基于决策树的日志分析方法
2020-07-14樊建昌余粟
樊建昌 余粟


摘 要:为了解决服务器运行过程中由于性能故障造成服务质量下降的问题,提出一种基于决策树的日志分析方法,以服务器日志文件中记录服务器关键性能指标的数据为研究对象,利用决策树中常用的ID3、C4.5和CART 3种算法预测服务器未来性能指标发展趋势。实验结果表明,在实际运行过程中,C4.5算法对服务器性能指标数据预测的准确率和召回率最好,分别达到了92.23%和95.37%,在3种决策树算法中拥有最高的准确率与召回率,且相比传统开发人员从日志文件中寻找故障的方法,准确率提高了20%左右,因此能够更好地预测服务器系统性能指标发展趋势。通过该方法可提前感知系统运行状况,并及时作出调整,从而有效降低实际生产过程中服务器故障发生概率,提高服务质量。
关键词:决策树算法;日志分析;Spark;大数据
DOI: 10. 11907/rjdk.191343
开放科学(资源服务)标识码(OSID):
中图分类号:TP301
文献标识码:A
文章编号:1672-7800(2020)001-0099-04
0 引言
随着互联网的快速发展,信息系统在人们日常生活中发挥着越来越重要的作用。信息系统服务器一旦发生故障,将会严重影响公司日常业务的开展。因此,对运行中的服务器定期进行安全检查,确定服务器当前运行状况以及可能存在的安全隐患显得尤为重要[1]。
在软件系统运行过程中,软件系统各部分运行状态以及运行过程数据都会以日志形式保存下来[2]。根据统计,在Cithub等常用开源平台上,绝大部分开源项目文件的每30行代码中,就有一行用来记录项目运行过程中产生的日志[3]。此外,在实际生产领域,若重新创建与生产环境完全一致的开发环境,成本非常高昂,所以生产环境中打印的日志文件往往成为研究人员进行服务器故障诊断预测的唯一数据来源[4]。
自从有学者提出利用日志文件进行服务器故障诊断预测以来,基于日志文件分析系统故障的方法开始受到越来越多人重视。传统由资深开发人员基于系统产生的日志文件查找系统潜在故障的准确率一般在70% - 80%之间[5-6],通过该方式进行故障分析,不仅费时费力,而且准确率不高。PREWETT[7]将专家知识表示为一系列规则进行故障诊断,规则可以人为扩展,并且是可解释的,但该技术的缺点是不能诊断未知错误,知识库也不易维护;Zhu等[8]将系统定义为数学表示,通过测试观察到的行为验证其是否满足模型,该技术适合诊断应用级别问题,但模型构建需要对系统有深刻理解;韩凯等[9]利用经验数据结合日志文件进行关联分析,同时结合统计理论对网络系统进行故障诊断,而不需要对系统内部或模型有深入了解,但其难以诊断系统的非稳态性故障。还有部分学者采用聚类方法分析日志文件,使用训练数据确定系统状态是否健康,找出故障潜在原因,该技术可以自动学习系统行为,但当数据特征维度变大时,精确度会下降[10-12]。如李刚等[13]将动态时间阈值和属性相异度相结合对日志文件进行分析,诊断出系统运行过程中的短暂与间歇性错误,但该方法很大程度上依赖于参数校正;宋永生等[14]利用可视化数据生成图表,由图表进一步分析故障发生位置,该方法便于解释与评估,但该方法最大的问题在于不能自动识别故障具体位置。
本文基于Spark分布式计算引擎[15],采用决策树中常用的3种算法对系统产生的日志文件进行分析,并从召回率、准确率等方面进行对比,选择准确率和召回率最佳的C4.5算法作为日志分析方法。该方法可以自动从原始日志文件中提取关键性能指标进行日志分析,对服务器运行状态进行及时诊断,并对服务器可能发生的故障进行预测,具有良好的实时性和准确性。
1 决策树算法
