采用局部边缘模型匹配的视频均衡编码算法
2020-07-20路标
路 标
(1.中国矿业大学 计算机学院,江苏 徐州 221116;2.徐州幼儿师范高等专科学校,江苏 徐州 221000)
0 引 言
视频编码包含两个互补过程:编码和解码,可通过编码优化来消除时间域和空间域冗余。考虑两种视频编码类型:无损编码和有损编码[1,2]。为了更高的压缩,有损视频编码是必需的,因为无损视频信息只允许中等压缩。与上述算法兼容的标准已经开发出来,可提供高质量、低失真和低比特率传输[3]。
为减少编码器计算负荷,可利用分布式视频编码方法(DVC)来实现低级别复杂度的视频编码,将复杂度从编码器转移到解码器中。例如,文献[4]提出空间域分布式视频编码系统,实现对包含快速运动和复杂运动的序列的改进。文献[5]在编码器和解码器中均执行DVC运动估计方案,编码器和解码器的协作可在提高编码效率的同时降低整体计算复杂度。文献[6]提出在编码器执行全局和局部运动估计,而在编码器和解码器上同步进行运动估计和补偿。文献[7]在解码器只执行局部运动估计,而在编码器中基于尺度不变特征变换(SIFT)进行全局运动估计。DVC运动估计方案有效地降低了编码器的复杂度,但也造成一些问题,两个主要缺点是性能表现不佳和解码器复杂度高。
为此,本文提出基于填充块的轻量级视频编码(PBLVC),所提出的方法在解码器使用局部边界匹配算法(PBMA)替换在编码器上的运动估计。另一个高复杂度算法,模式决策,通过4种不同的灵活模式,也需要从编码器转移到解码器。同时,所提方案由于设计思路不同而无法使用传统DVC架构,这里同步设计了一种块级设计和填充算法。
1 背景算法描述
1.1 H.264/AVC视频编码传统运动估计
所有传统视频编码标准都采用块式运动估计编码,用于减少时间冗余。率失真优化(RDO)函数是一种实现性能和运动估计的数据流量之间的最佳模式的综合评价方法[8,9]

(1)
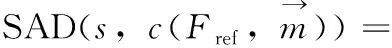
(2)
其中,N是图像块的大小, (x,y) 是参考帧的像素, (dx,dy) 表示运动矢量。然而,编码器复杂度是由运动搜索中累加叠加造成的。因此,式(2)表明,编码器采用运动估计带来高复杂度编码器加载,如图1所示。

图1 传统视频编码器的运动估计
1.2 基于PBMA的解码器运动估计
在传输视频编码器中,高性能运动估计本质上是一种高计算复杂度算法,如果没有高效率的运动估计,性能可能会降低超出预定义的容忍范围。该方案采用PBMA代替运动估计的功能,具体如下[10,11]
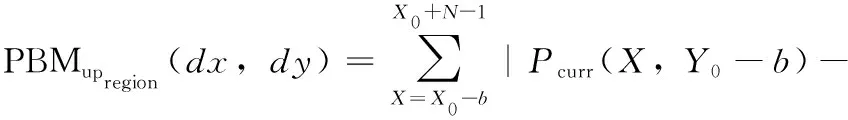
由此可得
PBM(dx,dy)=
PBMupregion(dx,dy)+PBMleftregion(dx,dy)
(3)
式中: PBM(dx,dy)、 PBMupregion(dx,dy)、 PBMleftregion(dx,dy) 分别为PBMA算法SAD函数的总值、上方区域和左方区域。 (dx,dy) 是候选运动矢量。Pcurr(X,Y) 和Pref(X,Y) 分别表示当前帧和参考帧的像素值。 (X0,Y0) 是起始图像块的位置。这里,N是图像块的大小,b是模板邻域大小。
PBMA算法和BMA算法的主要差别是,BMA算法使用图像块的所有相邻像素作为模板,而PBMA只使用部分的相邻像素作为模板,一般只选取两个相邻像素[12],因为相邻像素的解码块还没有被解码。如图2所示,每个方格作为一个像素。

