混部负载场景下离线负载资源调度策略研究
2020-07-14苏超梁毅
苏超 梁毅


摘 要:混部负载是当前业界提高数据资源利用率的重要手段,其原理是将在线负载和离线负载共同放置于同一数据中心、共享资源,在保证在线负载服务质量的前提下,将空闲资源分配给离线负载。当前针对混部负载中离线负载的资源调度采用传统的公平或者短作业优先等策略,并未考虑在线负载资源需求波动对离线负载运行的影响。为了达到进一步提升资源利用率和作业吞吐率的目的,提出基于负载完成时间预判的模拟退火资源分配策略。结果表明,该策略比公平策略和短作业优先策略在平均资源利用率上分别提高了7.8%和15.5%,在吞吐率上分别提高了38.2%和29.1%。
关键词:混部负载;资源分配;模拟退火算法
DOI: 10. 11907/rjdk.191243
开放科学(资源服务)标识码(OSID):
中图分类号:TP306
文献标识码:A
文章编号:1672-7800(2020)001-0064-04
0 引言
大数据中心资源利用率低下的问题一直备受关注[1-3]。为了进一步提升其资源利用率,业界提出了}昆部负载技术[4-5],它是指将延迟敏感型的在线负载与关注作业吞吐率[6]的离线负载混合部署于同一数据中心。混部负载的目标是提升原有单负载数据中心的资源利用率,并且优先保障在线负载的SLO以及最小化相应延迟[7-8]。由于在线负载是延迟敏感型的[9-10]刚,且其资源需求量已经可以通过科学的方法(如:机器学习、时间序列分析等)较为准确地加以预测[11-12],因此,如何将数据中心的剩余资源合理分配给既有离线负载尤为重要。
资源调度是保障数据中心负载执行效率及资源利用率的关键技术。目前,针对混部负载的资源调度主要集中于在线负载,通过机器学习、时间序列分析等方法预测在线负载的资源需求,进行准确的资源供给,以保障在线负载的服务质量[13-14]。然而,针对离线批处理负载的资源调度往往采用较为传统的公平或者短作业优先等策略,并未考虑在线负载资源需求波动对离线负载运行的影响[15-16],这导致离线批处理负载在运行过程中产生资源抢占或资源碎片现象,降低了离线负载的运行效率以及数据中心资源的有效利用率[17]。
针对上述问题,本文提出基于完成时间预测的离线负载资源调度策略。该策略首先通过回归树算法对数据中心既有离线负载完成时间进行建模和预判,并在已知在线负载资源需求的情况下,采用模拟退火的多目标组合优化启发式算法对离线负载进行更为合理的资源分配[18-19]。实验表明,该策略比传统的公平策略和短作业优先策略在平均资源利用率上分别提高了7.8%和15.5%,在作业吞吐率上分别提高了38.2%和29.1%。
1 离线负载完成时间预测
为了合理利用数据中心的空闲资源,本文采用CART回归决策树算法对当前数据中心离线负载的完成时间进行预判。
1.1 关键因素选取
为了预测离线负载完成时间,首先分析离线负载相关原理,探究影响负载完成时间的关键因素,然后通过实验加以验证。
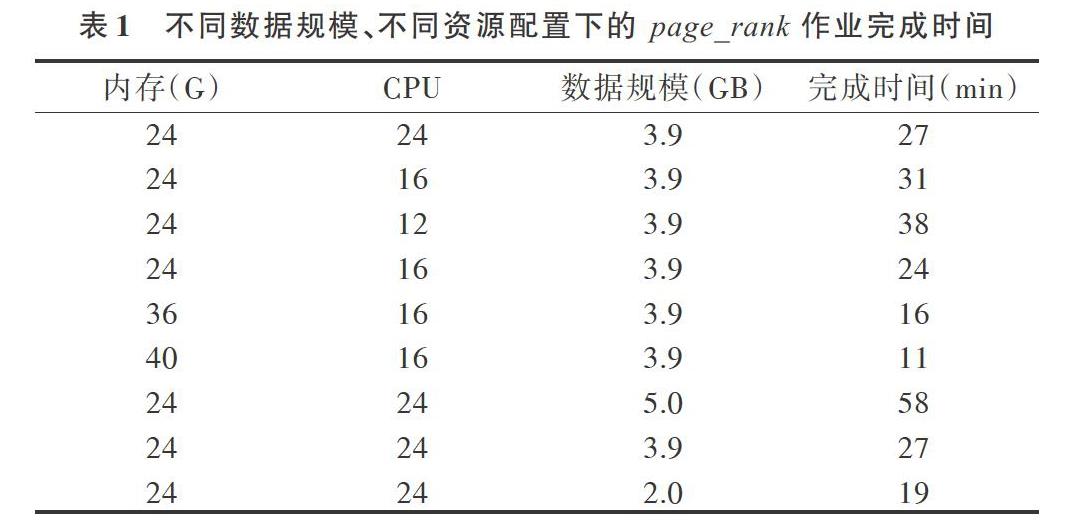
一個离线负载在分布式平台中会被分为多个任务进行计算,CPU数量代表了离线负载在相同时间可以同时运行的任务数量,在一定范围内,并行计算的任务越多,计算速度越快,负载完成时间越短。在计算过程中,内存不足会导致和磁盘频繁交换数据,消耗大量时间,相反,如果内存资源充足,则会降低这部分的时间开销。并且,大部分大数据离线负载的技术栈都基于Java,而内存不足会引起大规模的垃圾回收,导致其它进程和线程被阻塞,从而降低负载完成效率。此外,数据规模大小显然是影响负载完成时间的,一个小规模的数据片和大规模的数据集在完成时间上有明显差异。因此,本文提出在资源配置一定的数据中心,内存数量、CPU数量和数据规模是影响离线负载完成时间的3个关键因素,并通过以下几组page_rank实验加以说明,相关数据如表1所示。
