基于亲属关系网络的问卷调查系统①
2020-07-25孔敬
孔 敬
(中国社会科学院 民族学与人类学研究所,北京 100035)
当前社会科学研究最常用的数据采集方法是传统问卷、二手数据、访谈和观察,其次是互联网问卷[1].访谈和问卷调查是研究者获取第一手研究资料的最基本途径,是社会科学研究的基本方法之一.计算机辅助访谈调查(Computer-Assisted Interviewing,CAI)是由访问员或受访者借助电脑或其他电子终端设备,直接将问答信息做电子化记录并存储的调查方式[2].CAI相对于纸笔调查,在很大程度上改变了原有的数据收集过程,提高了访谈质量控制的时效性和有效性[3].CAI在国内外已广泛应用于社会调查研究[4-6].
亲属关系网络理论是社会网络理论的一个特定分支,有着其自身的公理定义和定理描述[7].基于亲属关系网络的问卷调查系统与一般问卷调查系统[8,9]的不同之处,一是问题针对受访者亲属关系网络和朋友圈中成员间的交互行为,问题适用的对象不仅仅是单一的受访者,而是多个成员交互对,是多元的问题对象;二是亲属关系网络的构建.问题和问题对象的多元复杂化、亲属关系网络可视化是本系统的主要特征和难点.系统将着力解决这些难点问题,支持研究人员进行基于亲属关系网络的问卷设计、问卷本地化和访谈数据可视化采集,以及统计分析软件可读的数据表输出.
1 系统总体设计
1.1 需求分析
社会科学国际化视野将其研究范围拓展到全球跨文化区域,不同文化领域有着不同的亲属关系结构与社会交互模式,研究人员需要根据其研究的不同文化区域和研究主题,设计不同的问卷问题.本系统将面向研究人员提供基于亲属关系网络的问卷设计工具并本地化问卷使其适应全球不同文化区域的研究.多层次、灵活多样的问题编制设计是问卷调查系统的基本功能,同时国际化、多语言也是其重要特征.
基于访谈员面对面访问研究个体的过程,提供可视化交互访谈界面,实现便捷、高效、可靠的研究数据采集,是本系统的主要目标.
问卷调查采集的数据需要以数理统计的模型分析来建构量化的因果解释,从而实现理论的模型化和定量化,开展社会调查的定量分析研究.因此,将问卷调查数据输出为当前常用统计分析软件(如SAS、SPSS等)可读取的数据表格式,也是本系统的重要功能需求之一.
1.2 功能结构
基于亲属关系网络的问卷调查系统的功能结构如图1所示,主要包括问卷生成管理、计算机辅助访谈、数据分析表输出和国际化等4大功能.

