基于凝聚式层次聚类的调频广播自动识别
2020-07-20刘播阳陈智超孔明明
夏 茂,刘播阳,张 政,陈智超,孔明明*
(1.重庆市无线电监测站,重庆 404100;2.国家无线电监测中心检测中心,北京 100037;3.西华大学无线电管理技术研究中心,四川 成都 610039)
调频广播是现代社会重要的信息传播方式之一,通过收听调频广播,可以获取实时路况信息和相关资讯。近年来,随着无线电技术普及和设备成本的降低,一方面,调频广播台站数量骤增,频谱监管工作量陡增、监管难度加大;另一方面,未经授权私自架设电台进行广播的行为(俗称“黑广播”)屡禁不止。黑广播不仅影响社会和谐稳定,还可能干扰航空、无线电、导航等业务,具有很大安全隐患。调频广播自动识别是解决这一问题的关键。
当前,调频广播识别主要有人工监听[1]、基于语音识别技术的方法[2-5]、基于频谱监测的方法[6-14]等。其中,人工监听方法依赖于技术人员监听播放内容,该方法识别正确率高,但需要大量技术人员参与,工作量大且效率低。基于语音识别技术的方法利用调频广播的音频数据识别其性质,即合法广播和“黑广播”,噪声等因素会影响识别的正确率。基于频谱监测的方法通过信号频谱特征来判断是否属于已知类信号,该方法可达到一定的识别精度,但是对于广播内容的分类达不到预期效果。基于信号强度定位广播的方法[15-16]通过选择合适的测向信号,交叉定位,可有效找到信号源,但需配备移动监测车和经验丰富的操作人员。
本文以语音识别技术为基础,采用基于凝聚式文本层次聚类的方法自动识别广播的属性和类别,设计了调频广播自动识别系统架构,提出了适合该研究对象的聚类收敛判定条件并进行了实验验证。采用本文方法得到的广播属性及其主题类别的自动识别结果可向不同业务主管部门精准推送。
1 自动识别方法
1.1 自动识别流程
基于凝聚式层次聚类的调频广播自动识别包括广播内容主题和关键词提取、识别验证和语料库更新3 个主要过程,如图1 所示。

图1 调频广播自动识别技术的流程图
1)主题和关键词提取。对于获取的黑广播与正常广播语音数据运用语音转写技术将音频转写成文本,对文本进行分析处理,计算特征项权重、构建空间向量并计算文本之间的欧式距离,然后运用凝聚式层次聚类法将文本空间向量划分为多个类别,最后运用词频分析将各类别内高频关键词分别构建为黑广播与正常广播的初始语料库。
2)识别验证。运用语音转写将待验证广播音频转换成文本,提取每个文本的关键词,判断关键词包含在哪个类别内,从而将音频归入对应的类别中,同时将未匹配的文本移入更新过程。
3)语料库更新。将无法匹配的正常广播文本、黑广播文本分别和初始正常广播、黑广播训练样本重新进行聚类和主题与关键词提取,更新初始语料库作为新语料库。
实现主题和关键词提取以及语料库更新的关键在于音频数据转写文本的处理和类别划分。
1.2 音频数据处理
1.2.1 语音转写技术
基于深度全序列卷积神经网络的语音转写(long form ASR)技术是目前较成熟的语音转写技术,该技术可将长段音频转换成文本。本文利用python 程序调用科大讯飞API 实现语音转写,调用程序主要包括预处理、文件分片上传、合并文件、查询处理进度、获取结果5 个步骤。语音转写完毕后会输出音频对应的完整文本数据,保存在相应的txt 文件中。本文使用的音频数据直接从实际的监测设备中获取。
1.2.2 文本预处理
对广播文本数据进行预处理主要包括数据清洗、中文分词、去停用词和构建向量空间模型4 个步骤。其中:数据清洗主要是利用正则表达式去除中文以外的文字及符号;中文分词主要原理是先基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况的有向无环图(DAG),然后利用动态规划查找最大概率路径,找出最大切分组合;去停用词主要是通过构建停用词表,将无法表现文本特征的词语删除;向量空间模型(VSM)是最简单有效的文本表示模型[18],其主要思想是将文本变成一个由特征项权重构成的多维向量,特征项可以是字、词等VSM 中不可再分割的最小语言单元。
一个文档F可以看成是由n个特征项(t1,t2,t3,···,tn)组成,其中ti是文档中第i个特征项(n≥i≥1),对每一个特征项都赋一个权重wi,此时文档F的形式化为

