融合用户和产品信息的多头注意力情感分类模型①
2020-07-25蒋宗礼
蒋宗礼,张 静
(北京工业大学 信息学部,北京 100124)
情感分类是NLP领域的研究热点之一,目的是根据文本的含义和情感表达,将文本分为两种或多种类型.情感分类在评论网站中有很广泛的应用,例如IMDB、豆瓣电影、大众点评等.本篇工作的研究任务是文档级别的情感分类,它是情感分析和观点挖掘的基础任务,它根据文本中单一的目标或产品来决定该文本的情感极性.传统的情感分类方法[1-3]是手动地从文本中抽取、设计和选择一些高质量的特征,然后训练各种分类器.近几年来,深度学习方法在NLP领域取得了重大突破,越来越多的研究者关注如何利用深度学习技术提高情感分类的效果.近来的大多数工作利用了神经网络去学习低维空间上的文本表征,因为评论文本有很明显的序列特征,所以处理序列信息的递归神经网络(Recurrent Neural Network,RNN)[4]能够很好的学习到评论中的情感信息,尤其是它的变体长短时记忆网络(Long Short-Term Memory,LSTM)[5],通过引入记忆单元和门控机制,缓解了传统循环神经网络出现的梯度爆炸或者是梯度消失的问题,在情感分类领域中取得了较好的效果.随着Attention 机制[6-9]在图像分类、机器翻译等领域的成功应用,越来越多的研究者开始将其引入到情感分类任务中,重点关注对情感分类有明显影响的单词或词语.但是单一的注意力机制难以提取到更丰富的情景语义信息,它很难对一些句法信息、指代信息等进行建模,并不能很好地判别句子的情感极性.
为了解决提取的情感信息单一的问题,本文提出了一种融合用户信息和产品信息的分层多头注意力的情感分类模型(Hierarchical User and Product Multihead Attention model,HUPMA),在词语层和句子层中分别用多头注意力提取出词语和句子的情感信息,并且在每个注意力中融入用户信息和产品信息.本文工作的主要贡献如下:
(1)提出了一种新的情感分类模型框架,在词语层和句子层分别使用多头注意力来学习更长的序列信息,捕捉到更丰富的上下文语境信息.
(2)在多头注意力中引入用户和产品信息,在多个子空间上得到更全局的用户偏好和产品特点对情感评分的影响.
本文分别在公开数据集IMDB、Yelp2013、Yelp2014上验证了模型效果,实验结果表明,在相同运行环境下,我们的模型相比于基于单头注意力的分层网络模型,在准确率上有所提升.
本文第1节介绍基于文档级别的情感分类的相关工作.第2节介绍模型的基本原理.第3节是本文的对比实验以及对实验结果的详细描述和分析.最后是对本文工作的总结和未来展望.
1 相关工作
文档级别的情感分类作为情感分析的基础任务之一,一直是情感分析领域的研究热点.最早使用的方法是基于情感词典的方法.基于情感词典的方法,一般依靠情感词典的构建和规则的建立,文献[10]通过情感词典及词性求出文本中情感词的得分,并将其按特定规则组合计算,来判断文本的情感倾向性.李寿山等[11]利用英文种子词典,借助机器翻译系统,构建了中文情感词典.情感词典构建的好坏决定了分类的效果,并且情感词典的构建依赖于人工统计,耗费大量的人力物力的同时存在着误差.
