融合用户兴趣度和信任度的协同过滤推荐算法
2020-07-20苑宁萍辛力坚王呼生宁鹏飞
苑宁萍,辛力坚,王呼生+,宁鹏飞
(1.内蒙古医科大学 计算机信息学院,内蒙古 呼和浩特 010110;2.内蒙古电力科学研究院,内蒙古 呼和浩特 010020)
0 引 言
协同过滤(collaborative filtering,CF)存在因数据稀疏、冷启动等造成的推荐精度低等问题。为此国内外学者们进行了大量的研究[1-7]。文献[8]为了解决其中的用户冷启动问题,将用户社交信息和评分信息进行融合,提出了一种基于社区专家信息的协同过滤推荐算法;文献[9]采用稀疏评分矩阵建立用户评分项目集合,对评分矩阵进行降维、构建近似评分矩阵并填充用户项目的评分集合,得到用户间相似度;文献[10]利用深度学习来决定矩阵分解中的初始化问题,实现信任效应对推荐的影响;文献[11]提出了一种高效的角色挖掘推荐算法,利用用户间共识向组内其他用户推荐服务;文献[12]利用用户提供的稀疏评估数据和稀疏社交数据来提高协同过滤的推荐效率。
研究结果表明,用户对社交活动的选择多基于兴趣爱好,并且往往与具有相同兴趣爱好的用户保持紧密联系[13,14]。近年来,大多数的研究只注重利用用户对社交活动的评分,忽略了用户对活动的兴趣和用户间的信任度,致使改进算法推荐精度提高有限。基于此,本文提出了一种融合用户兴趣度和信任度的协同过滤推荐算法。
1 基于兴趣度和信任度的模型描述
本节对基于兴趣度和信任度的个性化推荐模型进行详细描述。在本文构建的个性化推荐模型中,假设用户集合为U, 被评价过的社交活动集合为S, 未被评价的新社交活动集合为S′, 用户间可能存在信任关系,设为信任矩阵为TR。 设目标用户为ui∈U, 本文的目的就是利用融合兴趣度和信任度的协同过滤算法预测ui对未被评价的社交活动集合S′的评分,然后按照Top-N排序规则将排名靠前的社交活动推荐给目标用户ui。
1.1 用户对活动兴趣度表示
用户对社交活动的兴趣度是考量用户是否参加活动的重要影响因素之一。本文利用文件主题模型(latent Dirichlet allocation,LDA)求取用户ui参加过的社交活动S的主题分布,并用其表示目标用户ui的兴趣度。为了便于计算,我们设φt表示隐含主题t在单词集合上的多项式分布,设fileui表示目标用户ui参加的社交活动内容所形成的文件,利用文件主题模型可求出社交活动内容文件fileui所有的隐含主题多项式分布。参考文献[15]我们可以利用文件主题模型中的狄利克雷函数Dirichlet(α)、Dirichlet(β) 分别求取隐含主题与单词的概率分布δt和文件与单词的概率分布φfileui, 利用多项式分布函数Mult(φfileui)、Mult(δtfileui,m) 对文件fileui中的第m单词生成主题分配tfileui,m和单词wfileui,m, 其中α、β为两个狄利克雷函数的参数。用户文件fileui的似然函数为
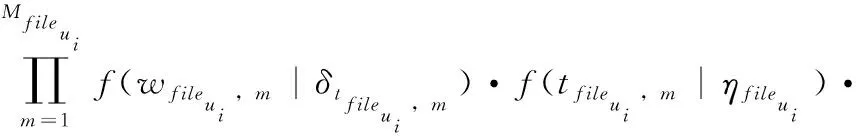
(1)
式中:wfileui,Mfileui,ηfileui,Ψ分别表示文件fileui中所有单词、单词的数量、单词的主题分配、单词对应的主题-单词概率分布。
设在文件主题模型中文档间是相互独立的,则Numf个文件的完全似然函数如下
(2)
式中:Wo,T,Υ分别表示文件中所有单词、主题的分布以及所有文件-主题词概率分布。我们几乎不可能从似然函数中推断出参数Υ和Ψ,并且难以直接从某一多变量概率分布中近似抽取样本序列,针对于此,采用吉布斯采样将隐含主题词t从联合的概率分布中采样出来