决策树算法[16]是一种典型分类方法,首先对原始数据进行处理,并归纳生成可读规则,该规则一般以树的结构体现,所以称为决策树。当需要对新数据进行分类时,只需利用决策树对新数据进行分析,即可得到分类结果,该方法已在大数据挖掘中得到广泛应用。
决策树是一个有向无环树,树的每个非叶节点对应训练样本集中的一个属性,非叶节点的分支对应属性的一个数值划分,每个叶节点代表一个类,从根节点到叶节点的路径称为一个分类规则。决策树构建主要通过对属性选择进行度量,目前属性度量方式主要有3种:信息增益、信息增益率和Gini指标。
1.1信息熵
熵是物理学和信息论中的一个重要概念[17],用来衡量一个数据分布的无序程度。对于一个训练样本而言,其熵越小,则训练样本的无序度越小,即训练样本越有可能属于同一类。信息增益即是一种通过样本信息熵进行度量的方法,集合D中某个样本属于第k类样本的概率为第k
1.3 C4.5算法
在ID3算法中,信息增益对取值数目较多的属性有所偏好,当所有分支均只包含一个样本时,分支纯度最大,但该决策树有一个明显缺点,即不具备泛化能力,无法对新样本进行预测。C4.5决策树算法即是为了提高决策树泛化能力而提出的[19],其采用信息增益率进行特征选择。其中,增益率定义为:
其中,IV(a)称为属性a的固有值,当属性a的潜在值数目越多,属性a的固有值则越大。在具体算法实现过程中,首先从候选划分属性中找出信息增益率高于平均水平的属性,再从中选择增益率最高的属性作为最终数据分类依据。
1.4 CART算法
CART决策树算法采用Gini指数选择属性划分,具体定义为:
Gini(D)反映了从数据集D中随机抽取两个样本标记类别不一致的概率。Gini(D)越小,数据集D的纯度越高[20]。
2 实验平台及数据准备
2.1 实验平台
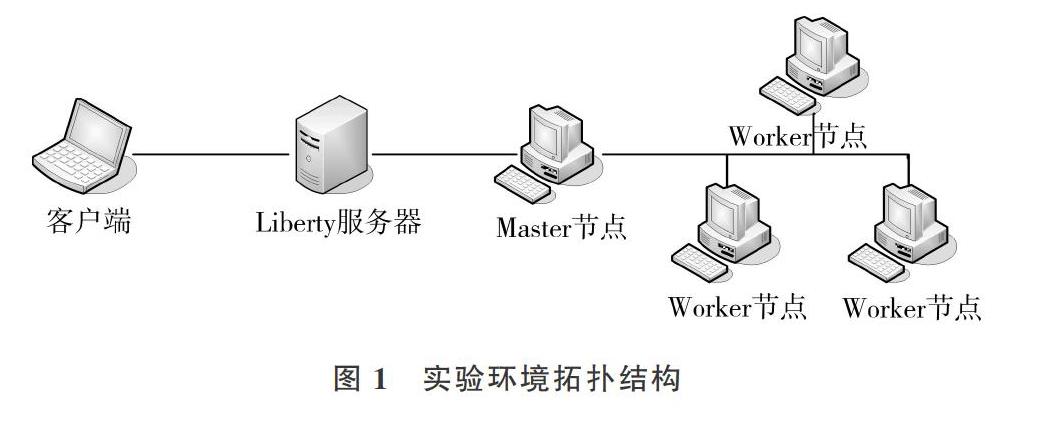
图1为实验环境拓扑图,其中客户端使用Dell 7567笔记本,Liberty服务器与4台Spark集群均使用宏碁Veriton台式机,硬件配置为:双核CPU,16G内存,2T硬盘。Liber-ty服务器部署WebSphere Application ServerV8.5服務器,提供Web服务。同时,Libertv服务器和4台Spark集群都通过docker安装Spark-2.2.0 -Hadoop-2.7与Hive 2.2.0,配置Master节点和Worker节点。
2.2 数据准备与数据清洗
本文选取某电商网站一年的交易服务器日志数据作为训练数据。以Smin为时间间隔进行数据统计,共有105 120个实例,每个实例都有其标记数据,根据当天的系统性能状况,由专业工程师进行标注。对于每个实例,选出32 000个能够体现系统性能的属性。由于日志分析系统是根据性能指标的历史趋势进行预测的,对105 120个实例以7天为周期向前回溯,可以重叠,最终生成103 392个实例。
在日志提取过程中,对于未提取出来的数据,本文将以null的形式展现出来。在进行机器学习之前,以不影响总体数据分布为前提,对未提取出来的日志数据作残缺值处理。由于日志数据所有属性均为数值类型,在实际操作中以7天为一个周期,在7天内某个数据属性的残缺值出现次数在3以下,则将当前属性其它数值的平均值作为该属性残缺值,如果当前属性的残缺值数量在4个以上,则将其它相关属性平均值作为当前属性的残缺值。在机器学习中,由于无关属性会在很大程度上影响分类器性能,所以在机器学习之前进行属性选择是非常必要的,保留一些最相关的属性,而将其它不相关或相关性非常小的属性去除。
本文利用主成分分析法对日志数据进行清洗,通过旋转变换对线性空间中的原始数据进行基变化,使变换后的数据投影在新坐标轴上,并使其方差最大化。剔除变换后方差最小的坐标轴,新坐标轴即为主成分[21]。主成分分析法是一种比较常见的降维方法,广泛应用于机器学习的数据降维问题中。利用Spark MLlib工具箱对主成分分析法加以实现,对32 000个属性进行降维操作,最终选取28 000个属性进行最后的机器学习模型训练。
