跨深度的卷积特征增强目标检测算法
2020-07-20王若霄徐智勇张建林
王若霄,徐智勇,张建林
(1.中国科学院 光电技术研究所,四川 成都 610209;2.中国科学院大学 电子电气与通信工程学院,北京 100049)
0 引 言
随着深度卷积神经网络的发展,目标检测领域因卷积神经网络强大的特征提取能力而发展迅猛,一般可分为双阶段和单阶段两类检测算法。双阶段检测算法因比单阶段检测算法多了区域提名阶段故精度较高,但推断速度较慢。单阶段算法以YOLO(you only look once)[1]、SSD(single shot detector)[2]为典型代表。本文基于检测系统的实时性对单阶段检测算法进行研究并针对单阶段算法的缺陷进行改进。尺度变化问题十分重要,因为目标的尺度变化范围太大会严重影响检测系统的性能。为了解决尺度变化问题,一个通用的方式是采取多尺度训练来模拟图像金字塔[3],但这仅是训练策略。单阶段检测算法由于缺少区域提名阶段,故对于尺度变化更易受到影响,单阶段算法为了解决尺度变化问题有了系列措施,SSD算法采用了多尺度预测,且设置了多种宽高比的预设框。YOLOv3[4]采用了特征金字塔结构[5]级联深层特征和浅层特征,浅层检测层加入深层语义信息有利于检测小目标。但这些算法解决尺度变化问题是不足够的,SSD只利用多层特征图分别进行检测,而不同特征层之间并没有联系起来;YOLOv3采取的特征金字塔策略仍有许多缺陷,感受野仍不够大。为了解决这些问题,本文提出了一种跨深度卷积特征增强的目标检测算法,称之为CDC-YOLO(cross depth convolution-YOLO),基于YOLOv3算法上进行改进。每层预测层针对它们所对应的感受野的不同分别采用不同的特征增强模块,即不同的多通道跨深度卷积模块(CDC系列模块)。CDC系列模块能充分利用多尺度多深度特征,形成统一的多尺度特征表达,改善各尺度特征图对目标尺度变化的适应能力,以提升网络对各尺度目标的检测能力。提出的算法能较好地解决尺度变化问题,并在VOC2007测试集上提高了mAP。
1 相关算法
1.1 基于深度学习的双阶段目标检测算法
从R-CNN[6]开始,基于深度学习的双阶段目标检测算法便成了研究的热门,各类基于R-CNN的改进层出不穷。两阶段算法主要是先进行候选框的区域提名,再对候选框进行多分类和精细的回归。自R-CNN之后,Fast-RCNN[7]、Faster-RCNN[8]、Mask-RCNN[9]等相继提出,改进的目的都是为了使得双阶段网络在保持精度的同时提高检测速度。双阶段检测网络一直都在致力于提高检测速度以提高检测系统的实时性和实用性,但是与单阶段检测网络相比,仍然不够简洁,推断速度仍不够快。
1.2 基于深度学习的单阶段目标检测算法
单阶段目标检测算法没有了区域提名阶段,而是直接在骨干网络上加入检测头进行分类和回归,从而大幅度提高检测网络的推断速度。单阶段检测算法始于YOLO,代表算法为YOLO和SSD,在两个基础算法上出现了许多改进的算法。YOLO算法结构过于简洁,其速度很快但精度较低,SSD算法采用多尺度预测和瞄点框的策略提高了精度,但仍然与两阶段算法精度有差距。近年来出现了很多单阶段的检测算法,RetinaNet[10]主要是为了解决单阶段算法正负样本和难易样本极其不平衡问题,RefineDet[11]吸收了两阶段算法的优点,使得单阶段检测算法也能有双阶段算法的精度,RFBNet[12]使用空洞卷积提高感受野,构造出人类的感受野特点。这些算法的改进目的都是为了保持单阶段网络速度优势的同时提高精度。YOLOv3针对YOLO精度低的问题做出了改进,使用特征金字塔及多尺度预测来提高性能,但原文指出:通过新的多尺度预测,可以看到YOLOv3具有相对较高的小目标检测性能。然而,它在中、大尺度目标上的性能相对较差,需要更多的调查才能找到原因[4]。一个可能的原因是最深层检测层的感受野不够大,具体将在之后进行分析。
因而本文针对深层预测层特点采取多通路跨深度的卷积结构增强语义信息且带有不同膨胀率的空洞卷积增大并构造丰富的感受野,弥补感受野的不足。对于浅层预测层,由于深层小尺度特征图插值上采样过程中感受野不变,与浅层大尺度特征图级联过程会增大浅层的感受野,因而会降低浅层预测层检测小目标的能力。故针对该不足采用多通路跨深度的卷积级联的方式,这种级联方式不仅能充分利用多尺度信息,且由于每个通路卷积个数(深度)不同,能融合利用的网络深度语义信息就更加丰富。因此,针对多尺度预测层各自的特点设计相应的特征增强模块提高性能,以应对尺度变化问题。
2 网络架构
本文针对YOLOv3在3个尺度上:13×13、26×26、52×52特征图对目标表示及它们所对应的感受野的不同,对3个尺度的特征分别采用不同的特征增强方法,改善各尺度特征图对目标尺度变化的适应能力,以提升网络对各大小尺度目标的检测能力。本节首先分析YOLOv3的网络框架,然后介绍CDC-YOLO网络整体框架,最后介绍与各预测层相适应的特征增强模块并分析改进的算法为何能很好地解决尺度变化问题。
2.1 YOLOv3网络框架
YOLOv3用于特征提取的骨干网络采用分类网络Darknet-53,该网络由53个卷积层组成,是一种全卷积网络,网络结构见表1。该网络不再使用池化层,而用采用步长为2的下采样卷积代替池化层,构成全卷积网络,更适合于目标检测任务[13]。Darknet-53还借鉴了ResNet[14]的思想采用了大量shortcut残差结构,从而加强了特征的传递且降低了梯度消失的风险。YOLOv3的整体网络结构如图1所示,可看出网络采取了特征金字塔结构,使用特征金字塔结构可以利用多尺度预测,其中高层特征带有高级语义信息和较大的感受野,适合检测大目标,浅层特征带有丰富的空间信息和较小的感受野,适合检测小目标。对于设定的网络输入尺寸为416×416时,经过32倍下采样的13×13尺寸的特征图(即Darknet-53的第51层卷积层)作为最深层预测层,2倍上采样后与16倍下采样的26×26尺寸的特征图(即Darknet-53的第43层卷积层)级联起来,该级联结果作为中间预测层,该级联结果再2倍上采样与8倍下采样的浅层52×52尺寸的特征图(即Darknet-53的第26层卷积层)级联,这样做可以使得浅层融合深层传递上来的高级语义信息,提高特征的表示能力,从而提升浅层预测层检测小目标的效果。因此最终网络会有3个预测层,对于输入尺寸为416×416时,分别有13×13,26×26,52×52这3个尺度的预测层。此外,YOLOv3根据真值标签信息的大小进行聚类,获得了9个尺度的瞄点框,不同尺度的预测层采用不同尺度的预设框,能让每层预测层的预设框更为贴近该层的感受野,提高检测能力。