(3)
(4)
(5)

(6)
设目标用户ui的文件为fileui, 新社交活动sj的文件为filesj, 两者所对应的主题分布为φfileui和φfilesj, 为了求取用户与社交活动的主题的相似度,本文引入库尔贝克-莱布勒散度(Kullback-Leibler,KL)[16]和延森-香农散度(Jensen-Shannon)[17]来计算两者之间的相似度,Jensen-Shannon定义为

(7)
式中:KL(·) 表示库尔贝克-莱布勒散度,其定义为
(8)
JS(ui‖sj) 会随着φfileui和φfilesj两者主题分布的差别而增大,这里定义目标用户ui对社交活动sj的兴趣度为inui,sj
inui,sj=1-JS(ui‖sj)
(9)
1.2 用户间信任度表示
在网络社交活动中,用户间的信任一般分为直接信任和间接信任[18]。直接信任顾名思义就是基于用户间的某种认知而产生的一对一信任,而间接信任就是用户因某个中间人的推荐而对另一个用户的信任。通常情况下用户间的信任值用[0,1]内的某个数值表示,信任值越趋于1越信任,信任值为0表示不信任。
定义1 信任网络:对于给定的社交活动网络,可将其对应的看出一个用户间因信任值而形成的信任网络Q=(U,E,D), 其中U为用户集合,E为信任网络中有向边集合,边e(ui,uj) 表示用户ui对用户uj的信任关系,D表示有向边上的信任度集合。
定义2 信任路径:在给定的信任网络Q=(U,E,D) 中,目标用户ui对非直接信任用户ux的信任感知是基于一条可达的路径p=(ui,…,uy,uz,…,ux), 并且路径p上任意边e(uy,uz) 的信任度都大于所设定的信任阈值wθ, 那么路径p就为一条信任路径。但信任也会随着路径的加大而衰减,所以我们在信任路径中规定一定的跳数阈值hθ。
一般来说在社交网络中,若一个用户被较多的其他用户所信任,那么一般表明此用户的可信度较高,反之亦然。基于此,我们借鉴Pagerank算法的思想求取用户的信任度
(10)
式中:Tui表示ui的信任用户集合,|Tui| 表示集合的大小,Nuj、Nur分别表示uj、ur被信任的用户个数。图1中用户节点间的信任度是基于用户面对面的直接信任产生的,但在实际的社交网络中,许多用户间可能不存在或存在不明显的潜在信任关系,这样得到的信任矩阵非常稀疏,计算信任相似度的难度就会难上加难。

图1 用户间信任网络
为此,本文在计算用户信任矩阵前,引入信任传递以计算无交集用户间的信任度,若两个用户间没有直接信任关系,其信任度的计算公式如下
(11)
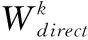
(12)
如图1中,设信任阈值wθ=0.5,hθ=3, 那么我们若是计算用户u2对用户u7的间接信任,则存在4条路径:u2→u6→u4→u7、u2→u6→u3→u7、u2→u5→u3→u7和u2→u5→u3→u1→u7, 而根据信任阈值wθ=0.5,hθ=3, 最终剩余u2→u6→u4→u7、u2→u6→u3→u7和u2→u5→u3→u7这3条信任路径。据式(12)得:W(1)=0.624*0.761=0.4749,W(2)=0.725*0.746=0.5409,W(3)=0.624*0.588=0.3669根据式(11)用户u2对用户u7的间接信任Td′u2,u7
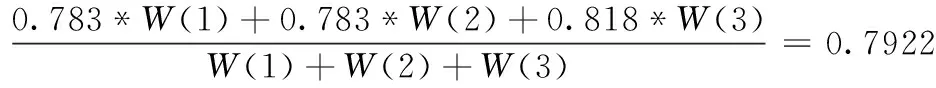
那么用户之间的信任度可表示为
基于以上各用户间的信任度值建立用户信任矩阵,这里用UT表示
(13)
式中:utumun表示用户um对用户un的信任度。
在基于社交活动的网络中,用户对其曾经参加的社交活动会有一个评价,所有用户对其所参加的所有活动的评价就形成了用户-社交活动评价矩阵,这里用US表示
(14)
式中:usmn表示用户um对社交项目sn评分,矩阵USm×n每一行都为用户ui对社交活动集S的具体评分,矩阵USm×n中的每一列是所有用户u对某一个社交项目si评分。
2 模型建立
基于前文中各相关因素,本节给出推荐模型建立的详细过程。
2.1 相似度融合
本节融合用户对社交活动的兴趣度和评分,构建新的兴趣度相似矩阵。
首先,获取用户-社交活动评价矩阵USm×n, 根据USm×n的元素利用Pearson相关系数计算目标用户与其他用户的相似度

