一种面向主干网的器件级动态功率感知节能机制
2020-07-18张金宏王兴伟
张金宏 王兴伟 易 波 黄 敏
1(东北大学计算机科学与工程学院 沈阳 110169)2(东北大学信息科学与工程学院 沈阳 110819)
近些年,随着互联网用户数不断激增,互联网规模持续壮大.思科在其年度互联网报告白皮书中指出:预计全球互联网用户数和设备数将分别从2018年的39亿人和184亿台激增到2023年的53亿人和293亿台[1],由此引发互联网能耗急剧攀升.预计到2030年信息与通信技术(information and comm-unication technologies, ICT)行业耗电量将高达82 650亿kW·h,其中,互联网耗电量高达66 900亿kW·h,约占80.94%,主干网高达26 410亿kW·h,约占31.95%[2].全球电子可持续发展倡议组织(Global e-Sustainability Initiative, GeSI)在SMART 2020,SMARTer2020,SMARTer2030一系列报告中指出,ICT行业的二氧化碳排放当量将以每年6%的速度递增,2020年将达到12.7×108t,约占全球总排放量的2.3%[3-5],预计到2030年此比重将增至23%[6].在波士顿咨询公司(Boston Consulting Group, BCG) 2017年11月发行的关于互联网对气候变化影响的报告中指出互联网每年释放大约10×108t温室气体(其中主干网约占13),约占全球二氧化碳排放量的2%[7].面对如此严峻的状况,针对互联网尤其是主干网的节能变得刻不容缓.
尽管在终端用户设备和“最后一公里”相关技术与产品中已经采用了一些高能效的方法,但是主干网仍然处于高耗能低能效的状态[8].这主要源于目前主干网的设计遵循“过供给原则”,即无论当前网络中流量大小均提供恒定的冗余网络资源以增加网络可靠性和容纳网络峰值流量需求[9-10].然而,实际上网络中的流量大小是动态变化的,并且在峰值和非峰值情况下流量差距很大[11].主干网的最大平均链路利用率低于30%,在非峰值流量期间甚至低于5%[12].在非峰值期间,由于现有网络设备不具备功率感知能力,其功耗无法随着资源利用率的变化而进行相应的调节,因此网络资源未得到充分利用,其峰值功耗造成了巨大的能量浪费,导致了严重的低功效[13-15].面对此种情况,需要设计一种功率感知机制以实现网元的功耗随其流量负载变化而自适应调节,即网元功耗能够紧随入流量大小而变化,网络只维持能够为所有入流量提供足够处理性能的必需数目的网元部件而休眠其余部件,这样能够消除不必要的功耗.该机制的实现需要基于对网元部件功耗状态的控制,但是如果我们仅仅对其进行粗粒度的功耗控制,则无法实现较为满意的功率感知效果.因此,我们提出了一种基于网元细粒度控制的功率感知路由机制,将网元的构成部件做进一步的功能拆分,提取出最小的可控器件单元—线卡端口,同粗粒度的路由器底架级控制和线卡级控制相比,基于线卡端口级的控制使得网元功耗能够更加精细地随着网络中流量负载的变化而进行相应的状态调整,进而实现网络资源更加充分的利用.此外,我们综合考虑了2种网元功耗调整策略,即基于动态功率管理(dynamic power management, DPM)技术的低功率闲置(low power idle, LPI)策略和基于动态电压频率调节(dynamic voltage and frequency scaling, DVFS)技术的自适应链路速率(adaptive link rate, ALR)策略,当网元满足一定的条件和阈值时可以采用这2种策略进行功耗状态转换,从而获得最大的节能收益.
作为功率感知的基础,流量负载情况的获取至关重要.由于主干网在一些时间段具有接近峰值和变化迅速的流量负载,因此我们需要动态获知主干网中流量的变化情况并基于此实现网络中各个网元对其相应部件功耗的动态控制.一般说来,基于不同的动态流量获取方法所做出的管理控制决策可以分为反应式决策和前瞻式决策[16-17].反应式决策需要监测单元实时测量网络上的流量信息,并将监测结果发送给决策单元供其对相应部件进行管理控制,然而此过程所花费的时间对性能影响很大,因此通常对该策略的处理反应时间有较为苛刻的要求,这样才能降低因流量信息实时获取处理而导致的决策滞后性对网络管理控制产生的负面影响.反应式决策的优势在于对当前即时流量进行决策,因此决策准确度一般有保障.前瞻式决策依据预测流量进行决策,因此能够避免反应式决策固有的决策滞后问题,从而能够更加及时地对网络进行管理控制,但其准确性严重依赖于流量负载预测的准确性.鉴于主干网基础设施和流量自身的特点以及本文功率感知控制的场景需求,本文采用前瞻式决策对主干网中的流量信息进行及时预测.
迄今为止,对于网络流量需求的预测方法有许多研究,其中一些预测方法,如基于神经网络或者小波技术等的重量级预测方法,有着较高的计算复杂度和时间开销,通常具有秒级甚至更长的预测时间[18-19].但是,由于对主干网流量突变期间部件级的功率状态动态控制需要更加迅速的流量预测方法来满足器件级的功率状态动态控制,因此本文的预测方法使用滑动平均和滑动标准差模型[20],这样可以实现对主干网中流量波动情况的快速预测,而且从本文开展的实验中可以看到,通过进一步调整预测参数能够提高这种方法的预测准确度,从而提高了决策单元对网元器件的控制精度.此外,本文还使用并行化的预测计数器并扩展入流量的计数窗口,这样可以增加流量预测中使用的样本数目,从而使预测模块对流量负载预测的准确性和稳定性均得到改善.
一般说来,无论我们使用什么样的方法进行流量预测都不可能完全消除所有的预测误差,因为实际流量大小可能超过或低于预测流量,而这将引发入流量速率和器件处理速率之间的差异,进而可能会导致数据分组丢失.为了尽可能避免数据分组丢失,我们可以使用缓冲区.尽管缓冲区的使用能够在一定程度上减少数据分组丢失,但是缓冲区过大将导致处理延迟显著增长,使路由器的性能严重下降.鉴于此,本文工作在控制分组丢失的同时,尽可能减少数据分组的处理延迟,在决策模块中考虑缓冲区的使用状况以减少缓冲区中因数据分组累积而引发的处理延迟.
此外,基于DiffServ模型,本文在考虑各节点节能收益的同时,还考虑其对不同应用的服务质量(quality of service, QoS)支持,尽可能在获得最大节能收益的同时,提供必要的QoS支持.由于目前的典型主干网核心路由器间采用捆绑链路进行互连[21],因此本文中节点间的互连链路均为捆绑链路.
综上所述,本文的主要贡献包括6个方面:
1) 面向主干网,提出了基于捆绑链路的动态功率感知路由器模型,且在最大化各节点节能的同时兼顾应用QoS需求,在节点调度引擎中提出了层次调度算法,使得不同类型分组的QoS在节点处得以保证.
2) 与大多数研究工作中假设静态流量需求的做法不同,本文提出的动态功率感知节能机制能够使得网元功耗自适应于动态流量负载.
3) 不同于基于粗粒度的路由器底架级动态功率控制和线卡级动态功率控制,本文提出了基于线卡端口级的更加细粒度的动态功率控制方案,对不同的流量变化情况给出了相应的定量求解方法,使得网元的功耗能够更加精细地随着网络中流量负载的变化而进行相应的状态调整.