图1 系统功能模块结构图
1.3 问卷生成管理模块
研究人员可在系统提供的问卷模板基础上通过新建、修改、删除问卷的章节、问题、问题答案选项等来创建自己的问卷,从而实现问卷的灵活定制.系统提供问题条件设置功能,问卷设计者可以编制自己的条件规则,如设定问题所针对的人群为女性、老人、仅受访者或上下三代人等等.系统提供问卷发布与版本管理功能.系统问卷可输出为Microsoft word 文档格式文件以方便阅读.问卷模板的题型包括亲属和社交网络成员绘制问题、成员基本属性问题、交互行为或交互关系类问题、成员详情问题和家庭配偶关系详情问题等多种类型.
1.4 计算机辅助访谈模块
(1)访谈项目的管理功能.包括新建、修改访谈项目等.项目包含了描述访谈项目的各种信息,如调研采用的问卷、调研地区、国家语言等.
(2)计算机引导的面对面访谈功能.首先完成可视化的亲属及亲属关系网络图绘制和社交圈朋友及朋友关系图绘制,然后对每一个成员的基本属性问题进行问答.其次是受访人和成员间的交互行为问题,第一步先选择交互人员,然后对每一对交互人员的交互活动情况进行问答.最后,对成员详细背景和家庭配偶关系的详细背景问题进行问答.
(3)访谈日志管理功能.深入访谈的问卷调查通常耗时较长,对一个受访者的访谈可能会间歇中断,也可能延续到几天.系统提供了访谈进度和日志管理功能,对访谈进度和详细时间进行记录与展示.
1.5 数据分析表生成模块
问卷调查系统所采集的数据,需要借助数学统计模型工具软件进行量化分析和研究.本系统计算机辅助访谈所生成的原始问答数据以XML数据库形式记录,需要进行数据预处理生成统计分析建模软件工具(如SPSS、R 等)可读的数据表,以及属性变量和值变量说明表.数据分析表生成包括数据表变量与值的抽取、数据编码化和csv或txt 格式的数据表生成.生成的数据表包括两大类型,一类是亲属关系网络数据表,用于亲属关系与家庭结构分析;另一类是问题变量值数据表,分为人员和家庭结合两个数据表,分别包含了人员相关问题答案和家庭结合问题相关答案.
1.6 国际化模块
国际化模块功能包括问卷本地化和系统本地化.问卷本地化可以导入已有问卷或选择系统内置问卷模板生成本地化语言的问卷、支持英语和本地语言双语编辑问卷,将问卷本地化为调研的国家或地区的语言版本,以适应在多个国家地区开展访谈调查.系统本地化可将系统界面语言设为调研地的国家地区语言,方便与当地受访者交流.
2 基于XML的数据设计与实现
2.1 基于XML 存储数据的优势
XML作为一种数据表示和交换的开放标准,它不仅能用于表示各种数据交换的载体,而且能用于表示和存储数据库数据,即XML数据库.XML数据库具有以下优势[10]:(1)XML 灵活、可扩展的语法结构可方便地表示各种结构化、半结构化数据,其高度结构化对复杂的属性关系,特别是重复属性的描述方便易行;(2)能够提供对标签和路径进行操作.传统的关系型数据库语言允许对数据元素的值进行操作,不能对元素名称操作;(3)当数据本身具有层次特征时,XML数据格式能够清晰表达数据的层次特征.XML数据库更适合管理复杂数据结构的数据集,问卷系统常采用XML 来设计存储问卷[11,12].
2.2 基于XML的问卷数据结构设计
基于亲属关系网络的问卷包括亲属、朋友和亲属关系图的绘制、面向个体成员、面向交互活动等多种类型的问题.不同类型问题有不同的操作方式和特殊属性.亲属、朋友和亲属关系图的绘制问题包括个体成员的属性问题和亲属关系问题;面向个体成员的问题有单选、多选和填空题等多种类型;面向交互的问题有两个层次的问题:第一层次问题是参与该交互活动的人员选择;第二层次问题是每一对交互人员在该交互活动中应答的相关问题,也有单选、多选和填空题等多种类型.基于XML 表达上述复杂关系的问卷数据模式(XML Schema)的结构图如图2、图3所示.

图2 问卷数据模式:主要XML元素结构图

图3 Subsection元素的子元素结构图
图2列出了基于XML表示的问卷数据模式的主要元素,首先是根元素Questionnaire,其下4个子元素:(1)languageCountry元素,描述了问卷的本地化信息.其中问卷语言和国家地区,采用ISO语言代码(ISO-639)与国家代码(ISO-3166)表示,以方便Java 国际化功能设计;(2)draw元素,描述亲属、朋友和亲属关系网络的绘制流程和问题设置;(3)section元素,存储按章节组织的所有问卷问题;(4)revise元素,存储问卷的修订历史记录.其中section元素是问卷的主体元素,包含1到多个subsection子元素.
元素subsection 如图3所示包含多级子元素,以描述多层次、多元化的问卷问题.每个subsection元素包含0到多个question(一级问题)和0到多个subsection(子章节),即每个章节可能只有一级问题或只有子章节,子章节可设下级子章节.元素question 包含了0到多个option子元素(问题答案选项)和0到多个的followupQuestion子元素(二级后续问题).
Question和followupQuestion元素都包含一个type属性.question的type属性包含了绘图、人员属性一一映射、单层、双层单人交互、三层双人交互、人员详细属性等8种类型问题.followupQuestion的type属性包含了单选、复选、下拉列表、文本框、画图题等7种类型问题.这两级问题类型可组合设计丰富的问题类型,用以编制复杂的调查问卷.
2.3 基于XML的访谈数据结构设计
调查访谈数据也采用XML文件存储,面向每一个受访者,存储访谈问答信息和访谈进程日志的XML的数据模式如图4、图5和图6所示.
图4所示访谈数据根元素Interview 有5个子元素:(1)fieldSite元素,描述访谈的项目背景和田野点信息;(2)interviewInfo元素,存储访谈管理信息,如访谈员、受访者、访谈日志等;(3)people元素,是一个占位元素,包含1到多个person子元素(person元素是存储访谈数据的最主要元素,包含了受访者提供的所有亲属和朋友的信息及相关问题答案,每一个person元素存储一个人员,其子元素结构见图5);(4)unions元素,也是一个占位元素,包含1到多个union子元素(union元素包含受访者提供的所有配偶对的信息和相关问题答案,每一个union元素存储一对配偶家庭结合,其子元素结构见图6);(5)questions元素,包含了1到多个question子元素(每一个question元素对应一个问题,存储该问题的完成情况).
Person、union和person的子元素question 都包含一个field子元素,该元素是存储所有变量及其值的通用元素,有qid、label和value 共3个属性,qid 存储问题的ID,label 存储问题的命名标签,value 存储问题的答案值.qid和label属性的值可用于导出的数据分析表的字段名.

