一种无源被动室内区域定位方法的研究
2020-07-18李若南李金宝
李若南 李金宝
(齐鲁工业大学(山东省科学院)山东省人工智能研究院 济南 250014)(黑龙江大学计算机科学技术学院 哈尔滨 150080)(黑龙江大学软件学院 哈尔滨 150080)
近年来,室内区域定位广泛应用于室内疗养院活动区域监控、智能场景(如机场、商场、博物馆等)区域导航、室内监狱犯人活动区域的标识和警戒、产区(如石油、化工等)电子围栏区域化管控、智慧大楼企业核心机密区域预警与室内施工场所(如地铁、隧道等)危险区域警报等各个领域.随着城市智能化的逐步发展,室内区域定位受到越来越多的关注[1].现有的室内区域定位技术中,低功耗蓝牙(bluetooth low energy, BLE)技术因低成本、低功耗、测量范围长等优势而得到广泛应用.基于BLE的室内区域定位方法主要包括近邻法、三边测量和指纹识别法[2-3].近邻法通过接收一些有限制范围的物理信号来判断用户是否出现在某一个锚节点附近,并指定最接近该用户的锚节点的区域为用户区域,该方法只提供粗略的区域信息,定位精度不高.三边测量利用无线设备与多个参考点的距离信息来进行区域定位,但是,由于噪声和障碍物阻隔使得信号衰减严重,进而导致测量的距离信息误差较大.指纹识别法包括离线阶段和在线阶段2部分,离线阶段通过从接收信号强度(received signal strength, RSS)序列中提取区域位置的相关参数构建指纹数据库,在线阶段利用从指纹数据库中查找的最匹配的RSS指纹,将当前RSS序列映射到参考区域,该方法定位效果较好,但实际操作复杂且指纹库更新与维护难度较大.RSS是一种不稳定的信号,其测量值在位置和时间上差异较大,致使上述方法都存在较大的定位误差.
本文提出了基于深度学习的室内区域定位模型,该模型利用注意力机制结合卷积神经网络(con-volutional neural network, CNN)和双向长短时记忆(bidirectional long short-term memory, BiLSTM)网络获取区域位置在空间维度和时间维度上的粗细粒度特征,实现室内区域定位.本文的主要贡献总结于3个方面:
1) 提出了新的基于注意力机制的CNN-BiLSTM室内区域定位模型(CNN-BiLSTM indoor regional positioning model based on attention mechanism, AMCLP),利用注意力机制,选取一些显著影响区域位置的RSS粗细粒度特征,在降低数据维度和计算复杂度的同时显著改善室内区域定位的性能;
2) 采用AdaBoost-SVM分类模型去除非视距(non-light of sight, NLOS)数据,并且通过截断傅里叶变换去除环境噪声来完成数据预处理,提高RSS序列的稳定性;
3) 利用走廊和会议室的真实数据构建数据集,对所提出的区域定位模型进行性能评估,证明了本文方法的有效性和对环境的适应能力.
1 相关工作
在基于BLE的室内区域定位方法中,最主要的误差来源于无线电信道效应的多径传播、反射、信道衰落等所引起的信号变化[4].目前,研究者主要采用近邻法、三边测量和指纹识别的方法解决上述问题.一些研究者采用近邻法和三边测量的方法,如Yu等人[5]提出的群集KNN(k-nearest neighbor)算法,该算法通过选择最佳最近邻点来减少环境干扰,提高区域定位性能.Jahan等人[6]结合三边测量和卡尔曼滤波算法来实现工业环境中的区域定位,其区域定位算法在2级产业环境[7](工业制造)中的定位样本准确率达到85.0%.目前,大多数研究人员使用基于RSS的指纹识别方法,该方法通常分为确定性算法(deterministic algonithm, DM)、概率性算法(probabilistic algorithm, PM)、模式识别算法(pattern recognition algorithm, PRM)三类.