(15)

(16)
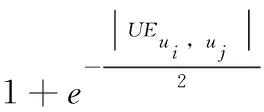
根据式(9),我们可以获得用户对社交活动的兴趣度矩阵INm×n
(17)
同理,根据INm×n的元素利用Pearson相关系数计算目标用户的兴趣相似度
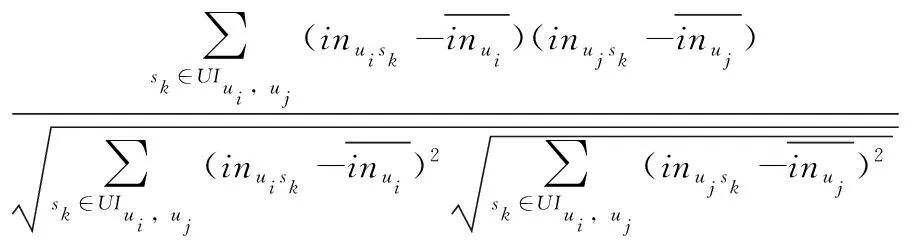
(18)

(19)
融合用户评分相似度和用户-社交活动兴趣相似度,可得综合用户相似度
sim(ui,uj)″=λsim(ui,uj)′us+(1-λ)sim(ui,uj)′in
(20)
式中:λ∈[0,1] 为调解参数,若λ=1表示没有考虑用户-社交活动兴趣相似度,即为传统的协同推荐算法。
2.2 个性化推荐
在融合用户-社交活动兴趣相似度的基础上,本文得出了用户间的综合相似度。但相似的用户是不是值得信任,推荐的社交活动能否得到目标用户的认可,是本文考虑的重点。为此本节在传统协同过滤推荐的基础上结合信任推荐的思想,将综合用户相似度与用户信任度相融合,得到个性化推荐权值

(21)
按照协同过滤推荐的步骤,采用修正后的个性化推荐权值Weui,uj加权修正原推荐公式
(22)

3 实验数据与参数设置
3.1 实验数据及评价标准
为了获得较大的社交数据,选取一线城市北京、上海、广州豆瓣同城2017年1月1日-2019年2月28日期间的所有社交活动。主要采集的信息为:用户信息(用户名、用户ID、用户的兴趣、用户对所参加过的社交活动的评分),社交活动信息(社交活动类别、社交活动的内容、社交活动ID等),数据统计见表1。

表1 数据统计明细
仿真实验将Top-N推荐算法推荐结果,采用Precision@N、Recall@N、MAE(mean absolute error)和覆盖率(Coverage)这4个评价指标评估各算法推荐的性能
(23)
(24)
式中:Reui,N、Teui分别表示各算法按照Top-N推荐给目标用户ui的社交活动以及用户ui在测试集中所参与的活动集合, |*| 为计算集合大小,这里设置N=1,3,5,7,10
(25)
式中:Pi为候选社交活动i的预测评分,Hi为活动i的实际评分,N为候选社交活动个数
(26)
其中,R(u) 表示向目标用户推荐社交活动集合。
3.2 参数设置
在文件主题模型中需要对参数进行优化设置,并且调节参数的大小这直接影响着算法推荐的效果,各参数设置如下:
(1)文件主题模型参数设置
实验采用自然语言处理框架Gensim实现文件主题模型,在模型中设分布函数参数β=50/Numk,α=0.01, 为了获得隐含主题t的最佳个数Numk, 利用豆瓣同城北京、上海和广州数据集测试文件主题模型在不同的Numk下Precision@5和Recall@5, 结果如图2所示。
通过图2我们可以看出在不同数据集上,随着隐含主题数的增大,评价指标Precision@5、Recall@5变化是有差别的。在豆瓣同城北京数据集上,评价指标Precision@5和Recall@5随着隐含主题个数Numk的增大而增大,在Numk≤60前期阶段,两个指标的增幅较大,在后期两个指标的增幅缓慢趋于平稳。当Numk=100时,两个评价指标Precision@5和Recall@5取得最高值。

