获取关联程度,并进行排序。图 3中,最后得到的结果是由式(1)得到的病害特征向量与实体之间的关联性概率。
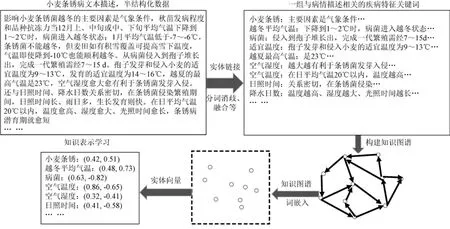
图3 小麦条锈病KG的知识嵌入过程Fig.3 Knowledge embedding process of wheat stripe rust KG
1.3 LSTM和Bi-LSTM网络
LSTM由sigmoid神经网络层和成对乘法操作组成,通过门控单元可以对单元添加和删除信息,通过 3个控制门(输入门、遗忘门和输出门)控制不同时刻的状态和输出,有选择地决定信息是否通过。其单元结构如图4所示。
在图4中,A表示sigmoid神经网络层,圆形操作框⊗代表点积运算、⊕代表求和运算,相同维数的两个向量经过圆形操作框后,乘以或相加相应的元素,正方形的节点代表“激活操作”,有2种激活方式:σ函数和tanh双曲正切函数。若两条线在箭头方向上融合在一起,它们就简单地堆叠在一起;若一行被分成 2行,它们会被复制到相同的两行中。
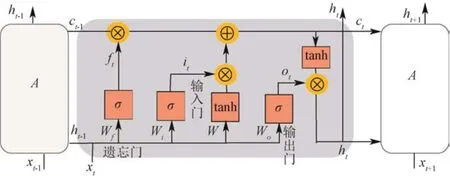
图4 LSTM的单元结构Fig.4 Cell structure of LSTM
LSTM能够避免长期依赖问题,但可能丢失很多与病害预测相关的信息。双向LSTM(Bi-LSTM)能够利用过去的若干输入和后面若干输入进行预测,该模型不仅解决了长期依赖问题,而且能够以正向LSTM与反向LSTM方式提取序列数据特征,实现时间序列的长期记忆,得到的预测结果比 LSTM更加准确。由于作物病害预测只能以当前环境因子和过去一段时间的环境因子预测当前时刻的作物病害发生的概率,所以采用Bi-LSTM模型能够提取与作物病害相关的环境因子特征,进行小麦病害预测。设在时刻t经过前向LSTM和后向LSTM后得到前向输出和后向输出,合并记为ht=[]作为该隐含层的输出,则环境因子与小麦病害发生的关系概率可以表示为
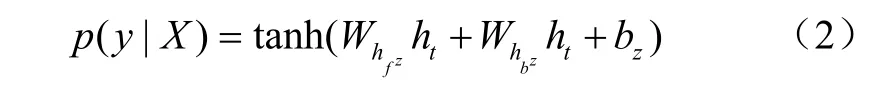
式中X为输入数据,y为病害类型,双曲正切函数tanh作为激励函数,Whz和Whz为 Bi-LSTM 的权值,bz为Bi-LSTM的偏差,权值和偏差都为待训练的参数。
为了防止训练模型产生过拟合,在Bi-LSTM中的非循环部分加入dropout。通过反向传播算法优化交叉熵损失函数L(θ):
