基于多模态输入的对抗式视频生成方法
2020-07-18于海涛杨小汕徐常胜
于海涛 杨小汕 徐常胜,
1(合肥工业大学计算机与信息学院 合肥 230031)2(模式识别国家重点实验室(中国科学院自动化研究所) 北京 100190)
视频的自动生成技术具有广泛的应用前景,例如视频编辑、增强现实、电影和游戏制作等.早期针对图像视频生成技术的研究主要集中在计算机图形学领域展开[1-3].最先进的计算机图形学算法能够合成逼真的照片和视频,但这些技术需要依赖于专用的设计软件和大量专家的手工劳动,而且通常被限制在特定的人物、物体或者场景.近年来,随着深度学习技术在物体检测、行为识别等领域取得突破性进展[4-6],视频生成这一更具有挑战性的问题逐渐走入了计算机视觉和多媒体等领域研究人员的视野.实现能够自动生成真实视频的人工智能算法是更完备的视觉表观信息和运动信息理解的一个重要标志.
传统的深度神经网络分类模型需要监督式地在大规模标注样本上进行训练,而生成对抗网络(generative adversarial network, GAN)[7]通过对抗式地训练生成式网络和判别器网络来无监督地学习样本的特征分布,进而可以根据随机种子,生成真实样本.基于这一思想,GAN在图片风格化和图像生成领域取得了优异性能[8-10],同时也被应用于视频生成并成为目前的主流方法[11-14].相比图像生成算法,视频生成是一项具有更多挑战的任务.尽管视频只比图像数据多了一个时间维度,但因此带来的运动信息的动态变化以及视觉内容的多样性都使得可能生成的结果空间变得十分巨大.此外视频是对执行各种动作的对象的视觉信息进行时空记录,生成模型除了要学习对象的外观模型外,还需要学习对象的物理结构.这些都是视频生成的困难所在.Vondrick等人[15]把视频表示为潜在隐空间中的特征点,可以训练生成网络来表示从隐空间到视频片段的映射.Tulyakov等人[12]把视频的潜在特征空间分解为运动子空间与内容子空间,大大减小了模型的复杂度.但由于这些方法是基于随机噪声生成视频,生成的视频存在视觉外观模糊不清、运动信息规律性不强的问题.
针对上述问题,大量基于条件式生成对抗网络的方法被提出.Li等人[14]提出用自然语言作为输入条件来指导视频生成.虽然自然语言对描述视频中的关键内容和主要运动信息有很大的帮助,但是仅用语言作为条件,最终生成的视频难以准确表达物体背景的细节信息以及长期的动态变化.在一些条件视频生成[16-18]中,运动轨迹、人脸AUs(action units)值和语义图等信息分别被作为输入条件来指导视频内容生成.虽然这些方法在特定领域的视频上得到了较好结果,但这些输入条件的标注仍然需要较为专业的技术人员才能提供.
本文我们希望建立更为简单、有效的输入条件来得到更加鲁棒、可控的视频生成模型.为了提供充足的视觉外观信息,我们采用图片作为输入来表达视频中包含的主要物体和场景信息.考虑到自然语言是人类用于描述事物或者表达意图的最有效的工具,因此在运动信息方面,我们采用自然语言作为引导.基于以上讨论,我们提出基于图片和文本输入的多模态对抗式视频生成模型.一方面,我们将输入的文本信息通过循环神经网络进行编码来提取语义特征.这些语义特征将被解码为运动特征来辅助视频中的视觉信息生成和运动信息生成.另一方面,考虑到视频片段中的物体或者场景在较短时间内通常比较相似,我们学习输入图片到视频帧的仿射变换来得到更为准确和连贯的视频序列.由于缺乏运动信息的监督标签,我们采用了生成对抗网络捕捉帧与帧之间的运动信息,为特征提取网络提供反馈,使其能够生成连续有意义的运动特征.