图4 访谈数据模式:主要XML元素结构图
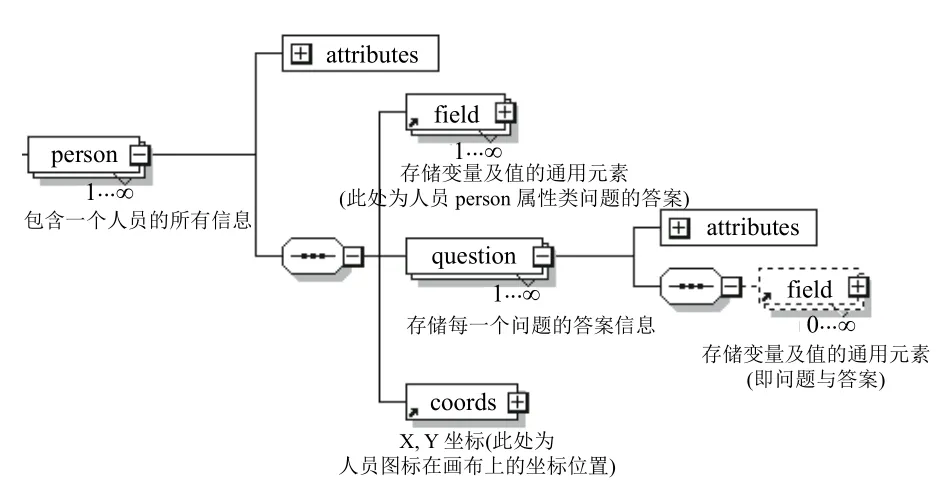
图5 Person元素的子元素结构图

图6 Union元素的子元素结构图
3 亲属关系网络构建与可视化访谈实现
3.1 可视化方法应用
在计算机和信息科学中,数据可视化是用图形、图像、动画序列等来表示数据、结构和大型复杂数据集的动态行为.传统上,数据可视化主要分为两个领域:科学可视化和信息可视化.科学可视化的一个突出特征是对具有自然空间属性的数据集的描述.但许多数据类型,其数据元素没有规定的空间位置,其中关系数据集就是一个简单的例子,例如树、图和网络.信息可视化是将这类数据集赋予空间信息,然后在画面上绘制.在信息可视化构建过程中,空间信息被分配给数据元素,而不是由数据元素本身提供[13].本系统的可视化属于信息可视化,其难点是亲属关系网络图的构建.
3.2 亲属关系网络图相关定义
定义1.亲属关系网络是由人员节点和人员节点之间的基本亲属关系构成的拓扑结构[14].Batagelj V.等将亲属关系网络图分为Ore-graph、p-graph和bipartite p-graph三种类型.bipartite p-graph 包括两种类型节点,一类是人员节点(圆圈代表女性,三角代表男性),另一类是配偶结合节点(矩形表示).孩子由单边弧指向其父母[15].本文亲属关系网络图类似于bipartite p-graph,但为了更清晰地展示人员家庭关系,本文图形符号及排列更改为:配偶结合节点(union)用等号表示.父母与子女人员节点(person)都用无向连线与父母结合节点(union)相连.父母节点在结合节点上方,子女节点在结合节点下方.由此形成一个基本家庭单元,如图7所示.亲属关系网络图由多个家庭结合单元联结而成,同一代的人员排列在同一行.

图7 一个家庭结合单元(union)的可视化图
定义2.路径(Path)和亲属距离(Distance).路径是指一个节点到受访者节点(Ego)的连的集合.亲属距离是指一个节点到Ego节点的路径上的结合节点(union)的个数.也就是说本系统的亲属关系网络图是以受访者(Ego)为基准的.
定义3.代值是节点与Ego节点之间的相对代值,而不是其在某一家族中的辈分代值.设Ego节点的代值为0,则其父母的代值为1,其子女的代值为-1,其兄弟姐妹的代值为0.其父母的union的代值为0,Ego与其配偶的union的代值为-1.
3.3 构建亲属关系网络图的关键算法
当亲属关系网络的成员数量较大,亲属间联姻等情况出现时,亲属关系网络图呈现了更多的动态变化和复杂性.图中每一个新成员的加入都有可能使得原有家庭结合(union)和成员(person)的图标位置发生改变,亲属间联姻将形成婚姻环路.Hamberger描述了在婚姻环路情况下亲属关系网络的多种形态[16].环路的形成使得部分人员的代际划分不确定,一个人可能属于不同的代,如何确定其在图中的代值成为亲属关系网络图构建的难点.本文设计了一个以受访者(Ego)的父母union(代值为0)为起点,迭代遍历整个亲属关系网络确定每个union和person的代值的算法.首先根据每个union和person在亲属网络图中到达Ego的图路径,计算其代值.亲属关系网络图中的婚姻环路使得部分union和person有多条路径与Ego相连,产生多个代值,需要采用消歧算法去除错误和不适合的代值,从而确定其正确代值.