图2 PBMA的匹配区域
1.3 模式决策H.264/AVC视频器的常规决策模式
H.264/AVC常规决策:传统的视频编码可以提高模式选择算法中的图像块选择灵活性,但是同样会增加图像块比较错误的比率。模式决策的RDO函数定义如下[13,14]
JMD(s,c,MD|λMD)=SSD(s,c,MD)+λMD·R(s,c,MD)
(4)
式中:MD表示模式决策,λMD是模式决策拉格朗日乘子。SSD函数是计算原始帧和参考帧之间的平方差之和。R(s,c,MD) 表示原始帧和参考帧之间的位编码。SSD函数可定义为如下形式
(5)
与传统的运动估计算法相类似,模式选择同样会遇到性能和复杂度之间的权衡。
LVC解码器模式决策:在解码器中所提出的模式决策具有4种不同的模式:模式0到3,其中模式(块类型)选自候选类型集 {4×4,4×2,2×4,2×2}。 最佳块类型的选择方法是用邻域像素计算平均加性差(MAD)。接下来,最好的块类型被按依次粘贴,解码器的模式决策完成。MAD计算形式为[15]
MAD(x,y)=SAD(x,y)/N2
(6)
其中, SAD(x,y) 是像素值的绝对差之和。
2 基于数据块的轻量级视频编码
2.1 算法框架描述
编码器算法框架:基于PB的LVC算法结构在编码器中由3部分组成:分类器模块、跳块掩码模块和重排模块(包括跳块记录表),以及传统帧内编码器,如图3所示。

图3 基于PB的LVC编码器
解码器算法框架:解码器由3个主要部分组成,包括传统的帧内解码器、块填充和像素填充,如图4所示。

图4 基于PB的LVC解码器
传统的帧内解码器首先从编码器解码视频流。解码后,对图像块进行填充,并将其分为零运动矢量置换(ZMVR)和部分边界匹配算法(PBMA),以替换高复杂度的运动估计算法。ZMVR和PBMA从跳块编码器获得跳块记录表信息,然后利用4种类型的块模式决策对零块和低运动块进行处理。采用PBMA算法基于邻域像素数据在跳块和候选搜索块中选择最佳匹配块运动估计,然后根据参考帧对其进行填充。在块填充后,对其余未使用块进行像素填充。像素填充方法包含本文提出的时空纹理合成(STTS)和传统的像素插值(PXI)。
2.2 编码器
该方案采用传统视频编码中的GOP帧编码结构,第一帧用传统帧进行编码,而其它帧使用跳块编码。这个过程与传统视频编码结果一样,帧内编码可防止整个GOP帧失真。具体包含如下5个步骤:
步骤1 分类器:分类器功能块,包括SAD和DC分类器。这些分类器用于识别零运动块和低运动块;因此,这种设计不适合确定中高运动块。SAD分类器可以用来确定SAD(0)(零运动块)。公式的定义如下
(7)
其中, SAD(x,y) 表示参考块和当前块间的SAD值, (x0,y0) 表示当前块坐标, Bcurr(x,y) 和Bref(x,y) 是当前和参考块像素值。在SAD分类后,进行DC分类,并对DC值(平均值)评估

(8)
其中, AVGcurr(x,y) 和AVGref(x,y) 分别是当前和参考块的DC值(平均值),该值有助于在低运动块部分像素重叠时轻松对低运动块进行搜索。因此,利用分类器块,很容易看出该LVC编码器采用局部帧间编码,而不是单纯采用传统DVC的帧内编码。
步骤2 跳块掩码和重排:跳过块掩码功能块,首先根据分类器块获得的结果屏蔽所有跳块,并将跳块的信息保存到跳块记录表中。掩码条件可设计为
来到后厢客厅,坤二少爷、百里香依次落座。庄大善人又招呼佣人捧上谷雨龙井,才满面堆笑地对坤二少爷说:“先生仙风道骨,一定不是俗人。庄某平生最敬重的,就是风水先生!”抿了口香茗,又说,“不过老朽有些疑问,先生您是怎么知道我家人丁不旺的?”