4) 综合考虑基于DPM技术的LPI策略和基于DVFS技术的ALR策略,使得这2种功耗调整策略互为补充.
5) 针对主干网基础设施和流量自身变化的特点,为了避免信息获取的滞后性以实现及时的控制管理决策,本文采用滑动平均和滑动标准差模型对流量进行快速准确的预测,并且在预测时隙序列的选取上考虑了同期预测和环期预测,并比较了基于两者的流量负载预测准确性差异,进而针对流量预测过估计误差和流量预测低估计误差对节点功耗和节点性能的影响进行了全面的评价.
6) 在不同应用场景下,探索本文机制在功效与最差延迟之间的权衡以及在功效与缓冲区占用率之间的权衡.
1 相关工作
目前,针对主干网器件级节能的研究工作,按控制策略可以分为ALR,LPI和混合策略等;按控制粒度可以分为粗粒度和细粒度;按实现目标可以分为在性能可接受的前提下仅以最大化节能为目标的约束节能和在节能与性能之间寻求最佳平衡点的权衡节能;按演进范畴可以分为完全打破且不依赖于原有的网络架构和网络协议等而进行全新设计的革新式以及在原有的网络架构和网络协议等的基础上进行扩充和改进的增补式.尽管革新式通常可以获取更为显著的节能效果,但其实现成本巨大;而增补式通常实现的节能效果较前者有限,但代价也较前者小很多.
ALR[22]根据链路节点端口的负载情况,自适应动态调节链路节点端口中数据传输处理速率,使链路节点端口能够在低负载时减小功耗,实现节能.它使不同的链路节点端口工作在不同的服务速率和相应的功耗等级上,在链路节点端口处于低利用率时降低链路节点端口的传输处理速率,能够在保证有限的性能影响下有效地降低功耗.网络中的任一链路节点端口可以根据链路传输负载情况节点端口处理负载情况,使用基于阈值的方法选择处于某一工作状态的传输处理速率机制,当链路端口利用率超过或低于某一阈值时,相应地调整传输处理速率.
LPI[23-25]通过在低链路利用率期间关闭链路任一端相连的网元或网元部件实现网络设备功率的节省,在需要正常传输数据时恢复对已关闭部分的正常供电,以此节约网络运营成本和实现网络通信的高效节能.
文献[18,26-30]的研究工作均着眼于器件级节能.文献[18]提出了一种时钟频率调节路由器架构,允许其内部模块依据流量负载采用不同的时钟频率运行.它给出了在不同网络环境下的4种频率切换策略:休眠唤醒切换策略、上边界切换策略、双边界切换策略和组合切换策略,以减少路由器功耗从而实现网络节能,但是通常这样频繁的调节会导致功率控制复杂化,而且产生的控制延迟不可忽略.文献[26]针对路由器线卡,提出了一种时钟频率自适应调节策略以最小化主干网能耗,该策略依据路由器线卡实际承载的流量需求,自适应调节路由器线卡时钟频率,这样,路由器线卡不需要总保持在全速运行状态,从而实现节能.在假设已知不同时隙的不同节点对之间的预测流量需求矩阵的前提下,它给出了一个混合整数线性规划模型,在不同时隙为每个路由器线卡选择最优时钟频率,从而使所有路由器线卡的总能耗最小.文献[27]提出了一种广义的ALR策略.它将网元的休眠视为服务速率为0的特殊情形.基于真实的分组轨迹,它分析了使用该策略的路由器对其邻居路由器产生的影响.结果表明:当一个路由器采用该策略时,其下游路由器可获得高达30%的节能.文献[28]提出了一种被称为“GreenRouter”的新型路由器架构,将一个线卡分成2个部分:网络接口卡和分组处理卡,且在这2部分之间通过一个2级交换结构相连.在该架构中,从所有网络接口卡进入的流量能够共享所有分组处理卡,而且这些流量可以按需聚集到一部分分组处理卡上,这样其余的分组处理卡可以被关闭以实现节能.文献[29]提出了一种将能效以太网(energy efficient Ethernet, EEE)协议和eBond(energy-aware bonding)协议相结合的混合协议“eeeBond”,在每个路由器的网络接口内部执行EEE协议来休眠与唤醒网络接口,在不同网络接口间执行eBond协议进行网络接口切换,从而使路由器能耗自适应动态带宽需求.它给出了一个统一的协议性能分析模型,推导出了用于设置协议最优参数的闭型表达式.结果表明,通过使用eeeBond协议和设置最优参数,网络可以实现最大节能.文献[30]基于NetFPGA平台,研究网络设备功率的刻画方法及其调节机制.它给出了一个量化的NetFPGA交换机路由器部件能耗的测量框架,提出了一个功率调节算法,根据实际流量负载调节FPGA(field programmable gate array)内核和以太网接口的运行时钟频率,但是它仅仅是基于硬件的节能.文献[26-27]是基于路由器线卡级的粗粒度控制,而文献[18,28-30]是基于路由器线卡端口级的细粒度控制,它们均未考虑QoS支持,大多采用单一节能策略,其中文献[28-29]基于LPI策略,文献[18,26,30]基于ALR策略,少数(如文献[27])考虑了LPI和ALR混合策略.
相比以上研究工作,本文提出的机制是面向主干网的增补式细粒度短期动态功率感知的约束节能,它在实现各节点功耗最小化的同时,兼顾对不同应用的QoS支持和性能保证,同时综合运用多种节能策略.
2 问题描述
2.1 网络模型
本文将主干网建模为连通图G(V,E),其中连通图顶点集合V={v1,v2,…,vn}表示所有网络节点的集合,连通图边集合E={e1,e2,…,em}表示所有网络链路的集合.
2.2 节点模型
本文提出的节点结构如图1所示,包括主控引擎、背板、底架、交换结构、缓冲区、调度引擎、线卡、转发引擎、复制引擎和端口等构件以及负载预测、缓冲区观测、决策、休眠唤醒控制和速率调节等功能模块.
主控引擎是路由器的控制中心,用于运行路由协议、实现配置管理和路由表查找等功能.背板由数据总线和交换结构组成,是路由器内部数据交换通道.底架用于承载线卡和交换结构,为线卡提供连接槽位.交换结构用于在路由器内部连接线卡的输入端口和输出端口.线卡用于实现分组处理、队列调度和流量管理等功能.转发引擎用于完成分组输入、存储与转发等功能.复制引擎用于组播所需的分组复制.端口用于连接路由器和外部线路,并在两者之间进行数据传输.缓冲区调节数据入口速率和数据出口速率之间的差异,部署缓冲区能够应对流量预测错误的发生.使用较大的缓冲区能够容忍更大的预测错误从而避免包丢失,但是包转发时延将变大.因此,缓冲区尺寸应该根据延迟容忍来决定.缓冲区观测模块对缓冲区的当前使用情况进行周期性观测并将此观测结果发送给决策模块.负载预测模块使用负载的历史统计信息和当前的负载情况来估计未来负载.在负载预测模块中,负载计数器统计入口负载的字节数,预测计算器根据负载计数器统计出的字节数计算预测值.决策模块根据由负载预测模块计算出的预测结果和由缓冲区观测模块获取到的缓冲区使用量综合决策,确定需要调节速率的端口数和或需要唤醒休眠的端口数(负载需求增加时,优先使用速率调节策略,如果将所有活动端口的速率都调至最大后仍无法满足负载需求时,则使用休眠控制策略唤醒必要数量的端口;否则,反之.)之后,决策模块将端口状态转换结果,即需要调整速率的端口数和需要休眠唤醒的端口数,发送到状态控制模块,即速率调节子模块和休眠唤醒子模块.
本文把当前节点中所有连接相同下一跳节点的不同端口分到1组,这样形成的1组端口称之为端口组.不同的下一跳节点对应不同的端口组,这样形成的转发表称之为端口组转发表,如表1所示:

Table 1 Forwarding Table Based on Port Groups表1 端口组转发表
休眠唤醒控制模块基于决策模块的端口数量调整信令和器件状态表中记录的器件已休眠已唤醒时间,依据已唤醒时间越长休眠优先级越高的休眠原则和已休眠时间越长唤醒优先级越高的唤醒原则,具体得出休眠唤醒端口组中的哪些端口,并向调度引擎和相应的端口下发功率状态转换信令.速率调节模块基于决策模块的端口数量调整信令和器件状态表中记录的器件所处不同速率等级的持续时间,依据同一速率等级持续时间越长调节优先级越高的调节原则,具体得出调节端口组中的哪些端口的转发速率,并向调度引擎和相应的端口下发功率状态转换信令.调度引擎在得到来自休眠唤醒控制模块和速率调节模块的相关信令后,向相应端口并行转发数据分组.相应的端口根据接收到的来自休眠唤醒控制模块和速率调节模块的相关信令进行相应的功率状态转换操作.节点内部各构件和功能模块间的逻辑关系如图2所示:
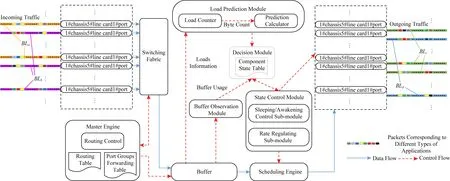
Fig. 2 Logical relationship among components and function modules inside the node图2 节点内部各构件和功能模块间逻辑关系