其中wi为ti的权重,因此t1,···,tn可以看作是一个n维坐标系,w1,···,wn可以看作是对应的坐标值并构成n维空间的一个n维向量,本文称为文档F的向量空间模型。
1.2.3 计算特征项的权重
TF-IDF 算法[19]是向量空间模型中最经典的用来衡量特征项重要性的计算方法。如果以词为特征项,则特征词对应的权重由2 个因素决定,即TF(term frequency)和IDF (inverse document frequency)。TF 表示为

式中:tfi,j代表文本Fj中特征词ti出现的次数;分子ni,j是该特征词在文件中出现的次数;分母∑nk,j指在文档Fj中所有词的出现次数之和,字母k表示所有文档的个数。
IDF 的计算公式为
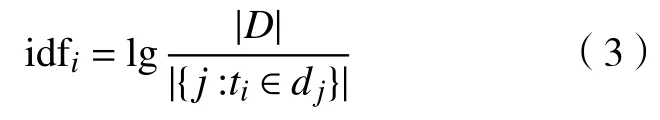
式中:分子|D|表示文档总数,分母是指所有文档中出现了特征词ti的文档数量。但若特征词ti不在语料库中就会导致分母为零,因此一般将此公式的分母更换为1+|{d∈D:t∈d}|。词语的重要性随着它在一个文档中出现的次数增加而增加,但也会随着它在总文档中出现的频率增加而减少。一个词在文档中的重要程度(权重w)就是TF 值与IDF 值的乘积,即
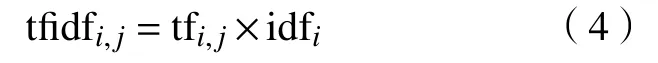
1.3 凝聚式层次聚类
层次聚类算法属于无监督学习的一种聚类算法,分为2 种聚类方式:凝聚式层次聚类(AHC)和分裂式层次聚类(DHC)。凝聚式层次聚类的思想是:首先将每个数据单独成簇,之后按照相似性度量标准将相似性最高的数据先进行合并,依照数据相似度从高到低的顺序依次合并成簇,簇间的相似度随着簇的合并而降低,直到达到给定的相似度阈值才会停止。本文采用凝聚式层次聚类法来对调频广播文本数据进行聚类,具体方法如下。
首先将原始样本(F1,F2,F3,···,Fn)中每个样本自成一类,原始的类中心为(C1,C2,C3,···,Cn),然后根据相似性度量标准将类中心最近的2 个文本合并,根据聚类收敛的条件不断重复这一过程直至所有可合并的类合并完成。本文采用的相似性度量标准为欧式距离法,为