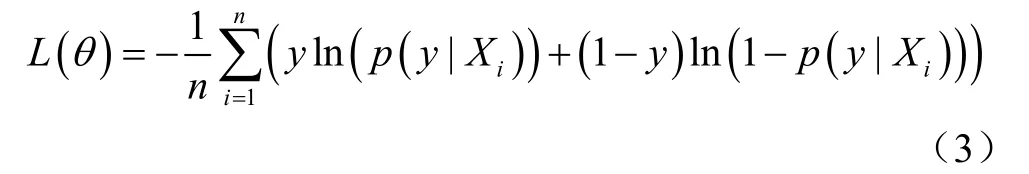
式中θ为模型参数,Xi为第i个训练样本,y为病害类型,n为训练样本数。
1.4 小麦条锈病预测方法
针对“小麦条锈病发生因素多、复杂、随时间变化”特性,提出一种基于KG和Bi-LSTM相结合的小麦条锈病预测模型。其模型结构如图5所示。
首先,利用词向量计算工具word2vec将每个KG中的每个三元组中的实体和关系转换为低维特征向量;
第二,将得到的向量作为Bi-LSTM的输入,提取作物病害环境因子特征;
第三,利用注意力机制对提取的特征进行特征融合。注意力层对Bi-LSTM提取的特征进行加权变换,突出重要病害相关数据的贡献,提高模型预测的准确性。其计算过程为

式中 H ={h1,h2,...,hn}表示 Bi-LSTM 生成的特征向量序列,w为训练学习的参数向量,M、a和r′分别为激励后的融合特征向量、注意力矩阵和与环境信息中特定属性高度相关的特征向量, H*表示变换后的特征向量。
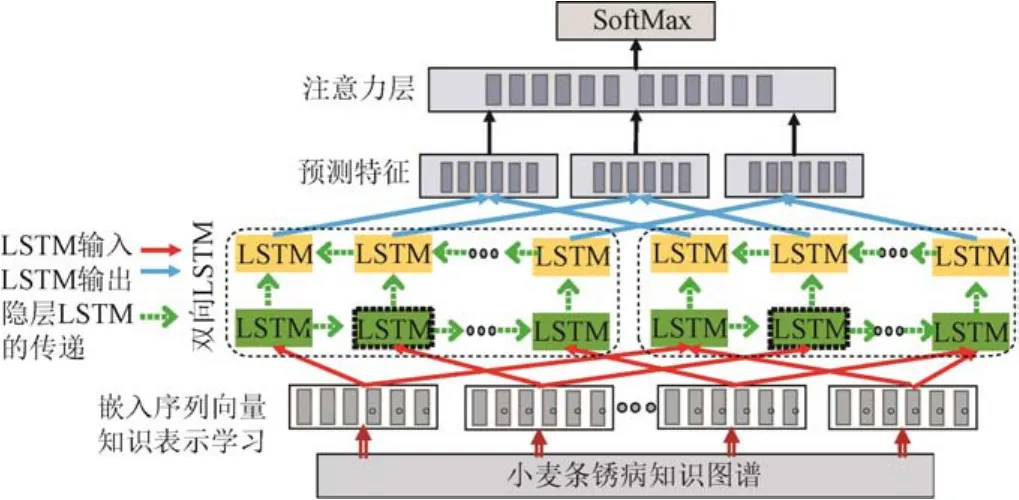
图5 小麦条锈病预测模型Fig.5 Prediction model of wheat stripe rust diseases
第四,对H进行tanh操作:H与wT相乘,通过Softmax得到注意力矩阵a,H与a相乘得到状态信息加权,进一步通过 tanh操作得到的值(在−1~1之间),用于病害预测的特征向量H*。
最后,通过 SoftMax分类器预测病害。将注意力层的输出值H*输入SoftMax分类器进行病害预测,并将其更改为“0”或“1”,作为预测结果。其中“0”表示“无病预测值”,“1”表示“有病预测值”。模型的损失函数定义为
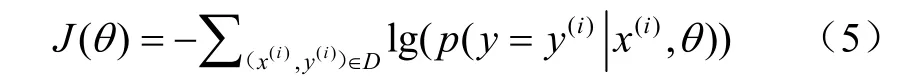
式中D表示由样本数据组成的训练集, (x(i),y(i))表示训练集中第i个样本数据,x(i)为10维向量,y(i)只有“0”和“1”2种值,“0”和“1”分别表示“无病预测值”和“有病预测值”,p(y=,θ)表示病害预测的概率,即预测值与非病态的样本数据 (x(i),y(i))。
1.5 模型预测精度评价指标
预测精度ACC指对于给定的验证数据集,模型正确预测的样本数与总样本数之比:
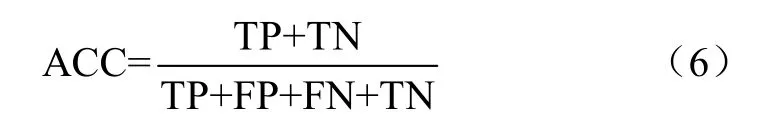
