一种应用于星载交换机的DDR3 共享存储交换结构的设计与实现*
2020-07-19王雷淘乔庐峰
王雷淘,乔庐峰,续 欣
(陆军工程大学 通信工程学院,江苏 南京 210001)
0 引言
网络技术的飞速发展带来了网络流量的爆炸式增长,卫星通信以其广阔的覆盖范围、稳定可靠的性能、灵活机动的接入、大容量宽频带、成本对距离不敏感等优点,在全球互联网中扮演着愈加重要的角色[1-3]。星载路由器的一大特点在于其带宽和存储资源十分珍贵。DDR3 以其存储容量大、读写速度快等特点,越来越多的被应用于路由器中队列管理器的设计当中[4]。常见的基于DDR3 的队列管理器中,都采取将数据实际存入DDR3 中,将地址指针送入队列控制器中的链表建立虚拟出口队列的方式[5]。然而,当需要读出数据时,输出电路仅能从队列中获取待输出数据包存储位置的起始地址指针,而无法获取数据包的实际长度,在实际操作时,需要暂停DDR3 的读操作以获取数据包长度信息,这无疑降低了DDR3 的读写效率,影响了整个路由器的传输性能。一种解决方法是利用长度信息SRAM,将每一个数据包的长度信息存储其中,在获取待读出数据包的起始地址指针时,从该SRAM中读出数据包的长度信息,将其同起始地址指针一起送往DDR3 控制器,从而实现数据包的连续读出。但是,针对于星载路由器存储资源十分珍贵这一特点,这种解决方式明显并不适合。
本文在上述分析的基础上,基于FPGA 硬件平台,设计了一种基于DDR3 的星载路由器的队列管理器。队列管理器通过调用片外DDR3 作为数据存储区,增大了缓冲区容量,并设置共享存储区,可以有效应对突发,提高了抗流量波动的能力。在本电路中,本文采取了一种可以连续对多个读出请求进行操作的设计方案,保证了DDR3 的连续读写。同时,为了减少存储地址指针时的资源消耗,本电路采用了基于大数据块的存储区分配方式,将存储区分为了16 384 块大小相同的存储块,使用块指针加上块内信元指针的方式对数据包进行寻址,并设置了基于sram 的指针缓冲区[6]。本文将进一步详细介绍其具体的设计与实现方式。
1 系统硬件架构
系统的硬件架构包括前级的预处理电路、查找引擎,后级的输出调度器和输出合路电路等,如图1 所示。
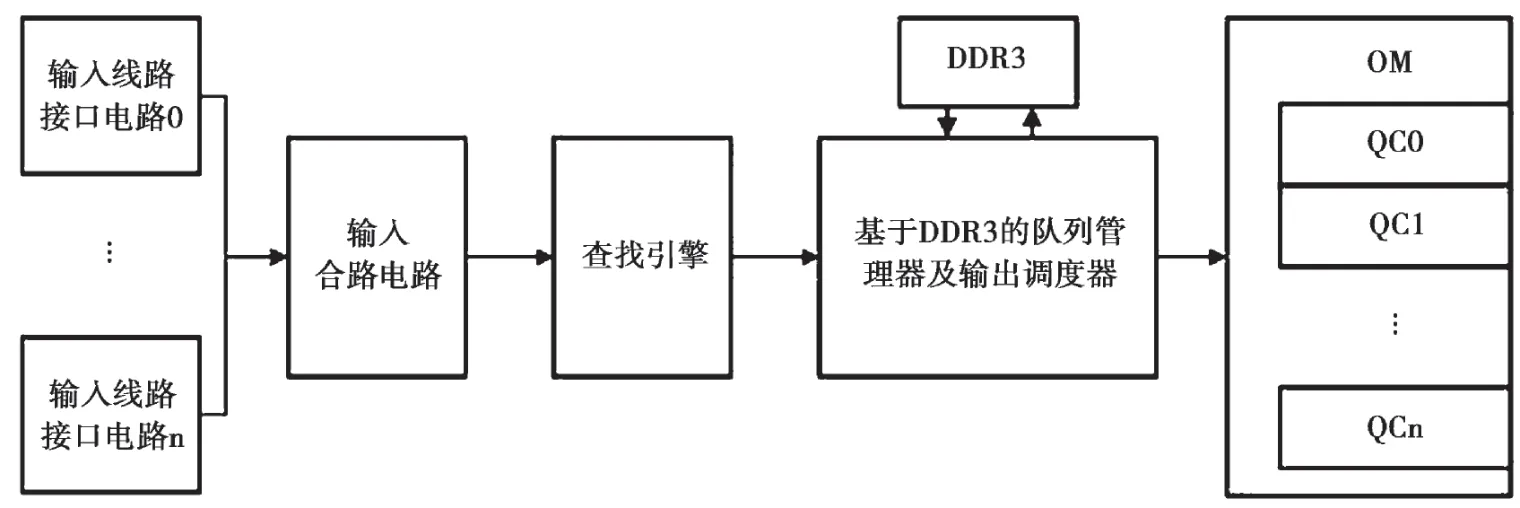
图1 系统逻辑架构