另一种情感分类的方式是基于机器学习和深度学习的方法,利用深度学习技术可以自动提取文本的深层特征,使文本情感分类研究得到了进一步的发展.主流的深度学习网络包括卷积神经网络(Convolutional Neural Networks,CNN)[12]和RNN,其中卷积神经网络通过卷积操作实现对文本的局部信息的捕捉,通过池化操作实现对局部重要信息的提取.Kim 等人[13]将经典的CNN结构应用在情感分类任务上.Xiang Zhang等[14]从字符角度来训练卷积神经网络,使网络不需要提前知道关于语法和语义的信息.但是CNN 只能提取到文本的局部信息,丢失了词语的顺序信息,而词语的顺序信息在文本处理上是不能忽略的.相比于CNN,RNN的内在结构使得它在文本序列建模方面更有优势,能够很好地捕捉上下文信息.尤其是RNN的变体LSTM 引入了门控机制,缓解了RNN 中梯度消失和梯度爆炸的问题.Tang 等[15]为了对句子之间的关系进行建模,引入自底向上的基于向量的篇章表示方法,首先用LSTM 实现单句表示,再用RNN编码句子间的内在关系和语义联系,采用层次化RNN模型来对篇章级文本进行建模.该模型相比标准的循环神经网络模型实现很大的效果提升.Siwei Lai 等[16]提出了RCNN模型,先使用双向循环神经网络得到上下文表示,再经过卷积、池化操作后输出分类结果.注意力机制(Attention Mechanism)使得模型能够在训练过程中高度关注特定的词语,更好地捕捉句子中的重要成分,提取出更多的隐藏特征.Wang 等[17]采用方面嵌入的方式来生成注意力向量,关注句子的不同部分.Yang 等人[18]提出了分层注意力网络(Hierarchical Attention Network,HAN)模拟文本的构成方式,对单词和句子进行分层编码,并根据其注意力权重融合成文本表示,不仅捕捉了句子中比较重要的词语,还给篇章中比较重要的句子赋予更高的权重.实验表明,结合注意力机制的神经网络模型在情感分类任务中取得了比传统方法更好的效果.在网络评论中,有些词语是表达用户情感的,有些词语则是对产品本身的评价.为了将这些用户和产品信息引入情感分类任务中,研究学者们在这方面做了很多工作,并且都获得了一定的提升.唐都钰等人[19]在CNN网络的基础上添加了用户和产品的偏置矩阵和表示矩阵来表示这些信息.考虑到用户偏好矩阵训练比较困难,陈慧敏等[9]在层次网络中融入用户和产品的相关信息,考虑了全局的用户偏好以及产品特点,进一步提高了模型性能.但是上述模型提取到的情感信息相对都比较单一,受Transformer模型[20]的启发,本文提出一种融合用户信息和产品信息的分层多头注意力的情感分类模型HUPMA.首先该模型利用分层多头注意力,分别在词语层和句子层中采用不同的隐层向量权重参数,形成指代信息更丰富的注意力权重分布;其次,在多头注意力中融入用户信息和产品信息,同时采用不同的用户向量权重和产品向量权重参数,形成多个子空间下不同的用户偏好和产品特点对情感评分的影响,从而能够对指代信息丰富的上下文进行建模,同时挖掘出用户信息和产品信息在多个维度上的深层特征.
2 模型
融合用户信息和产品信息的基于分层多头注意力的情感分类模型HUPMA 如图1所示.
模型主要包含了4个部分:词汇层编码、词汇层的多头注意力机制、句子层编码、句子层的多头注意力机制,其中在词汇层的多头注意力机制和句子层的多头注意力机制中融入了用户和产品信息.首先,在模型的词语层,利用双向LSTM计算单词的向量表示,然后用多头注意力结合用户、产品信息来学习单词的注意力权重分布,进而生成句子的向量表示;在模型的句子层,同样利用双向LSTM计算句子的向量表示,用多头注意力结合用户、产品信息来学习句子的注意力权重分布,得到文本的向量表示.最后经过一个Softmax层,完成评论文本的情感分类.
2.1 基于LSTM的分层网络结构
本模型采用“词-句子-文章”的自下而上的层次化结构来表示一篇文本,获取更丰富的上下文情感特征,既符合人类的阅读习惯,也缓解了过长的序列导致的长句依赖的问题.LSTM是一种带门控机制的循环神经网络,通常被用于处理序列文本数据,可以避免传统的循环神经网络的梯度消失或梯度爆炸的问题,另外,LSTM通过引入记忆单元和输入门、输出门、遗忘门3种门控机制来捕捉句子的依赖关系和上下文语境信息.