式中TP为被模型预测为正的正样本,TN为被模型预测为负的负样本,FP为被模型预测为正的负样本,FN为被模型预测为负的正样本。
2 结果与分析
从60 000个实体中抽取出86 500条实体关系图,组成86 500个三元组,用于病害预测。采用10折交叉验证法进行小麦条锈病预测试验,则验证集规模为8 650个三元组。将本文方法与其他 5种病害预测方法进行比较:基于自适应判别深度置信网络(Deep Belief Networks,DBN)[24],基于时间序列的神经网络预测方法(Neural Networks, NN)[30]和基于时间序列和RBF网络的植物病害预测方法(Time Series and RBF Networks, TSRBF)[31]以及基于长短时记忆网络(Long Short-Term Memory,LSTM)和双向 LSTM(Bi-directional Long Short-Term Memory, Bi-LSTM)[28]的作物病害预测方法。5种比较方法DBN、NN、TSRBF、LSTM和Bi-LSTM方法都是直接利用小麦条锈病的环境信息数据进行病害预测,没有利用KG转换成的向量数据。试验设备配置及环境:32G内存, Intel Core i5-4200U CPU @2.30 GHz;GPU GEFORCE GTX 1080ti;Ubuntu14.0,深度学习架构是Tensorflow1.7.0和Keras,包括LSTM。
试验结果如图6所示,图6a、b为训练集的预测精度,图6c、d为测试集的预测精度。由于使用了Dropout,一些节点被抑制。随着迭代次数的增加,精度线出现抖动,但验证集的精度高于训练集,且不存在明显的过拟合现象。当迭代次数为280时,Bi-LSTM模型在训练集上的准确率为90.27%,在验证集上的准确率为94.38%。
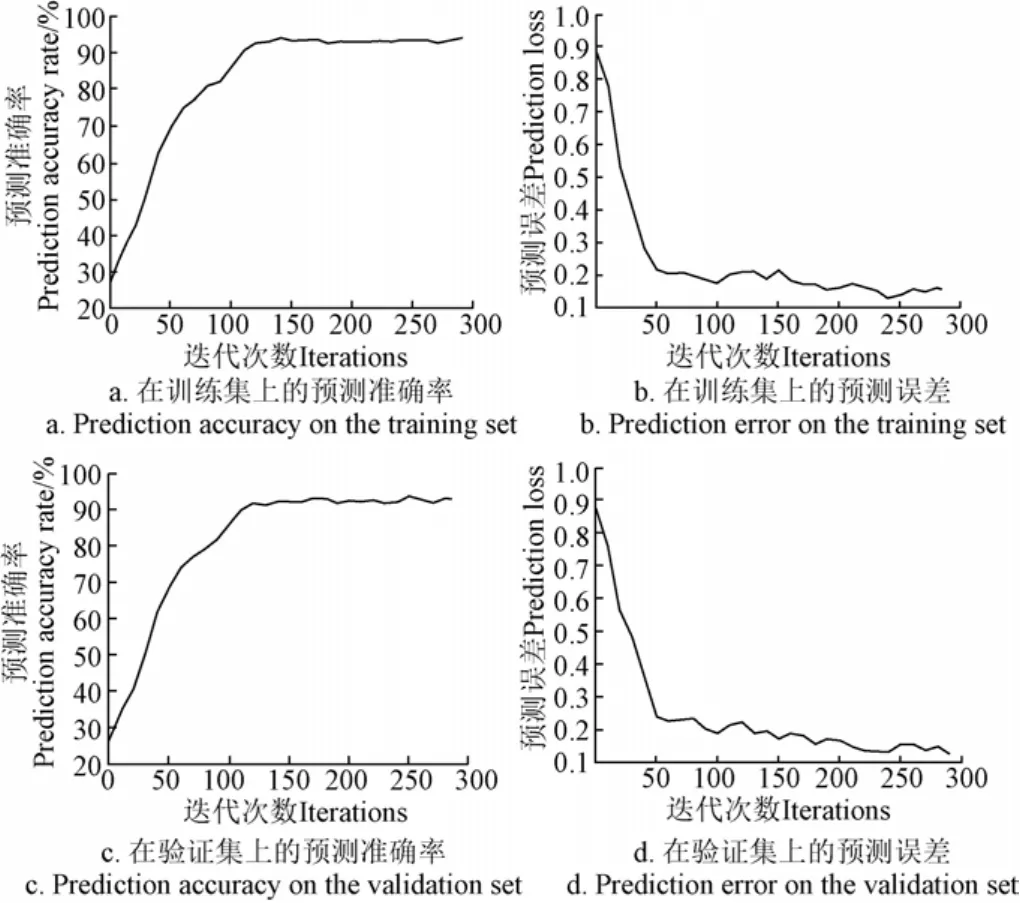
图6 预测精度和loss随迭代次数的变化Fig.6 Prediction accuracy and loss with the number of iterations
