基于神经网络的中超联赛球队实力水平聚类方法研究
2020-07-17兰兆青吴炎兵李京玲
兰兆青,吴炎兵,李京玲
(1.山西农业大学文理学院,山西太谷 030801;2.山西农业大学体育学院,山西太谷 030801;3.太原理工大学水利科学与工程学院,山西太原 030001)
四年一届的世界杯像火球般在2018年夏点燃世界,吸引着无数人为她熬夜,为她疯狂[1]。代表着中国足球最高水平的中国足球协会超级联赛更是吸引了若干国人的关注,多位学者从内容、方法等不同侧面进行了研究[2-9]。本文运用自组织特征映射网络和模糊聚类分析相结合的方法,依据2014年至2017年中超足球联赛16支球队的最终成绩,用聚类法对上海上港和武汉卓尔两支球队做出评价。
1 球队的选取与编码实现
1.1 球队选取
球队的选取分为时间节点的选取和参赛球队的选取两部分。首先,时间节点的选取要注重时效性,时间太长,球队的变动会很大,可能有的球队会在附加赛中退出,也有可能降级至中甲联赛,或者有强大资金的注入,邀请强有力的外援。我们从中超历史上有纪念意义的2014年开始,选取了近4年(2014年、2015年、2016年、2017年)来的中超球队成绩作为本次球队水平聚类的依据。其次,球队的选取要照顾到强队、弱队,也要照顾到地区的差异,同时还要照顾到老牌球队与新兴势力。我们选取16支球队进行聚类,分别为:山东鲁能、上海申花、天津泰达、北京国安、长春亚泰、广州富力、江苏舜天、河南建业、重庆力帆、浙江绿城、辽宁宏运、石家庄永昌、延边富德、河北华夏幸福、贵州人和和上海申鑫。
1.2 编码方法
每一个球队用一个四维向量x=[x1,x2,x3,x4]来表示,向量的第一至第四个分量分别代表该球队在2014至2017年中超联赛上取得的成绩(主要指排名)。
具体的编码方法为:如果进入中超联赛的,用其自身的最终排名(1~16),如果降级为中甲联赛的,在球队中甲联赛最终排名的基础上加16。16支球队最终求得的特征向量,见表1,数字越小表示成绩越好。

表1 球队成绩一览表
2 方法介绍