(1)词语层LSTM网络
定义文档中的某个句子si=[xi1,xi2,xi3,···,xin],xij表示第i个句子的第j个词语,首先将句子中的词语xij编码为向量表示wij,通过双向LSTM编码wij的上下文,得到隐层表示hi=[hi1,hi2,hi3,···,hin],其中hij∈Rd,d为LSTM 单元输出向量的维度.每一时刻的LSTM单元的输入由上一时刻隐藏层的输出和本时刻输入的词向量组成.具体计算方法如下:
(2)句子层LSTM网络
因为同一评论中不同句子之间有一定的情感联系,挖掘这种相互联系有助于整个评论文本的情感极性分析,因此本文除了词语层的LSTM网络外,还使用一个句子层的双向LSTM网络来进一步挖掘句子之间的依赖关系.通过词语层之后就得到了句子向量si,然后句子层的LSTM网络将句子向量si编码为句子层的隐层向量hi.

2.2 融入用户和产品信息的多头注意力机制
(1)多头注意力机制
注意力机制的主要目的是从众多信息中选择出对当前任务目标更关键的信息.传统的单头注意力机制难以提取到更丰富的情景语义信息,进而对评论文本的情感分类的效果也产生了影响,为了从多个子空间上学习更加丰富的情感信息,本文采用了多头注意力代替传统的单头注意力,如图2.
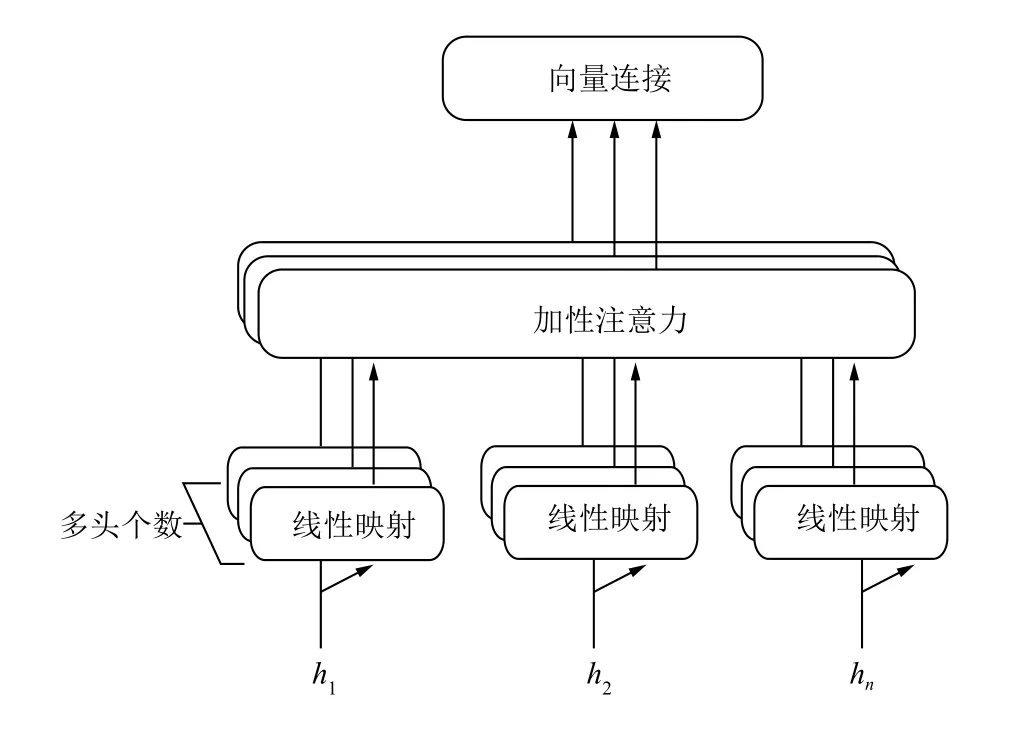
图2 多头注意力机制
首先将LSTM层产生的隐层向量表示拆分为多个头,线性变换后然后送入加性注意力层,重复计算head_num次,其中head_num为多头的个数,最后拼接所有的attention值作为下一模块的输入.考虑到不同的用户、不同的产品会对情感分析造成一定的影响,因此在多头注意力机制中引入了用户和产品信息,其中每个head的注意力计算如图3.