Fig. 3 Link structure图3 链路结构
2.3 链路模型
典型情况下,主干网每对节点间由多条物理链路互连,这些链路形成一条逻辑捆绑链路[21].本文采用文献[31]的做法假设节点vi和节点vj之间的捆绑链路BLij由nij条容量相同的物理链路组成,表示为:BLij={li1j1,li2j2,…,linjjnj}.本文抽象每条物理链路的结构如图3所示,包括功率放大器、在线放大器、光再生器和前置放大器等中间设备.其中,功率放大器用来提高信号发送功率,在线放大器用来延长信号传输距离,光再生器用来对信号进行整形,前置放大器用来改善接收端灵敏度.
定义1.物理链路速率集.假设每条物理链路都遵循ALR策略,则对于不同的链路利用率LU,其自适应链路速率R可以确定:

(1)
其中,θi(i=1,2,…,k-1)表示划分阈值.我们将这些不同速率组成的集合称为物理链路速率集,记为Rlink={R1,R2,…,Rk}.
2.4 功耗模型
定义2.端口休眠唤醒状态集与合并状态集.当端口处于活动状态Sa时,端口正常运行和处理分组;当端口处于浅层休眠状态Ss时,端口不处理分组,但是使用一小部分功耗以维持端口的初始化状态,这样可以实现其从该状态返回到活动状态的快速苏醒;当端口处于深层休眠状态Sd时,端口被完全关闭,其功耗为0.因此,端口的休眠唤醒状态集可以表示为S={Sa,Ss,Sd}.此外,再考虑到与上述物理链路速率集相对应的端口速率集R=Rlink={R1,R2,…,Rk},我们得到端口的合并状态集S={Sa1,Sa2,…,Sak,Ss,Sd}.
在休眠唤醒3个状态中只有端口处于活动状态才能够处理数据分组,如果处于活动状态的端口不足以满足流量需求,则将引起包丢失,因此处于休眠状态的端口必须在可接受的时间内按需激活;相反,如果因流量需求减少而不再需要过多处于活动状态的端口,则需使多余的端口进入休眠状态以实现节能.图4展示了端口状态之间的转换.

Fig. 4 Transforming among port states图4 端口状态之间的转换
从深层休眠状态到活动状态或浅层休眠状态,需要包括更新内存和存储初始信息等操作.在浅层休眠状态,功率被持续供给以保持内存芯片上所有的数据,只是没有提供时钟信号,因此唤醒器件从浅层休眠状态到活动状态只需要重新提供时钟信号.同深层休眠状态的唤醒时间相比,从浅层休眠状态到活动状态的唤醒时间很短.表2比较了3种状态的属性细节,本文设从活动状态到浅层深层休眠状态和从浅层休眠状态到深层休眠状态的转换时间为0,因为这些转换仅是简单地停止供电.

Table 2 Property Comparison Among Different Port States表2 不同端口状态间的属性比较
定义3.端口之外的器件(如线卡和底架)状态.开启状态,器件正常运行和处理分组;关闭状态,完全关闭器件,其功耗为0.
当且仅当一个线卡上的所有端口都处于深度休眠状态,这个线卡才能关闭;同理,当且仅当一个底架上的所有线卡都关闭了,这个底架才能关闭.
表3是器件状态表,包括所有器件当前的状态以及该状态所持续的时间.
根据节点内部各构件的工作原理、彼此间的交互方式、DPM技术、LPI策略以及功率状态划分定义,抽象出节点功耗模型:

(2)


Table 3 Component State Table表3 器件状态表
基于DVFS技术、上述的ALR策略和先前给出的链路模型,抽象捆绑链路功耗模型:

(3)


(4)

(5)


(6)

基于上述的节点功耗模型和链路功耗模型,全网的功耗模型为
(7)
3 器件级功控机制
器件级功控机制既要考虑流量预测又要考虑缓冲区的占用情况.图5展示了对从当前节点vi流向下一跳节点vj的数据分组,器件级功控机制(component-level power controlling mechanism, CPCM)是如何进行工作的,其中,Ipre为预测时隙,Iobs为缓冲区观测时隙,Ipre=Iobs,Iswi为端口进行功率状态转换的时隙,Dcal为因预测计算而产生的时延,Ddec为因确定需要进行状态转换的端口数目而产生的时延,Dide为因落实需要进行功率转换的具体端口而产生的时延,Dtra为因端口进行功率状态转换而产生的时延.
从图5可以看出,器件级功控机制主要包括6个阶段:
1) 负载预测模块收集流量负载信息(从t=t0到t=t0+Ipre);
经过调查发现,苹果主要贮藏病害是在果园或采收、分级、运输等过程中感染的,在贮藏期间遇到适宜条件就会发病。因此,苹果苦痘病、苹果霉心病、苹果虎皮病等主要贮藏病害的防治须采取综合措施,部分措施要在苹果生长期实施。同时要尽量减少病原体,加强果园管理,防止机械损伤,创造适宜的贮藏环境,确保贮藏质量。
2) 根据第1阶段收集的信息计算出预测的负载大小(从t=t0+Ipre到t=t0+Ipre+Dcal);
3) 通过缓冲区观测模块获取缓冲区使用量(在t=t0+Ipre);
4) 根据从第2,3阶段获取的结果,决策模块决定当前节点未来需要运行所处的功耗状态等级(需要多少器件运行并运行在怎样的速率级别上),并将决策结果发送给休眠唤醒控制模块和速率调节模块(从t=t0+Ipre+Dcal到t=t0+Ipre+Dcal+Ddec);
6) 所有收到信令的端口开始进行相应的状态转换,调度引擎根据信令将数据分组发送给相应端口(从t=t0+Ipre+Dcal+Ddec+Dide到t=t0+Ipre+Dcal+Ddec+Dide+Dtra).
3.1 预测模块

3.1.1 预测时隙序列的选取
选取不同的时隙序列(1,2,…,t-1)进行预测直接影响到预测准确性,本文尝试采用3种方法确定预测所需的时隙序列(1,2,…,t-1)以对时隙t内的负载大小进行较为全面地预测.
定义5.狭义同期预测.将基于先前每周对应工作日中与当前时隙相同时隙负载大小对当前时隙负载大小进行的预测称为狭义同期预测(special same-period prediction, SSP).
定义6.环期预测.将基于先前连续时隙负载大小对当前时隙负载大小进行的预测称为环期预测(continuous-period prediction, CP).
3.1.2 计数器数目的选取
1) 单一计数器

(8)

(9)
其中,α和β分别表示滑动平均和滑动标准差的平滑参数.从式(8)和式(9)可以看出,由于预测计算能够通过移位寄存器来实现高速运算,因此在负载预测模块中的计算时延可以忽略,器件级功控机制的总时延可以表示为D=Dcal+Ddec+Dide+Dtra≈Ddec+Dide+Dtra.由于此预测方法计算量较小,因此适合负载高的核心路由器.