本文的主要贡献是提出了一个新的多模态对抗式视频生成模型,将文本信息和图片信息同时引入视频生成,使得生成模型更加可控、生成结果更加鲁棒.
1 相关工作
我们简要地将相关工作分为两大类:图像生成和视频生成,下面将分别围绕这2个方面详细介绍相关工作.
随着深度学习在图像分类和物体检测领域取得突破性进展,如何生成真实的图像在人工智能领域也得到了广泛的研究和分析.最早在2014年Goodfellow等人[7]提出了GAN网络的理论框架,利用GAN以无监督的方式生成图像.虽然早期的GAN为图像生成提供了一个独特而有前景的方向,但是生成结果存在模糊不清、细节丢失等问题.为了得到高质量的图像,Denton等人[19]进一步将拉普拉斯金字塔引入GAN.最近,Reed等人[20]利用GAN基于给定的文本描述进行图像生成,实现了从字符级到像素级的翻译.Zhang等人[21]将2个生成网络叠加在一起,逐步渲染出逼真的图像.CoupledGAN[8]构建了在不同域中生成图像的模型,可以无监督地将一个域中的图像转换为另一个域中的图像.InfoGAN[22]学习了一种更具解释性的隐特征来表示图像.Arjovsky等人[23]提出了一种更稳定的对抗网络算法框架Wasserstein GAN.
视频生成在计算机视觉领域并不是一个全新的问题.由于计算、数据和建模工具的限制,早期的视频生成工作侧重于生成动态纹理模式[1-3].近年来,随着GPU(graphics processing unit)、网络视频和深度神经网络的出现,越来越多的基于深度学习的视频生成方法被提出.但要将对抗式图片生成模型扩展到视频,需要对空间和时间的复杂变化进行描述,这使得问题具有更多的挑战.最早基于GAN的视频生成模型是Vondrick等人[15]提出的,该算法采用时空3D反卷积分别生成前景与背景.最近,基于GAN的3D反卷积[13]被进一步分解为1D反卷积层和2D反卷积层来生成视频.同时大量基于条件式生成对抗网络的视频生成方法被提出.Li等人[14]提出了用自然语言编码来指导视频生成.Marwah等人[24]采用了循环的VAE(variational autoencoder)和分层的注意机制来通过文本生成图像序列.Pumarola等人[17]以人脸AUs值和图片作为输入,通过无监督的方式训练,并借助连续变化的AUs值生成动态的表情视频.Pan等人[18]提出基于语义图的视频预测,通过语义图实现多样化的图片生成,同时使用VAE对视频帧中的运动信息进行编码,最终生成真实的街景视频.
根据上述分析,本文的工作是提出了以图片和文本作为输入条件的对抗式视频生成模型.与已有的基于条件对抗网络的视频生成方法相比,我们提出的多模态视频生成方法的输入条件更简洁、有效.
2 多模态对抗视频生成方法
图1显示了本文所使用的基于多模态输入的条件视频生成模型的框架图.整个网络结构由5个子网络组成,包括文本特征编码网络RT、运动特征解码网络DV、图片生成网络GI、图片判别网络DI、视频判别网络DV.整个网络基于GAN框架进行训练.