(9)
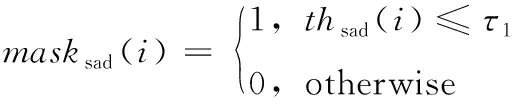
(10)

(11)
其中,thsad(i) 和thdc(i) 分别是SAD(x,y) 和AVG(x,y) 的微分值。如果图像块i的thsad(i) 和thdc(i) 如果分别小于阈值τ1和τ2, 则masksad(i) 和maskdc(i) 的取值均为1,操作中跳过这些数据块。否则,它被假定为一个非跳过块。在跳过块确定之后,重排块函数将用一个新顺序重新排列保留块(非跳过),该顺序将非跳过的块集中在一起。
步骤3 子帧编码:如果该帧超过了50%个块,则该帧是半视频帧处理,重排块在子帧块之后。否则,如果帧跳过小于50%的块,则保留完整的视频帧。由此,可以在慢动作视频序列中大大减少发送到解码器的帧大小。然而,如果高运动视频序列中的帧不够充分,它将向下一个功能块发送一个完整的帧。
步骤4 帧内编码器:传统的帧内编码的功能块,如H.263,H.264/AVC,H.265/HEVC,MPEG-2和MPEG-4帧内编码,甚至JPEG,JPEG-2000等编码方式,都依赖于设定的取值范围。因此,本文采用高性能H.264/AVC和H.265/HEVE主配置帧内视频编码方法。此外,因为速率控制问题产生的反馈信道的问题,提出了编码器的码率控制方案,其在根本上不同于传统的DVC在解码器的速率控制。
步骤5 跳块记录表:该记录表只需要2 b大小存储对每个块的信息进行储存,例如,(0,0)代表非跳块,(1,0)代表SAD分类器跳块,(0,1)表示DC分类器跳块,(1,1)表示保留的图像块。
2.3 解码器
解码器处理核心位于跳块记录表信息中。因此,这个内核可以生成具有块和像素填充功能的高性能解码器。所考虑的解码器包括以下部分。
步骤1 帧内解码器:该方案采用H.264/AVC和H.265/HEVC视频解码直接可以从编码器自动检测出大部分的参数;这不包括跳块信息。
步骤2 子帧恢复:如果编码器使用子帧功能,解码器应该将其恢复到完全的帧;否则,跳过这个步骤。
步骤3 反向重排:反向重排功能块,按块顺序排列。将块的位置恢复到原来的视频帧状态。
步骤4 ZMVR重建:ZMVR根据跳块记录表的信息,从参考帧(前一帧)的同一块中直接粘贴零运动块。然而,有时这是不理想的,因为一些非跳过块还没有从参考帧中重建,非重建块将继续在下一PBMA块中处理。
步骤5 PBMA匹配块选择:PBMA功能本质是边界匹配算法,主要基于稀疏的边界像素块在参考帧搜索范围,寻找最佳匹配块。PBMA步骤如下:①利用丢失块上、左邻域像素建立PBMA模板。②从参考帧搜索范围中选择候选块。③将每个候选块的邻域像素与搜索范围中的模板进行比较。④与模板最相似的候选块是最佳匹配块。⑤最好的匹配块被粘贴回当前帧中。为简单起见,有关计算定义如下
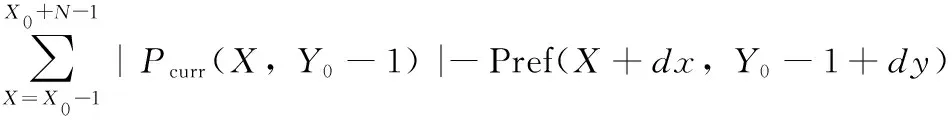
由此可得
PBM(dx,dy)=
PBMupregion(dx,dy)+PBMleftregion(dx,dy)
(12)
式(12)的定义与式(3)的定义类似,不同之处是将b取值为1。
步骤6 STTS像素填充:STTS函数是一种纹理合成算法,但是不同于传统的纹理合成只适用于空间域。而STTS则适用于空间框架和时间框架。虽然这将增加复杂性,但性能也得到了提高。空间纹理合成是在传统图像处理中从小数字样本图像重建大数字图像的有效方法之一。因此,该方案使用STTS算法实现像素填充。
在块填充函数之后,大多数块已经被恢复,只有几个块需要用像素填充来重建。STTS函数采用8邻域作为在解码器中的搜索范围。需要在每个当前像素的4个方向使用模板块,找到当前像素的最佳匹配;模板分别位于上、下、左和右平面上。然后,在搜索范围内找到模板块的最佳匹配。最后,如果选定候选像素,则粘贴候选像素对其进行恢复,如图5所示。