Fig. 6 Comparison among single counter and multiple counters图6 单个计数器和多个计数器的比较
2) 多计数器
以图6为例,如果单一计数器,则在一个计数窗口中的分组数在[0,4]之间变化,而如果4个计数器,则在一个计数窗口中的分组数在[54,114]之间缓慢变化.可见,多计数器窗口的使用增强了的统计稳定性,可以显著改善流量负载预测准确度以及进一步避免频繁的预测决策带来的网元器件功率状态切换震荡.

(10)
(11)
3.2 缓冲区
无论采用何种预测方法都会有误差存在,因此本文在节点内部引入缓冲区来容忍这些误差.然而,这些误差可能会逐渐累积在缓冲区中,从而增加缓冲区溢出风险,因此需要定期观测缓冲区的使用量.
为了避免缓冲区溢出导致数据分组丢失,本文设置缓冲区警戒阈值.当缓冲区使用量超过该阈值时,缓冲区观测模块启用观测值加倍机制,即将双倍的当前缓冲区实际使用量作为观测值向决策模块进行反馈,以便预留足够的端口容量.


(12)

由于使用缓冲区会增加数据分组的等待时延,因此为了既实现节省网络功耗又避免节点处理性能下降,需要在功效和缓冲区占用率之间进行必要的均衡(详见4.3.2节).
3.3 决策模块
决策模块根据负载预测模块的预测结果和由缓冲区观测模块获取到的缓冲区使用量,综合确定如何调整端口状态和数目.


(13)


(14)


(15)

在决策模块中嵌入应对不同流量负载变化趋势的端口数转换算法(详见算法1和算法2),用于得出在任一预测时隙的数量转换矩阵,从而明确各状态端口间的数量变化情况,决策模块据此将端口数量调整信令分别发送给休眠唤醒控制模块和速率调节模块.
为了确保节能收益最大化,同时考虑到唤醒端口需要付出一定的转换代价(使端口复苏至正常工作状态需要一定的时延,并且该时延不可忽略[12])而休眠端口是瞬间完成的(只需对端口停止供电即可),算法1和算法2分别基于不同的流量变化趋势权衡休眠唤醒和速率调整所需付出的代价以及所能获得的节能收益.且在算法1和算法2中,为了书写简洁,我们将端口组Gij中在时隙t-1处于状态的全部端口切换到状态而产生的容量变化量简记为.
对于流量负载增加的情形,首先进行提升速率操作,即反复将当前处于最低速率等级的端口的速率等级进行逐级提升,直至能够满足流量增长需求为止;若所有开启端口的速率等级升至最高后仍不能满足流量增长需求,则进行唤醒端口操作,先唤醒浅层休眠端口,后唤醒深层休眠端口,并且为了尽可能减少唤醒端口数量,将休眠端口直接唤醒到速率等级3(对于流量负载增加剩余量不足速率等级3的部分,按流量负载实际剩余量将休眠端口唤醒至速率等级1或速率等级2).算法1的行①初始化各状态端口间的数量转换矩阵为零矩阵;行②③是对流量负载增幅较小(将端口速率升至2级即可满足)时的调整;行④~是对流量负载增幅较大(所有开启端口速率提升至最高级仍无法满足)时的调整;行~是对流量负载增幅居中(通过提升速率操作可以满足)时的调整;行返回更新后的各状态端口间的数量转换矩阵.
算法1.流量负载增加时各状态端口间的数量转换算法.









then




对于流量负载减少的情形,为了尽可能增加休眠端口数量,首先尽可能多地休眠当前处于低速率等级的端口,之后进一步通过降低速率,尽可能多地减少当前处于高速率等级的端口数量.算法2的行①初始化各状态端口间的数量转换矩阵为零矩阵;行②~是对流量负载降幅较小(将处于速率等级1的端口休眠即可满足)时的调整;行~是对流量负载降幅居中(将处于速率等级1和2的端口休眠即可满足)时的调整;行~是对流量负载降幅较大(将处于速率等级1,2,3的端口休眠才可满足)时的调整;行返回更新后的各状态端口间的数量转换矩阵.
算法2.流量负载减小时各状态端口间的数量转换算法.


then







⑩ else
3.4 状态控制模块
3.4.1 休眠唤醒子模块


休眠唤醒控制模块的工作分为2个阶段:
1) 接收来自决策模块的端口数量调整信令,确定哪几种状态端口需要进行休眠唤醒操作以及每种状态端口需要调整多少个.
3.4.2 速率调节子模块