在图1 中,输入至该系统的数据流首先经过合路电路和查找引擎进行预处理,而后送入队列管理器。在预处理过程中,电路会对数据流进行分类,传统的流分类策略主要是依据数据包报文头中的五元组(源IP 地址、目的IP 地址、源MAC 地址、目的MAC 地址和协议种类),这种分类方式实现简单、判定速度快,适于硬件实现。
经过分类的数据流,会在数据包报文头头前面增加一个本地头,其中包含了包长、输入输出端口号、所属队列号(FLOW_ID)等信息。
2 队列管理器设计
在网络流量管理中,主要存在两个关键机制:一个是对不同应用或协议对应的业务流进行区分的流量分类机制;另一个则是用于实现对数据包的缓冲管理、基于流的排队管理、输出调度和输出速度控制的队列管理机制。
本电路使用的队列管理器逻辑模型如图2 所示。

图2 队列管理器逻辑模型
其主体结构为多个相互独立的链表队列,不同的队列分别对应于特定的协议或应用,队列之间使用在预处理电路中生成并放置于本地头中的队列好(FLOW_ID)进行区分。FLOW_ID 的数值范围可以根据业务的实际需求进行动态调整,最大可同时对数千个队列进行管理。考虑到星载路由器存储资源十分珍贵的特点,本电路采用DDR3 作为队列管理器的数据缓冲区,从而在尽量降低片内资源消耗的同时,保证了数据缓冲空间的大小,实现对大量队列的精确管理。
针对于队列管理器,具体的电路细节如图3 所示,其中包括写入预处理电路、自由指针管理电路、队列控制电路、DDR3 控制器。
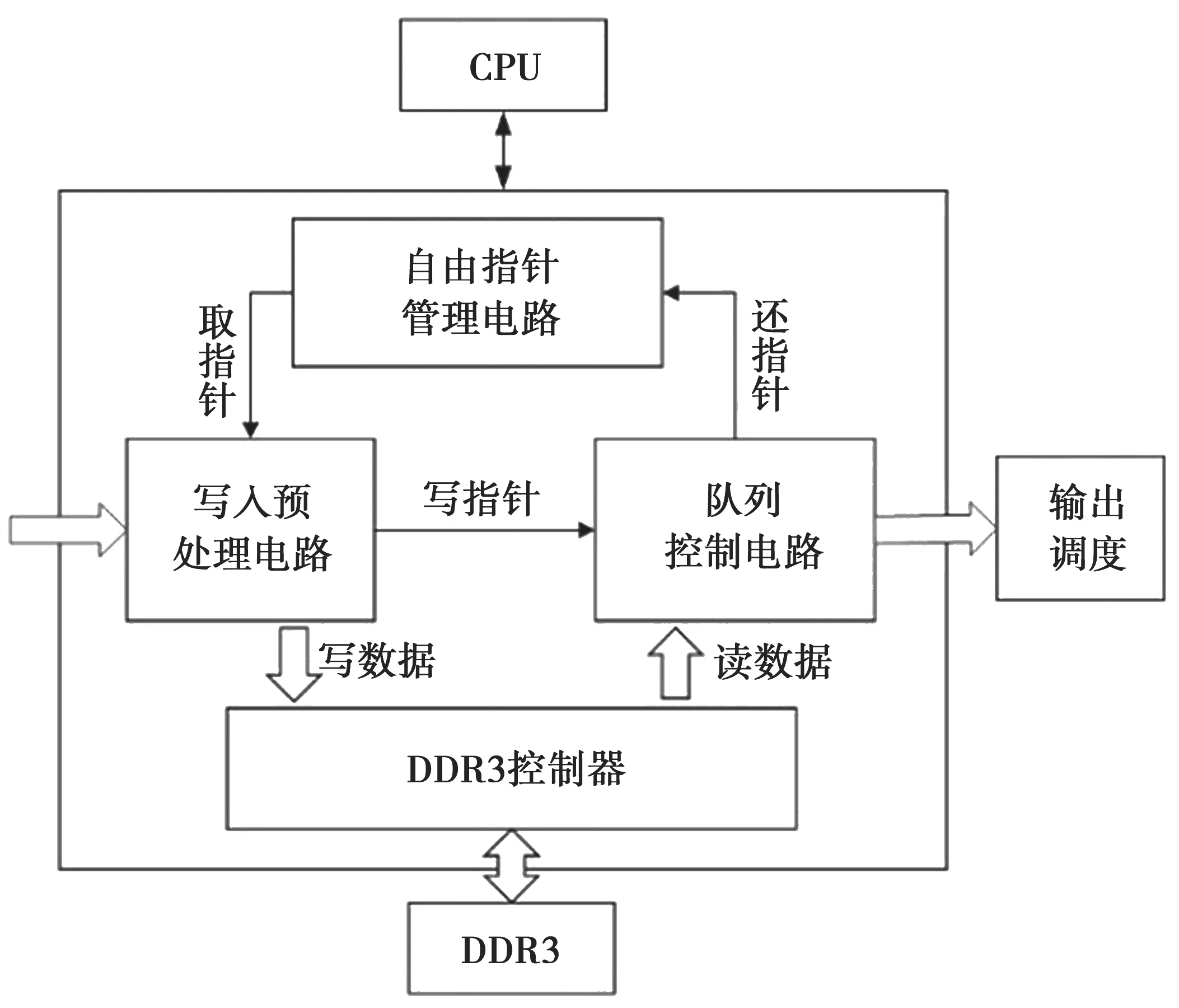
图3 队列管理器的电路结构
其中,需要特别说明的是,针对自由指针管理电路,其主要负责维护系统当前所有可以使用的地址指针,同时执行地址指针的分发和回收功能。
本电路中采用基于块的存储区分配,使用块指针和块内指针联合寻址的方式存储数据包。数据存储在DDR3 中,链表队列中实际排队的是使用的是数据包对应的块指针,因此自由指针管理电路中仅需使用128 k 大小的sram 即可存储全部的块指针,大大降低了自由指针管理电路存储地址指针时的存储资源消耗。
本文所设计的队列管理器具有以下几个特点:
(1)对于每一队列,都预先保留了一定大小的缓冲区。同时设立共享缓存区,可供个别队列在私有存储区耗尽时申请使用,避免丢包;
(2)使用片外存储器DDR3 作为数据缓存区,极大的并提高了存储容量。同时以块为单位对DDR3 进行划分并分配指针,使用块所对应的指针以链表的形式构建逻辑队列,降低存储地址指针时的存储资源消耗,并降低了读写数据包时,打开不同bank、行时的额外时间消耗;