图5 STTS左侧模板
步骤7 PxI插值重建:PxI功能块利用像素插值重建当前帧中的像素。PxI模块可以使用任何隶属插值算法和采用4-领域像素的平均值来完成像素恢复。
步骤8 跳块记录表:跳块记录表功能,是基于编码器的信息表进行构建。此表能够支持最好的解码信息。
3 实验分析
3.1 实验设置
本实验中选取峰值信噪比(PSNR)性能和计算复杂度作为评价指标,对比算法选取H.264/AVC、H.265/HEVC、DISCOVER以及本文算法进行对比。PSNR指标的计算形式为
(13)
式中:MSE是均方误差指标,表示处理图像和原图之间的差异。
实验对象选取GOP视频编码测试集,其长度设置为8,帧的总数是150,其包含4种通用的视频测试序列:“大厅监控”“工厂监控”“足球视频”和“交通监控”。其中“大厅监控”“工厂监控”“交通监控”“足球视频”分别为低、中低、中高、高活跃视频序列。
实验硬件设置:CPU是AMD 7850K 3.2 GHz,内存大小是8 GB,系统为Win7旗舰版,采用文献[13]所设计的C++模拟工具软件进行验证,其采用一种图形化的方式进行视频编码过程实现,并对算法的有效性进行验证,如图6所示。
图6 模拟器操作界面
为验证所提视频编码算法性能,实验设置:假定模型中含有n=200局部视频模块。此服务器扮演索引和边缘服务器的功能,其包含c=1500标准清晰度的视频素材,视频的播放速率是r=2Mbps, 可将其分成m=10帧。视频机顶盒的数据存储容量是s=100, 该容量等于10个视频大小,其中每个视频大小是300 kbps。
3.2 PSNR性能对比
对于GOP8测试对象,H.264/AVC、H.265/HEVC、DISCOVER以及本文算法的PSNR性能对比结果如图7(a)~图7(d)所示。
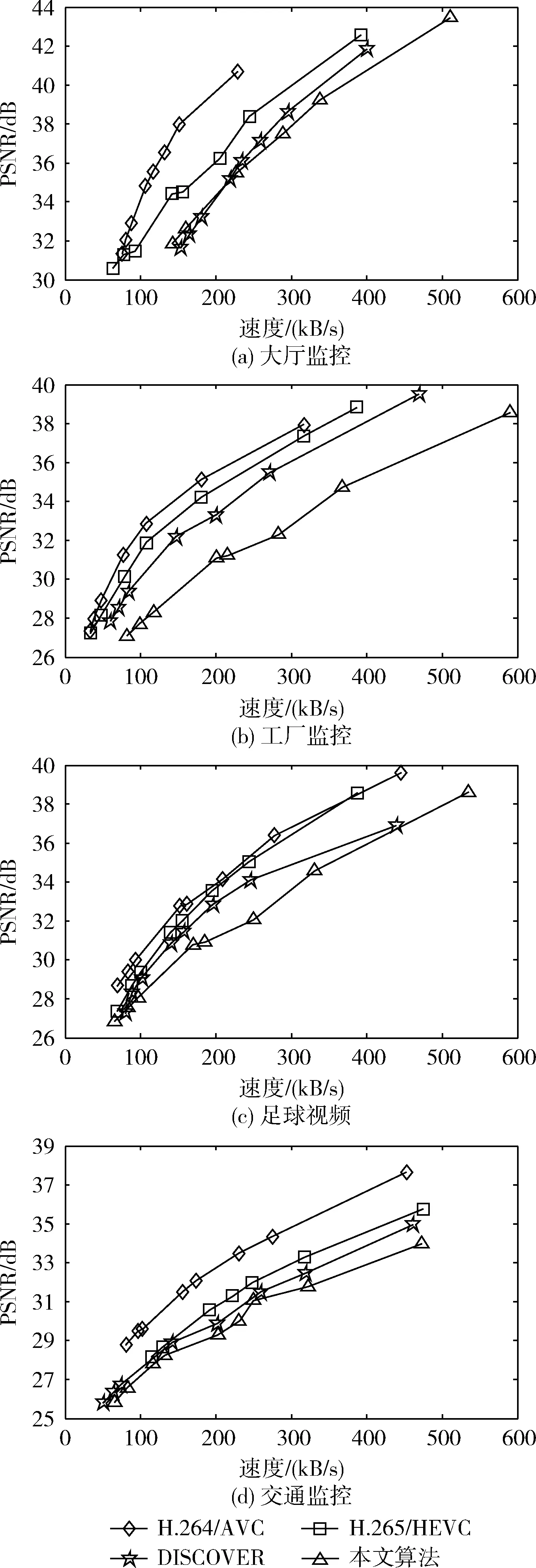
图7 GOP8测试对象上PSNR性能对比