(2)词语层的多头注意力机制
不同的词语对句子的情感表达的重要度不同,为了深度挖掘每个词语在多个子空间上的情感信息表达,在词语层引入多头注意力机制,同时不同的用户、不同的产品在评论中的情感用词也有差异,因此,将用户、产品信息融入到多头注意力的计算中,计算方式如下:

hij是词语层的LSTM产生的隐层向量,αij是在考虑用户信息和产品信息后,句子中第j个词的权重,度量的是这个词语在整个句子si的重要程度.αij由式(8)和式(9)计算而来:
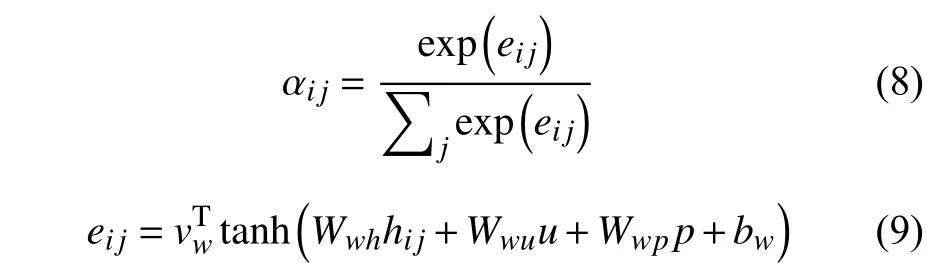
其中,eij是向量αij未归一化时的权重表示,vTw、Wwh、Wwu、Wwp和bw分别表示计算eij时的前馈神经网络中对应的点积权重、隐层向量权重、用户向量权重、产品向量权重和偏置,初始赋随机向量,作为模型训练的参数.
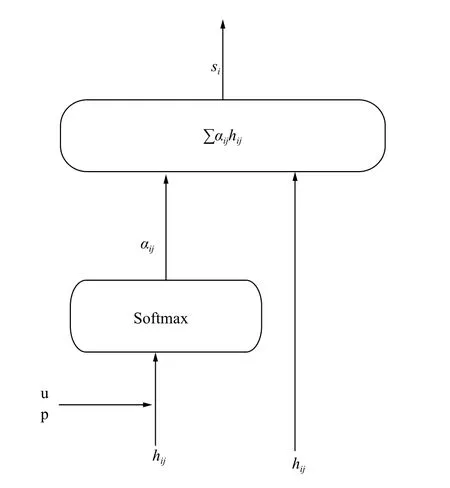
图3 加性注意力机制
(3)句子层的多头注意力机制
和词语层的多头注意力机制类似,一条评论文本中的不同句子对最后的情感表达也有着不同的重要度,因此在句子层引入多头注意力机制,计算方式如下:

hi是经过句子层的LSTM产生的隐层向量,βi是在考虑用户信息和产品信息后的注意力权重,度量的是某个句子在整个评论文本d中的重要程度.βi由式(11)和式(12)计算而来:
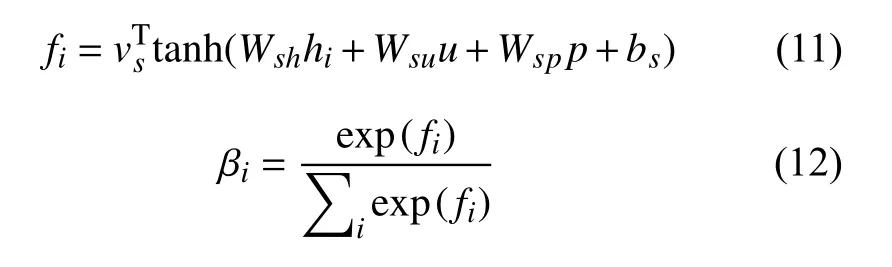
其中,fi是向量βi未归一化时的权重表示,vTs、Wsh、Wsu、Wsp和bs分别表示计算fi时的前馈神经网络中对应的点积权重、隐层向量权重、用户向量权重、产品向量权重和偏置,初始赋随机向量,作为模型训练的参数.