DM是通过比较信号特征(如向量)与指纹库中计算出的统计值[8]来估计目标区域.Tsai等人[9]提出利用模糊逻辑技术定义RSS的分布为离散函数,通过将数据聚类成模糊集来解决RSS不稳定的问题;Jun等人[10]利用AP(access point)序列的度量来处理RSS的时间波动和设备异质性的问题,并且通过动态区域划分机制减少所需参考区域的数量;Mohsin等人[11]通过选择和组合来自几何和指纹方法的理想元素来构建RSS距离模型来追踪患者,获取患者所在的病房;Tian等人[12]提出基于RSS的指纹特征向量算法,通过匹配在线获取的RSS序列向量和RSS指纹数据库特征向量之间的相似性,估计用户所在网格区域,但该方法需要大量的环境测量和校准,难以实际应用;Li等人[13]提出基于原始细胞(cell of origin, COO)和接收的信号强度指示(received signal strength indication, RSSI)指纹的混合算法,通过目标与细胞区域的连接范围来估计目标的区域,在办公室和走廊环境下,定位在距离圆形目标区域的中心点2.32 m和2.06 m的样本准确率都为80.0%,该方法易于实施和维护,但成本高、误差较大.
PM是通过计算信号特征属于存储在指纹库中某个分布的可能性来估计目标区域.Youssef等人[14]通过构建的基于概率的推理模型,将RSS序列建模为时域和频域中的随机变量;Yadav等人[15]提出基于贝叶斯推理算法的区域定位模型;Sikeridis等人[16]采用无监督的学习算法,根据区域感知架构,构建基于网格区域的综合概率定位模型,在部署的多层设施测试平台上,定位在距离网格区域中心点0.80 m的样本准确率为88.5%,该模型对未标记区域有较好的定位效果,但依赖于边缘设备的计算和集中式的3层基础架构.
PRM是通过离线阶段收集RSS序列训练模型,在线阶段利用实时的RSS序列预测区域位置.Zhuang等人[17]利用信道分离多项式回归模型将指纹识别和扩展卡尔曼滤波融合来进行室内区域定位;Cao等人[18]提出基于车辆的概率和模式识别方法,该方法利用RSS概率分布函数表示网格区域的RSS值,并通过人工神经网络(artificial neural network, ANN)建立输入RSS序列和输出位置之间的对应关系,该方法在距离目标区域中心点0.96 m的样本准确率为96.4%,但训练复杂度高;Sánchez-Rodríguez等人[19]使用C4.5算法组合RSS和方向信息来建立了低计算复杂度模型,该模型在距离区域中心点2.60 m的样本准确率为95.0%,并且能够在轻量级设备上应用.
本文提出通过注意力机制捕获RSS序列与区域位置粗细粒度特征的映射关系,进而获取区域位置信息.相对于目前定位效果最好的网格区域综合概率定位模型[16],本文提出的方法在走廊和会议室环境中都取到了更高的定位精度和样本准确率.其中,2 m×2 m网格采集中走廊环境下,距离网格中心点小于0.50 m和小于0.75 m的样本准确率分别达到86.6%和96.4%;会议室环境下,距离网格中心点小于0.50 m和小于0.75 m的样本准确率分别高达96.5%和98.2%.
2 研究框架及实验方法
目前,利用RSS序列的室内区域定位研究已经取得了一些较好的研究成果,但这些研究或者存在定位精度差、准确率偏低的问题,或者存在算法过于复杂、依赖基础设施部署等问题.本文提出一种AMCLP模型,该模型通过CNN获取区域中心点的细粒度特征,利用BiLSTM根据时序规律获取区域范围的粗粒度特征,并且采用注意力机制捕获粗细粒度特征中与区域位置相关的特征,来获取区域位置信息.
图1是本文提出的室内区域定位系统架构.AMCLP的过程分3个步骤:1)利用构建的蓝牙Mesh网络,通过智能手机收集走廊和会议室环境中每个参考区域的RSS数据;2)利用AdaBoost-SVM分类模型去除原始数据中NLOS数据,并且通过截断傅里叶变换去除环境噪声来完成数据预处理;3)利用AMCLP模型获取区域位置信息.
2.1 数据预处理
如图2(a)所示,由于无线电信道效应[20]的多径传播、反射、信道衰落的影响,致使RSS在同一个参考区域信号波动较大.如图2(b)所示,不同锚节点的RSS序列中位数差别较小,统计特征不明显,难以在时域空间辨别噪声.本文采用AdaBoost-SVM分类模型去除NLOS数据,增强信息稳定性,然后通过傅里叶变换将RSS序列转换到频域空间,在频域空间里通过选用合适的滤波函数去除环境噪声.