算法1.迭代遍历消歧代值确定算法的主要步骤1)计算已确定代值union 中子女的代值,其子女代值等于该union的代值,若该子女person 有配偶且没有处理其union,则进入步骤2),否则进入步骤3);2)已知person 代值,计算该person与其所有配偶的union的代值,采用union 代值消歧算法(详细步骤从略)确定其代值,若该union 代值确定,则将该union 代入步骤1),循环步骤1)至4),最后循环当前步骤直至其所有的配偶union处理完毕;3)计算union 中父母的代值,采用person 代值消歧算法(详细步骤从略)确定union 中父母person的代值,如果该父母person的代值确定,且其父母union 代值未确定则进入步骤4),若该父母person 还有其他配偶且没有处理其union,则进入步骤2),当父母的代值全部处理完毕,则结束流程;4)已知子女代值,计算该子女的父母union的代值,父母union的代值等于子女的代值,将确定代值后的父母union 代入步骤1),循环步骤1)至步骤4).
上述算法流程如图8所示,由此确定union和person的代值以及其与受访者的亲属距离和网络图路径后,再根据以下原则设计亲属关系图的自动排列算法(具体算法步骤从略).
(1)以受访者父母的union为中心,其他亲属union按照与受访者的亲属距离的升序向左右两个方向扩展排列.
(2)每个家庭单元union的成员尽可能靠近排列,每个union的子女排列在一起不能插入其他人员.
(3)同一代的person 排列在同一行.
(4)union和person的排列要尽可能减少person 连线之间的交叉,并使连线最短.

图8 迭代遍历消歧代值确定算法流程(局部)
采用上述迭代遍历消歧代值确定算法和自动排列算法生成的亲属关系网络图如图9.图中包含了150多个亲属,在实际访谈样本中,有多达400多人的大家族.自动排列方法解决了大家族亲属关系网络图的绘制问题.

图9 自动排列算法生成的150多人的亲属关系网络图(缩略图)
3.4 访谈答案和进程可视化
在前述构建的亲属关系网络图之上进行访谈答案的可视化标注,并对访谈进程可视化展示.这两个方面的可视化实现主要采用颜色标记法.
(1)答案可视化,不同的答案选项以不同的颜色标记在亲属关系网络图上.
(2)问题答题状态可视化,在问题导航栏,每一道题的标题以绿色、蓝色和红色3种不同颜色显示,分别表示未答、部分已答、全部答完这3种状态.
(3)访谈进度的可视化,采用不同颜色和比例标注问卷完成进度条.
4 系统展示
本系统主要功能界面展示如下:可视化访谈界面如图10、问卷设计编辑界面如图11、问卷本地化界面如图12、数据分析表输出结果示例如图13.

图10 基于亲属关系网络的答案可视化标注界面(局部)

图11 问卷设计编辑界面

图12 问卷本地化双语编辑界面

图13 访谈数据分析输出表之一(局部数据)
5 结论
本文在基于亲属关系网络的问卷调查系统中,采用XML 设计了灵活、多元化的问卷数据结构以满足社会访谈调查研究中复杂问卷的设计,并提出了一个迭代遍历消歧确定代值的算法,解决了亲属关系网络图可视化显示中一个家庭或人员代际位置不确定的问题,以及大家族亲属关系图自动排列问题.本系统可应用于不同文化区域的家庭人口结构分析的研究,以及面向亲友的各种交互行为和活动的深入调查研究,比如语言使用、民族交往、社会互助、家庭婚恋等研究课题的深入访谈研究.采访数据可输出为SPSS 等常用统计软件可读的数据格式,方便进一步数据分析.系统已被国内外学者在中国、哈萨克斯坦、吉尔吉斯斯坦和意大利等地应用,为科研人员在不同文化区域开展面向亲属关系网络的社会访谈调查研究提供了有效便捷的工具.