3 实验方法及结果
3.1 实验流程
在日志分析模块,所有性能指标都标注了是否有故障以及故障类型。由日志提取模块生成的系统性能指标,可以根据历史标注数据形成的训练模块判断出当前系统是否有故障以及故障类型,所以日志分析模块所采用的机器学习算法是监督学习。日志分析预测结果为当前CICS交易服务器在未来发生性能故障的概率,在实际训练预测模型时,将原始数据集保留一部分作为测试集,剩余部分作为训练集,在随机选取训练样本过程中保证测试集和训练集中每个样本比例大致相同,以减小取样造成的误差。本文使用十折交叉验证法生成预测模型,将原始数据源分成10份,进行10次训练,每次选取其中1份作为测试样本,其余9份作为训练样本。该方法既能够保证每个样本都有一次机会用于测试,又没有样本进行重复测试,因此试验结果较好。
当模型建立之后,需要制定预测模型性能评估标准,本文使用误差率衡量预测模型的预测效果,误差率是指不正确分类在整个实例集中所占比例。在模型实际训练过程中,可能产生4种结果,如表1所示。其中,数据集标签有Yes和No两种,分别表示服务器有性能故障与无性能故障;预测结果也有Yes和No两种,分别表示服务器会产生性能故障和不会产生性能故障。因此,模型预测结果有4种:正确的肯定TP( True Positive)表示数据标签是Yes,预测结果也是Yes的情况;正确的否定TN( True Negative)表示数据标签是No,预测结果也是No的情况;错误的肯定FP( False Positive)表示数据标签是No,预测结果是Yes的情况;错误的否定FN( False Negative)表示数据标签是Yes,预测结果是No的情况。其中,正確的肯定和正确的否定都是正确的预测结果。另外,一般称错误的否定为漏报,而称错误的肯定为误报。在日志分析系统中,漏报的代价大于误报的代价,因为误报只会浪费工程师时间以确认是否会产生性能故障,而漏报则会使工程师忽略问题,导致问题真实发生,产生严重后果。
3.2 实验结果
本文使用Spark的MLlib工具箱,借助十折交叉验证法对训练数据集进行验证,分别利用ID3、C4.5和CART 3种不同算法对数据进行训练。结果如表2所示,从中可看出3种算法的准确率都高于85%,其中,C4.5算法的召回率最高,即能查出性能故障的概率更高。图2为3种算法实验结果的ROC曲线对比结果,从中可以看出C4.5算法在FPR较高时准确率更高,ID3算法在FPR较低时准确率更高。日志分析系统需要尽可能提高模型召回率,因此可以相应降低对准确率的要求,本文最终选取C4.5算法进行系统日志分析。
4 结语
由实验结果可以看出,本文设计的日志分析方法可以自动对原始日志文件进行分析,从而解决了软件工程师手动查取日志文件进行系统故障判断较为费时费力的问题。相比传统手工方法,其故障判断的准确率及效率都提高了20%左右。使用分布式计算引擎进行日志分析,相对于传统的串行查询,提高了日志分析速度,而且易于扩展。未来可根据具体日志业务特点进行更加精准的建模,以进一步提高模型预测准确率,避免服务器故障的发生。
参考文献:
[1]YUAN D,PARK S,ZHOU Y.Characterizing logging practices inopen-source software[C].Proceedings of the 34th International Con-ference on Software Engineering. IEEE Press, 2012: 102-112.