表1 Darknet-53网络结构
2.2 CDC-YOLO网络框架
CDC-YOLO算法不像YOLOv3将特征金字塔的各层预测层直接进行预测,而是根据各层预测层的特点后接了与之适应的特征增强模块再进行预测。其整体网路框架如图2所示。其中,52×52尺寸的预测层后接CDC2模块,26×26尺寸的预测层后接CDC1模块,13×13尺寸的预测层后接CDC0模块。通过在不同检测层上设计不同的感受野,以此增强特征表示,采用CDC系列模块的多尺度特征表达来应对尺度变化问题。
2.3 特征增强CDC模块
之前提过YOLOv3原作者指出尺度最小的13×13特征图,其感受野不够大难以适应大尺度变化,检测大目标效果不够好,现结合感受野分析原因。理论感受野计算公式如式(1)所示,式子中RFi+1是第i+1层的感受野大小,Ki是第i层的卷积核大小,Si是第i层的步长。根据该式子计算YOLOv3的骨干网络 Darknet-53 的每层卷积层的感受野大小(这里忽略了大量1×1卷积),如图3所示,最深层的感受野甚至超过了400,但这仅仅是理论感受野。文献[15]指出特征图的实际有效感受野小于理论感受野。这是因为并不是感受野内的所有像素对输出向量的贡献均相同,对同一个特征图进行卷积运算时边缘区域进行计算的次数会小于中心区域,随着卷积的不断堆叠,实际上会导致边缘感受野不断衰减,输入中越靠近感受野中心的元素对特征的贡献越大。衰减的分布大致是呈现高斯的,故实际有效感受野是一个高斯分布,有效感受野仅占理论感受野的一小部分。可见有必要增大深层的理论感受野,使得其实际有效感受野更大,才能有效地检测大目标
RFi=Si(RFi+1-1)+Ki
(1)
因而本文针对深层预测层的感受野的特点采取多通道跨深度的卷积特征增强模块CDC0,即在13×13深层预测层后接一个如图4所示的CDC0模块,该模块使用多个通路且深度呈现“阶梯状”且尺度各异的跨深度卷积核,这种卷积核结构在文献[16]中已有类似的应用,且取得了较好的效果。下面具体解释CDC0结构:

图1 YOLOv3网络框架

图2 CDC-YOLO网络框架

图3 YOLOv3各层感受野增长规律
(1)该结构是类似inception[17]的多通路网络结构,其共分为4个通路,每个通路均利用1×1的卷积将通道数(channels)降为1/4,分成4个通路的原因是各层检测层通道数目都是2的倍数,使用3个通路的话将无法均分,该层13×13卷积层的通道数目为1024,故每个通路均降维成256维度,每个通路均经过一系列卷积操作后concat级联起来,最终输出通道仍为1024。结构与inception不同的是,每个通路的卷积个数并不相同,即卷积结构跨深度,4 个通路分支均有不同的卷积层深度,不算上用于通道降维1×1卷积,第1个通路进行了1次卷积操作,第2个通路进行了2次卷积操作,第3个和第4个通路进行了3次卷积操作。输入信息经过不同的卷积层深度后级联起来能综合各个卷积深度的语义信息,使得语义特征丰富且多样。
(2)4个通路均采用了不同膨胀率的空洞卷积(其中第一个通路的膨胀率为1,即相当于没有采用空洞卷积),空洞卷积可以在不增加特征图的尺度下增大感受野,而每个通路采用不同的膨胀率可使得每个通路分支均具有不同感受野大小,构造丰富多样的感受野大小,可以更好地应对不同尺度的目标,更加适应于尺度变化。
(3)该模块中最后一个通路将5×5的卷积核拆为了1×5和5×1的卷积,相比拆为两个3×3卷积核更节省参数,有利于提高网络的推断速度。而且这种非对称的卷积结构拆分,比拆分为几个相同的方形卷积核效果更好,能够处理更丰富的空间特征,增加特征多样性[18]。以上几个方面均能提高13×13预测层对大目标的检测能力,利用多尺度的特征形成统一的多尺度特征表达以应对尺度变化问题。