2.3 优化模型
本文的任务是对给定的评论文本,判断其情感极性,是一个情感分类的任务,因此采用交叉熵损失函数作为代价函数,通过最小化损失函数来训练模型,找到最优参数.同时,为了避免过拟合,加入了L2正则化作为惩罚项,损失函数公式如下:

其中,yki表示第i篇评论文本的真实的情感类别,表示模型对第i篇评论文本预测的情感类别,k为情感类别的某一类,以数字表示.λ表示L2 正则化的惩罚系数,λ越大,惩罚力度越大.θ表示模型中的全部训练参数.
2.4 模型复杂度分析
在模型的词语层的多头注意力和句子层的多头注意力中,对每个头的注意力都在维度上做压缩.首先将底层LSTM产生的隐层向量进行维度上的拆分,拆分之后的维度为dhead=dlstm/head_num,其中dlstm为底层LSTM输出向量的维度,head_num是多头的个数.然后在维度为dhead的向量上做注意力函数运算,所以在多头注意力中虽然需要计算多次,但是相较与之前的单一注意力,整体的计算成本并没有增加.同时,多个头之间的注意力计算是相互独立的,因此可并行运算,进一步提高模型的性能.
3 实验分析
3.1 实验设置
为了验证本文模型的有效性,分别在3个情感分类任务的数据集上进行实验,IMDB、Yelp2013、Yelp2014 这3个数据集是Tang 等[19]构建的公开数据集.IMDB是用户对电影评分数据集,Yelp2013和Yelp2014是用户对商家的评分数据集.在数据预处理阶段,本研究采用Stanford CoreNLP[21]实现评论文本中词语的切分和句子的切分,同时提取数据集中的用户信息和产品信息,预处理后的数据集统计如表1.其中IMDB划分10个类别,Yelp2013和Yelp2014划分5个类别,级别越高代表评价越好.
将每个数据集中80%作为训练集,10%作为验证集,剩余10%作为测试集,用Accuracy和RMSE作为模型分类效果的评价指标.采用文献[9]中用SkipGram模型[22]训练好的词向量作为初始化的词向量,维度为200,此外,用户和产品信息的维度也设定为200维,并随机初始化,随着模型一起训练.LSTM层的神经元维度设为200维,用Adam[23]算法来优化超参数,该算法通过计算梯度的一阶矩估计和二阶矩估计,能够为不同的参数设计独立的自适应性学习率.然后在验证集上选择表现最好的超参数作为模型参数,最后用测试集测试模型在情感分类任务上的效果.

表1 IMDB,Yelp2013和Yelp2014数据集统计数据
3.2 基准模型
本文模型将与以下基准模型进行实验对比.
(1)Majority 将训练集中出现次数最多的情感分类标签作为测试集的预测标签.
(2)Trigram 以评论文本的一元语法、二元语法和三元语法为特征,以支持向量机(SVM)[24]为分类器,训练模型.
(3)TextFeature[25]将提取的词语和字符的N 元语法、情感词典等作为特征,训练SVM分类器.
(4)UPF[26]从训练集中抽取use-leniency特征和相关产品特征,作为Trigram方法和TestFeature方法的特征.
(5)AvgWordvec 用Word2Vec方法获得训练集和验证集的词语向量表示,然后以词向量的平均向量为评论向量,然后用这个向量为特征训练SVM分类器.
(6)NSC+UPA在层次化的文本分类模型中引入了用户信息和产品信息来提高文档级别情感分类的效果.
3.3 模型性能对比
表2列出了HUPMA模型及基准模型的情感分类结果,我们将这些结果分为两组,第一组是仅仅考虑文本信息的模型,第二组是同时考虑文本信息以及用户和产品信息的模型.为了验证分层多头注意力和用户产品信息对本文模型的性能影响,将用户信息和产品信息去掉,得到HUPMA(不含UP)的实验结果.HUPMA(含UP)一行是融合用户信息和产品信息的分层多头注意力的模型分类结果.