[2]SHARMA C, JHAPATE A.A survey: analytics of web log file throughmap reduce and Hadoop [Jl. International Journal of Scientific Re-search&Engineering Trends, 2016,2:2395-566X.
[3] LIN X,WANG P,WU B.Log analysis in cloud computing environ-mentWith Hadoop and Spark[C].Broadband Network&MultimediaTechnology (IC-BNMT), 2013 Sth lEEE International Conference omIEEE, 2013:273-276.
[4]SHUSHUAI Z H U,AKALI H,RUSSELL J,et al.Method and systemfor implementing collection-wise cessing in a log analytics system[ P].U.S. Patent Application 15/089, 129, 2017-1-5.
[5]廖湘科,李姗姗,董威,等.大规模软件系统日志研究综述[J].软件学报,2016, 27(8):1934-1947.
[6]VULYA S P. JOSHI K, DI GIANDOMENICO F, et al. Failure diag-nosis of complex systems[M].Heidelberg: Springer, 2012: 239-261.
[7]PREWETT J E.Analyzing cluster log files using Logsurfer[C]. Pro-ceedings of the 4th Annual Linux Showcase& Conference. 2003:169-176.
[8]ZHU J,HE P, FU Q, et al. Learning to log: helping developers makeinformed logging decisions[C].Proceedings of the 37th InternationalConference on Software Engineering, 2015: 415-425.
[9] 韩凯,赵国庆,胡天宇,等,基于日志分析的虚拟机智能运维[J].信息与电脑:理论版,2018( 20):7-10.
[10]钟雅,郭渊博.基于机器学习的日志解析系统设计与实现[Jl.计算机应用,2018,38(2):352-356.
[11] 马文,朱志祥,吴晨,等.基于FP-Growth算法的安全日志分析系统[J].电子科技,2016.29(9):94-97.
[12] 张日如.聚类分析在Web日志中的应用[J].信息与电脑:理论版.2019(2):116-117.
[13]李刚,陈怡潇,黄沛烁,等.基于日志分析的信息通信网络安全预警研究[J].电力信息与通信技术,2018,16(12):1-8.
[14] 宋永生,吴新华.基于Pvthon的Moodle学习平台日志分析[Jl.计算机时代,2018( lO):19-21,25.
[15]ZAHARIA M. CHOWDHURY M, FRANKLIN M J,et al. Spark:cluster computing with working sets[J].HotCloud, 2010, 10: 95.
[16]周志華机器学习[M].北京:清华大学出版社,2016.
[17]叶韵.深度学习与计算机视觉[M].北京:机械工业出版社,2017.
[18]张小轩.ID3算法的研究及优化[D].青岛:山东科技大学,2017.
[19]沈亮亮,蒙祖强,张兵,等.面向不完备数据的改进C4.5算法研究[J].软件导刊,2018.17(6):95-99.
[20]史选民,史达伟,郝玲,等.基于数据挖掘CART算法的区域夏季降水日数分类与预测模型研究[J].南京信息工程大学学报:自然科学版,2018,10(6):760-765.
[21]MENG X. BRADLEY J,YAVUZ B. et al. Mllib: machine learningin Apache spark[Jl. The Journal of Machine Learning Research,2016, 17(1):1235-1241.
(责任编辑:黄健)
基金项目:上海市科委创新行动计划项目( 17511110204)
作者简介:樊建昌(1994-),男,上海工程技术大学机械与汽车工程学院硕士研究生,研究方向为计算机视觉及数据挖掘。