式中:Fi、Fj分别表示文本集合中第i个和第j个文本;wm,i、wm,j分别表示文本Fi和Fj的第m个特征项的权重;n表示文本特征项的数目。通过式(5)可计算出在数据集中文本Fi与文本Fj的距离,并将距离最近的2 个文本合为一个类。
本文并没有使用设定阈值的方法终止聚类,而是通过研究分析,给出了一种新的聚类收敛的判定条件,即每次合并成一类之前要进行判断:分别统计合并前这2 类中文本词频前10 的关键词,记为关键词Top10,这2 类关键词Top10 的集合分别记为
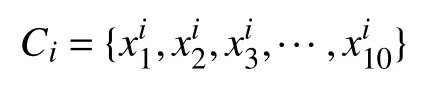
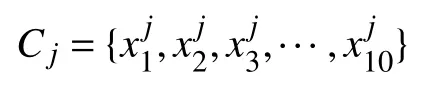
层次聚类法的优点是不需要事先设定初始的聚类中心和聚类个数,因此不会因选取聚类中心和种类的不同导致实验结果产生差异。其缺点在于时间复杂度T(n)和空间复杂度S(n)高,从而使得算法运算过程较慢,因此在样本量大时需要做相应的优化。
2 应用验证
2.1 主题和关键词的提取
利用设备在某一地区24 h 监听不同频点的广播语音,收集音频数据,其频点包含97.2、100.8、90.8、98.3、96、106.1 MHz 等,每个频点至少包含10 个音频文件。其中有92 个黑广播音频文件,50 个正常广播音频文件,每个音频时长约10 min,部分采集到的音频数据如表1 所示。无台标的是黑广播数据。台标的识别是根据在自定义词典中加入了常见台标名称,再通过正则表达式从切分的词语中提取出来。
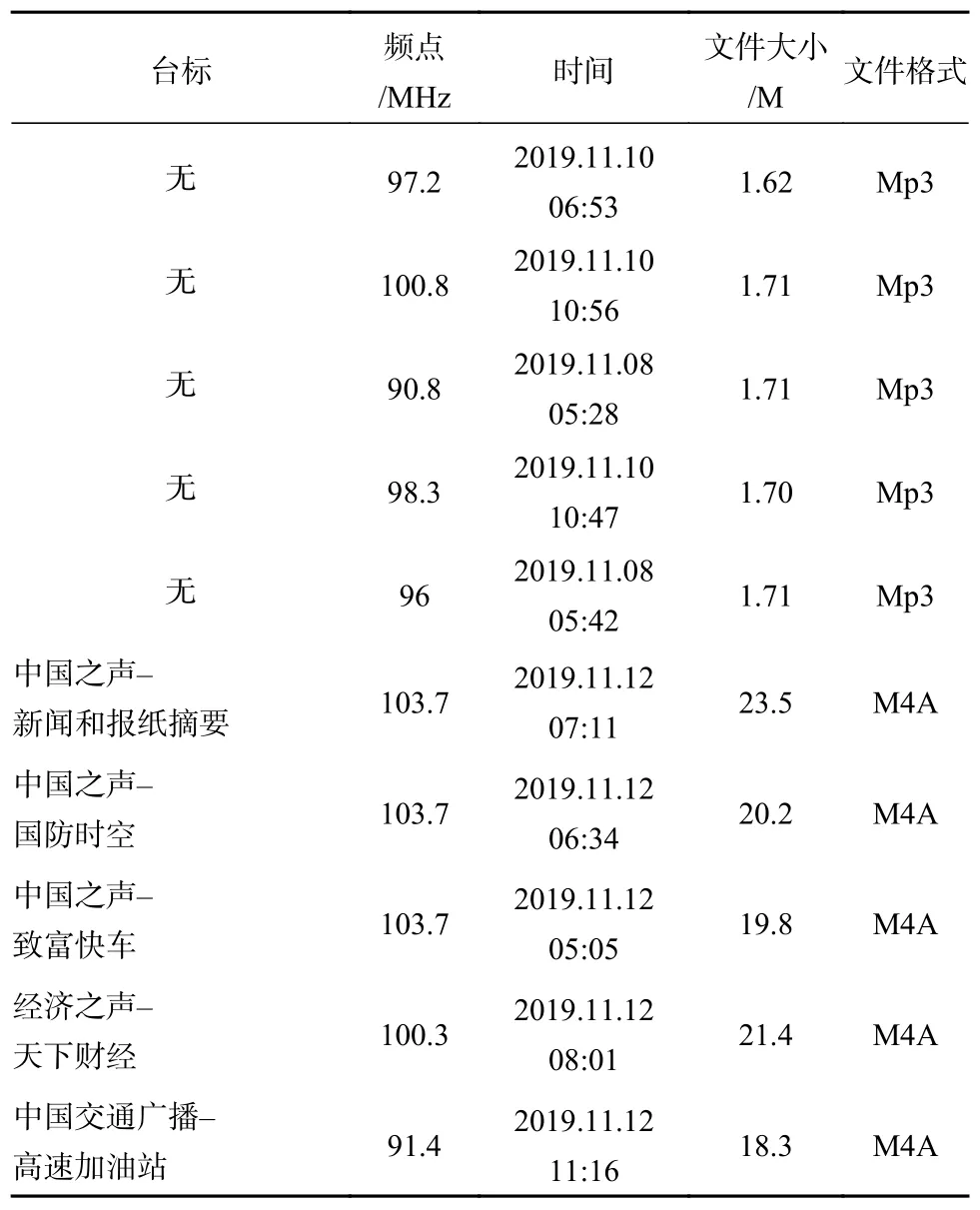
表1 采集到的音频数据
调用科大讯飞接口将采集到的语音数据转化为文本文件,格式为txt,部分结果如表2 所示。

表2 音频转换成的文本文件
以2019 年11 月8 日凌晨,频点为90.8 MHz的文本为例,该文本部分内容如表3 所示。

表3 文本文件内容示例
对转化成文档的黑广播数据进行凝聚式层次聚类:首先利用公式(1)—(4)计算每篇文档的特征词及其权重(保留3 位小数),部分数据如表4 所示;利用距离公式(5)计算黑广播文档之间的距离,部分数据如表5 所示;从与第1—92 篇文档中选取1 篇与其距离最小的文档构成簇进行合并,合并前考虑聚类收敛的判定条件,若两簇内Top10 关键词重复个数大于1 则继续合并,否则跳过此次合并开始下一组合并。层次聚类部分合并过程中重复的关键词及按照收敛条件合并次数如表6、表7 所示。其中:不考虑收敛条件时,黑广播和正常广播分别需要合并91、49 次完成聚类;在满足收敛条件下,黑广播合并成功83 次,失败9 次,共聚成3 类,正常广播合并成功39 次,失败11 次,共聚成6 类。