根据图7所示结果可知,在PSNR性能指标上,本文算法的PSNR性能指标值相对于H.264/AVC、H.265/HEVC、DISCOVER这3种算法更低。这表明本文算法的视频处理效果能够更加有效的还原图像,其还原后的图像能够更加接近于原始视频图像。同时,对比H.264/AVC、H.265/HEVC、DISCOVER这3种算法,DISCOVER算法要优于H.264/AVC、H.265/HEVC两种编码算法的PSNR性能指标,H.264/AVC的PSNR性能指标最差。这表明本文算法相对于选取的对比算法在编码、解码过程中还原原始视频的能力更强。
3.3 计算效率对比
对于GOP8测试对象,H.264/AVC、H.265/HEVC、DISCOVER以及本文算法的计算效率对比结果见表1,计算时间分为编码时间、解码时间和总时间。
根据表1结果可知,在计算效率上,本文的计算用时是最少的,例如在足球视频处理上,本文算法的编码时间是12.1 s,解码时间是11.9 s,总用时是23.3 s,这要低于H.264/AVC、H.265/HEVC、DISCOVER这3种算法在视频处理上的计算时间。类似的,在“大厅监控”“工厂监控”“交通监控”3种视频场景下,本文算法计算效率也要高于选取的H.264/AVC、H.265/HEVC、DISCOVER这3种算法,这表明所提算法具有更高的计算效率。而选取的H.264/AVC、H.265/HEVC、DISCOVER这3种算法中,DISCOVER算法的计算效率要高于H.264/AVC、H.265/HEVC两种算法,H.264/AVC算法的效果最差。

表1 计算效率对比/s
4 结束语
为提高视频编码算法性能,提出一种基于局部边界匹配的分布式视频均衡编码算法。主要思路是采用局部边界匹配算法(PBMA)和4种灵活形式的模式决策算法,有效解决了在编码器中的运动估计和模式决策的高计算复杂度,实现了编码器计算复杂度向解码器的均衡转移,降低了总体计算复杂度。上述实验过程通过Matlab仿真模拟进行了验证,为更进一步验证算法的性能,在今后的工作中考虑采用硬件对算法进行具体实现,使得实验结果更加接近于实际应用,提高对应用的指导意义。