图4 CDC0模块
对于52×52尺度的浅层预测层,该层感受野小且空间信息丰富,有利于检测小目标,但只包含颜色、边缘等低级语义特征,检测小目标效果仍不够好,因而YOLOv3采用特征金字塔增强浅层特征,但深层小尺度特征图插值上采样成大尺度特征图过程中感受野并没有因此减小,与浅层大尺度特征图级联过程会增大感受野,降低模型检测小目标的能力。因此在该检测层后接CDC2模块以增强表示能力,尽量提高该层的语义信息,以弥补浅层语义信息不丰富的缺陷。CDC2模块如图5所示。该模块使用多通路且跨深度的“阶梯状”卷积核,且同样在各个通路将方形卷积核拆分为条形卷积核。每个通路的卷积深度呈阶梯状,这样的跨深度结构能综合不同深度下的语义和空间信息,构造丰富的特征,能更好地应对尺度变化。这里并没有采用空洞卷积,是因为52×52特征图尺度较大,浅层预测层检测小目标不需要太大的感受野,文献[17]指出感受野越大对小目标检测效果越不好。RFBNet也利用多尺度卷积结构并使用了空洞卷积增大感受野,但其不足是没有针对不同深度的预测层的各自特点单独设计模块,在浅层预测层和深层预测层均采取相同膨胀率的空洞卷积(分别为1,3,5),本文通过实验佐证了浅层特征图用大的膨胀率反而降低对小目标的检测能力,经过实验验证发现,如果CDC2模块中第1个和第4个通道分别采用膨胀率为1和2的空洞卷积,其它模块均不变时,训练后在VOC2007test测试的结果见表2,可以看出,浅层使用空洞卷积后不仅速度变慢,精度也有下降,尤其体现在瓶子这类小物体上,对于鸟类小目标的检测性能得下降也很明显。而且RFBNet还有不足是模块的每个通路卷积个数相同,没有充分利用跨深度的信息。
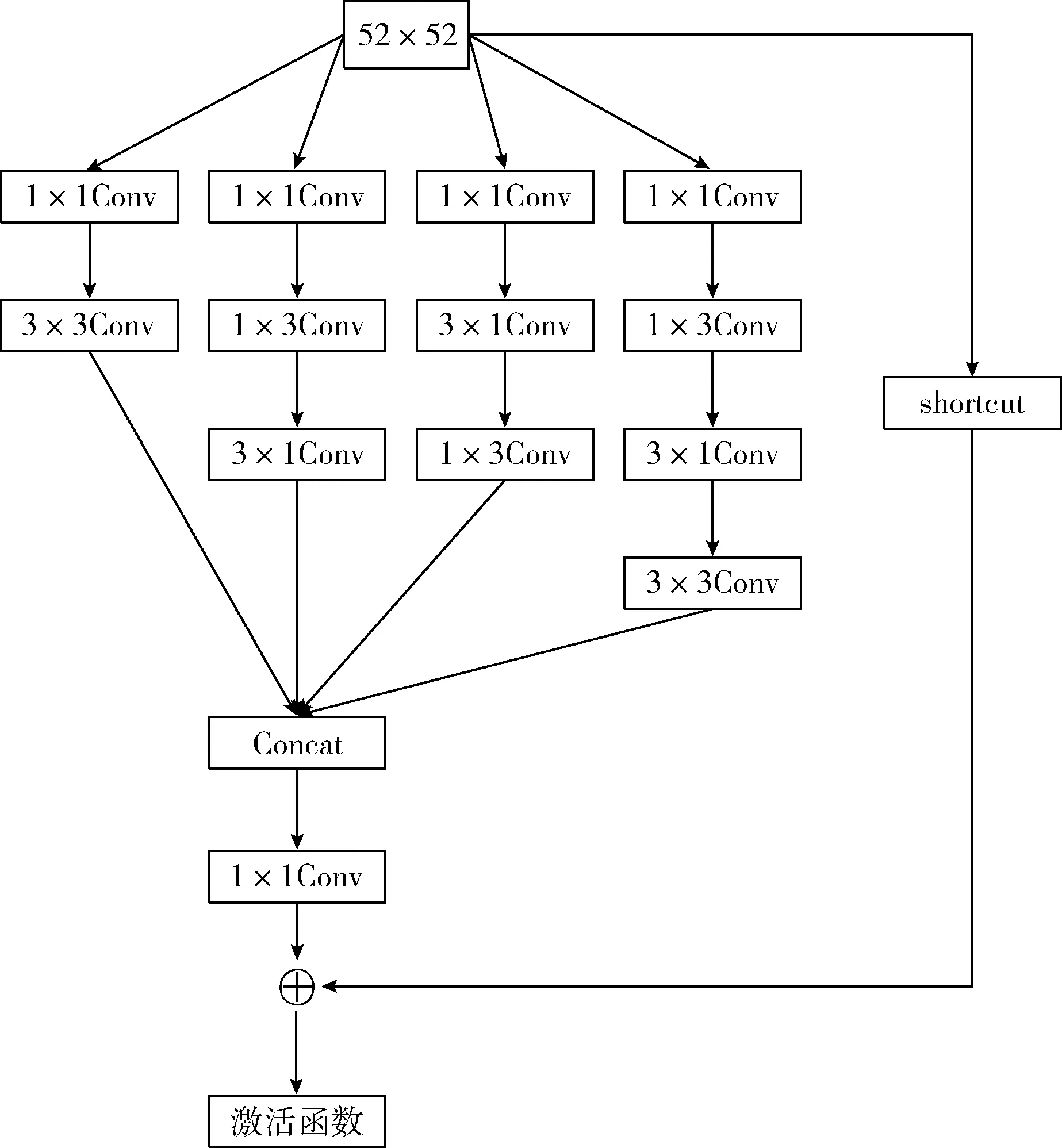
图5 CDC2模块