图2 不同隐含主题Numk下Top-5推荐性能
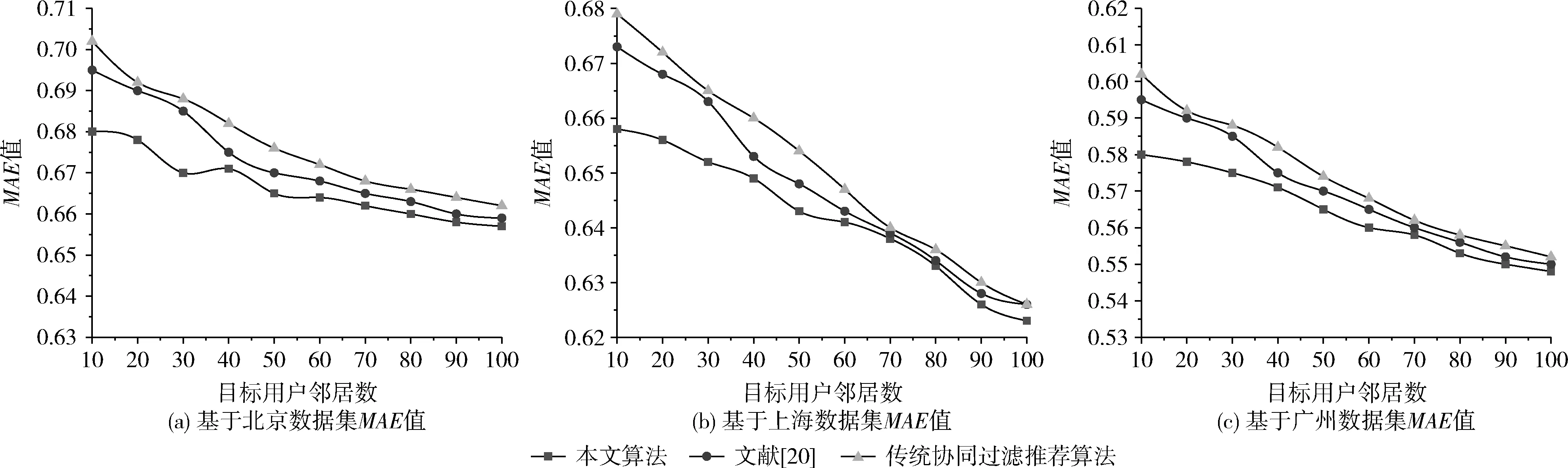
在豆瓣同城上海数据集上,在Numk≤80前期阶段,推荐评价指标随隐含主题个数Numk的增大而增大,在80 (2)调节参数λ的设置 调节参数λ是融合用户评分相似度和用户-社交活动兴趣相似度的关键参数。设目标用户邻居个数Num=10、20、30、40、50, 本文算法的MAE值跟参数λ的关系如图3所示。 图3 调节参数λ与MAE之间的关系 在不同的目标用户邻居数下,本文算法的MAE值随着参数λ的增大基本趋势是一致的,即随着λ值的增大先减小后缓慢增大。其中当邻居规模Num=30, 参数λ=0.4时MAE值最小,邻居规模Num=50, 参数λ=1时MAE值最大。综合考虑,为了获得最优效果,设邻居规模Num=30, 调节参数λ=0.4。 本文实验的硬件环境为Intel(R) Core(TM) i5-8400@2.8 GHz,RAM:8 GB,软件环境为:Windows 7操作系统,使用Python编程实现。这里我们将已结束的社交活动作为训练集,将新的社交活动作为训练集,为验证本文所提算法的性能,将本文算法与传统协同过滤推荐算法、文献[20]进行目标用户新社交活动推荐效果对比。 本节将3种算法对已有用户社交活动的推荐结果进行对比分析。通过图4这3种算法在Top-N(N=1,3,5,7,10) 下的推荐评价指标对比可以看出,本文提出的个性化推荐算法在不同N值下的推荐指标明显好于其它两种推荐算法,说明本算法在综合用户对活动的兴趣度、用户间信任度后能够取得较好的推荐结果。其中图4(a)和图4(b)为3种算法在豆瓣同城北京数据集上的推荐结果,其中在Top-N(N=1,3,5,7,10) 的推荐中,本文算法相较于文献[20]和传统协同过滤推荐算法的准确率至少提升了5.88%和12.5%,召回率至少提升了约7.84%和23.53%;图4(c)和图4(d)为各算法在豆瓣同城上海数据集上的推荐结果,本文算法相较于文献[20]和传统协同过滤推荐算法的准确率至少提升了5.26%和21.42%,召回率至少提升了约8.57%和19.23%;图4(e)和图4(f)为各算法在豆瓣同城广州数据集上的推荐结果,本文算法相较于文献[20]和传统协同过滤推荐算法的准确率至少提升了4.92%和18.18%,召回率至少提升了约7.89%和12.73%。 