(3)在DDR3 控制器中,将读数据和分析本地头的工作分开进行,使得DDR3 控制器可以连续处理多个读请求,实现了DDR3 的连续读写,进而提高了路由器的传输性能。
2.1 基于块的存储区分配
队列管理器的设计往往要求具备一定的抗流量抖动能力。假设在某一时刻,某一个或某几个队列对应的数据流连续突发,而队列管理器又无法及时输出时,则需要为这些队列分配额外更多的存储资源,这对缓冲空间的大小提出了更高的要求。同时,在队列管理器中,数据实际存储在缓冲区中,缓冲区的读写速度也就决定了队列管理器的吞吐率上限。
由于DDR3 存储容量大、读写速度快等优点,本电路采用DDR3 作为片外存储区。DDR3 为了提高读写的效率,采取了突发操作,在突发长度为8,位宽为64 bits 的情况下,一次突发操作可以写入或者读出64 字节的数据。在写预处理电路中完成了将经过的数据包包长填充为64 字节的整数倍,并将一个数据包划分为了多个长度为64 字节的信元的操作,这样,一次突发即可完成一个信元的写入或者读出操作。本电路采用的基于块的存储区分配,即将存储区划分为16 384 个大小相同的存储块,每个存储块对应一个块指针,在块内使用块内指针进行寻址,当数据包输入时,实际存储在DDR3 中,然后将其对应的块指针送入链表中建立虚拟输出队列。如图4 所示。

图4 基于块的存储区分配
在写入预处理电路中设置了两块sram 存储各队列的详细信息,包括首尾块指针、首尾块内指针等。由于在存储块内,信元总是按顺序存储,因此每次写入或读出数据包时,只需要根据该队列的队列编号,从寄存器中获取对应的首尾块指针和块内指针,即可迅速定位到该队列的首尾位置,进行读写操作。而每个数据包本地头中都包含有该包长度,在每次读写操作完成后,可以很方便的对首尾指针进行更新。
同时,由于DDR3 的读写特性,每次读写时需要按照顺序打开存储数据的所在bank、行、列,消耗一定的时钟周期,按照通常的存储方式,即有可能出现同一个数据包存储在不同行、不同bank 的情况,在读写时消耗额外大量的时钟周期。通过划分大块存储区的方式,基本可以保证同一个数据包的数据存储在相同bank 的相同行内,避免了读写时在不同bank 和行之间切换,有利于提高DDR3的读写效率,进而提高系统的吞吐率。
2.2 工作流程
系统上电之后,DDR3 控制器首先需要对DDR3进行初始化操作。初始化完成后,即可按照图5 所示的工作流程开始数据包的输入操作。

图5 写入工作流程