将Bi-LSTM模型在2个数据集上进行试验比较:1)直接利用小麦条锈病的环境信息数据进行病害预测;2)利用KG转换成的向量数据,在验证集上的对比结果如图7所示。从图7中能够看出,引入KG后能够有效提升模型的预测精度,当迭代次数为280时,引入KG后模型的预测精度为94.63%,而直接利用环境信息数据的预测精度为88.24%。结果说明本文提出的方法是有效的。表1为利用6种方法,进行10折交差验证法50次试验得到的平均预测精度及运行时间。
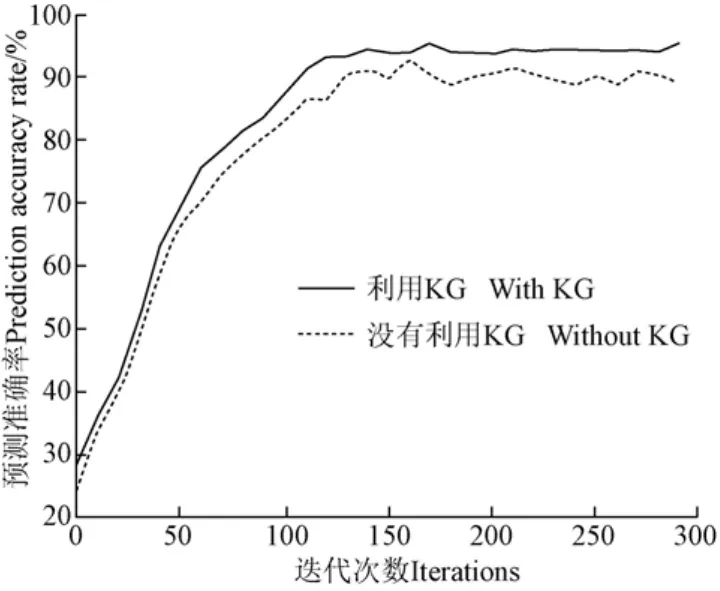
图7 引入KG和未引入KG的预测精度比较Fig.7 Prediction accuracy on two datasets with KG and without KG
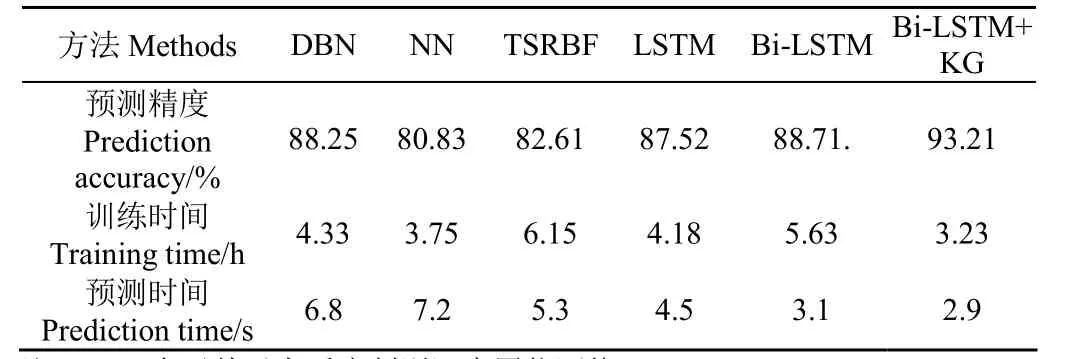
表1 6种方法的平均预测精度及运行时间Table 1 Average prediction accuracy and running time of six methods
从表 1可以看出,本文方法的精度最高,且远高于其他方法,Bi-LSTM次之。其原因是,KG充分利用了环境信息与小麦条锈病之间以及不同环境信息之间的相互作用和影响,其他预测方法完全基于输入的环境信息数据,可能会引入不相关的环境因素和噪声等,导致预测精度低。Bi-LSTM和LSTM模型的准确性高于DBN的主要原因是它可以学习一系列样本数据的变化规律,以及这些变化规律对病害预测的影响,提高了预测的准确性和可靠性。Bi-LSTM或LSTM的训练时间和测试时间小于NN和TSRBF的原因是Bi-LSTM和LSTM可以将类别信息引入模型训练中,使训练具有监督作用。
3 结 论
针对小麦病害预测难题,提出了一种基于知识图谱(Knowledge Graph, KG)和双向长短时记忆网络(Bi-directional Long Short-Term Memory, Bi-LSTM)相结合的小麦条锈病预测模型。首先,构建小麦条锈病KG,由KG整合小麦条锈病发生的环境信息资源;第二,利用word2vec将KG的知识转换为低维特征向量;第三,利用Bi-LSTM模型提取小麦条锈病预测的鲁棒性特征,进行病害预测;最后,利用小麦条锈病发生相关的历史天气和环境信息等病害发生数据进行了验证。结果表明,KG和Bi-LSTM相结合能够预测小麦条锈病,预测结果为93.21%。该方法为小麦条锈病防治提供技术支持。未来的研究是压缩KG和Bi-LSTM,以便应用于软硬件受限的移动设备。