Fig. 2 Timing diagram and box plot of anchor node RSS sequence and regional center point图2 锚节点RSS序列和参考区域的时序图和箱线图
2.1.1 AdaBoost-SVM分类模型
将本文的AdaBoost-SVM融合模型与一些常用的机器学习分类模型,如支持向量机(support vector machine, SVM)模型、自适应增强(adaptive boosting, AdaBoost)模型、随机森林+决策树(random forest+decision tree, RF+DT)模型,对走廊和会议室环境中NLOS和视距(light of sight, LOS)情况下的RSS数据进行建模分析,通过对比分析实验发现AdaBoost对于LOS环境下的RSS序列具有较好的分类效果,而SVM对于NLOS环境下的RSS序列具有较好的分类效果,因此本文建立AdaBoost-SVM分类模型,利用AdaBoost模型先区分大部分LOS环境下的RSS数据,SVM再从分错的样本中区分大部分NLOS环境下的RSS数据,通过2次分类能够去除大部分NLOS环境下数据.
AdaBoost是用于分类的常用的增强算法,它是一种结合相同类型弱分类器的自适应迭代算法.在本文中,弱分类器选用后向传播(back propagation, BP)神经网络,AdaBoost算法对训练集中每个BP神经网络,以0.1的学习速率,通过800次迭代训练原始的RSS序列并获取每个序列的权重,然后根据权重参数,通过学习速率增加值为1.05和减少值为0.7的自适应学习算法对网络进行优化,并对RSS序列进行NLOSLOS的分类预测,之后对分错的样本进行标记,并用SVM进行2次分类,最后对获取NLOS数据进行剔除.其中,BP神经网络的层数为3,网络个数为8,隐含层神经元采用S型正切函数,输出层神经元采用S型对数函数,隐含层神经元个数n2和输入层神经元个数n1之间的关系为
n2=2n1+1.
(1)
2.1.2 截断傅里叶变换去噪
文献[10]指出RSS序列为高斯分布,并且傅里叶变换对时序信号的全局噪声去除效果好,所以本文选用与信号峰相同的频域高斯形滤波器,利用傅里叶变换将信号由时域转换到频域,然后在频域通过高斯滤波函数去除高频噪声.信号f(w)经过离散傅里叶变换得到F(w):

