基于在线主题模型的新闻热点演化模型分析
2020-07-14戴长松王永滨王琦
戴长松 王永滨 王琦
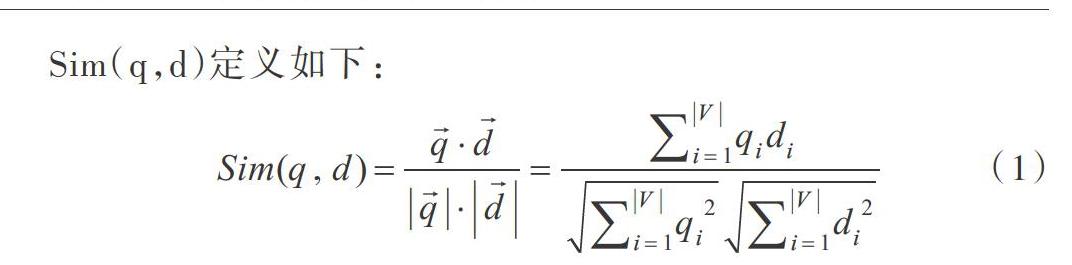
摘 要:为了对新闻媒体平台的重大事件进行话题演化建模分析,基于隐含狄利克雷分布(LDA主题模型算法)对话题动态建模,在变分推断主题模型基础上建立衡量话题内容和热度变化的流行话题模型(TTM-OL-DA)。针对用户关注的重大新闻事件发展方向与热度,提出话题内容向量与流行因子,对整个话题生命周期进行量化,从而有效地从大量相关新闻中挖掘出话题演化细节,帮助用户更好地掌握话题发展情况。在特定新闻板块筛选的数据集下,通过设置对比实验和人工评测方式,验证该方法在困惑度上优于在线主题模型算法。
关键词:新闻热点;话题演化;在线主题模型;动态话题建模;变分推断
DOI: 10. 11907/rjdk.191252
开放科学(资源服务)标识码(OSID):
中图分类号:TP303
文献标识码:A
文章编号:1672-7800(2020)001-0084-05
0 引言
网络信息爆炸式增长,尤其是文本类型数据,如来自新闻网站、微博、论坛等,纷繁复杂导致用户无法一一查看感兴趣的话题内容。当某个重大新闻事件发生时,相关新闻报道层出不穷,为了帮助用户准确实时掌握舆情事件的发展和走向,尽可能还原话题的焦点和热度,文本挖掘尤其是话题模型研究应运而生。
基于LDA(Latent Dirichlet Allocation,隐含狄利克雷分布)主题模型[1]的话题演化研究方法近年被研究人员广泛采用。楚克明等[2]使用LDA模型对不同时段的文集进行话题抽取,然后通过话题分布计算相邻时间段内两个话题的距离表示话题间的关联,不足之处是各个时间段内的话题模型完全独立,仅根据模型生成的主题分布推测话题间的联系会使新出现的话题内容脱离实际。原始的LDA算法并不具备在线建模能力,为了使模型能够随时间进行演化,Loulwah等[3]基于LDA提出了在线主题模型(On-LineLDA,以下简称OLDA),这种方法以增量更新的方式构建主题模型,更新时不需要访问之前的数据,使主题模型具有了在线学习能力。OLDA的出现为话题演化提供了一种新思路,即利用在线学习能力模拟话题演化过程;胡艳丽等[4]根据时序划分文本流并采用OLDA模型抽取每个时间片的子话题,提出基于相对熵的子话题关联分析方法;崔凯等[5]基于改进的吉布斯算法对文本进行主题建模,并利用相对熵比较主题间的相似度以发现话题演化过程中的“遗传”和“变异”。
以上方法均采用吉布斯抽样算法构建LDA主题模型。该方法优点是实现简单,缺点在于需要迭代的次数较多,在一些要求时效性的场景下表现较差。与吉布斯抽样算法相对的是变分贝叶斯方法,Chase等[6]的研究表明,变分贝叶斯方法实现复杂但建模更准确快捷,因此本文采用变分贝叶斯方法构建主题模型,在该方法基础上实现OL-DA模型并提出流行话题模型(Trending Topic Model on On-line LDA,简称TTM-OLDA)。
1 话题演化模型
话题跟踪或演化最早出现于话题检测与跟踪( TopicDetection and Tracking,TDT)相关研究中。话题跟踪中的话题指某一个具体的事件而非一类领域[7],典型的话题如“个税起征点提高”、“崔永元曝光阴阳合同”等都属于话题范畴。新闻话题随着时间的发展,关注点和热度也会随之发生变化,以“阴阳合同”事件为例,人们的关注点从最初的“范冰冰逃税,税务局介入调查”变为“范冰冰被罚款”,再到“崔永元受到人身威胁”等等,其话题相关内容本身发生了变化,而热度指人们对这个话题的关注程度,本文将对这一指标量化为强度。