数据包经过预处理电路后到达队列管理器时,包头前加装了本地头,其中包含了队列编号、出端口位图、包长等信息。写入预处理电路根据数据流的队列编号(Flow ID),从存储队列信息的sram中获取该队列的首指针地址、尾指针地址、队列深度等详细信息,如果当前队列长度(已使用存储区)没有超过私有存储区,则直接进行指针获取、数据写入、队列信息更新的流程。若已经超过私有存储区,则转而向共享缓存区域申请存储资源,申请成功后,才能继续进行后续的操作。
读出操作与写入操作类似,如图6 所示。

图6 输出工作流程
当有链表队列中有完整数据包可以输出时,调度器根据其队列编号从队列信息寄存器中获取首尾指针等信息,并判断,若当前存储块已经读空,则向链表队列申请新的块指针,归还当前块地址给自由指针电路,并更新链表信息,将新的块指针和块内指针送入DDR3 控制器,若当前存储块尚未读空,则将当前块指针和块内指针送入DDR3 控制器。DDR3 控制器根据读请求和地址指针,将数据包从DDR3 中读出,最后更新队列信息。
在DDR3 控制器根据读请求从DDR3 中读数据时存在一个问题,即跟随读请求一同送入的地址指针仅指示了等待读取的数据包在DDR3 中的起始地址,并不携带数据包的长度信息,控制器也就无法确定要从DDR3 中读取多少数据。因此,控制器在从DDR3 中读出第一个信元后,需要暂停读出操作,从首信元中分离出本地头,进而获取数据包的长度信息,然后再继续执行读操作,将数据包的剩余信元完全读出。在分离本地头、获取长度信息的这个过程中,DDR3 的读操作处于停滞状态,降低了其读写效率,对于路由器的吞吐率造成了一定的影响。一种解决方案是利用sram 将各数据包的长度信息都存储起来,当发出读信号时,将数据包对应的长度信息同地址指针一同送入DDR3 控制器中,这样虽然解决了DDR3 连续读写的问题,但当存储的数据包较多时,存储各数据包的长度信息需要消耗额外大量的存储资源。
3 DDR3 控制器设计
对于调用DDR3 作为片外存储区的电路而言,DDR3 的带宽决定了本电路吞吐率的上限,因此,保证DDR3 的连续读写是提高电路性能的关键。在数据包读出时,DDR3 控制器依据从队列中读出的块指针和块内指针对数据包进行读出操作,由于队列和队列信息sram 中不包含数据包长度的实际情况,DDR3 控制器需要在读出数据包首信元后暂停对DDR3 的读请求,从首信元的本地头中分析出数据包总长度,然后再继续从DDR3 中读出数据包的剩余信元,在分析首信元这一过程中,DDR3 读操作一度处于停滞状态,大大降低了DDR3 的读写效率。本文提出并实现了一种将读出信元和分析首信元的工作分开,可以连续处理多个读信号的DDR3控制器设计方案,保证当有读写请求时,DDR3 可以连续读写,不存在停滞,同时避免了消耗额外的资源去存储各数据包的长度信息。