对于中超足球联赛的参赛球队为几流水平的问题,有许多方法可以得到,但整体上可以分为有监督指导的分类和“无师自通”的分类两大类。对于有监督指导的分类,我们需要提前给定训练样本,即把某几支球队定为一流或者二流,并且以其为标准来评价其他球队。然而这样的球队是很难找到的,即使是顶级球队也有发挥不好的时候,如果将其作为标准,就会产生偏差,并且选取的球队不同,最终的结果也不同[10]。因此,对于这类问题,我们选择无监督学习的聚类方式。本文采用自组织特征映射网络和模糊聚类分析相结合的聚类方法。
2.1 自组织特征映射网络
自组织特征映射网络(SOM,Self-Organizing Feature Map),也叫Kohonen网络,由荷兰学者Teu⁃vo Kohonen于1981年提出,是一个由全连接的神经元阵列组成的无教师、自组织、自学习网络。该网络中的单个神经元对模式分类不起决定性作用,需要多个神经元协同作用完成,并且是根据输入空间中输入向量的分组进行学习和分类,不需要预先知道部分球队的水平和实力,只要给定分类的类别数量N,算法就会自动将所有样本按照相似性的原则进行划分。该法接受一个n维向量作为输入,对应一个包含n个节点的输入层,每个输入的样本都对应一个竞争层节点。输入层节点与竞争层通过权值向量连接(网络结构,见图1)。网络训练的过程就是在空间上对神经元进行有序排列的过程。在更新权值时每个神经元附近一定领域内的神经元也会得到更新,较远的神经元则不更新,而输出神经元之间根据距离的远近决定抑制关系。通过竞争、合作、自适应三个网络训练过程,最终使连接权值的统计分布与输入模式渐趋一致。当训练结束时,对应同一个竞争层节点的输入样本就被列为同一类别。当有新样本输入时,系统以拓扑结构的形式输出分类结果。
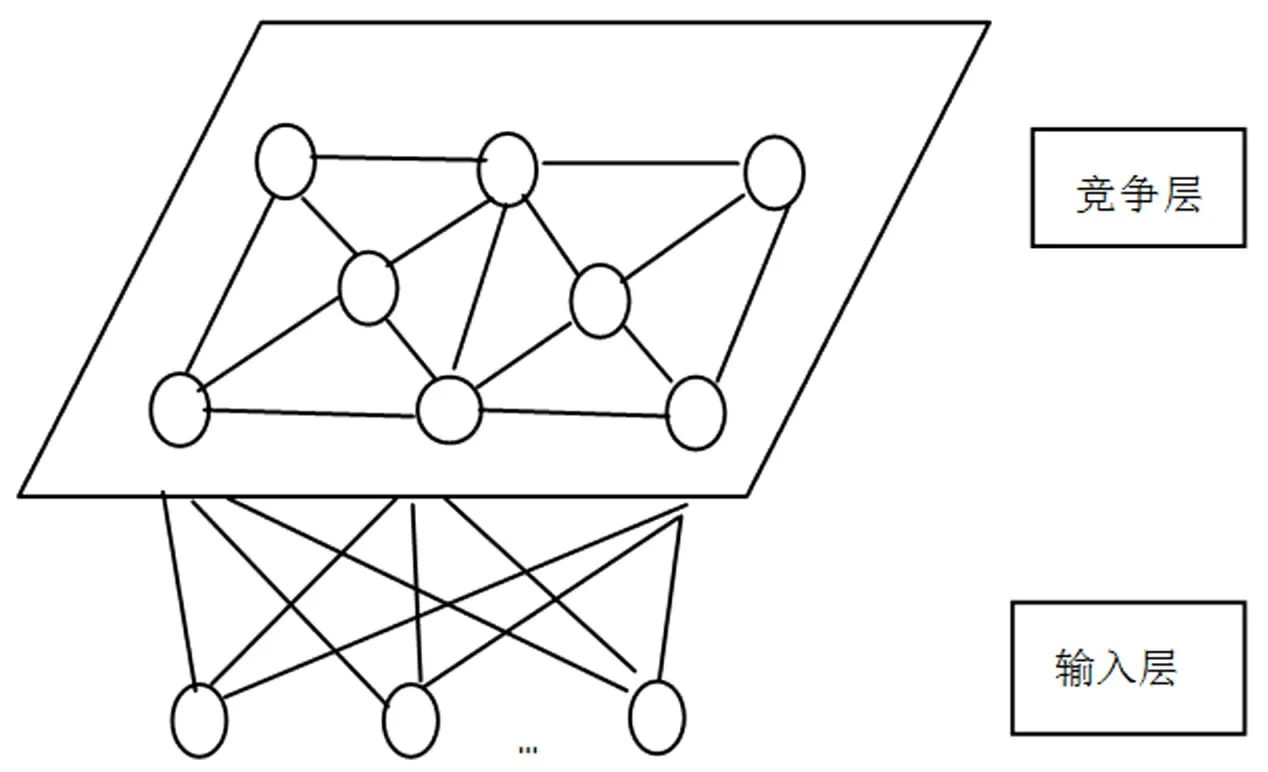
图1 自组织映射网络模型
2.2 模糊聚类
聚类就是将数据集分成多个类或簇,使得各个类之间的数据差别应尽可能大,类内之间的数据差别应尽可能小,即为“最小化类间相似性,最大化类内相似性”原则。模糊聚类分析是利用模糊等价关系来实现的一种聚类方法,而模糊等价关系是指在论域R上满足:①自反性,R⊂I;②对称性,即R′=R;③传递性,R∘R⊂R。
