孤立森林算法在智能监控中的应用
2020-07-17闻明窦晨
闻明 窦晨
(北京科技大学天津学院 天津 301830)
传统的人工盯盘监控数据的方式效率不仅低下,还对应着巨大的人力成本。而现存的监控数据自动监控需要管理员去挨个配置各个环境数据的合理范围,超出合理范围的会触发告警系统。但管理员对数据的合理波动范围往往并不全都清楚,随着监控设备的陡增,这项工作量也变得非常大,异常检测平台和告警容易被旁置。况且,由于传感器质量问题,现场安装问题的广泛存在,这些监控数据存在着不准确、失真等多种问题,光是设定阈值很难将自动监控平台派上用场,这就需要我们采用机器学习算法、深度学习算法等技术对数据进行清洗、分析和归类。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论[3]。
1 基于自动化算法的监控数据异常检测
数据挖掘类的任务如异常检测和信息检索需要定义度量。最常见的度量是基于距离和密度的,大多数现有的工作都是基于这些度量对工程中的实例进行排序。但是这些方法有一个问题,就是它的计算成本很高,特别是在大数据情形下计算成本很高,随着维度的上升计算要求的性能飙升。
孤立森林(Isolation Forest)是一种新颖的无监督学习算法,用于判断数据集内是否存在异常点,由Fei Tony Liu及周志华等于2008年提出[4]。它使用的度量不依赖于距离和密度计算。它的基本思想是将给定的数据集中的每个对象与其他对象隔离开来。因为异常点具有两个特征,一个是少,另一个是异常。所以他们比正常的数据更容易在数结构中被隔离。因此,异常点的平均路径长度比孤立树集合上的其他正常对象的平均路径长度更短。
孤立森林在工程中的实践经过时间的考验已经被证明是一个良好的算法。但是,我们在开发的过程中发现它有一些缺陷。我们改进的一个缺陷是,当数据集包含多个正常点簇,用原始的孤立森林算法不易将异常数据分离出来。造成这种缺陷的原因是当数据集包含多个正常点簇时,局部的异常点容易被密度相似的正常点簇掩盖,导致它不太容易被孤立森林算法隔离。
2 对算法的改进
考虑了孤立森林算法和它在探测局部异常点方面的缺陷以后,我们提出了以下的新算法,它可以通过计算相对质量克服孤立森林的缺点。
在传统的孤立森林算法中,使用的是基于路径长度的全局排名度量,我们改为使用基于数据点在本地邻域的相对质量的本地排名度量来对数据点进行排名。在树结构中,数据点的相对质量是通过数据点从根节点到叶节点的路径上的两个节点的质量比来计算的。计算相对质量时使用的两个节点取决于任务的具体要求。
在异常检测中,我们采用的新算法只考虑x相对于它的邻域的相对质量。相对质量计算的方式为x所在的直接父节点和它的直接叶节点的质量比。
在每个孤立森林树Ti中,一个数据点x相对于它的邻域的异常分数si(x)可以被这个公式估计:

其中Ti(x)是x所在的树Ti的叶子节点,是的直接节点,m(·)是树节点的质量,是正则化参数,等于用于训练Ti的数据集的大小。
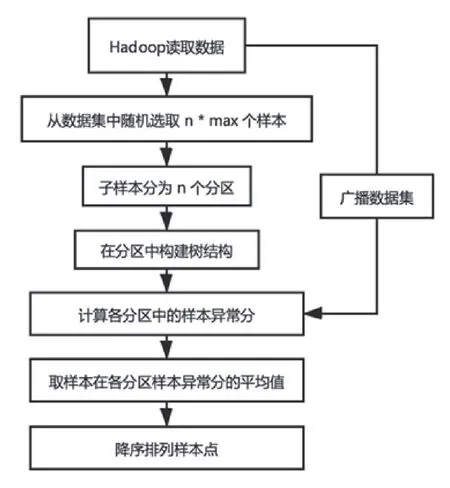
图1 新算法流程图

表1 新旧算法基准测试结果
si(·)的值域为(0,1]。这个分数越高,x越有可能是一个异常点。与原本的孤立森林中的路径长度分数相比,si(x)衡量了一个数据点在局部的异常程度。
最后的异常分数可以对局部异常分数取平均得到
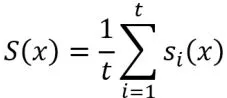
给定数据集的所有数据点的异常分数被计算出来以后可以根据异常分数从高到低排列,这个排名表示了数据点在数据集中的异常分数排名。
3 服务器端的设计与实现
算法智能分析平台的开发过程如下:
(1)搭建Hadoop分布式机器学习平台,从数据库中加载已有的监控数据,对监控数据进行数据预处理,数据存入HBase。
(2)使用Python 编写异常检测算法的实现,对HBase中的数据进行分析。该过程需要对算法具体实现的参数进行调优。分析完成的结果写入数据库。
(3)最后分析结果由监控数据展示平台的前端拉取展示,告警平台的程序定时拉取数据筛选出等级较为严重的日志发送到管理员的邮箱中。
由于Hadoop本身并没有支持我们设计的新算法,所以我们设计了程序使这个算法支持Hadoop。新算法的大致流程如图1。其中n是算法树的数量,max是每棵算法树的采样数量。
Hadoop 分布式计算算法树包括:对数据集随机采样不放回,并行构建算法树和并行计算数据点相对于邻域的异常分数,最后综合异常分数计算异常分数平均值。对数据集进行随机采样且不放回的实现是:将数据集读入内存构建为HBase要求的格式,用指标索引数据集中的样本,加速下一步访问。用Linux的/dev/urandom 取随机数作为numpy 的随机数生成器的种子,取出大小为n*max 的样本集,然后调用numpy API广播随机样本集,最后用孤立森林算法构建算法树。
算法树构建成功后,将样本代入公式计算样本相对于邻域的相对质量。这里在编程上需要对每个样本遍历算法树计算出样本相对于所有算法树的异常分。这里因为可以并行化可以充分发挥Hadoop自动并行化加速的特性,提高算法实现的性能。
4 实验结果
在实验和测试方面我们测试比对了孤立森林算法和新算法在探测异常点任务上的表现。实验中我们统一采用无监督学习的配置。数据集上的标签不会参与模型训练过程。标签仅用于评估模型的运行效果。异常点探测任务的效果评估我们用AUC这个指标衡量。ROC曲线是一个用来说明二进制分类器系统的区分能力的曲线,横坐标为它的区分阈值。AUC 是ROC曲线下面积。最后我们会计算标准差来检查孤立森林和新算法之间的差别是否显著。
我们用了十个基准测量数据集[1]分别用孤立森林算法和我们改进的新算法进行了测试。我们将参数t默认值设置为100,最佳子样本数量设置为在8,16,32,64,128到256之间搜索。新算法的MinPts 参数的默认值设置为5。孤立森林算法的MinPts参数设置为1,这是随机森林算法的默认设定[1]。基准测试的结果见表格1,其中NA是我们的新算法。
以AUC为指标的话,新算法和孤立森林相比效果类似。大部分数据集都不包含局部异常点,因此这两种算法的AUC都是类似的。我们也测试了MinPts=5时的孤立森林算法,并不会提高孤立森林算法的成绩。
从运行时间来看,新算法要显著好于孤立森林算法。这是因为新算法的更小,产生的树比孤立森林要小很多,所以即使参数相同新算法也会比孤立森林快。