表4 特征词及权重
表5 文档距离

表6 黑广播凝聚式层次聚类判定过程

表7 正常广播凝聚式层次聚类判定过程
广播语音样本的凝聚式层次聚类树状图,如图2—3 所示。横坐标表示参与聚类的各文档,纵坐标表示欧式距离,文档(类)的距离越近相似程度越高。为了提取每一类的主题,聚类完成后根据词频从每一类中提取关键词Top10,根据关键词对各类主题进行人工标注,最后将黑广播与正常广播的关键词Top10 分别放入语料库,形成的语料库如表8、表9 所示。
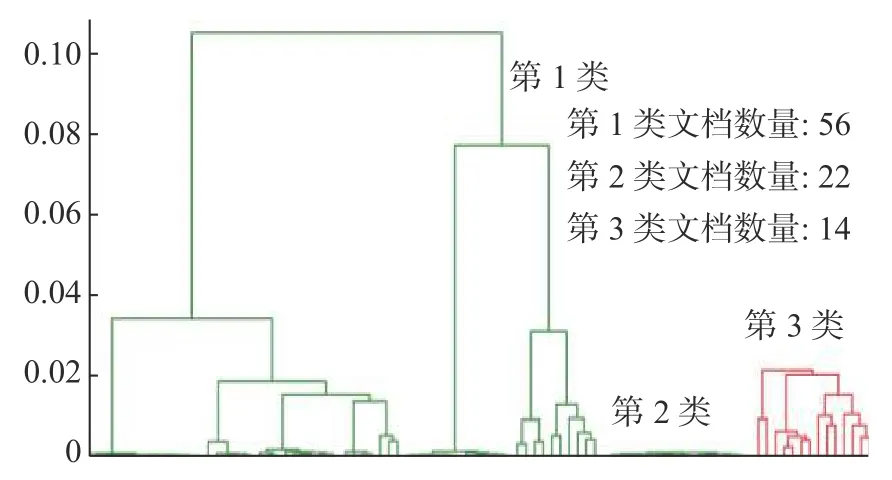
图2 黑广播层次聚类树状图

图3 正常广播层次聚类树状图

表8 黑广播各类的关键词语料库
在训练黑广播语料库时,未添加自定义词典时训练出的黑广播分词词语效果为“玻璃体”“浑浊”“两个”“疗程”,在添加了“玻璃体浑浊”与“两个疗程”这样的词在自定义词典之后,效果为“玻璃体浑浊”“两个疗程”。用此种方法可以在分词的时候,将所有正常广播的台标和整点报时放入自定义添加词典中,之后可以利用正则表达式提取出台标、报时。使用Re 库提取手机号和座机号的正则表达式为:
tel_number=re.findall("1d{10}",str_object_list)

表9 正常广播各类的关键词语料库
tel_number_A=re.findall("d{10}",str_object_list)
本实验提取到的电话号码有1704****4472、1718****927、400****589。对于同一类txt 文件进行归类存储,再分别对每一类提取其关键词,提取到的关键词如表8、表9 所示。将加入正则表达式的结果,用wordcloud(图像处理库)和matplotlib(图像展示库)对其处理,关键词、黑广播手机号、台标、整点报时制成词云图展示的结果,如图4 所示。

图4 关键词展示
2.2 识别验证过程
实验建立了黑广播与正常广播语料库后,验证实验的目的是检验新采集的广播数据在无人干预的情况下是否能够自动识别广播的属性及类别。
首先将获取的音频数据转为文本,其中频率为98.3、90.8、88.5、89.6、99.3 MHz 的音频文件分别有27、22、25、29、33 个,中华之声-两岸热新闻音频文件10 个,经济之声-财经夜读音频文件8 个,中国交通广播-汽车风云音频文件10 个,中华之声-两岸热新闻音频文件10 个,每个时长约10 min。转成的部分音频数据如表10 所示。然后检验特征词是否被包含在广播语料库中,部分特征词如表11 所示。测试结果如表12 所示。
对184 个样本进行检测,其结果显示,与人工标注属性一致的有167 个,未识别广播属性的样本11 个,错误6 个。计算其正确率和属性综合评价指标。其中综合评价指标(F)包括精确率(P)、召回率(R)。

