基于文档关系改进的向量空间模型
2020-07-23何丹丹吴树芳徐建民
何丹丹,吴树芳,徐建民
(1.河北大学 网络空间安全与计算机学院,河北 保定 071002;2.河北大学 管理学院,河北 保定 071002)
向量空间模型是一种经典的信息检索模型,目前对该模型的改进主要是查询扩展.查询扩展[1]的基本思想是利用与查询术语相关的词语对用户原始查询进行扩展,现有研究方法主要包括基于词典的方法[2]、基于反馈的方法[3-5]和基于语义的方法[6]等.基于词典的方法通常用同义词典作为扩展源,给出与原始查询词相关的扩展词,如文献[2]利用语义词典与词向量相结合的方法进行查询扩展.基于反馈的方法是从用户认为相关的文档或者前n篇文档中选择与查询词相关的词语,从而实现对查询词的扩展.如文献[5]将抽取的维基百科文章作为反馈文档,提出了基于伪相关反馈的监督查询扩展方法和无监督查询扩展方法.基于语义的方法是指最大程度上保留原始查询词的语义信息,选择与查询词语义相近的扩展词.如文献[6]以查询词作为根节点,与其有语义关系的词作为子节点,构建概念语义空间,实现扩展研究.这些方法都是基于查询端来研究的,且均取得了一定效果,此外还可以从文档端的角度展开研究.
合理利用文档关系可以提高模型的检索性能[7].Balinski等[8]充分利用了文档间的距离关系,并根据这些距离修改文档的初始相关性权重,实现检索结果重新排序.Plansangke等[9]根据文档与查询词之间的相关性,并利用文档关系,对文档进行分类,然后重新对文档进行排序.Acid等[10]在简单贝叶斯网络检索模型中合理利用文档关系,实现对模型的扩展研究,提高了查询效果.徐建民等[7]通过在基本的信念网络检索模型中增加一层文档节点,利用文档间存在的相似关系对基本模型进行扩展研究,使得检索效果有所提高,进而得到更加合理的相关文档排序结果.然而目前利用文档关系对传统向量空间模型进行改进尚未研究.
基于此,本文提出一种基于文档关系改进的向量空间模型,该模型将初始检索结果中排名靠前的高相关文档组成基准集,通过计算初始检索结果集中每篇文档与基准集的相似度,来修正文档与查询的相似度,作为最终的相似度,实现对向量空间模型的改进,并通过实验验证了方法的有效性.
1 文档关系的度量
文档之间的关系主要包括相关关系和相似关系,分别可以通过相关度和相似度来衡量.相关度一般是指语义相关度,即2个概念间的相关程度[11],其主要采用基于本体结构的语义相关度方法来度量;相似度是指2个或多个文档中出现的词语、句子、段落或者篇章的吻合程度,2篇文档在词语、句子、段落或者篇章上相似部分越多,代表这2篇文档的相似度越高[12].相似度是相关度的一种特殊情况,相似度越高,则相关度越大,但是相关度越大并不能说明相似度越高[11].
本文以相似度为例度量文档间关系.文档相似度的研究既可以从文档内容的角度,也可以从文档间结构的角度来进行,其中,基于文档内容的研究方法主要有向量空间模型的方法和集合运算模型的方法;基于文档间结构的方法主要有基于文档结构的方法和基于引文图的方法.这几种方法中应用较为普遍的是向量空间模型方法,故本文采用该方法来计算文档间的相似度,实现对文档关系的度量.为了方便表述本文的改进细节,下面对向量空间模型方法作一些简单介绍.
在向量空间模型(VSM,vector space model)中,假设文档集D中包含M个特征项,分别用k1,k2,…,kM表示,di=(wi1,wi2,…,wiM)表示文档集中的第i篇文档,wit表示特征项kt在文档di中的权重,计算方法如公式(1)所示.
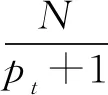
(1)
其中,tfit表示在文档di中特征项kt出现的频率,idft表示逆文档频率,N表示系统中所有文档的数量,pt表示存在特征项kt的文档数.
用户的查询q表示为q=(wq1,wq2,…,wqM),wqt为特征项kt在查询q中的权重.查询q和文档di的相似度用文档向量和查询向量的夹角余弦值来衡量,如公式(2)所示.
(2)
2 基于文档关系改进的向量空间模型
2.1 基本过程
本文提出的基于文档关系改进的向量空间模型的基本过程主要包括3个阶段,由图1所示.
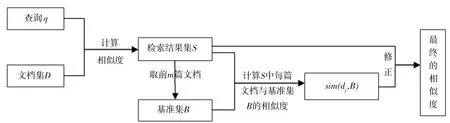
图1 基于文档关系改进的向量空间模型的基本过程Fig.1 Basic process of vector space model improved based on document relationship
1) 利用查询术语实现查询,并将文档集的查询结果进行降序排列,取前n篇文档作为初始检索结果集S={d1,d2,…,dn}.