表2 CDC2采用空洞卷积与否的对比实验
对于26×26尺度的预测层,该预测层检测中间尺度的目标,后接如图6所示的CDC1模块,该模块同样采取了不同尺度的跨深度卷积核,也同样将方形卷积拆分成两个条形卷积。结构中第2条通路先经过1×3横形卷积,再经过3×1竖卷积,第3条通路先经过3×1竖形卷积再通过 1×3 横形卷积,条形卷积和方形卷积不同,更加对条状目标敏感,1×n对于横形物体更加敏感(如汽车、铁轨等),n×1对于横形物体更加敏感(如行人)。这里使用了膨胀率为2和3的空洞卷积,因为该层检测中间尺度的目标,并不需要52×52检测层那样检测大目标,感受野不需要那么大,因此膨胀率需要设置小一些。
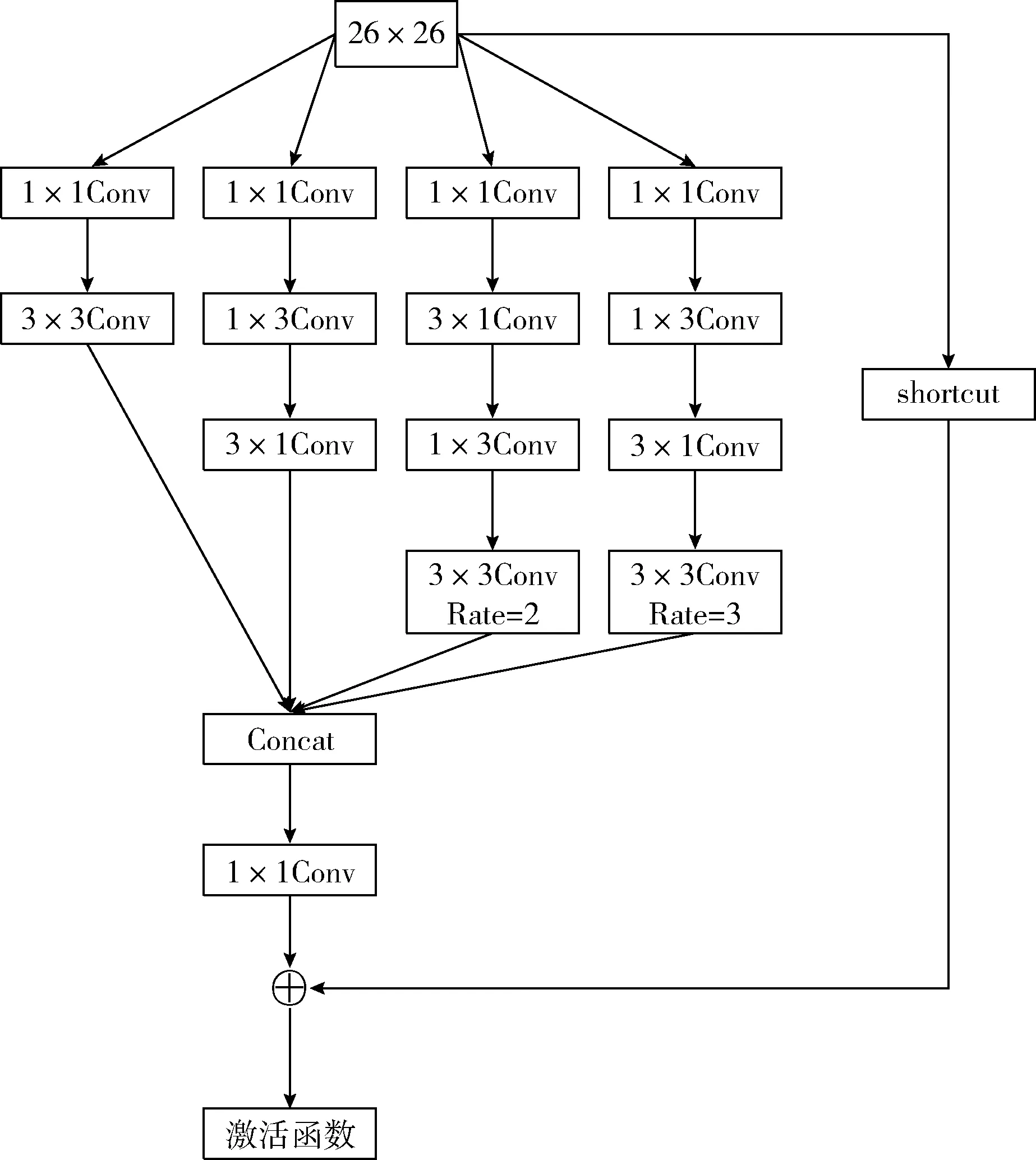
图6 CDC1模块
为了验证跨深度的卷积结构是有效的,本文设置了对照实验,在3个检测层后不再分别采用CDC0、CDC1、CDC2模块,而是均采用如图7所示的非跨深度的类inception卷积结构,该模块的每个通路的卷积核个数均相同,也就是各个通路的卷积深度是相同的,且没有针对每个检测层各自的感受野特点去设计不同的特征增强模块。VOC2007上的实验结果见表3,显然,跨深度卷积结构有着更优异的性能。
2.4 损失函数
本文所采用的损失函数分成了L1、L2、L3这3个部分,最终损失是它们的加和。