表10 需要被识别的广播文本数据信息
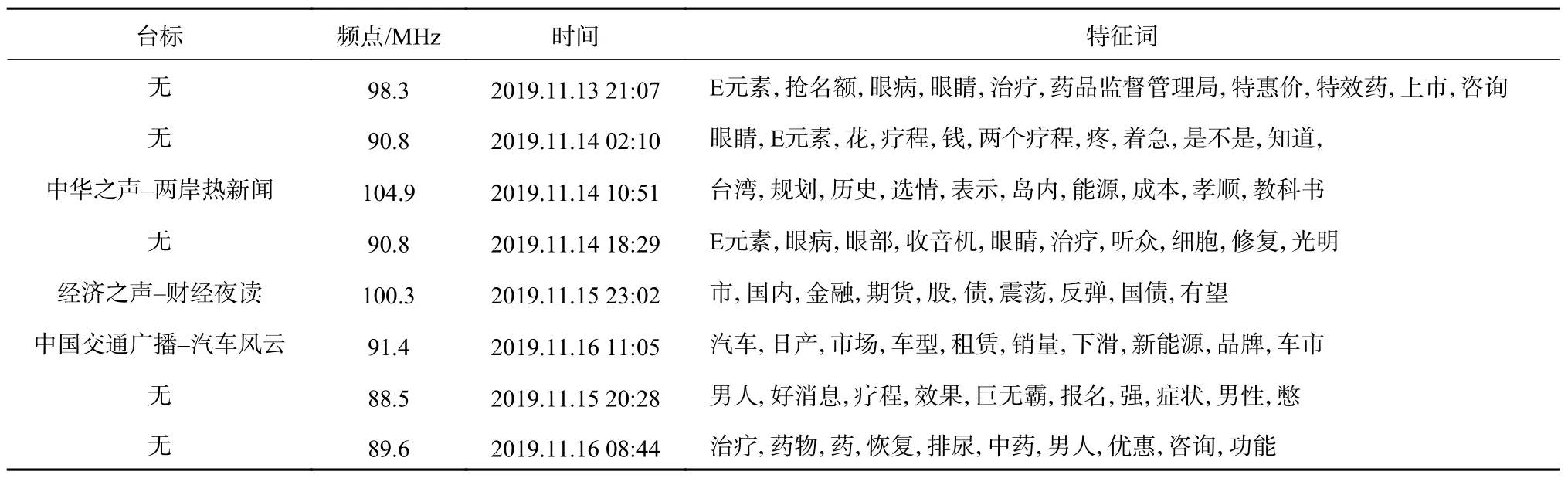
表11 对应广播文本数据得到的特征词

表12 测试结果

式中:TP、EP和 FN分别为检测正确的样本、检测错误的样本和未能检测的样本。
综合评价指标的计算公式为

当α=1时,就是最常见评价指标

综合评价指标F1综合了精确率P和召回率R,因此,用综合评价指标F1来评价实验。F1越大则表示实验结果越好。

不同主题的广播,若播放内容经上述方法识别出存在违规则可向相关部门推送,例如:类别为治疗男性疾病的广播可向医疗监督管理机构推送;类别为新闻的广播可向宣传部推送;类别为交通安全的广播可向公安推送;类别为经济类的广播可向银行业监督管理机构推送。
2.3 语料库更新过程
对未识别出广播属性的样本经过人工标注属性后加入训练的文本库中重新进行语料库的训练(与原始语料库的提取主题和关键词方式相同),经过训练后的新语料库如表13、表14 所示。

表13 更新后的黑广播关键词语料库
在更新了语料库之后,对样本进行重新测试,其中与人工标注属性一致的有179 个,未识别广播属性的样本3 个,错误2 个;类别标注正确162 个,错误22 个。


表14 更新后的正常广播关键词语料库

相比语料库更新之前,实验结果正确率上升了6.52%,综合评价指标上升了0.045 3。
3 结论
本文综合运用了语音文本识别、数据预处理、层次聚类、数据可视化等技术,通过对广播语音文本的聚类实现了语料库的构建、更新,并进行了识别效果的验证实验。结果表明,基于凝聚式层次聚类的方法可有效地识别调频广播的属性和类别,在实际监管工作中可将广播音频数据相关主题推送到对应的医疗、市场、食品药品、舆论等监督管理机构。