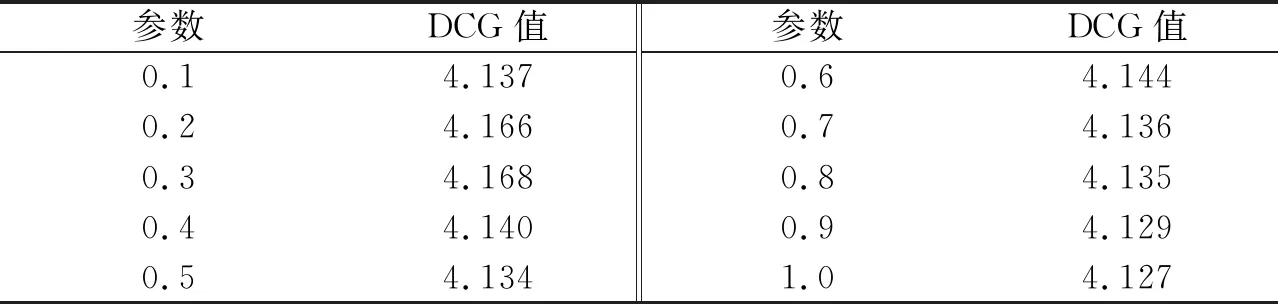
2)从初始检索结果集S中选取前m篇文档组成相关文档的基准集B={d1,d2,…,dm},其中m取排名靠前的高相关文档数(m 3)通过计算集合S中每篇文档dj与基准集B的相似度sim(dj,B),用来修正原模型中文档dj与查询q的相似度,得到最终的相似度,从而实现对检索结果的重排序,得到改进的向量空间模型.如果某篇文档与查询的相似度不高,但是与基准集的相似度高,则该文档与查询可能也是相关的,因此利用文档与基准集的相似度来修正文档与查询的相似度,这样可以使在前n篇之外的相关文档排名靠前.同样,基准集中的每篇文档也用文档与基准集的相似度来修正文档与查询的相似度,如果某篇文档与查询的相似度高,但是与基准集的相似度低,则该文档与查询可能不相关,利用该方法进行计算可以使得在前n篇文档中相关度低的文档排名靠后. 上述3个阶段中,最关键的一步为第3步,当计算文档与基准集的相似度时,如果直接利用文档与基准集中每篇文档的相似度来计算,存在一定的不足:基准集中每篇文档与查询的相关程度是不同的,故其权重理应是不同的.为解决该问题,将基准集中每篇文档与查询的初始相似度作为该文档权重,结合权重来计算文档与基准集的相似度,并给出了具体的计算方法,如公式(3)所示. (3) 其中,文档di∈B;sim(dj,di)表示文档dj与文档di的相似度,sim(di,q)表示文档di与查询q的相似度,均采用向量空间模型方法来计算. 本文首先利用公式(3)度量出文档间关系,然后在传统的向量空间模型的基础上融入文档关系,实现对模型的改进. 检索结果的前m篇文档一般可以更好地表达用户的查询意图,故利用集合S中的文档dj与基准集B的相似度,来修正文档dj与查询q的相似度,实现对VSM模型的改进,如公式(4)所示,把这种检索方法称之为VSM_Improve模型. sim_improve(dj,q)=αsim(dj,q)+(1-α)sim(dj,B), (4) 其中,α为调和参数,sim(dj,q)为文档dj与查询q的相似度,sim_improve(dj,q)为文档dj与查询q改进后的相似度. 在信息检索评测领域,目前没有构建标准的中文信息检索测试集[15].文献[15]建立的中文信息检索数据集,适合一般的小型实验测试,并且在一些实验中多次使用,因此本文采用该数据集进行实验验证.该数据集中共有1 578篇中文文档,文本内容主要是与计算机相关的一些领域,其中主要包括5个查询主题,每个查询主题有各自的相关文档集.专家已经对相关文档集进行了相关性评分,评分取值为{0,0.1,0.2,…,1},评分的值越大文档越相关,其中,1表示完全相关,0表示毫不相关. 论文采用信息检索中常用的2种评价指标来检测改进模型的有效性,分别是折损累计增益(discounted cumulative gain,DCG)和准确率-召回率曲线. DCG值[16]既考虑检索结果中文档的相关性,也考虑文档在检索结果中出现的位置,它是依据相关文档在检索结果中排序的位置来给出该文档的分数,DCG值越大则说明排序结果越合理.假设相关文档排序靠前,则其价值较高,否则价值较低,相应地做出贡献则较少.DCG值计算方法如公式(5)所示. (5) 其中,|k|表示检索结果按照相关性从大到小依次排列,取前k个结果组成的集合.Si表示结果列表前k个文档集合中第i个文档的相关性得分,它的取值为0~1.Si=0表示第i个文档与查询毫无关系,Si=1表示第i个文档与查询完全相关. 准确率-召回率曲线用来说明检索结果中的相关文档是否准确和全面[17].准确率(Precision)和召回率(Recall)的计算公式分别如公式(6)和公式(7)所示. (6) (7) 其中,|A|表示该系统中检索到的所有文档的数目,|B|表示该系统中与查询有关的所有相关文档数目,|R|表示该系统中检索到的相关文档数目. 3.3.1 相关参数的确定 1)相关文档的数量m值的确定 基准集B中相关文档的数量m的确定非常关键,如果选取的相关文档太少,则文档之间的关系无法充分发挥作用,便会遗漏掉一些相关信息;如果选取的相关文档太多,不相关文档的数量也会增多,则会引入大量噪声.为了探讨合适的基准集B,进行了参数训练,分别计算出当相关文档m的取值为5、10、15、20时,查询在数据集中的平均DCG值,如表1所示. 表1 m不同取值下查询的平均DCG值 从表1可以看出,当m=5时,查询的平均DCG值较高.