(1)分层多头注意力的有效性
第1组的实验采用的是不考虑用户和产品信息的分类方法,包括统计模型、传统的机器学习模型和神经网络模型,对比实验结果可看到,Majority 效果很差,因为它没有考虑任何文本信息、用户信息和产品信息,仅仅用一种统计思想寻找频率最高的情感分类标签.同样是基于机器学习的SVM分类器训练模型,用基于N元语法和情感词典的TextFeature 比基于平均词向量的AvgWordvec在IMDB、Yelp2013和Yelp2014三个数据集上的情感分类准确率分别高出了9.8、3和4.2个百分点,说明采用了N元语法模型的词向量能够利用上下文信息丰富语义特征,比平均词向量效果更好.NSC模型和NSC+LA模型相比TextFeature在IMDB数据集上的情感分类准确率分别提高了4.1和8.5个百分点,在Yelp13数据集上的情感分类准确率分别提高了7.1、7.5个百分点,说明神经网络模型比传统的机器学习模型在情感分类任务上的表现更好,尤其是加入了注意力机制后,模型效果得到了进一步提升.不考虑用户信息和产品信息的情况下,本文提出的HUPMA模型(不含UP)在3个数据集上的准确率比基准模型均提高了一到两个百分点,这也验证了引入分层多头注意力思想在提取文本上下文信息的有效性.
(2)融合用户信息和产品信息的有效性
第2组的实验采用的是考虑用户和产品信息的分类方法,结果表明,加入了用户信息和产品信息的模型相比于仅仅考虑评论文本信息的模型分类准确率更高,Trigram模型加入用户和产品信息后,在IMDB和Yelp2013数据集上的分类准确率分别得到了0.5、0.1个百分点的提升,NSC+UPA模型相比NSC+LA模型在3个数据集上的分类准确率分别得到了4.6、1.9、3.7个百分点的提升,通过对比可以发现,在神经网络结构中,用户和产品信息的引入对模型的提升效果更加明显.与不考虑用户和产品信息的HUPMA模型相比,HUPMA(含UP)模型在IMDB数据集上的准确率提高了4.3个百分点,而在Yelp2013和Yelp2014两个数据集上的准确率仅提高了2.2个百分点,原因是IMDB数据集上的用户数据和产品数据相对比较丰富.这一结果验证了融入用户偏好和产品特征之后的模型在情感分类上的有效性.
(3)融合用户和产品信息的多头注意力模型的有效性
同样是引入了用户和产品信息的分层的网络结构,本文模型HUPMA 比NSC+UPA模型在3个数据集上的情感分类准确率分别提升了1.2、2、0.9个百分点.这一结果验证了融入用户偏好和产品特征之后的分层多头注意力模型在情感分类上的有效性.

表2 IMDB、Yelp2013和Yelp2014数据集上的情感分类结果
3.4 模型运行时间对比
为了验证本文模型HUPMA的运行时间,在同等运行环境下,在Yelp2013数据集上分别运行单头注意力模型和多头注意力模型,得到不同的模型单次迭代的运行时间,如表3.从表中可以看出,多头注意力模型的单次迭代运行时间和单头注意力模型的单次迭代运行时间相差不大.

表3 不同模型完成单次迭代的训练时间(单位:s)
4 结论与展望
本文提出了一种融合用户信息和产品信息的分层多头注意力的情感分类模型,首先,模型采用“词-句子-文章”的层次化结构来表示一条评论文本,为了从多个视角选择有用的信息,在词语层和句子层都引入多头注意力的思想.然后在每层注意力中融入了用户信息和产品信息,使模型在多个子空间上得到更全局的用户偏好和产品特点对情感评分的影响.实验结果表明,在同等条件下,本文模型在IMDB和Yelp数据集上的准确率均优于基准模型.在今后的工作中,我们试图将多头注意力引入基于Aspect的情感分类任务中,从更丰富的特征空间中识别评论文本中多个实体的情感极性.