通过实验分析可知,当内存资源和数据规模固定时,负载完成时间随着CPU资源数量的增大而减小;在CPU资源数量和数据规模一定的情况下,随着内存资源的增大,负载完成时间也会延长;在资源配置不变的情况下,随着数据规模的缩小,负载完成时间也明显降低。因此,验证了内存、CPU资源配置和数据规模是影响负载完成时间的关键因素。
1.2 CART回归树算法及应用建模
CART回归树是一种典型的二叉决策树,可以用作回归建模,其所选取的特征划分标准是Gainσ,即平方误差最小[20]。选择具有最小Gain盯的属性及其属性值,作为当前未划分的特征集合中的最优分裂属性以及最优分裂属性值。具体模型构建方法如下:
2 基于多目标优化的资源分配策略
2.1 模拟退火算法
面对目标优化算法中常见的局部最优问题,模拟退火算法应运而生。该算法基于固体降温的思想,一个固体内部的分子从某一较高的初始温度开始,到某一温度停止,伴随温度的不断下降,分子的活性趋于稳定。在搜索解的过程中可能会出现局部最优现象,但是模拟退火算法会继续搜索,并以一定的概率接受搜索过程中出现的非最优解,伴随着温度降低,接受概率逐渐下降,直到某一温度停止,搜索结束,获得全局最优解。该算法将一次向较差解的移动看作一次温度跳变的过程,并且以一定的概率接受这样的移动。这里“一定的概率”的计算就是参考了金属冶炼的退火原理,在温度为,时,出现能量差为AE的降温概率为P(AE),其计算表达式为:
P(△E)=e(AElkT)(3)
其中,k是一个常数,通常情况下取值为1,△E=Enew-Eold在计算过程中一直小于0。这种基于一定概率接受的准则也被称为M etropolis准则。
该算法是一种通用性的优化算法,算法具有概率性的全局优化性能,其特点是可以比较快地找到问题的最优解。在资源调度问题上,需要快速地将资源对离线负载进行分配,因此该算法适用于本文的场景。
2.2 基于模擬退火的离线负载资源调度策略
本文提出的策略追求两个目标,一是在每一批离线批处理作业完成时间△tall batch内,数据中心离线批处理作业的吞吐率TR最大;二是在每一批离线批处理作业完成时间△t all batch内,数据中心的平均资源利用率pr最高。问题形式化表达如下:
2.2.2 能量的定义
在资源分配过程中,每一种不同的资源分配方式所达到的资源使用效果也不尽相同。因此,为了评价每一种资源分配方式的优劣程度,需要定义评级函数,在组合优化算法中,评价函数是评价一个解是否达到最优指标。模拟退火计算过程中,每一个退火阶段的评价函数就是当前温度下的能量E,由问题建模的表达可知,评价函数应该从当前分配方式下的平均资源利用率和离线作业的吞吐率两个方面进行评估和考量。因此,当前能量表达式如下:
在式(11)中,w1、w2是吞吐率权重和平均资源利用率权重,可以设置其具体值,本文设定w1= W2= 0.5。
2.2.3 产生函数的定义
在同一温度下迭代K次搜索最优解的过程中,设定K值为25。根据已有的解和产生函数生成新的解。新解的产生方法是通过交替改变负载的节点分配方案和开始运行时间形成的,具体而言,首先通过随机生成节点组合Li,形成新的解;持续5次后,随机生成新的负载开始运行时间,然后重复改变节点组合过程,直至K次迭代结束。其中,负载开始时间的生成方法是在时刻t0到所有负载串行执行完成的结束时间fn之间随机生成一个时间点。
离线作业资源分配策略具体流程如下:
过程1:离线作业资源分配策略
首先定义初始资源分配组方式、初始温度等相关参数,M_free表示可分配的内存集合,C_free表示可分配的CPU集合,ET表示离线负载预期完成时间集合。然后定义一个初始资源分配策略,并判断该分配方式是否符合资源约束条件,不符合则重新生成直至符合条件。从初始资源分配方式在每一个温度下经过K次搜索,每一次都是按照产生函数中所描述的方式产生下一个解,并结合Metrop-olis准则和评价函数判断并产生当前温度的最优解。随着温度降低,搜索得到全局最优策略,也即本文探索的最佳资源分配方式。