(2)
其中,N为样本总数;σ为高斯宽度,σ越大,高斯滤波器的频带越宽,平滑程度越好.反变换过程将频域信号恢复成时域信号:

(3)
F(w)=0时频率称为截断频率F0,设定1个截断频率F0,小于F0为噪声,其值置为0,F0过高,去噪效果差,F0过低,去噪过度损失正常的信号.本文根据经验设定σ=20,F0=50时可以有效地去除高频噪声.通过傅里叶反变换可获得去噪后的信号.
2.2 AMCLP模型
如图2(a)所示,RSS是不稳定时序信号,其短序列特征存在较大差异,且同一参考位置、不同锚节点的RSS序列具有相似响应波形,锚节点之间的RSS序列相互关联.针对时序数据这一特性,本文利用CNN处理局部数据的关联性和特征提取,通过BiLSTM捕获数据时序性和依赖性,并结合注意力机制实现室内区域定位,如图3所示,AMCLP模型主要由3部分构成:CNN层、BiLSTM层、注意力机制.

Fig. 3 Model of AMCLP图3 AMCLP模型
CNN层采用64个1×1卷积核作为区域中心点的特征提取器,利用权重共享提取输入的序列信息中包含区域中心点的细粒度特征,为了防止过拟合,在CNN层后添加丢弃层,丢弃率设定为经验值0.2,且CNN层和丢弃层的激活函数为Relu.此外,文献[21]指出在CNN中,浅层神经元倾向于学习一些简单的特征,比如边缘、位置等,深层神经元能够检测到一些抽象的特征,比如动作、表情等.对于时序数据来说,随着网络深度的增加,模型的复杂度也会增加,所以为了降低模型复杂度并保证网络性能,本文根据经验将卷积层设置为2层.
BiLSTM层在循环神经网络(recurrent neural networks, RNN)的结构上加入记忆门与3个门控单元,通过64个LSTM单元来对历史和未来消息进行有效的控制.如式(4)~(9)所示,遗忘门ft的权重矩阵(Wxf,Whf,Wcf,bf)用来控制是否忘记当前状态,输入门it的权重矩阵(Wxi,Whi,Wci,bi)用来控制是否应存储输入,输出门ot的权重矩阵(Wxo,Who,Wco,bo)用来控制是否输出状态,这3个门通过设置xt,ht-1,ct-1的状态来决定是否接受输入,是否忘记之前存储的内容并输出稍后生成的状态.其中,xt表示当前时刻的输入,ct-1表示上一时刻神经元细胞状态,ht-1表示上一时刻的隐层向量状态,ht表示当前时刻的隐层向量状态,ct表示当前时刻神经元细胞状态,ct可通过ct-1和it的加权之和获得:
it=σ(Wxixt+Whiht-1+Wcict-1+bi),
(4)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf),
(5)
gt=Relu(Wxcxt+Whcht-1+Wccct-1+bc),
(6)
ct=itgt+ftct-1,
(7)
ot=σ(Wxoxt+Whoht-1+Wcoct-1+bo),
(8)
ht=otRelu(ct).
(9)
BiLSTM[22]通过引入第2层,扩展了单向LSTM网络,即在原有的正向LSTM网络层上增加1层反向的LSTM层,在第2层中隐层的连接以相反的时间顺序流动,因此该模型能够充分利用来自过去和未来的信息.我们使用逐元素和来组合正向和反向传递输出:

(10)
Iv表示v个锚节点的RSS序列向量,C(·)表示CNN粗粒度特征提取,H(·)表示LSTM细粒度特征提取.BiLSTM的3个门的交互操作使得BiLSTM能够根据当前数据与过去、未来数据的关联,抽取潜藏时序规律的区域范围的粗粒度特征Bi.此外,其存储记忆特性可以有效地解决反向传播中梯度消失的问题:

(11)
注意力机制的原理是对输入序列的不同局部,赋予不同的重要性,即权重,而对于不同的输出序列局部,输入局部给不一样的赋值规划或者方案,即输出序列局部由上一阶段输出和当前阶段的输入局部构成.注意力机制利用激活函数为Sigmoid的128个神经元生成权重参数Ai,Ai作为注意力分配的系数,从序列中学习每1个粗细粒度特征的重要程度,并按重要程度将特征合并,采用加权的方式对RSS序列上下文信息进行1次基于权重的筛选,让网络能够学习捕获RSS序列上下文在时序上、空间上的结构关系.
Ai=Sigmoid(wTBi),
(12)
Li=Bi×Ai,
(13)
其中,i表示样本序列数,Ai表示第i个RSS序列的权重参数,Bi表示第i个RSS序列的细粒度特征,Li表示室内区域的位置信息.随着RSS序列的不断增加,由于不同的时间片和空间位置信息量的差别明显,使得模型根据时间步方式捕获特征的能力越来越差,而注意力机制可以有效利用序列差别信息,提升序列学习效果.根据经验,设置样本批次为100,迭代次数为230,优化算法为Adam(adaptive moment estimation)算法.
3 实验与分析
在本研究中,实际测量数据表明:当相邻蓝牙装置相隔3~4 m时,所测信号最稳定,定位效果最好.为充分利用节点资源,如图4所示,当5个锚节点在走廊与会议室中不呈现随机分布而分别近似呈线性分布与星型分布时,实验定位的精度和准确度呈现最佳效果.