Fig. 1 Framework of antagonistic video generation method based on multimodal input图1 基于多模态输入的对抗式视频生成方法框架
文本特征编码网络DV用于提取输入文本的语义特征,运动特征解码网络Rm根据文本的语义特征进一步生成运动特征来表达目标的运动信息.图片生成网络GI能够根据输入图片和对应的运动特征生成最终的视频帧.在对抗式训练中,视频判别网络DV用于捕捉帧与帧之间的运动信息,从而为图片生成网络GI,文本特征编码网络RT和运动特征解码网络Rm提供反馈.而图片判别网络DI则专注于单帧图片的视觉内容判别,为输出更清晰的图片增加更多的细节约束.每个模块的实现细节将在后面章节进行详细介绍.
2.1 文本特征编码网络RT和运动特征解码网络Rm
长短期记忆网络(long short term memory, LSTM)是一种针对序列型数据而设计的前馈神经网络,主要用来处理序列有关数.其通过在相邻时刻的隐藏层神经元之间加入连接形成循环结构,LSTM可以重复利用之前时刻的历史信息,为了提取文本的语义特征以及图像序列的运动特征,本文采用LSTM搭建了文本特征编码网络RT和运动特征解码网络Rm.
本文提出的模型中,我们通过图片输入得到待生成目标的视觉内容信息.但要想生成视觉上连续变化的视频序列,则还需要为模型引入运动信息.我们使用文本描述来提供运动信息.由于LSTM处理序列数据时的优势,在自然语言处理(natural language processing, NLP)领域常被用于机器翻译[25]和句子语义特征提取.类似地,我们采用LSTM搭建了一个编码-解码结构.为了处理变长的文本输入信息,我们用一个LSTM网络来对文本信息进行编码,将输入的文本信息编码为一个定长向量.同时为了产生前后关联的运动编码信息,使用另一个LSTM对定长向量进行解码,得到一系列的运动编码信息.具体如下.
首先,描述语句分词后被表示为词向量并依次输入文本特征提取网络RT,网络RT是初始状态为h0的LSTM.最终文本描述语句(W1,W2,…,WK)被表示为最后一个单元对应的隐藏层特征(记为M0).其中网络RT的初始状态h0用全0向量表示,Wi为第i个词向量,K为句子长度.文本特征提取网络的输出M0将用于运动特征解码网络Rm的输入.运动特征解码网络Rm由另一个LSTM构成.以文本特征M0作为初始状态,全0向量作为初始输入,以后每一次的输入为前一层的输出,Rm网络将M0解码为生成每帧图像所需的运动特征(M1,M2,…,Mk),Mi表示第i帧的运动特征,k表示生成视频的长度,在实验中我们固定k=16.
2.2 基于图片和运动特征的视频帧生成网络GI
根据Hao等人[16]的研究表明:视频生成任务需要预测的输出帧中大部分像素都可以直接从第1帧复制,这些像素只在位置上发生了一定的偏移.而第1帧中的少数像素区域由于被遮挡和剧烈运动等因素,需要用算法重新生成.基于以上分析,本文的视频生成网络GI采取与Hao等人类似的分治方法,把要预测的视频帧分解为变换图和新生成图.其中变换图由输入图片根据光流特征扭曲变换得到,而新生成图由图片和文本特征直接解码得到,最后通过合并变换图和新生成图得到最终的输出结果.视频生成网络GI的结构如图2所示.具体实现过程将在下面详细展开介绍.
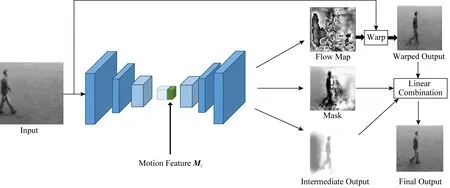
Fig. 2 Video generation network based on pictures and motion features图2 基于图片和运动特征的视频帧生成网络GI
给定图片I0∈RW×H×N和运动特征Mi∈RDM,i=1,2,…,k,视频生成网络GI将输出当前时刻的视频帧O∈RW×H×N.对于图片I0,我们首先用一个具有9个3×3卷积层和3个池化层结构的卷积网络得到(W8)×(H8)尺度的视觉特征.Mi是一个DM维向量,其在输入后将被扩展为Mi∈Ri=1,2,…,k,每个大小为(W8)×(H8)的特征通道上的值都相同,以适应图片的卷积特征的尺度.W和H分别表示图片的宽和高,N为输入图片的通道数.最终扩展后的运动特征将与图片卷积特征按通道进行合并.
基于合并后的图片视觉特征和运动特征,我们首先用一个具有9个3×3卷积层和3个反卷积层结构的卷积网络进行上采样.最后通过3个不同的卷积层生成3个子图,包括稠密光流图D、掩模图M和新生成图Oh.其中稠密光流图D用于描述原始输入图片中每个像素的位移情况,掩模图M用于描述输入图片中哪些区域因为遮挡或者目标快速移动需要新生成像素,新生成图Oh则表示新生成的图片像素信息.
在得到稠密光流图D之后,我们采用一个可微分的扭曲变换将输入图片I0做仿射变换得到变换图Of.具体来说,变换图Of的(x,y)位置的像素值是从原始图片I0的(x0,y0)=(x+Δx,y+Δy)位置变换得来,其中Dx,y=(Δx,Δy).由于Dx,y生成结果是实数,因此采用双线性插值来计算变换图Of中的每个像素值:

(1)
其中,(i,j)是(x0,y0)的四邻域.
最终输出图片可以通过合并变换图Of和新生成图Oh来得到:

(2)
2.3 视频判别器DV和图片判别器DI
传统的GAN网络由2个网络组成:生成网络和判别网络.生成网络的目的是生成尽可能真实的图像,而判别网络的目的是尽可能区分真实图像和模型生成图像.这2个网络在一个最大最小的博弈游戏中不断优化,共同提升.在实际应用中,生成网络和判别网络都被实际化为卷积神经网络.其目标函数为
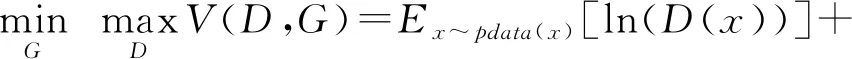
(3)
在本文模型中我们在生成图像的同时还要保证视频序列之间的动态连贯性.因此我们的网络框架包含了2个判别器:视频判别器DV和图片判别器DI.这2个判别器与生成网络协同训练,使得模型能够提供更为高质量的生成结果.同时我们采用改进的WGAN[23]来稳定模型的训练.本文模型的优化目标可以表示为

(4)
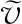
图片判别网络DI采用常规的包含4个3×3卷积层(每层都包含一个池化操作)和1个全连接层的2D卷积网络来实现.训练时,当输入真实图片时使其输出1,当输入由网络生成的图片时使其输出0.而视频判别网络DV则采用包含4个3×3卷积层(每层都包含一个池化操作)和1个全连接层的3D卷积网络来实现.这是因为DV的输入是连续的k帧图片,而3D卷积能够提取其中的时域信息.同样,当输入真实视频时使其输出1,当输入由模型生成的视频时使其输出0.视频判别网络可以捕捉帧与帧之间的动态变化信息,为文本特征编码网络RT和运动特征解码网络Rm提供反馈.
我们将总损失函数定义为
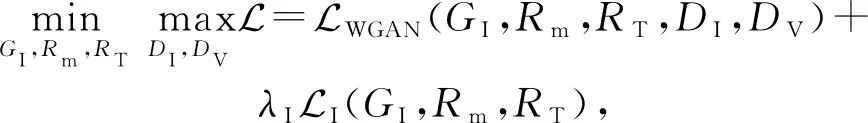
(5)
其中:
Ii为真实的第i帧图片,该项使得生成图片与真实图片更接近,加快模型收敛速度.
2.4 训练方式
与传统的GAN网络框架相同,我们先训练图片判别网络DI、视频判别网络DV,再对抗式地训练文本特征编码网络RT、运动特征解码网络Rm、图片生成网络GI.我们使用Adam优化器进行训练,batch size为16,学习率为0.000 5,β1=0.9,β2=0.99.
3 验证与实验结果
本文所用数据集示例如图3所示:

Fig. 3 Dataset examples图3 数据集示例
3.1 实验使用数据集介绍
SBMG(single-digit bouncing MNIST gifs)数据集为了验证模型的有效性,我们采用了和Mittal等人[26]一样的方法合成动态的手写数字视频样本.SBMG是包含单个数字运动的视频,每个视频样本是由手写数字数据集MNIST[27]中随机采样的图像生成.对于给定大小为64×64的数字图像,根据指定运动描述语句(例如数字7上下移动)移动手写数字对应的白色像素点来模拟生成数字的运动视频.我们生成了60 000个视频样本,每个视频样本都对应着一个描述语句.图3(a)显示了由数字7构造生成的视频以及对应的描述语句.实验中,我们随机选取50 000个视频用于训练,10 000个用于测试.
TBMG(two-digit bouncing MNIST gifs)数据集也是由MNIST数据集中的数字图片生成.区别在于TBMG是包含2个数字同时运动的视频.采用MNIST数据集中的2张图片,按照描述语句移动2张图片的白色像素区域并叠加得到视频样本.TBMG数据集包含30 000个视频样本.图3(b)显示了由数字4和8构造生成的视频以及对应的描述语句.实验中,我们随机选取25 000个视频用于训练,5 000个用于测试.
KTH(kungliga tekniska högskolan human actions)数据集为了在更真实的数据集上评估本文模型的性能,使用了KTH数据集[28].这个数据集包含超过2 000个视频序列,是通过拍摄25个人执行6种不同的动作得到.我们选取人物步行的视频序列来进行实验.通过把人物步行的视频进行切分和人工标记,我们得到了200个包含“从右向左走”和“从左向右走”2种行为的视频.每个视频有16帧,视频帧大小为64×64.图3(c)显示了人物“从左向右走”的视频和其对应的描述语句.实验中,我们随机选取175个视频用于训练,25个用于测试.
3.2 与现有对比模型评估
为了评估我们的模型,我们与现有的模型Cap2vid[24]和Sync-DRAW[26]进行了比较.Cap2vid通过学习文本与视频帧之间的长期和短期依赖关系,通过LSTM建模以增量的方式生成视频.Sync-DRAW使用一个循环的变分自编码器(R-VAE)和一个分层的注意机制来创建一个随时间逐渐变化的视频帧.

Fig. 4 Comparison of effects of different models on SBMG图4 不同模型在SBMG上的效果对比
图4显示了不同方法在SBMG数据集上的数字视频生成结果.
由图4可以看到Cap2vid生成的视频中数字外观上前后有一定差异.而Sync-DRAW和本文的方法基本保持了原有的内容.
图5展示了不同方法在TBMG数据集上的数字视频生成结果.