速率调节模块的工作分为2个阶段:
1) 接收来自决策模块的端口数量调整信令,确定哪几种速率端口需要进行速率调节操作以及每种速率端口需要调整多少个.
2) 对于同种速率端口,依据速率调节规则,具体得出调节端口组中的哪些端口的转发速率,并向调度引擎和相应的端口下发速率转换信令.
3.5 调度引擎
为了避免单一采用优先级排队调度算法(priority queuing, PQ)可能出现的低优先级队列“饿死”现象以及单一采用轮询类算法(如轮询调度(round robin, RR)、加权轮询调度(weighted round robin, WRR)、赤字加权轮询调度(deficit weighted round robin, DWRR))可能出现的无法对延迟、抖动和丢包率等敏感的关键分组提供优先级保证的问题,并考虑面向主干网节点和高速链路的应用场景(面向低速链路的公平排队(fair queuing, FQ)类调度算法不适用该情形),本文在调度引擎设计中提出了一种层次调度算法PDL(PQ-DDWRR-LRMDTF).它的队列由2大类组成:1个PQ队列和m个动态赤字加权轮询调度(dynamic deficit weighted round robin, DDWRR)队列,且PQ队列优先级高于所有DDWRR队列.只有当PQ队列中的所有分组都被调度完成,才会对DDWRR队列中的分组进行调度,并且两者之间是抢占式的,以此确保后面随时到来的紧急分组可以被高优先级调度.
定义11.RMDT(remaining maximum delay time).对于流入节点的某个数据分组packetk,假设其对应的应用类型为typek,这种应用类型所允许的最大延迟为delaymax k,该数据分组转发至当前节点已经花费的延迟时间为delayk,则该数据分组所允许的剩余最大延迟时间RMDT为delaymax k-delayk.
PQ队列和每个DDWRR队列均采用最小RMDT优先(least RMDT first)对分组进行排序,RMDT最小的分组排在所在队列的最前面,调度引擎在每个队列内部总是从队首分组开始执行调度,并且在2种队列的内部均采用非抢占式调度,即正在处理的分组即使没有新进来分组的RMDT小,也不必让位于新来的分组,而是直到当前分组处理完成后才处理新来的分组.这样设计的原因是为了避免同种队列内部的抢占式调度造成的频繁切换而形成的颠簸现象.在某一时刻,如果所有DDWRR队列中存在小于PQ队列队尾RMDT的分组,则按该分组RMDT大小将其移至PQ队列相应位置,以防止被“饿死”.
依据国际电信联盟标准ITU-T Y.1541[33]中关于QoS类别的划分和定义以及ITU-T Y.1221[34]中关于业务合约(traffic contracts)的划分和定义,将分组分为4大类:会话类(如VoIP(voice over Internet protocol),VTC(video teleconferencing),IPTV(Internet protocol television))、流类(如流媒体、VOD(video on demand))、交互类(如Web访问、数据库检索)和背景类(如FTP(file transfer protocol)和Email),不同类型分组需满足的QoS参数指标如表4所示:

Table 4 QoS Constraints Corresponding to Different Types of Packets表4 不同类型分组对应的QoS约束
当出现差分服务代码点(differentiated services code point, DSCP)的每跳行为PHB标识码为加急转发EF、确保转发AF4,AF3或AF2的分组时,则由分类器将其放入PQ队列,优先处理;当新到分组的PHB为AF1或BE时,则由分类器依据其所属的端口组,将其放入对应的DDWRR队列.DDWRR队列之间采用动态赤字加权轮询方式进行调度,每个队列维护一个赤字计数器(deficit counter, DC),DC值表示每次允许调度该队列的字节总数.每次轮询调度时,首先初始化每个非空队列的DC值为本队列上次剩余的DC值和按当前各自权重计算所得的带宽之和,调度引擎依次访问所有非空队列,如果当前队列队首分组大小不大于DC值,则DC值减去此分组的大小,并由调度引擎发送该分组到输出端口,如此不断更新DC值,发送分组到输出端口,直到队首分组大小大于DC值为止,将此时剩余的DC值累加到当前队列下次轮询时使用,如果队列已空,则设置DC值为零,调度引擎移向下一非空队列进行轮询调度.
具体地,分配给第j个DDWRR队列的权重可以计算得出:
(16)

(17)

综上所述,PDL层次调度算法整体工作流程如图7所示,调度引擎通过采用PDL层次调度算法对进入当前节点的所有数据分组进行不同优先级的调度转发,可以确保最紧急的数据分组最先被转发,而非紧急的数据分组也不会被“饿死”,这样使得不同应用类型的分组所需的QoS在节点处得以保证.

Fig. 7 Schematic diagram for PDL scheduling algorithm图7 PDL调度算法示意图
4 仿真实现与综合测评
本文以功耗作为网络图权值在节点间采用SPT(shortest path tree)算法路由每对流量需求,同时对所有网元都采用器件级功控机制.
在机制测评中,对于探索节能与性能之间的权衡以及探索过估计误差和低估计误差、计数窗口数目、环期预测和同期预测方式对预测准确度、节能和性能的影响,由于这些涉及的均是本机制的特有属性,我们与未采用该机制时进行对比;而对于反映机制功效的比例性,我们选取文献[32]中提出的节能机制BDTP(buffer dual-threshold policy)作为对比机制,该机制预设端口缓冲区占用率双阈值,对不同的流量负载动态调整链路传输速率实现节能.此外,为了对比公平起见,我们将LPI策略引入对比机制BDTP,假设此时物理链路同样具有浅层休眠和深层休眠状态,当无分组传输时其可以立即进入浅层休眠状态,超过预设时间转为深层休眠状态.
4.1 仿真环境
所有方案的仿真环境为:
硬件配置CPU为Intel Quad-Core i5-4590@3.30 GHz,RAM为4 GB(DDR3,1 600 MHz);操作系统为Windows 7 professional 64 bits;开发平台为Microsoft Visual Studio 2010;开发语言为C++.
4.2 仿真数据集
仿真用例采用3个典型的主干网CERNET2 (20个节点和22条链路)、GéANT (41个节点和65条链路)和INTERNET2(64个节点和78条链路),拓扑结构如图8所示,特征属性如表5所示.