经过分析发现,在对首信元进行分析获取包长的这段时间内,DDR3 并不是无法进行读操作,而是无法继续进行当前数据包后续信元的读操作。因此,我们可以考虑让DDR3 控制器在对某数据包的首信元进行分析的过程中,暂时搁置对该数据包的读操作,先对后续的读请求进行应答,读出相应的信元,等到有首信元分析完毕时,再来继续读出该数据包的剩余信元。DDR3 控制器其结构图如图7所示。
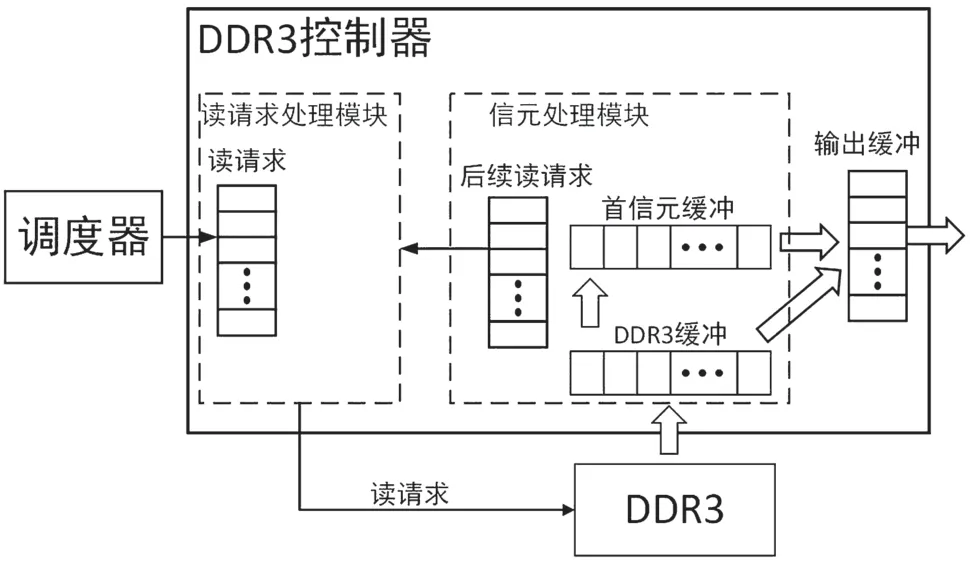
图7 DDR3 控制器结构
本电路中将DDR3 控制器主要分为读请求处理模块和信元处理模块两部分。读请求处理模块负责根据调度器发来的读请求和信元处理模块发来的后续信元读请求,从DDR3 中读出数据,信元处理模块则负责对从DDR3 中读出的信元进行判断,若是首信元,则先存入首信元缓冲中,分析获取包头等信息,形成后续信元读请求,送入读请求处理模块,若不是首信元,则送入输出缓冲中等待输出。具体的工作流程如图8 所示。

图8 DDR3 工作流程
读请求处理处理模块对调度器发出的读请求和信元处理模块发出的读请求进行轮询监测。对于调度器发出的读请求,读请求处理模块根据地址指针,从DDR3 中读出数据包首信元,而后暂时搁置该数据包的读操作,继续处理其他读请求;对于信元处理模块发出的读请求,读请求处理模块根据地址指针和包长信息,可以从DDR3 中读出数据包的全部剩余信元,完成数据包的读操作。
信元处理模块则时刻对DDR3 缓冲进行监测,当其中有数据时进行判断,若是首信元,且不是单信元数据包,则开始进行分离本地头、获取包长信息、生成后续信元读请求的操作;若是首信元且是单信元数据包,表示该数据包已经输出完毕,可以直接将其送入输出缓冲中等待输出;若不是首信元,表示读请求处理模块正在完成某数据包剩余信元的读出工作,则将该数据包的首信元和后续信元一起送入输出缓冲中,等待输出。
本设计通过将处理读信号和分析首信元的工作分入两个模块进行,使得控制器可以连续处理多个读请求,避免DDR3 读操作进入停滞状态,保障了DDR3 的读写效率,提高了电路的传输性能。
4 仿真结果与分析