3 性能评估
3.1 实验环境及负载选取
实验环境是由5个节点组成的Spark集群,其中一个节点为主节点,4个节点为从节点。每个节点的硬件配置、软件环境如表2所示。
本文共选取了4个典型的离线负载作为数据中心既有的离线批处理作业,分别为PageRank\KMeans、SVD++和ShortPath。
3.2 实验结果与分析
对不同数据量的离线作业进行组合并分组实验,分组情况如表3所示。
4 结语
本文针对混部负载中离线负载资源使用问题,提出了基于多目标组合优化的分配策略,实现了最大化当前资源利用率和最大化吞吐率两个目标。实验结果表明,与公平分配策略相比,本文提出的策略在平均资源利用率上平均提高了7.8%,在吞吐率方面平均提高了38.2%;与短作业优先策略相比,在平均资源利用率上平均提高了15.5%,在作业吞吐率方面平均提高了29.1%。下一步的研究方向是对资源进行细粒度划分和更为合理的利用。
参考文献:
[1]王晨晨,孙睿.浅析大数据的发展[J]中国市场,2018( 27):194,196.
[2] 陈兴业.评估计算机系统性能的一种方法[J].华南工学院学报:自然科学版,1987(1):16-22.
[3] DELIMITROU C,KOZYRAKIS C.Quasar: resource-efficient andQoS-aware cluster management [J]. ACM SIGPLAN Notices, 2014,49(4):127-144.
[4] 李勇,张章,孟丹,等.面向混合负载的集群资源弹性调度[J].高技术通讯.2014(8):782-790.
[5]JYOTHI S A. CURINO C, MENACHE I, et al.Morpheus: towards au-tomated SLOs for enterprise clusters[C].OSDI, 2016:1 17-134.
[6]SALEHI M A, JAVADI B, BUYYA R.Resource provisioning based onpreempting virtual machines in resource sharing environments [J].Concurrency and Computation: Practice&Experience, 2013: 1-21.
[7]NAWAZ M, ENSCORE JR E E,HAM I.A heuristic algorithm for them-machine, n-job flow-shop sequencing problem[J].Omega, 1983,11(1):91-95.
[8]VERMA A, PEDROSA L,KORUPOLU M, et al.Large-scale clustermanagement at Coogle with Borg[C].Bordeaux: ACM Tenth EuropeanConference on Computer Systems, 2015.
[9]BANKOLE A A, AJILA S A.Cloud client prediction models for cloudresource provisioning in a multitier web application environment[C].IEEE International Symposium on Service Oriented System Engineer-ing, 2013:156-161.
