适应立体匹配任务的端到端深度网络
2020-07-18徐士彪张晓鹏
李 曈 马 伟 徐士彪 张晓鹏
1(北京工业大学信息学部 北京 100124)2(中国科学院自动化研究所 北京 100190)

Fig. 1 Architecture of PSMNet[13]图1 PSMNet网络结构[13]
立体匹配(stereo matching)是计算机视觉领域中的经典问题.相比激光测距等方法,立体匹配能够低成本从双目图像中便捷恢复场景深度,在自动驾驶、机器人避障、立体图像智能编辑等领域具有重要应用价值[1-5].近年来,深度学习(deep learning)受到广泛关注,并在诸多计算机视觉任务中取得显著成功[6-8].鉴于此,国内外研究者尝试设计用于立体匹配的深度网络[9-10].相比传统方法,深度学习模型尤其是端到端模型,能够在学习大量数据的基础上得到更准确的视差结果[11-15].
然而,现有深度网络尚存在诸多不足:现有网络的特征提取模块多源自于求解其他问题的网络模型,对立体匹配任务特性考虑不足,冗余度高;3D卷积常用于立体匹配的视差计算,性能优越.然而,3D卷积复杂度高,难以实现大卷积核运算,现有网络多采用小卷积核3D卷积,感受野范围受限.
针对上述问题,提出改进的端到端神经网络模型.该模型以当前性能优异的金字塔立体匹配网络(pyramid stereo matching network, PSMNet)[13]为基准方法,对其核心模块,包括特征提取模块和3D卷积匹配模块,进行改进.所提出特征提取模块专为立体匹配问题所设计.相比现有特征提取网络,结构更简洁,能够在保持结果精度前提下分别以90%和25%的幅度大幅减少参数量与计算量.在视差计算模块中,提出分离3D卷积,相比现有3D卷积复杂度低.因此,可实现大卷积核运算以扩充感受野,从而提高立体匹配准确度.在SceneFlow数据集上验证了所提出方法的优异性能,并通过对比实验从准确度、计算成本等方面验证2个模块的有效性.
1 整体网络架构
本文所提出网络以PSMNet为基准网络,因此,先简要说明PSMNet网络结构,再给出本文网络设计.
PSMNet网络结构如图1所示.首先,提取立体图像特征,用于构建匹配成本特征体(cost volume).之后,通过3D卷积运算计算视差.在立体图像特征提取过程中,PSMNet使用类似ResNet[16]的网络结构,再使用空间金字塔池化(spatial pyramid pooling, SPP)结构[13,17]融合多尺度特征增强特征表达.然后将特征连接形成匹配成本特征体.在视差计算部分,PSMNet网络包括2种版本网络,分别是多次残差级联Basic的3D卷积网络和使用Stackhourglass结构[18]的3D卷积网络.
本文在PSMNet网络结构基础上提出改进的立体匹配网络架构.如图2所示.首先,从立体匹配问题特性出发,提出简洁的特征提取网络SimpleResNet,替换PSMNet网络中的特征提取部分.之后,提出用于视差计算的具备大感受野的分离3D卷积层,替换PSMNet网络的Basic结构中的3D卷积层.
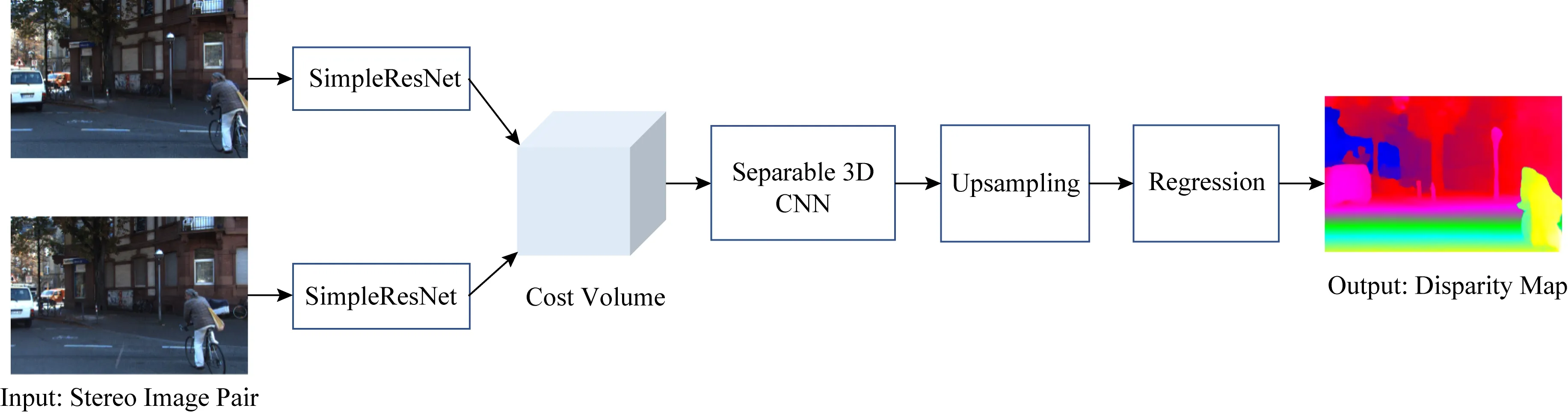
Fig. 2 Architecture of the proposed task-adaptive network for stereo matching图2 本文适应立体匹配任务的网络结构
2 适用立体匹配的特征提取结构
PSMNet网络的特征提取部分使用了类似ResNet网络的结构.但是,ResNet网络原是针对图像分类任务所设计.图像分类与立体匹配2个任务之间存在较大差别.
首先,图像分类属于平移不变任务,要求即使输入图像发生平移变换,输出分类结果不变.与图像分类不同,立体匹配需要平移敏感,即当输入图像有空间移动时对应结果也应该有相应变化.其次,图像分类需要提取高度抽象的特征用于表达语义信息,以对图像内容类型做出准确判断.但是,立体匹配求解过程并不需要语义级别特征.事实上,立体匹配需要求解2张图像上像素点之间的对应关系.因此,要求网络在不同空间位置提取的特征具有更多局部细节描述能力.
具体而言,在分类任务中,通常采用较深的特征提取网络,并倾向采用大的感受野.网络越深,感受野越大,可用的全局信息越多.同时,感受野足够大,才能够提取出具有平移不变性的特征.而且,随着网络层数的加深,提取到的特征更抽象,也更能够表征图像语义.但是,在立体匹配任务中,增大感受野将降低网络所得特征的差异性.特征图上相近位置的特征将因为大的感受野所导致的对应图像区域重叠度大而变得相似,特征自身位置信息也变得模糊.
综上,立体匹配任务对于高抽象程度的语义特征没有需求.采用较低抽象程度的特征更便于区别不同空间位置的像素.抽象特征不仅难以带来显著的性能提升,而且其获取需要较深层次网络结构.而较深网络意味着更多的参数量与计算量.因此,直接将原本用于处理图像分类任务的网络结构用于立体匹配不够合理.
鉴于上述事实,本文设计了专用于立体匹配任务的特征提取网络.在该网络中,通过限制卷积核大小以减少感受野;同时,简化卷积网络结构,在大幅减少参数量的同时增加网络能够提取的细节信息的比重,使提取的特征具有更强的差异性,更便于鉴别不同空间位置的像素.鉴于所提出的特征提取网络是依据立体匹配特性针对ResNet网络进行简化得来,将其称为SimpleResNet网络.其具体结构如表1所示.其中,H和W分别表示输入图像高和宽.网络参数表示方法与ResNet网络相同[16].例如Conv2_x残差单元包含4组2层卷积操作. 其中,第1层卷积操作的卷积核尺寸为3×3,输出通道为64;第2层卷积操作的卷积核尺寸为1×1,输出通道为32.