Fig. 4 Experimental scene图4 实验场景
实验环境是某实验楼的1段走廊和1个会议室,实际场景分别如图4(d)和图4(b)所示,空心箭头(黄色箭头)表示5个锚节点M1,M2,M3,M4,M5的位置.图4(c)为走廊环境平面图,宽3 m,长30 m,锚节点线性分布,相邻锚节点距离为3 m;图4(a)为会议室环境平面图,宽7 m,长8 m,浅色区域(黄色区域)表示障碍物,相邻锚节点距离3 m或4 m.表1为实验场景参数,其中T表示每个场景观察的周期,H表示每个参考区域观察时长,S_com表示场景复杂度,A_num表示锚节点数量,A_distri表示锚节点分布,A_Dis表示相邻锚节点的距离,S_size表示场景规格,M_size表示网格尺寸,D_dim表示数据集维数,S_num表示样本数,R_num表示网格个数.

Table 1 Experimental Scene Characteristics and Parameters表1 实验场景参数
如图4所示,利用走廊和会议室环境下部署的BLE锚节点构建Mesh网络,其中BLE设备以相同的传输功率周期性广播锚节点信息,根据被定位目标因遮挡和阴影效应对无线信号的影响,判断目标所在的区域.首先将定位环境均匀地划分为R_num个网格,记录网格中心点坐标,通过智能手机在每个网格区域的中心点,采集由目标遮挡和阴影效应引起的锚节点RSS序列变化值,每个网格区域采集5~6 min的数据,测试周期为1周.网格尺寸分为1 m×1 m,1 m×2 m,2 m×2 m这3种类型,根据网格尺寸和测试环境构建6个不同训练集,每个训练集(D_X,D_Y)中,D_X表示RSS的样本数,D_Y表示锚节点的RSS序列(IRSS1,IRSS2,IRSS3,IRSS4,IRSS5)和标记的网格中心点坐标(X_center,Y_center).如表1所示,走廊环境下,样本总数分别为33 532,11 210,5 388,尺寸为1 m×1 m,1 m×2 m,2 m×2 m的网格数量分别为63,21,11.会议室环境下,样本总数分别为22 001,10 935,5 667,尺寸为1 m×1 m,1 m×2 m,2 m×2 m的网格数量分别为42,20,11,训练集与测试集的样本比例为7∶3.
3.1 数据滤波效果评估
如图5所示,本文选用4种滤波算法对锚节点M1的RSS进行测试,其中,图5(a)~(e)分别表示原始数据图、中值滤波图、窗口平均滤波图、算术平均滤波图、截断傅里叶变换滤波图.通过比较可以发现:中值滤波在不改变样本数量的前提下能够过滤特别明显的异常噪声,但是对于不太明显的异常噪声和一般噪声效果不好.窗口平均滤波法不能去除掉明显的异常噪声和异常噪声.算术平均滤波法能够过滤特别明显的异常噪声,但对于一般噪声效果不好,并且样本的数量会有所减少.截断傅里叶变换滤波法可以在不改变信号波形和样本数量的情况下,去除绝大部分的噪声使信号更加稳定.因此,本文选用截断傅里叶变换滤除噪声.

Fig. 5 Comparison of filtering effect of five different filtering algorithms图5 5种不同滤波算法滤波效果比较
3.2 分类性能分析
为了验证本文提出的AdaBoost-SVM融合模型的NLOSLOS分类性能,如表2所示,分别将本文的融合模型与单SVM模型、单AdaBoost模型、AdaBoost+预处理、融合RF+DT模型进行对比实验,其中,表2中黑体部分表示本文的融合模型的实验效果.此外,本文根据基于混淆矩阵的标准度量评估这些机器学习算法性能,4类分别为TP(true positive),TN(true negative),FP(false positive),FN(false negative).应用的分类性能指标为:


Table 2 NLOS Classification Performance表2 NLOS分类性能
AdaBoost模型中BP作为弱分类器参与建模,SVM的时间复杂度为O(N2M),AdaBoost的时间复杂度为O(NMlgM),AdaBoost-SVM的时间复杂度为O(NMlgM+N2M),N为特征维度,M为样本数.由表2可知,预处理后的单个机器学习模型AdaBoost与常用的组合模型RF+DT相比,分类精度提高3.1%,灵敏度提高1.4%,F1提高2.4%.此外,AdaBoost对LOS数据具有较好的分类效果,而SVM对于NLOS数据具有较好的分类性能,因此本文通过将SVM和AdaBoost进行结合,利用2次分类来提高NLOS的分类性能.与传统的单个机器学习模型SVM和AdaBoost相比,AdaBoost-SVM融合模型时间复杂度分别增加O(NMlgM)和O(N2M),但是准确度提高了16.5%和21.3%,分类精度提高了26.7%和27.9%,F1提高了13.7%和14.0%,AdaBoost-SVM模型在离线训练阶段以执行时间为代价获得高精度和高准确度.与常用的组合模型RF+DT相比,AdaBoost-SVM融合模型分类性能最优,其分类准确率和精度分别高达97.6%和99.9%,F1达到97.5%,灵敏度达到95.2%.
3.3 定位性能分析
本文设置距离定位区域中心点小于0.40 m,0.50 m和0.75 m为评估区域,如表3所示,采用样本与区域中心点坐标之间的平均平方误差MSE(mean squared error)、平均绝对误差MAE(mean absolute error)、样本预测准确率NUM_pre(number prediction accuracy)作为评估指标:

(14)
其中,NUMT表示落入参考区域样本数,NUMF表示没有落入参考区域样本数.
不同情况下定位效果如表3所示,其中G_dis表示评估区域,即距离定位区域中心点误差分布的区间“<0.40 m”,“<0.50 m”和“<0.75 m”.Tr_num表示训练集样本数,Te_num表示测试集的样本数.Scene表示实验环境,Edge表示测试样本是否位于边缘区域,其中,“×”表示测试样本不在边缘区域,“Right”表示测试样本位于右边缘区域,“Left”表示测试样本位于左边缘区域,De_no表示是否进行数据去噪,其中,“√”表示对数据进行去噪处理,“×”表示对数据不进行去噪处理.
3.3.1 不同环境的室内区域定位效果
如表3所示,走廊和会议室平均平方误差分别为0.11m和0.03 m,平均绝对误差分别为0.12 m和0.05 m,差别很小.表4为走廊和会议室样本准确率差值,走廊、会议室样本准确率在“<0.40 m”,“<0.50 m”,“<0.75 m”的平均差值分别为10.3%,7.0%,2.3%.图6(a)~(c)分别是1 m×1 m,1 m×2 m,2 m×2 m网格区域中走廊和会议室环境下的样本准确率.如图6(c)所示,2 m×2 m网格环境下,走廊和会议室评估区域为“<0.75 m”的样本准确率为94.4%和98.2%.综上可知:本文的AMCLP区域定位算法在不同环境、不同锚节点布局下定位准确度和精度都较好.

Table 3 Positioning Effect in Different Situations表3 不同情况下的定位效果
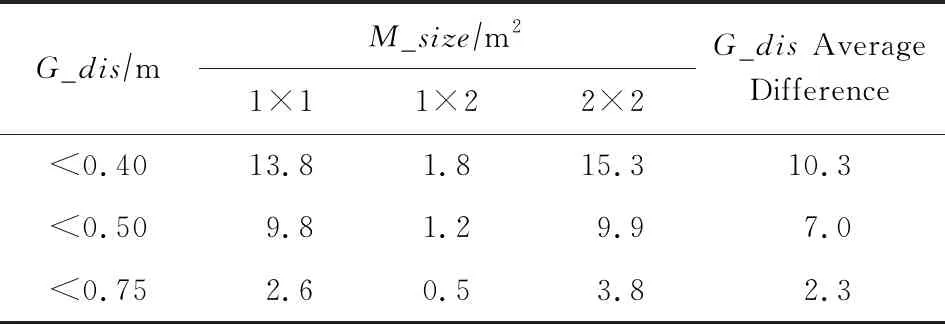
Table 4 Corridor and Meeting Room Positioning Accuracy Difference

