基于KNN-LSTM的PM2.5浓度预测模型①
2020-07-25宋飞扬铁治欣黄泽华丁成富
宋飞扬,铁治欣,2,黄泽华,丁成富
1(浙江理工大学 信息学院,杭州 310018)
2(浙江理工大学科技与艺术学院,绍兴 312369)
3(聚光科技(杭州)股份有限公司,杭州 310052)
根据2018年哈尔滨市生态环境状况公报[1]显示,2018年空气质量共超标52天,超标天数中首要污染物为PM2.5的天数共有39 天.PM2.5又称细颗粒物,由于其粒径小,活性强且附带有害物质的特性,会对呼吸道系统和心血管系统造成伤害[2].空气污染问题不仅与人们的日常生活、身体健康密切相关,还会对城市的招商引资、经济发展造成较大的影响.因此对大气中PM2.5浓度的预测有着重要的意义.
空气质量预测模型主要分为基于大气运动学的数值预报模型(NWP)与基于机器学习算法的统计模型[3].数值预报模型是从大气内部物理规律如大气动力学、热力学等出发,建立对应的数学物理模型,用数理方法,借助大型计算机的计算能力,建立数值预测空气污染物浓度的动态分布运输和扩散模型.例如:JM Xu等[4]基于尺度空气质量模式系统(CMAQ)提出了CMAQMOS模型,有效纠正了CMAQ 中平均污染物排放清单所导致的系统性预测误差;Ming-Tung Chuang 等[5]应用结合化学的天气研究与预测模型(WRF-Chem-MADRID)对美国东南部地区进行预测,结果显示在O3和PM2.5预测中表现良好.机器学习模型则是利用统计学、概率论以及复杂的算法搭建模型,从已知数据中挖掘数据关系,实现精细化预测.例如王敏、孙宝磊等[6,7]利用BP神经网络模型对PM2.5浓度进行预测,实验效果较好;彭斯俊等[8]利用ARIMA模型对于时间序列短期预测有着较高的精度的特点,挖掘序列内部规律,得到了不错的结果;喻其炳等[9]通过K-means方法筛选相似性高的数据来训练基于支持向量机的PM2.5浓度预测模型,提升效果明显.
虽然以上所提PM2.5浓度预测模型各有优点,但是其往往只根据目标站点的污染因子和气象数据,而忽略了PM2.5的分布也具有区域性[10].针对这种问题,本文提出了一种基于时空特征的KNN-LSTM网络模型,通过KNN算法选择目标站点的空间相关信息,利用LSTM 具有时间记忆的特点,从时间和空间两个维度考虑,实现对PM2.5浓度的预测.同时还利用哈尔滨市多个空气质量监测站的污染物数据,与BP神经网络模型和普通的LSTM模型进行实验对比,结果表明本文所提KNN-LSTM模型能较好预测未来时刻的PM2.5浓度值.
1 理论与模型
1.1 长短时记忆网络
长短时记忆网络(LSTM)主要是为了解决循环神经网络(RNN)在长序列训练过程中梯度消失的问题[11,12].与RNN相比,LSTM增加了3个门控:输入门、遗忘门、输出门.门的作用是为了控制之前的隐藏状态、当前的输入等信息,确定哪些信息该丢弃、哪些信息该保留.LSTM的模型结构如图1所示.

图1 LSTM的模型结构
图1中Θ代表操作矩阵中对应的元素相乘,+代表进行矩阵的加法.

对于LSTM 当前的输入xt和上一状态传递的ht-1,通过下面公式得到4个状态:其中,zf、zi、zo、z分别表示遗忘门控、输入门控、输出门控和当前输入内容,Wxi、Wxf、Wxo、Wxz分别代表输入层到输入门、遗忘门、输出门和细胞状态的权重矩阵;bi、bf、bo、bz分别为输入门、遗忘门、输出门和细胞状态的偏移量.σ为Sigmoid函数,tanh为双曲正切函数.LSTM存在两种传输状态:ct(cell state)和ht(hidden state),其中LSTM 中的ct对应RNN 中的ht.t时刻在LSTM 内部主要进行以下3步,如式(5)、式(6)、式(7)所示.
(1)经过zf控制上一个状态ct-1哪些需要保留或遗忘.
(2)经过zi对输入xt选择记忆.
(3)经过zo控制哪些会作为当前状态的输出.