Table 1 Architecture Parameters of SimpleResNet表1 SimpleResNet网络结构参数
为方便与PSMNet网络的特征提取部分进行对等比较以验证本文推论,本文在SimpleResNet网络中保留了PSMNet特征提取部分所用ResNet网络的整体结构,只依据推论做出2方面修改:限制了非下采样且具有重复结构层的卷积核大小;大幅度消减重复网络结构.如此,限制感受野和减少层数的同时保持网络整体结构不发生改变.具体地,只保留PSMNet中Conv_1与Conv3_x中的卷积核原尺寸,其余卷积核减少至1×1大小;去除Conv1_x,Conv2_x,Conv3_x模块中的重复卷积结构;将原特征提取部分的48层卷积层减少至14层.重复结构和层数减少量依据实验得来.
相比PSMNet网络的特征提取结构,Simple-ResNet网络复杂度和计算量减少显著:原特征提取网络约有300万个参数,SimpleResNet网络参数减少至不足20万个,减少量超过90%.所作简化操作均源自前述推论:立体匹配并不需要过大感受野和高度抽象的语义信息,如ResNet网络这类层次深、感受野覆盖范围大的结构,对于立体匹配任务而言存在极大冗余.因此,所提出方法并不会因为网络深度的大幅度减小而对立体匹配准确度有较大影响.后续通过实验验证了该观点.
3 分离3D卷积(separated 3D CNN)
在端到端立体匹配深度网络中,3D卷积能够在优化匹配成本特征体的同时实现视差计算.与前段网络部分以提取特征为目的不同,此段网络的目的是利用邻域信息优化已提取的成本特征,以减少视差中错误离散值的出现.
鉴于采用更大邻域范围内的约束将更有利于优化成本特征,倾向在网络中应使用较大卷积核.然而,3D卷积计算复杂度高,扩大3D卷积核将带来巨大的参数量增加.
为了克服3D卷积计算在扩大感受野时的参数量爆炸问题,提出分离3D卷积层结构.图3(a)是正常的3D卷积层,图3(b)是所提出的分离3D卷积层.分离3D卷积将3D卷积分解为1次长与宽维度的2D卷积与1次视差维度的1D卷积.普通3D卷积参数量为m2×c(m为卷积核宽高,c表示类型数),而使用分离3D卷积的参数量是m2+c.当m与c增长时,后者参数量增长远小于前者.