本设计中,队列管理器的电路核心模块采用Verilog HDL 编程实现,开发环境采用的是Xilinx集成开发环境VIVADO 2018.3,使用仿真软件Modelsim SE-64 2019.2对整个系统进行行为级仿真。
4.1 数据包输入及队列状态更新的仿真
如图9 所示,前级有数据包可以输入时(i_frame_ptr_fifo_ft_empty),从指针中获取该包所属的流编号(wr_flowid),进而从存储队列信息的sram中获取首尾地址指针等队列信息(如图中①)。当需要申请新的存储块时,向自由指针电路发送请求(ll_wr_req),并附带流编号(ll_wr_flowid)(如图中②),自由指针电路收到请求后,首先获取该流当前队列长度和门限值,若队列长度小于门限值,表示为该流预留的存储区还有剩余,将新申请的块指针返回写入电路(如图中③)。收到块指针后,将数据包送入输出缓冲fifo(i_frame_data_fifo_ft_dout),准备送入DDR3 控制器中(o_cell_data_fifo_ft_din)(如图中④)。写入完成后,该队列的长度、首尾指针等都有变化,对队列信息进行更新(depth_flag_refresh),DDR3 控制器收到写入请求后,将数据包写入DDR3 中(如图中⑤)。

图9 数据包输入仿真
4.2 数据包输出仿真图
如图10 所示,当某队列中有完整数据包时,向调度器发出一个可读信号(q_rdy),若正好此时端口空闲(port_rdy),则向队列管理器发出读信号(q_status_rd_req),申请要读出数据包的地址指针(如图①)。调度器收到地址指针后(rd_addr),将其写入面向DDR3 控制器的读信号缓冲中(sdram_req_fifo_ft_din),等待从DDR3 中输出(如图②)。等到数据包输出完毕后,DDR3 控制器将已经刚读出的数据包的相关信息送回调度器当中(sdram_rtn_fifo_ft_din)(如图③),调度器从中获取该包所属的流编号(q_status_ref_flowid)、包长度(q__status_ref_len)后送到队列管理器当中,队列管理器根据收到的信息对队列信息寄存器进行更新,若该数据包是数据块中的最后一个包,则此时该数据块为空,队列控制器想自由指针控制电路发出请求归还指针(rtn_ptr_req)(如图④)。
4.3 DDR3 控制器工作仿真图