其中,隐藏层到输出层的权重矩阵记为W'.
1.2 KNN算法
KNN算法[13]是一种有监督学习的分类算法.其实现较为简单,训练速度较快.KNN 用空间中两个点的距离来度量其相似度,距离越小,相似度越高.通过最邻近的k个点归属的主要类别,来对测试点进行分类.常见的距离度量方式有欧氏距离、马氏距离、曼哈顿距离等.特征向量Xi、Xj之间的欧氏距离计算公式如下:
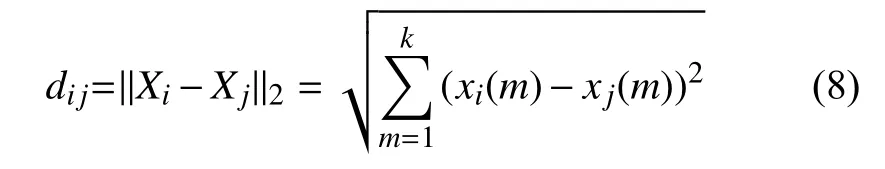
其中,k表示特征向量的维度,xi(m)、xj(m)分别为Xi、Xj第m维的值,m的取值范围为1,2,3,···,k.
1.3 模型介绍
1.3.1 基于单站点的LSTM预测模型
本文首先实现了基于LSTM的单站点PM2.5浓度预测模型,该模型是通过目标站点空气质量六因子(NO2、PM2.5、PM10、SO2、CO、O3)的历史数据,来预测当前时刻的PM2.5浓度.若当前时刻为t,其输入为t-st,t-st+1,···,t-1时刻六因子的小时数据.输入的数据先后经由LSTM层和两层全连接层(Dense层)后得到PM2.5的浓度预测结果.其中损失函数采用均方误差(MSE),计算公式如式(9)所示.模型的优化器选用Adam 优化器[14].
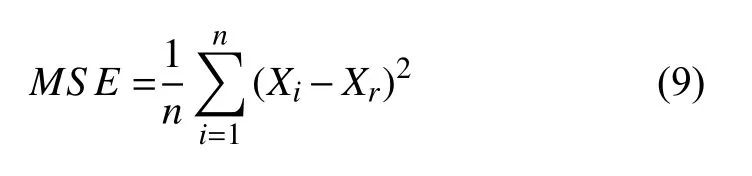
其中,Xi为PM2.5浓度预测值,Xr为PM2.5浓度真实值,n为训练集样本数.
实验选取均方根误差(RMSE)和平均绝对误差(MAE)作为评价指标.计算公式如下:

1.3.2 KNN-LSTM预测模型
对于单站点LSTM模型只考虑时间特征,而没有充分利用空间相关特征的问题,本文利用KNN算法对邻近的空间因素进行筛选,作为额外输入,对其进行修正,构建KNN-LSTM模型以实现对PM2.5浓度更精准的预测.
KNN-LSTM模型主要可分为以下7步,预测模型流程图如图2所示.

图2 KNN-LSTM模型流程图
(1)数据预处理.在原始数据使用前,需要对缺失样本和异常值进行处理.空气监测站对数据缺失的部分用-1表示,统计后可知,各因子的缺失部分占总数据量均不超过5%.故采用简单方便的线性插值法进行填充.由于其数据的收集都要经过一系列严格的审核流程,认为其数据真实且有效,不对数据进行去噪处理.
鉴于检测站点各个污染因子有着不同的量纲和量级,为了取消由于量纲不同引起的误差和保证模型的高效性,对数据进行max-min 归一化处理[15],将数据转化到[0,1]的范围内,并在预测结束后进行数据恢复.max-min 归一化公式如下:

其中,xt为原数据,x′t为归一化后的数据,xmax、xmin分别为数据中的最大值与最小值.
(2)采用KNN算法提取目标站点的空间相关特征,令K=1.本文采用欧氏距离来衡量目标监测站和附近站点之间的相关程度,距离越小,空间相关性越强.KNN算法的选择过程如下所示.
1)根据单站点LSTM模型中的时间步长st构建PM2.5状态矩阵.假设其时间步长为st,区域中共有m个站点,为方便起见,我们将t时刻站点i的时间步状态量Xti和t时刻PM2.5状态矩阵St定义如(13)、式(14)所示:

其中,xun为编号为u的站点在n时刻的PM2.5浓度值(u=1,2,3,…,m;n=1,2,3,…,t).
2)通过计算目标站点与其他邻近站点(共m-1个)t时刻时间步状态量之间的欧氏距离,并进行从小到大排序,选取前k个对应监测站点的PM2.5数据作为t时刻目标站点的空间相关因素,记为Xsp:

其中,xisp为t时刻与目标站点第i相关的站点PM2.5浓度值.
(3)根据目标站点的历史污染数据,利用LSTM网络提取时间特征.输入仍为目标站点st时间步的空气质量六因子数据,t时刻输入数据lstm_inputt如式(16)所示.
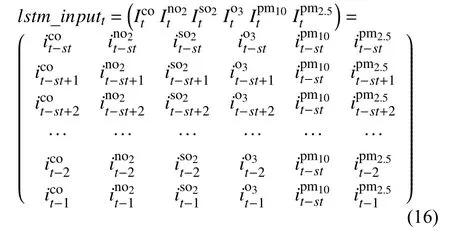
将lstm_inputt经过LSTM层得到的输出向量记为lstm_outputt.