Fig. 3 3D convolution and separated 3D convolution图3 3D卷积与分离3D卷积
此外,考虑到与分类任务不同,立体匹配任务中输入图像分辨率大,训练时每批数据数量较少,不适合在分离3D卷积后接批量归一化(batch normali-zation, BN)操作.因此,本文使用分离3D卷积搭配群组归一化(group normalization, GN)层替代PSMNet里的3D卷积和BN层结构.
4 实验与结果
本节通过实验验证所提出方法和模块.首先,介绍所用数据集、评价标准与网络训练过程.然后,通过消融实验验证本文方法和模块的有效性.之后,通过与当前优秀方法进行性能比较与分析,证明本文方法的先进性.最后,通过对比基准网络PSMNet,证实所提出网络在时间、显存占用方面的优势.
4.1 数据集与训练过程
使用SceneFlow数据集完成网络的训练与对比实验.SceneFlow数据集[11]属于大型合成数据集,共计包含35 454对训练用立体图像数据与4 370对测试用立体图像数据.每对数据都提供了稠密真值信息与相机参数信息.数据集中所有图像分辨率均为960×540.SceneFlow数据集按照场景内容分为3个子数据集,分别是FlyingThings3D,Driving,Monkaa.其中,Flying-Things3D子数据集的场景包含大量漂浮的随机类型物体,图像内物体较多,细节内容较为丰富;Driving子数据集是在模拟汽车驾驶过程中所抓取,其内容是开阔的街道场景;Monkaa子数据集的场景内容是深林环境中的猴子,其中有较多近距离物体,即存在较多视差值较大的区域.
本文实验使用端点误差(end-point-error, EPE)作为量化指标评.端点误差是真值与估计视差值之间的平均欧氏距离.其计算为
(1)
其中,d与gt分别表示视差的估计值和真值,N是参与计算的像素总数,n是指示变量.EPE评价指标分值越低表示方法性能越好.
在Pytorch框架下构建网络.在Ubuntu操作系统下完成网络训练.训练所使用GPU为单个NVIDIA GeForce TITAN X Pascal.
网络使用Smooth L1距离作为监督训练的损失函数.需要注意的是,所提出网络和PSMNet网络相同,均设置视差上限为192.该值适用于大部分实用情形.但是,SceneFlow数据集中存在部分数据视差真值超过该上限.为避免此部分数据的干扰,训练过程只取用视差真值小于等于192数据参与计算损失函数回传.训练损失函数:
(2)
其中:
其中,dn与gtn分别表示第n点的网络估计视差值与视差真值,N′表示视差真值小于等于192的像素点总数.
网络每次训练数据批量大小设置为3.训练过程是端到端训练,无需其他后处理方法.针对数据集中每对图像以原尺寸输入网络,训练学习率设置为0.001,在SceneFlow数据集上使用Adam优化方法[19]训练10轮.Adam方法参数为β1=0.9,β2=0.999.训练时间持续约40 h.
4.2 消融实验与分析
在SceneFlow测试集上通过消融实验测试所提出网络的核心模块,包括特征提取模块SimpleResNet和分离3D卷积模块Globalconv.结果如表2所示.
用ResCNN+Basic+BN表示PSMNet网络的原始基础结构.SimpleResNet+Basic+BN表示使用本文提出的特征提取模块SimpleResNet代替PSMNet中的特征提取模块ResCNN.从替换前后的EPE数值可看出:相比ResCNN,所提出特征提取网络结构SimpleResNet网络参数降低超过90%(见第3部分分析)的情况下,依然能够保持较低的EPE.