话题演化指新闻话题在内容和强度上的变化过程,如何从这些海量的新闻文本中挖掘出话题的演化方向和过程,对舆情分析、文本挖掘等领域有着重要的研究意义。
1.1 主题模型
在自然语言处理等领域,主题模型指对多文档语料库进行隐含特征发现的算法,发展至今,提到最多的主题模型是Blei在2003年提出的LDA主题模型,当前关于话题演化的很多研究也是基于LDA主题模型[8-15]构建的。主题模型从文档和词两个维度之间抽象出一个“主题”维度,如图1所示。
作为文本聚类领域应用最广泛的算法之一,LDA主题模型已经经历了10余年的发展.至今围绕主题模型的相关研究仍是文本挖掘领域的热点方向之一。
最初的向量空间模型( Vector Space Model,VSM)中,Salton等将语义相似度转化为向量空间上的相似度,为了比较请求文档q与目标文档d的相似度,以qi和di表示词i在文档中的权重,一般使用tf-idf值表示,其余弦相似度Sim(q,d)定义如下:
由于向量空间模型无法解决一词多义和多词一义问题,Dumais等提出了隐含语义分析(Latent Semantic Analv-SIS,LSA)模型,该模型基于SVD矩阵分解构造文档一词矩阵Xdy的一个低秩逼近矩阵,不仅缓解了一义多词问题,还在原本的文档一词矩阵上作了特征降维,对于原始向量空间的噪声进行消除。
LSA矩阵分解过程如下:
其中,d表示文档数量,v表示词个数,k表示潜在语义维度。同样,文档一词矩阵Xdy一般使用词的tf-idf值表示。
LSA模型不足之处在于矩阵分解过程十分漫长,无法解决一词多义,且在数理统计上无法推导,可解释性较差。为解决上述问题,Hofmann等提出了pLSA模型。该模型基于概率统计,假设文档与主题、主题与词之间服从多项式分布,使用常见的参数估计方法,即EM算法对模型参数进行估计,pLSA模型为现在最常见的LDA主题模型产生奠定了理论基础。
LDA主题模型可看作pLSA的贝叶斯版本,这里的贝叶斯先验体现在LDA为文档一主题和主题一詞分布添加了狄利克雷先验。在主题模型技术中,无视文档中词语顺序,因此这类模型也称为词袋模型或unlgram模型。语料中的每篇文档可看成由多个主题组成,而主题则是由多个关键词构成,每篇文档下的主题有其自身权重系数。同样,每个主题下的关键词也有其权重,这些权重代表了它们对主题或者文档的贡献程度。
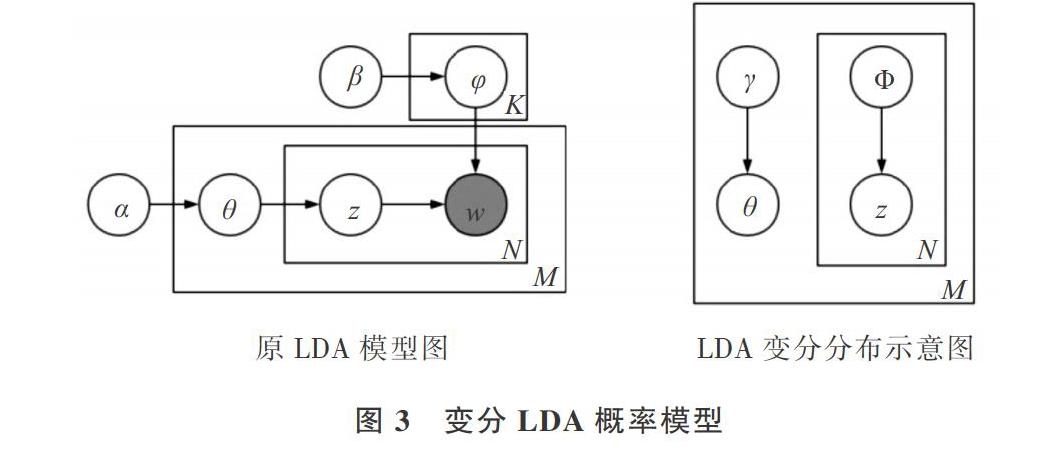
LDA是一种非监督的文本聚类算法,在pLSA假设基础上,LDA引入了狄利克雷先验分布确定文档到主题和主题到词的多项式分布参数。在结构上看,LDA主题模型依据文档、主题、词生成三层贝叶斯概率模型,相对于PLSA,LDA主题模型借鉴了贝叶斯学派思想,为模型参数加入了先验分布,使得主题和词的分布随机化。由于LDA的上述优点,使其在文本挖掘领域应用十分广泛,围绕其设计改进的模型也屡见不鲜。LDA概率如图2所示。
1.2 在线主题模型OLDA