Fig. 8 Topology use-case diagram图8 拓扑用例

Table 5 Topological Structure Properties表5 拓扑属性
流量数据集.对于CERNET2拓扑,通过教育网Aladdin网管中心信息平台(1)阿拉丁网络信息管理系统,http:219.243.208.6snmpindex.php提取在观测期间网络中所有节点间的进出流量监测数据,得到节点间流量分布及交互情况.对于GéANT拓扑和INTERNET2拓扑,采用文献[35]中提供的流量数据.
环期预测数据集.由于每周对应工作日之间的流量特征具有相似性,本文选取从2016-04-10—2016-04-16期间每天24 h流量轨迹.
同期预测数据集.选取以上3个拓扑从2016-02-28—2016-09-24每天4:00—5:00,14:00—15:00,21:00—22:00这3个时间段的流量轨迹.
需要指出的是,除了在4.4.5节与环期预测进行比较时我们使用同期预测数据集之外,其余各处仿真均使用环期预测数据集.而且除了4.4.4节之外,其余各处仿真均使用8个计数器.
4.3 参数的设置和确定
参考思科12000系列路由器(2)Cisco XR 12000 Series and Cisco 12000 Series Routers.http:www.cisco.comcenusproductsrouters12000-series-routersdatasheet-listing.html设置仿真中使用的功耗和器件配置等参数,如表6所示:

Table 6 Simulation Parameters Setting表6 仿真参数设置
对于预测参数α,β,Ipre,Iobs的取值需要根据不同的流量负载状况进行调整,本文在3个典型的代表低负载(4:00—5:00)、中负载(14:00—15:00)和高负载(21:00—22:00)特征的轨迹下对这些参数值进行调整.在这些轨迹下,分别通过式(8)或式(10)来获取参数α的值,之后分别通过式(9)或式(11)来获取参数β的值.流量增加时,对这2个参数值向下取整,反之向上取整.根据不同主干网中各节点的历史流量日志和器件部署情况设置Ipre值,而Iobs取值的标准是在保证没有分组丢失的条件下选取使当前节点功耗最小化时对应的Ipre值的整数倍.
按上述方法,CERNET2拓扑中的沈阳节点、GéANT拓扑中的丹麦节点以及INTERNET2拓扑中的匹兹堡节点在不同流量等级(traffic level, TL)的负载轨迹下的预测参数设置如表7所示:

Table 7 Prediction Parameters Setting表7 预测参数设置
4.4 机制测评
采用定义12~14中的功效、缓冲区占用率和最差延迟作为参数度量指标评价本文提出的器件级功控机制CPCM.
定义12.功效(power efficiency, PE).将当前所有休眠器件以及低速率器件共同节省的总功耗与所有器件都活动且运行在最大速率时的总功耗的比值称为功效.功效越高越节能.
当预测开启的处于各种速率的器件不能满足实际到来的流量时,即实际入口负载到达速率大于节点处理输出速率,则需要使用缓冲区来容纳未被及时处理的分组,从而增加缓冲区的使用,因此除了需要对功效进行度量之外,还需要对缓冲区的使用情况进行度量.
定义13.缓冲区占用率.将当前已经使用的缓冲区大小占缓冲区总容量的百分比称为缓冲区占用率.缓冲区占用率越小,分组的等待延迟越小.
定义14.最差延迟.将数据分组进出缓冲区的最大时间间隔称为最差延迟,用来度量负载延迟.
此外,本文还讨论采用不同数目的计数窗口以及环期预测和同期预测对预测准确性的影响,以及过估计误差和低估计误差对器件级功控机制的影响.
4.4.1 比例性
比例性可以反映功效随负载变化的紧密程度,以此评价设计机制的节能潜力.最理想的情况是两者完全成正比例线性变化,此时节能收益最大化.
定义15.节点负载率.将节点流量负载与节点容量的百分比称为节点负载率.
定义16.端口开启率(port opening ratio, POR).将节点中开启端口数与总端口数的百分比称为端口开启率.
定义17.比例性.将端口开启率随节点负载率动态变化的线性程度称为比例性.

Fig. 9 Proportionality test图9 比例性测试
从图9可以看出,在CPCM机制下,节点功效和端口开启率都紧随节点负载率的变化而趋近线性比例变化,尤其对于规模较小的拓扑比例性更好.而且,通过观察功效变化情况可以发现,CPCM机制的引入能够节省大量的功耗,甚至当节点负载率高达70%时,仍能维持14%~20%的功效.由此可见,CPCM机制能够依据流量负载变化非常有效地控制功效和端口状态.而在BDTP机制下,节点功效在低负载和高负载时差异很大,近似阶跃式变化;端口开启率始终较高,对节点负载率的变化不敏感,并且拓扑结构越复杂的节点越明显.2种机制的显著差异主要来源于前者对捆绑链路中全部物理链路规划端口的开关和速率的调整,较大限度地保证了所开即所需,而后者捆绑链路各端口之间是相互独立的,没有聚合流量,于是开启了多余的端口或者使用了较大而不必要的高速率,导致功效显著降低.
4.4.2 节能与性能之间的权衡
权衡是既要保证节能效果又要保障一定的运行性能而不得不在两者之间做出的折中考量.本文关注功效与最差延迟之间的权衡以及功效与缓冲区占用率之间的权衡.
图10显示了在不同的缓冲区使用量警戒阈值ζ下的功效与最差延迟权衡分布以及功效与缓冲区占用率权衡分布.可以看出,当设置最差延迟为某个确定值时,能够获得在此限制下的最大功效;反之,当需要实现特定级别的功效时,能够获得此时的最坏延迟.例如,观察区域C1,G1,I1中ζ≥0.8的点,功效达到80%以上,但最差延迟至少30 ms,使用这样的ζ值能够以增大最差延迟为代价换取功效最大化.这种情况适用于在注重节能的环境下进行部署,仅需满足最低的延迟需求即可.又如,在区域C2,G2,I2中的ζ≤0.2的点,此时缓冲区频繁刷新,与区域C1,G1,I1相比,功效降低超过50%,但最差延迟减小可达23,即最差延迟被最大程度地减小,但功效被最小化.这种情况适用于对负载延迟有苛刻约束而对节能不敏感的环境.最后,在区域C3,G3,I3中的ζ∈[0.6,0.7]的点,这样的点是权衡后的“甜蜜点”,既没有太糟糕的最差延迟(比第1种情况少50%),也能获得一定的节能效果(比第1种情况少30%).因此,本文通过选择适当的控制参数 ζ 以满足在某一环境下的部署需求.