Table 2 EPEs of PSMNet and Our Networks表2 本文网络与原网络EPE对比
进一步地,以PSMNet网络性能最佳的组成结构ResCNN+SPP+Stackhourglass+BN为基准方法验证所提出的特征提取网络.表2中SimpleResNet+Stack hourglass+BN是用所提出特征提取网络替换原特征提取网络.从表2实验数据看:在此框架下,所提出特征提取网络在参数量减少情况下,EPE更低.
为验证所提出分离卷积的效果,在SimpleResNet+Basic+BN基础上,使用所提出的分离3D卷积替换Basic中所用到的普通3D卷积,记作SimpleResNet+Globalconv+BN.从表2可以看出:相比普通3D卷积,分离3D卷积能够有效降低误差.表2中SimpleResNet+Globalconv+GN方法是用分离3D卷积加GN层替换了SimpleResNet+Basic+BN中原属于PSMNet的后2部分.从结果可看出:该方法的EPE相比SimpleResNet+Basic+BN的EPE,降低约12%的相对量.该实验说明:所提出分离3D卷积搭配GN操作相比普通3D卷积搭配BN操作,性能显著更佳.
需要注意的是:以上对比方法(除PSMNet网络性能最佳的组成结构外),以及本文方法均未加入SPP结构.既是为了方便与PSMNet中基础方法(不含SPP结构)对比,也是因为SPP结构将破坏SimpleResNet网络局部性特征提取能力.
4.3 横向对比实验与分析
所提出方法与其他现有深度学习立体匹配方法在SceneFlow测试集上的EPE对比如表3和图4所示.其中Ours为本文性能最佳方法,对应表2中的SimpleResNet+Stackhourglass+BN.从表3和图4可见:相比其他5种方法,PSMNet网络效果最佳;而相比PSMNet网络,本文方法在大幅度降低特征提取模块参数的同时,EPE更低.

Table 3 EPEs of Our Networks and Other Methods表3 本文网络与其他网络方法EPE对比
图5是采用SimpleResNet+Stackhourglass+BN方法与PSMNet方法在ScenenFlow数据集上所得视差结果.如图5所示,本文方法与PSMNet网络在大部分区域表现相近,均能够得到与真值相近的结果.但是在方框标示的物体内部的连续区域,PSMNet网络所得结果出现明显错误,而所提出方法结果基本无误.

Fig. 4 Visualized EPEs of our network and other methods图4 本文网络与其他网络方法EPE可视化对比

Fig. 5 Disparity maps obtained by our network and PSMNet图5 本文网络与PSMNet网络视差计算结果
4.4 计算成本分析
表4和图6给出了所提出方法和基准方法的时间与显存开销的实验数据.在此实验中,所有方法在每批次训练过程中统一采用1张输入图像.从表4和图6中可以看出:本文方法SimpleResNet+Basic比基准方法ResCNN+Basic减少了约0.4 GB显存占用.同时,单次训练速度加快约0.1 s,提升量为25%.相较Basic方法,使用Globalconv模块显存增量约为0.7 GB.显存占用增长是由于Globalconv模块所用更大的卷积核以及所增加的中间缓存所导致.其中,由中间缓存带来的显存占用增长占比更多.在实际使用中可以通过及时释放中间缓存以释放更多的显存.Basic结构使用相同大小的卷积核会因为显存不足而无法运行.

Table 4 Computation Time and Memory Costs of Different Networks
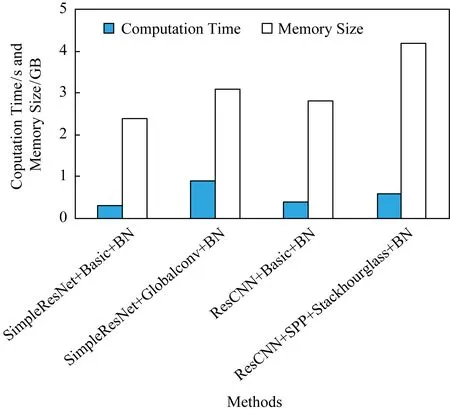
Fig. 6 Visualized time and memory costs of different networks图6 各网络计算时间开销与显存占用可视化对比
改进后Globalconv模块相比Basic方法时间增长较为明显.这是因为分离卷积后,在视差维度上将卷积核扩大至覆盖所有视差的同时,需要对原特征填补较大区域,该操作带来较多额外耗时.
5 结 论
在分析现有端到端立体匹配网络不足之处的基础上,提出了改进的立体匹配深度网络.首先,根据立体匹配任务特性设计了新的特征提取结构.该结构在减少90%参数量的同时,能够保持稳定的网络性能.之后,提出了分离3D卷积运算.相比传统3D卷积,该运算能够在增大卷积核尺寸扩大感受野的同时抑制参数量的增加,从而提高视差计算的精度.
所提出网络也存在不足之处.例如分离3D卷积需要额外的填补操作、增加了较多额外耗时.本文将在未来工作中着手解决该问题.