如图11 所示,读信号处理电路当收到前级发来的读请求(sdram_req_fifo_ft_empty)时,首先从中读信息(sdram_req_fifo_ft_dout)中获取数据包起始地址(read_start_addr)送往DDR3 中(app_addr),请求读出数据,随后交由信元处理电路分析该数据包的首信元,暂时搁置该读请求,继续处理其他读请求(如图中①)。
当收到来自信元处理电路的读请求时(sdram_secreq_fifo_empty),读信号处理电路根据包长度,将数据包剩余信元全部读出(如图中②)。

图10 数据包输出仿真
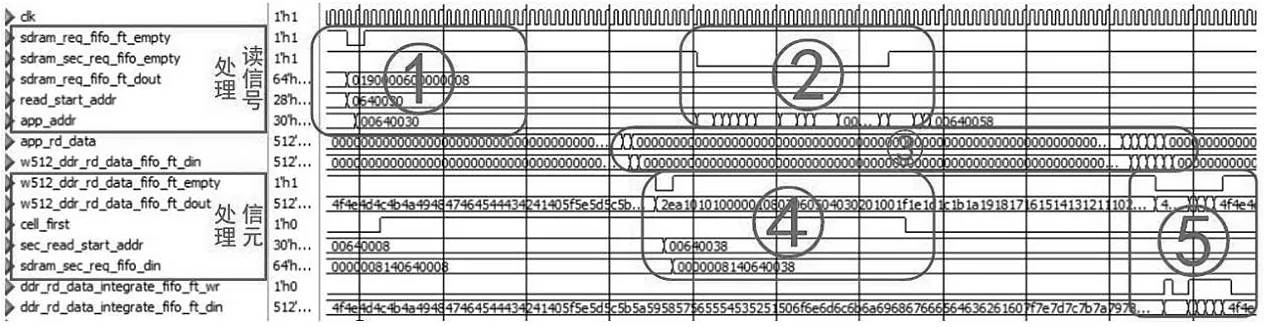
图11 DDR3 控制器工作仿真
DDR3 输出的信元(app_rd_data)存储在一个DDR3 输出缓冲当中,等待进一步处理(w512_ddr_rd_data_fifo_ft_din)(如图中③)。信元处理器检测到缓冲区有信元时,首先检测是否首信元(cell_first),若是,则将后续信元起始地址和包长作为新的读信号,发送给读信号处理电路(sdram_sec_req_fifo_din)(如图中④)。等到数据包完全读出后,将其存入输出缓冲中,等待输出(如图中⑤)。
5 性能分析
星载路由器对资源消耗、吞吐率等都有严格的要求,在资源消耗较低的前提下仍能保证一定的吞吐量。电路基于Xilinx Virtex-7 XC7V690T 设计实现,图12 所示为该设计的硬件资源消耗情况。从图中可以看到,在调用外部DDR3 作为数据存储区时,虽然访问片外存储区的时间会增加,但对应的片内硬件资源消耗也较低,实际占用的BRAM 资源仅为18%。
图13 为本设计的功耗评估报告,电路中大量采用了状态机结构,其与流水线结构相比,状态机结构能耗相对较低,可以看到整个队列管理器动态功耗4.391 W,存储部分的功耗只占了20%。

图12 FPGA 内部硬件资源消耗

图13 功耗评估报告
6 结语
本文提出了一种基于FPGA 硬件平台的网络流量管理系统架构,基于流建立队列并进行资源预留,同时,为了减少片内资源消耗,提供更大的数据缓存功能,本系统使用了片外DDR3 作为数据缓冲区。在此基础上,针对其中的核心关键模块,队列管理器和DDR3 控制器,进行了设计与实现。
仿真结果表明,该电路能够对不同的数据流实现有效管理,实现资源预留,正确地完成了数据流的写入与读取操作,能够对不同的业务提供绝对服务保证,减少了关键业务的时延。