Fig. 6 Positioning accuracy of different environments and different anchor nodes图6 不同环境和不同锚节点布局定位样本准确率
3.3.2 边缘位置的室内区域定位效果
左边缘和右边缘区域分别表示距离左墙壁和右墙壁10 cm的区域,正常区域表示距离墙壁大于1 m的区域,评估区域G_dis表示定位到区域中心点的误差距离“<0.40 m”,“<0.50 m”,“<0.75 m”的区域.
如图7所示,和正常区域位置相比,当评估区域为“<0.40 m”时,左边缘区域和右边缘区域的样本准确率分别降低15.6%和4.6%;评估区域为“<0.50 m”时,左边缘和右边缘的样本准确率分别降低10.7%和2.2%;评估区域为“<0.75 m”时,左边缘和右边缘的样本准确率分别降低2.2%和1.4%.所以与正常区域相比,当评估区域为“<0.40 m”和“<0.50 m”时,左边缘区域的样本准确率变化较大,当评估区域为“<0.75 m”时左边缘区域的样本准确率变化不大.

Fig. 7 Edge position location sample accuracy图7 边缘位置定位样本准确率
而右边缘区域在不同评估区域内的样本准确率变化始终很小.此外,评估区域为“<0.75 m”时,左边缘、右边缘及正常区域的样本准确率分别是97.5%,99.7%,98.3%.因此,本文的AMCLP区域定位算法在边缘区域定位也取得了很好的效果.
3.3.3 不同网格区间室内区域定位效果
图8为不同网格样本的准确率,与1 m×2 m网格相比,会议室环境下,不同网格的样本准确率差别很小.走廊环境下,当评估区域为“<0.40 m”时,1 m×1 m和2 m×2 m网格的样本准确率相差14.6%和17.1%;当评估区域为“<0.50 m”时,1 m×1 m和2 m×2 m网格的样本准确率相差10.4%和12%;当评估区域为“<0.75 m”时,1 m×1 m和2 m×2 m网格的样本准确率相差3.1%和5.3%,故AMCLP区域定位算法在不同网格下样本准确率和定位精度较好.
3.4 不同算法的区域定位效果
本文将AMCLP与现有的区域定位模型原始COO指纹[13]、无监督综合概率[16]、ANN[18]、C4.5[19]进行了性能比较,表5为不同算法的区域定位效果,其中,表5中黑体部分表示本文算法的定位误差和定位准确度.
由表5可知,本文的AMCLP方法在1 m×2 m网格采集下,距离网格中心点0.50 m的样本准确率为97.4%,相比于无监督综合概率定位模型[16],网格区域中心点距离至少提高0.30 m,样本准确率提高8.9%,与文献[18]的方法相比,网格区域中心点距离提高0.46 m,样本准确率提高1.0%,所以,本文的AMCLP方法得到了最好的样本准确率和定位精度.

Table 5 Regional Positioning Effect of Different Algorithms表5 不同算法的区域定位效果
4 总 结
本文提出AMCLP模型,该模型利用注意力机制,通过融合粗细粒度特征,学习RSS序列特征与区域位置的映射关系来获取区域位置.预处理时,利用AdaBoost-SVM分类模型去除NLOS数据,其分类准确率和精度分别达到了97.6%和99.9%,F1达到97.5%,灵敏度高达95.2%.实验结果表明,距离网格中心点小于0.75 m的样本准确率,在走廊环境和会议室环境,1 m×1 m网格采集下分别高达96.6%和99.2%,1 m×2 m网格采集下分别高达98.3%和99.2%,2 m×2 m网格采集下分别高达94.4%和98.2%.与文献[16]相比,距离网格中心点的距离至少提高0.05 m,其中,走廊环境和会议室环境中的样本准确率在1 m×1 m网格采集下提高了8.1%和10.7%,在1 m×2 m网格采集下提高了9.8%和10.7%,在2 m×2 m网格采集下提高了5.9%和9.7%.未来工作中,计划在更复杂的室内环境下进行实验,获取更多区域位置的RSS序列特征信息以进一步验证本文的室内区域定位模型AMCLP.