图7 非跨深度的特征增强模块

表3 采用跨深度卷积与否的对比实验

(2)

(3)


(4)
3 实验与结果分析
3.1 数据集训练与测试
本文的实验在配有i5-8400的CPU和1080Ti显卡的PC机上运行,本文使用标准数据集VOC2007和VOC2012 trainval作为训练集,采用VOC2007 test作为测试集来评估网络的性能。主干网络Darknet-53采用Imagenet数据集进行了预训练,便于检测网络的权重微调。网络的输入尺寸为416×416,采取随机梯度下降法,动量设为0.9,权重衰减设置为5×10-3,一共迭代100个epoch,一次性送入训练的图片为16张,初始学习率为10-3,50个epoch后学习率下降10倍,80个epoch后学习率再次下降10倍。本文使用检测算法最常使用的mAP(平均均值精度)指标来检验网络的性能,如表4所示,为目前经典的检测算法与本文算法CDC-YOLO的性能对比,这些算法均在VOC2007和VOC2012 trainval训练,在VOC2007 test进行测试,且均在同一软件和硬件下训练与测试。表5显示了本文改进后的算法和原始YOLOv3的性能对比。
3.2 结果分析
从表4可以看出,YOLOv3比YOLOv2的mAP高很多,得益于特征金字塔模块,尤其瓶子这类小目标检测精度提高最大。而CDC-YOLO有着最高的mAP,不仅瓶子这类小目标检测精度有较大提高,对于鸟、人等尺度变化大的类别的检测精度也有较大的提高,体现了算法对于目标尺度变化的鲁棒性。从表4也可以看出,CDC-YOLO在大幅度提高精度的同时,没有折损太多检测速度,满足实时性要求。
3.3 主观结果分析
本文在用Pascal VOC训练完成后,为了验证在除Pascal VOC测试集外的实际场景图片里CDC-YOLO是否真的能更好地处理尺度变化问题,因而找了一些图片作为验证。如图8所示是针对目标尺度变化范围较大且复杂场景下的检测结果对比,图8(a)的3张图是YOLOv3的检测结果,而图8(b)的3张图是本文CDC-YOLO检测结果。可以看出复杂场景下YOLOv3明显漏检了一些尺度较小的行人,而CDC-YOLO 基本能够检测到这些行人。主要因为行人的尺度变化范围较大,需要对尺度变化非常敏感才能做到。通过这些例子可知 CDC-YOLO 不仅检测精度高于 YOLOv3,且由于对尺度变化更为敏感,因而召回率也更高,漏检率降低。
4 结束语
本文提出了一种基于深度学习的目标检测算法CDC-YOLO,通过在YOLOv3的多尺度预测层后分别接入与各检测层的特点相适应的跨深度卷积特征增强模块,该模块能综合利用多种网络深度的空间信息和语义信息,也能够构造多种感受野大小,提高检测层的表示能力以及应对多尺度目标的能力。跨深度卷积结构能改善各尺度特征图对目标尺度变化的适应能力,形成统一的多尺度特征表达,以提升网络对各大小尺度目标的检测能力。实验结果表明,改进后的算法的mAP有较大的提升,而且对尺度变化大的物体更加鲁棒。在保证精度提高的同时不会折损太多检测速度,满足实时性要求。

表4 不同检测算法在VOC2007 test上的检测结果/%

表5 改进前后性能对比

图8 YOLOv3与CDC-YOLO复杂场景下检测结果对比