Fig. 5 Comparison of the effects of different models on TBMG datasets图5 不同模型在TBMG数据集上的效果对比
由图5可以看到,Cap2vid仅通过文本生成视频,生成结果虽然能保持数字的运动,但是数字在前后帧的变化过大.而我们的方法生成的视频具有更好的清晰度和连贯性.Sync-DRAW方法生成的结果同样不够清晰,而我们通过对输入图片进行变换得到视频帧,能够为生成任务提供更多的细节,同时保证了视频内容在前后帧的连贯性.
图6显示了不同方法在KTH数据集上的结果对比.

Fig. 6 Qualitative comparison of models on KTH图6 模型在KTH上的定性对比
由图6可以看到Cap2vid生成的人物姿态过于单一,未能模拟人物行走的完整动作,而Sync-DRAW的生成结果同样不够清晰.我们的方法生成的视频结果在人物的清晰度以及动作的完整性上都有更好的表现.
由于Cap2vid与Sync-DRAW为无监督方法,无法计算定量指标,我们基于模型生成的结果进行了定性比较,同时我们将本文提出的方法与Hao等人[16]提出的方法进行了定量比较.从表1来看,PSNR,SSIM(2个指标值越大越好)都有所提升,其中BMG为SBMG和TBMG的合并.

Table 1 Model Contrast Analysis表1 模型性能量化分析
3.3 模型变体的定性与定量评估
为了验证本文模型各个组件的有效性,我们设置了模型变体进行对比实验:图7(a)基于文本输入(将图片输入置0)的视频生成方法;图7(b)基于图片和文本特征直接解码生成视频帧,不采用变换图与新生成图合并的方式;图7(c)本文提出的完整生成模型.
如图7所示,通过3个方法的实验对比我们可以看到,仅输入文本的模型图7(a)能生成一部分运动信息,但由于缺乏目标的视觉信息,生成视频过于模糊.模型图7(b)虽然能够生成可辨识的视频结果,但由于生成结果是直接通过解码图片和文本特征得到,因此细节信息不如完整模型图7(c)通过合并变换图和新生成图得到的结果.

Fig. 7 Comparison of model variants on KTH datasets图7 模型变体在KTH数据集上的结果对比
下面我们通过计算预测视频帧和真实视频帧之间的PSNR和SSIM[29]指标进一步评估不同模型性能.如表2所示,通过比较SSIM和PSNR,可以看到完整模型图7(c)在BMG数据集和KTH数据集上的结果都优于模型变体图7(a)和图7(b)的结果.图6和表2中的实验对比都表明我们提出的多模态输入更有益于得到鲁棒可控的视频结果.此外,通过把视频生成结果分解为由输入图片变换得到的内容与新生成内容,可以得到更清晰、连贯的视频序列.

Table 2 Quantitative Analysis of Model Variation and Complete Model
图8显示了我们模型更多的生成结果.由图8可以看出我们的模型在清晰度以及动作的连贯性上都有不错的表现.
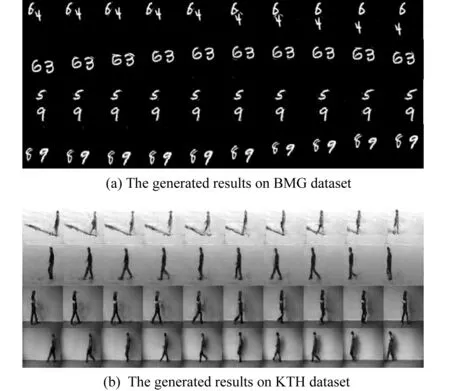
Fig. 8 Model generation results图8 模型生成结果
4 总结与展望
基于生成对抗网络的视频生成算法近年来得到了研究人员的广泛关注.本文提出一种新的基于多模态输入的条件式视频生成模型.一方面基于图片信息输入为生成视频提供更多细节,并基于仿射变换来预测视频帧;另一方面使用文本特征编码网络和运动特征解码网络得到运动信息,进而辅助生成网络输出连贯的视频序列.在SBMG,TBMG,KTH数据集上的实验结果表明,我们的模型在运动连贯性和内容前后一致性上都优于现有的模型.我们的方法使得生成模型更加可控、生成结果更加鲁棒.但本文提出的视频生成算法仍然有很大的改进空间,在未来我们将继续探索更有效的模型,以适应更为复杂环境下的视频生成需求.