图3 KNN-LSTM网络结构
(5)将数据划分成训练集与测试集,用训练集数据进行模型训练,用测试集数据进行验证,并记录结果.
(6)令K=K+1,重复步骤(3)~(5),直到K>M为止.其中M为邻近站点的数量.
(7)根据所记录测试集上评价指标(这里选用RMSE),确定最优的K.
2 实验结果及分析
2.1 监测站点及数据展示
为了验证所提方法的有效性,本文采用哈尔滨市区11个空气质量监测站4月1日至5月31日两个月共计1464条小时监测数据作为实验数据.站点名称及坐标位置见表1.

表1 哈尔滨市空气质量监测站站点位置及其编号
阿城会宁空气质量监测站远离城区且与其他监测站点距离较远,根据各站点PM2.5时间序列的相关性可知:阿城会宁站点与其他站点间的相关性系数均不超过0.6,而其他站点任意两站点间的相关性系数均超过0.7,因此在KNN进行空间站点选取时,忽略阿城会宁站,同时这证明了PM2.5的浓度分布具有区域性.图4为部分站点PM2.5数据展示,可以明显看出站点的数据的分布具有相似性.

图4 PM2.5 监测数据(从上到下分别为站点编号1137A,1129A,1130A,1132A的数据)
2.2 实验环境及模型参数设置
实验环境及计算机配置如下:程序设计语言为Python3.6.5;开发环境采用Anaconda所自带的Spyder编辑器;Keras版本为2.2.4;Tensorflow版本为1.13.1;Scikit-Learn版本为0.19.1;计算机处理器为AMD Ryzen 5 2500U,内存为8 GB;操作系统为Window10 x64.
对数据进行划分,其中前1300条数据用于训练,80%为训练集、20%为验证集,后152条数据作为测试集.LSTM层的时间步长timestep为12,K值选取为2 (具体原因见2.3节).具体网络参数设置如表2所示.
2.3 KNN算法中K值的选择
本文通过KNN算法来获取目标站点的空间特征,由于K值的选择会影响到选择相关站点的数目,进而影响实验结果.图5给出了K值选择与评价指标RMSE变化之间的关系.根据图5所示,当K=2时,预测效果最好.故K值选择为2.
2.4 实验对比
为了验证本文所提模型的有效性,本文选择传统BP神经网络以及传统LSTM神经网络作为对比实验,3种模型均在相同的实验平台下进行,各个模型预测值与实际值的对比见图6.

图6 预测值与实际值的对比图
本文所有实验均采取均方根误差(RMSE)和平均绝对误差(MAE)作为评价指标.为消除一次实验的偶然性,每种实验均进行30次,迭代50次.表3中评价指标数据均为30次实验结果的平均值(结果保留3位小数).由表可知本文所提KNN-LSTM模型相对于BP神经网络,平均绝对误差(MAE)、均方根误差(RMSE)分别降低了19.25%、13.23%;相较于LSTM模型MAE、RMSE分别降低了4.29%、6.99%.可见本文所提KNN-LSTM模型要优于BP神经网络和LSTM模型.

表3 各个模型的评价指标
3 结语
本文使用哈尔滨市国控空气质量监测站空气质量六因子的小时数据进行PM2.5浓度预测.首先对缺失值采用线性插值的方法进行填充,为减少由于量纲造成的误差,对数据进行max-min 归一化处理.再利用KNN算法为目标站点选取与其空间相关的邻近站点,得到其空间特征.然后对目标站点搭建LSTM模型,接着将得到的空间特征输入到LSTM模型中.通过训练集数据进行训练,再将训练好的模型用测试集进行评估.通过选取最优的K值,确定最终模型.实验结果表明:本文所提模型的预测结果曲线更为平滑且与真实值更加接近,均方根误差和绝对平均误差均为最小,预测效果相较BP神经网络和传统LSTM神经网络模型更好,可以为PM2.5的预警预报提供一定的参考.
由于数据收集的不充分,仅仅利用空气质量六因子作为输入数据是相对片面的,后续研究考虑引进更多影响因素以提升模型效果.