该法实现聚类是用模糊数学把样本之间的模糊关系定量的确定,而客观且准确地进行聚类。主要分为三步:①通过求解样本集中任意两个样本之间的相关系数构造出模糊相似矩阵;②改造相似关系为等价关系;③对求得的模糊等价矩阵求λ截集,实现聚类[11]。
3 足球水平聚类实现
3.1 基于自组织特征映射网络
(1)定义样本:足球水平聚类中涉及到16个球队,而每个球队的成绩用一个四维向量表示,所以足球队水平抽象为16个4维向量聚类的问题。输入向量维数为4,同时竞争层也含有4个节点。
(2)创建网络:考虑到分类过细,有可能把许多球队单独分为一类,而选用二分类则分类有点粗,故设定聚类的类别数为4类。设置竞争层为2×2的六边形结构(见图2)。使用MatLab工具箱函数selforgmap创建网络。

图2 网络拓扑结构图
(3)使用Train函数对输入样本进行训练,并选取和训练数据一样的数据作为测试数据对网络进行测试。测试后的网络连接,见图3。
图3中的六边形代表神经元,菱形中的细线表示神经元之间有直接的连接,菱形内部的颜色均为白色,说明神经元之间的距离不存在差异,都很近(颜色越深说明神经元之间的距离越远)。
由于神经网络具有一定随机性,所以多次运行可能产生结果不太一样。总体来说,聚类比较稳定的球队是:
第一流:山东鲁能、上海申花、北京国安、广州富力;
第二流:辽宁宏运、石家庄永昌;
第三流:延边富德、河北华夏幸福;
第四流:贵州人和、上海申鑫。
其余球队都有浮动的趋势。
3.2 基于模糊聚类分析
主要采用模糊C均值聚类方法的MATLAB函数fcm求解。该方法的调用方式为:[center,U,obj_fcn]=fcm(data,cluster_n)。其中右端data是需要聚类的数据集合,cluster_n为聚类数。左端center指最终的聚类中心矩阵;U为隶属度函数矩阵;obj_fcn是迭代过程中的目标函数值。使用该方法,将评价区域分为有四个聚类中心的集合:(山东鲁能,上海申花,北京国安,广州富力,江苏舜天);(天津泰达,长春亚泰,辽宁宏运,河南建业,石家庄永昌,重庆力帆);(浙江绿城,上海申鑫,贵州人和);(延边富德,河北华夏幸福)。