Fig. 10 Tradeoff between energy saving and performance图10 节能与性能之间的权衡
从图10还可以看出,如果使用增加功效的参数,则缓冲区占用率将增长,反之功效将减小.这是因为缓冲区中数据分组的累积会导致最差延迟的增长.当选择减少最差延迟的参数,缓冲区占用率也将减少,因此可以通过恰当地使用缓冲区减小最差延迟.
4.4.3 过估计误差和低估计误差的影响
当负载预测模块得到的预测性能偏离实际需要的性能时会产生过估计或低估计.
如果是过估计,则意味着投入了比实际需要更多的器件用于处理入口负载,降低了功效,造成能源的浪费,但对节点的处理性能没有影响.
如果是低估计,则意味着投入了比实际需要更少的器件用于处理入口负载.这会导致数据分组在缓冲区中的不断累积从而导致负载最差延迟的增长,甚至可能导致数据分组累积过多而使缓冲区溢出从而导致分组丢失,严重影响节点的处理性能.
图10中的区域C1,G1,I1中的点可以看作是发生低估计时的状况,尽管获得了功效收益,但是最差延迟的增长恶化了节点的性能.区域C2,G2,I2中的点可以看作是发生过估计的状况,牺牲了功效换取了负载最差延迟的减小.对于运行在主干网中的核心节点来说,与过估计相比,低估计的发生更需要被避免.
4.4.4 计数窗口数目对预测的影响
定义18.端口数平均误差.将当前开启端口数Nactive和实际所需开启端口数Nactual间的平均误差称为端口数平均误差,记为χ,计算为
(18)
χ能够反映过估计低估计的趋势.
定义19.端口数均方根误差.将当前开启端口数Nactive和实际所需开启端口数Nactual之间的均方根误差称为端口数均方根误差,记为δ,计算为
(19)
δ能够反映预测值追踪实际负载的准确程度.其中,npre是预测的总次数.
记处于过估计状态的端口数均方根误差为δover,计算为
(20)
δover值越小,表示过估计的影响越小,可以实现更高的功效控制.
记处于低估计状态的端口数均方根误差为δunder,计算为
(21)
δunder值越小,意味着低估计的影响越小,可以实现更小的负载延迟.其中,nover和nunder分别是过估计和低估计发生次数.
图11展示了节点预测模块采用不同数目的计数器时的预测准确度比较,在3个拓扑中,在高负载情形下δunder均大于δover而占据主导地位,在低负载情形下δover都大于δunder而占据主导地位,在所有情形下平均误差χ都趋于0.上述说明,计数器数目不影响预测趋势.与单个计数器相比,当使用8个计数器时,所有的δover和δunder均大幅降低,这是由于增加计数器数目可以减少流量负载频繁波动对预测准确度的影响.

Fig. 11 Comparison on prediction accuracy among different number of counters图11 不同数目计数器间的预测准确度比较
4.4.5 环期预测和同期预测
记环期预测、广义同期预测和狭义同期预测下的端口数均方根误差分别为δCP,δGSP,δSSP,均通过式(19)计算得到.
图12展示了当选取不同的预测时隙序列时对预测准确度的影响.可以看出,低负载时,采用环期预测的均方根误差明显小于广义同期预测和狭义同期预测;高负载时,大多数情况下环期预测的准确度与广义同期预测较为接近.这是因为环期预测对网络流量低平稳高抖动的日夜规律依赖性更大,呈现低负载预测准确度高而高负载预测准确率低的特征.在所有负载情形下,对于时间跨度敏感的流量负载,如图12(b)所示,狭义同期预测准确度明显下降;而对于时间跨度不敏感的流量负载,如图12(a)所示,狭义同期预测的准确度超过了广义同期预测.这主要是由于在前者情形下,与广义同期预测相比,狭义同期预测的流量负载时间序列抖动偏差变大,导致其预测误差增大;而在后者情形下,狭义同期预测的由不同周相同工作日相同时隙组成的流量时间序列比广义同期预测的由不同工作日相同时隙组成的流量时间序列更好地保留了流量相似性,因而具有更小的抖动,提高了预测准确度.

Fig. 12 Accuracy comparison among CP, GSP and SSP图12 环期预测和同期预测的准确度比较
5 总 结
本文面向主干网提出了一种细粒度器件级功控机制,该机制依据流量负载大小动态调整网元器件功率状态实现了节能,且在节能的同时兼顾用户QoS需求的满足,在提供QoS保证的前提下尽可能最大化节能收益.此外,本文还考虑了在功效和负载最差延迟之间以及在功效和缓冲区占用率之间的权衡问题,同时揭示了预测过估计和预测低估计、环期预测和同期预测以及扩展入口负载计数器的计数窗口对器件级功控机制的影响.仿真结果表明:本文提出的器件级功控机制能够细粒度、动态和比例性地控制各网元功耗.
由于本文提出的机制是增补式的,并不需要“大刀阔斧”式地更换目前现有的基础设施、网络架构和网络协议等而进行各个层面的全新设计,在实际部署中仅需要适当扩充和增添少许网络功能模块以及在现有网络协议基础上作相应修改即可,且机制依据的DPM和DVFS等功率调节技术以及ALR和LPI等节能策略也较为成熟,因此本文提出的机制具有实际可行性和可能性.在实际部署本文提出机制时,网络运营商需要根据不同应用需求场景通过参考我们的实验结果选取适当的缓冲区使用量警戒阈值使得节能与性能之间达到权衡或者侧重于二者之一,同时根据不同的拓扑结构和历史流量分布情况选择合适的预测时隙获取方式和计数器数目,严格避免低估计的发生,也尽量避免过估计的发生.
我们未来的工作将着重于探索端口速率调节方法对基于链路状态的开放最短路径优先路由算法等网络级路由机制的影响以及两者之间的协同交互,通过综合运用器件级和网络级节能机制,使网络获取更大的节能收益.