通过观察初始查询结果可以发现,查询的前5篇文档大部分是相关的,而随着文档数量的增多,会出现相关度不高的文档以及不相关文档,进而会引入噪声.故对于本测试集来说,将相关文档m的数量设定为5较好. 2)参数α的确定 为合理地将文档与查询的相似度、文档与基准集的相似度进行融合,实验对参数α的取值进行训练.在α分别取0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0时,分别计算查询在数据集中的平均DCG值,实验结果如表2所示. 表2 参数α的不同取值下查询的平均DCG值 从表2可以看出,当参数α=0.3时,查询的平均DCG值达到较高值.由于基准集中包含了与查询相关的术语,所以如果参数α取值较大,则在检索结果中无法合理体现文档关系的用途;而如果参数α取值较小,则用户的初始查询意图无法很好地起到相应的作用.故本文将参数α的值设定为0.3. 3.3.2 实验性能比较及分析 为验证VSM_Improve模型的有效性和准确性,通过构建10个查询,即在每个查询主题下分别构建2个查询,然后分别将VSM模型和VSM_Improve模型的检索结果降序排列,并用DCG值、准确率-召回率曲线对这2个模型进行性能评价. 1)DCG值的比较 对于构建的10个查询,分别在VSM模型和VSM_Improve模型中计算每篇文档与查询的匹配程度.由于用户在查看搜索引擎结果时,用户只关注前20~30个查询结果[4],如果用户在这其中未找到所需要的内容,用户将会重新构造查询.因此分别计算出这3种模型检索结果的TOP-10、TOP-20、TOP-30的平均DCG值.图2为10个查询结果的TOP-10、TOP-20、TOP-30下的平均DCG对比图. 从图2可以看出, VSM_Improve模型的平均DCG值在TOP-10、TOP-20、 TOP-30下均高于VSM模型.产生这种结果的原因是:一般情况下,符合查询需求的文档排序比较靠前,换言之,查询结果的前几篇文档更能充分表达用户的查询意图;利用文档关系,找出与基准集相似度高的文档,这些文档更能体现用户的查询需求,与简短的查询词相比,会使得查询结果更加准确和全面.故文中用文档与基准集的相似度来修正文档与查询的相似度,得到文档的最终相似度,实现对检索结果的重排序.若某篇文档与基准集相似并且与查询匹配程度也较高时,则该文档的排名会靠前,反之若与其中一个相似度较低时,文档的排名则会靠后,因此VSM_Improve模型会提高相关文档的排名,同时会剔除不相关的文档. 图2 2种模型的查询结果在Top-10、Top-20、Top-30的DCG对比Fig.2 DCG comparison of query results of two models in Top-10、Top-20、Top-30 2)准确率和召回率的比较 这部分实验分别计算了基本模型和改进模型在10个查询下,当召回率的值为10%、20%、30%、40%、50%、60%、70%、80%、90%和100%时,其相应的准确率,最后计算出这10个查询的平均准确率,并绘制出准确率-召回率曲线,如图3所示. 图3 准确率-召回率曲线Fig.3 Curve of precision-recall 由图3可以发现,在召回率相同的情况下, VSM_Improve模型的准确率高于VSM模型.在召回率为10%、20%、30%、40%时,虽然VSM_Improve模型的准确率高于VSM模型,但是2个模型的准确率相差不大,因此可以看出,检索模型的前几篇文档一般情况下是满足用户查询需求的.通过模型的改进之后,会剔除一些排在前面的不相关文档,并且提高相关文档的检索概率.产生这种结果的原因是:在实际信息检索过程中,用户输入的查询词一般比较简短且模糊,不能准确表达自身的信息需求,因此会导致查询的准确率和召回率不理想.由于与查询相关的文档间会有一定的相似性,这些相关文档在一定程度上可以很好地表达用户的查询意图,故本文利用文档间关系,通过找出与相关文档集相似度较高的文档,可以使得查询结果更加全面和准确. 考虑到用户输入的查询词一般较少,对信息需求的表达往往不够准确和全面,导致查询结果不理想的问题,本文提出一种改进的向量空间模型,利用文档间关系,找出与基准集中的篇文档均相似的文档,进而找出查询的相关文档,并将每篇文档与基准集的相似度、每篇文档与查询的相似度进行融合,进而提高了检索效果,使得检索结果更加合理.接下来将尝试分析文档间的其他关系,并在信息检索模型中进行实现.2.2 改进的向量空间模型
3 实验
3.1 实验数据集
3.2 评价标准
3.3 实验结果及分析



4 结束语