结合以上两种方法,中超足球水平聚类如下:
第一流:山东鲁能,上海申花,北京国安,江苏舜天,广州富力;
第二流:天津泰达,长春亚泰,辽宁宏运,河南建业,石家庄永昌,重庆力帆,浙江绿城;
第三流:延边富德,河北华夏幸福;
第四流:上海申鑫,贵州人和。
这个聚类结果与中超足球2018年比赛结果基本一致。
4 测试
为了检验本次聚类的精确度和客观性,把已经得到的聚类结果作为分类类别,任意选取的两支我们熟悉的球队作为待判样品(见表2),选用MatLab中的分类函数classify函数进行线性判别分析,判断这两支球队在该标准下属于哪种水平,并与实际水平作比较。
classify分类函数的调用格式为:
class=classify(s,mydata,g)
其中s是测试样本的集合;mydata是原始数据集;g是球队所属类别构成的集合的转置。
输出结果为:Class=1 4
测试结果表明,上海上港划分为第一流、武汉卓尔划分为第四流。而上海上港作为测试球队在2018赛季也是位居积分榜第二,属于一流水平。测试结果与球队的实际水平是一致的,可见结合自组织特征映射网络和模糊聚类分析得出的球队水平聚类结果是客观、准确的。
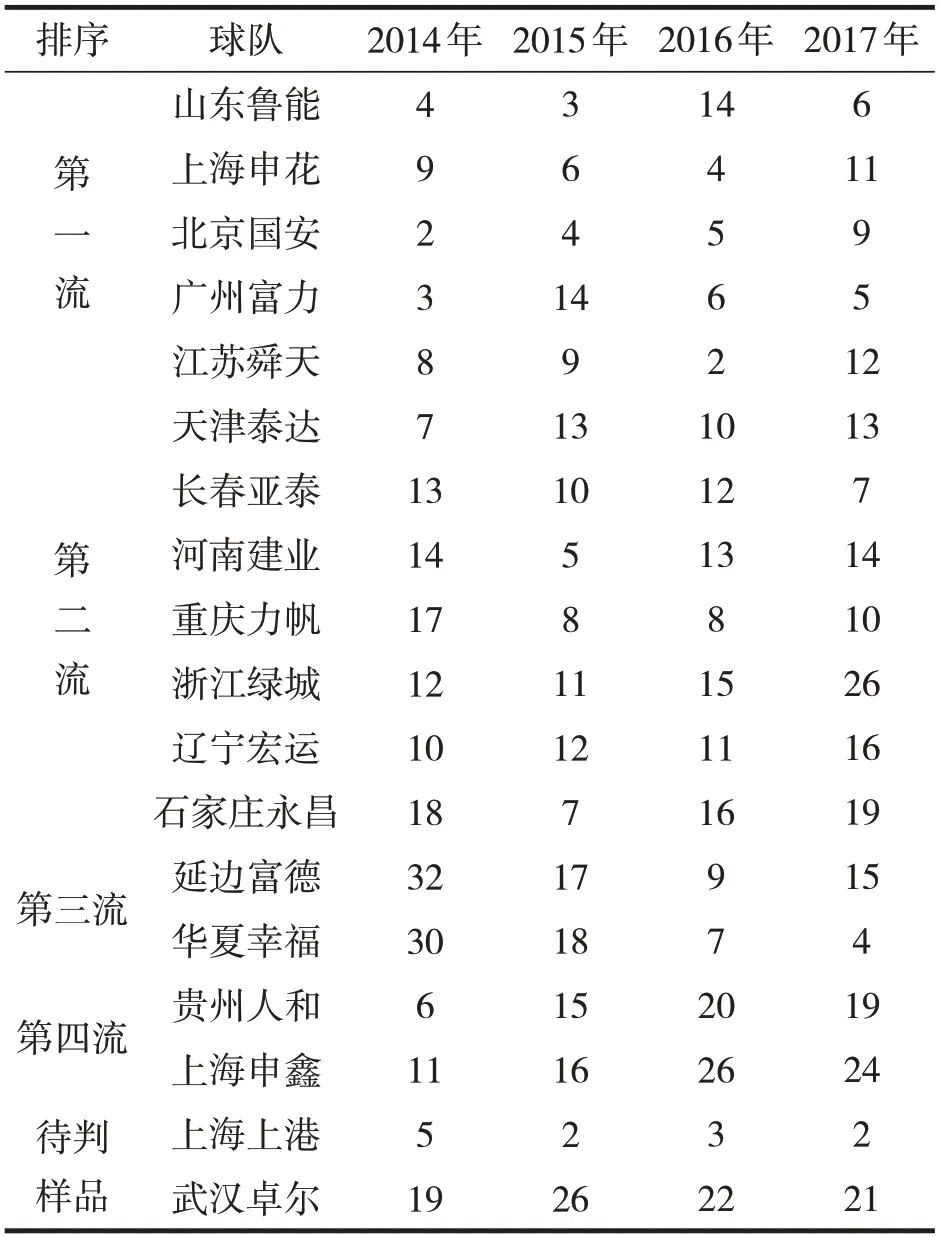
表2 评价标准及待判样品表
5 结论
(1)结合自组织特征映射网络和模糊聚类分析对中超联赛球队整体水平进行聚类,得出的聚类结果与中超足球2018年比赛结果基本一致。说明本文提出的这种聚类方法是合理可行的,得出的结论是客观准确的。
(2)从2018中超联赛贵州人和的参赛成绩来看,虽然被划分为第四流球队,但在本赛季中却比出了积分榜第六的好成绩。可见,排名只是代表历史,只要球队团结努力,一切都可以改变。相信,如果我们在战略战术,运行机制等有益于足球水平提高的相关方面多加关注和投入,对中国的足球多一些耐心,少一些苛责,中国足球总会有扬眉吐气的一天。