图4 各算法Top-N推荐评价指标对比 为了比较本文算法与其它两种算法在MAE上的差异,这里固定调节参数λ=0.4, 以目标用户邻居数目为变量,3种算法MAE值的变化如图5所示。 图5 不同算法间的MAE对比 通过图5可以看出,3种算法随着邻居数目的增加,MAE值都呈下降的趋势,但本文算法的MAE值整体上都小于其它两种算法。在豆瓣同城北京数据集上,当邻居数目Num>50后,3种算法MAE值下降的幅度缓慢,邻居数目Num≤50前,本文算法的MAE性能优势更明显;在豆瓣同城上海数据集上,当邻居数目Num>60后,3种算法MAE值下降的幅度缓慢,基于MAE值的优劣区分度不高,而邻居数目Num≤60前,本文算法的MAE值相较于其它两种算法更小,社交个性化推荐的误差更低;在豆瓣同城广州数据集上,邻居数目Num=70为分界点,Num>70后3种算法MAE值下降幅度缓慢,MAE值大小接近,但整体上相较于其它两个数据集,MAE值都要小,推荐的精度较高,这是由于在广州数据集上对活动的评分反馈信息量大于其它两个数据集。 本节以目标用户邻居数目为变量,观察3种算法在3个数据集上的推荐覆盖率,其实验结果如图6所示。 图6 不同算法间的Coverage对比 通过图6可以看出,3种算法随着邻居数目的增加,覆盖率会不断提高,但后期覆盖率增幅都趋于平缓。在3个数据集上,本文算法的覆盖率都远远大于其它两种算法,这是由于本文算法将用户对社交活动评分、兴趣和用户间的信任度融合到推荐中,扩大了潜在社交活动的推荐范围,从而提高了推荐活动的覆盖率。 本文在传统协同过滤推荐的基础上融合用户兴趣度和信任度,提出了一种个性化推荐算法。算法综合用户对社交活动的兴趣度和评分,构建新的兴趣度相似矩阵得到用户间的综合相似度,将综合用户相似度与用户信任度相融合,得到个性化推荐权值,以不同的权值配比获得最终的社交化活动推荐。利用豆瓣同城数据集分析确定了文件主题模型参数和调节参数λ值。与其它两种算法对比可知,本算法不仅取得了较高的准确率和召回率,在覆盖率和推荐误差上也有较好的表现,但推荐精度的提高可能要增加时间和空间消耗,将本文算法并行化处理以降低时间复杂度是后续研究的重点方向。
4 仿真实验与对比分析
4.1 不同算法的准确率和召回率对比

4.2 不同算法的MAE对比
4.3 不同算法的覆盖率对比

5 结束语