在LDA提出之后,为适应流式数据的文本建模分析,Loulwah等提出了在线主题模型OLDA(Online LDA),它可对连续时间窗口内的语料分别进行训练。为了让前一个时间窗口内的模型特征得到“遗传”,提高分散建模效率,OLDA模型将前一个主题模型内单词的主题分布作为下一个主题模型的主题先验分布,使得OLDA模型具备在线处理流式文本能力。
1.3 话题演化模型
话题演化作为文本主题挖掘领域的重要组成部分,在LDA主题模型提出之后,基于LDA算法的话题演化模型设计受到越来越多的研究者关注。根据单斌等的研究,基于LDA主题模型的话题演化方法目前可依据时间信息划分为先离散方法、后离散方法、结合时间特征到LDA模型等3种方法。
本文属于“按时间信息先离散”方法。先离散指将语料中的文档依据时间特征离散至相应的时间窗口内,时间窗口长度可根据语料特点选用不同的时间粒度,先离散方法依次对每个时间窗口内的语料进行建模。需要注意的是,不同时间窗口的主题模型并不完全独立而且参数相关。
针对话题演化过程中的话题内容和强度变化,本文基于LDA模型生成的文档到主题的分布,计算相邻的时间窗口内话题内容变化,记为相邻话题语义距离。一旦该语义距离超出某个阈值,说明该话题在内容上发生了变化,即发生了话题演化过程,该变化由内容向量计算而得。在话题强度变化上,对同一个话题,其强度由一个随时间窗口变化的系数衡量,该系数表示某个话题在相应时间窗口的流行程度,使用者可根据实际情况设定系数的阈值以界定话题的流行程度,这个系数称为流行因子。
2 基于变分推导与内容遗传的话题演化模型
2.1 LDA生成过程
LDA的吉布斯(Gibbs)和变分推导分别称为smoothed版本和basic版本,与smoothed版本不同之处在于,使用变分贝叶斯方式的推导过程更加复杂,其生成模型的流程也很不同。
Cibbs抽样多见于贝叶斯概率分析问题中[16],LDA主题模型同样依赖于贝叶斯假设。basic LDA的生成过程如下:①从狄利克雷分布中产生文档主题分布θ,其中O-Dir(a);②从泊松分布中生成一篇文档的单词个数Nd,即Nd-possion(λ);③对文档中的每个单词ωd,n,首先选择一个主题Z d,n,即Z d,n-Mult(θ);④单词ωd,n的主题Z d,n确定之后,再根据概率分布p(ωd,n| Zd.n,β)生成单词本身的ω d,n。
其中,入为随机事件平均发生率,a是一个K维向量,是狄利克雷分布的超参数,由狄利克雷分布产生的参数θ为生成文档的主题分布概率向量。θ=(θn,θ1,…,θk-1)T,θ,表示文档选择第i个主题z的概率。
为了对真实数据进行模拟,同时为简化模型,这里使用真实文档的单词个数取代Nd。与smoothed版本最大不同之处在于β是一个KxV的矩阵,表示主题Zd,n产生词ω d,n的概率。区别在于β是一个可估算的确定量,而不是从狄利克雷分布中随机生成的。变分LDA使用的变量及参数如表1所示。
2.2 LDA变分推导
LDA变分推导的关键在于变分EM算法,以LDA推导为例,当给定一篇文档时,要求解其隐变量的后验分布表达式。
这样,对该假设函数O求极值就可近似得到原始分布的近似,称为变分分布。在新的模型分布中,Blei引入了两个新的参数y和中替代原来模型的超参数。为了获得模型下界,采用EM算法对其进行估计,EM算法分为E步(求期望)和M步(最大化似然函数)。
流行因子反映了话题强度变化,为了方便话题的流行因子计算与比较,设置i的阈值大小T为10,即取话题前10个概率较大的词概率参与流行因子计算。
话题k的内容向量定义如下:
3 实验及结果展示
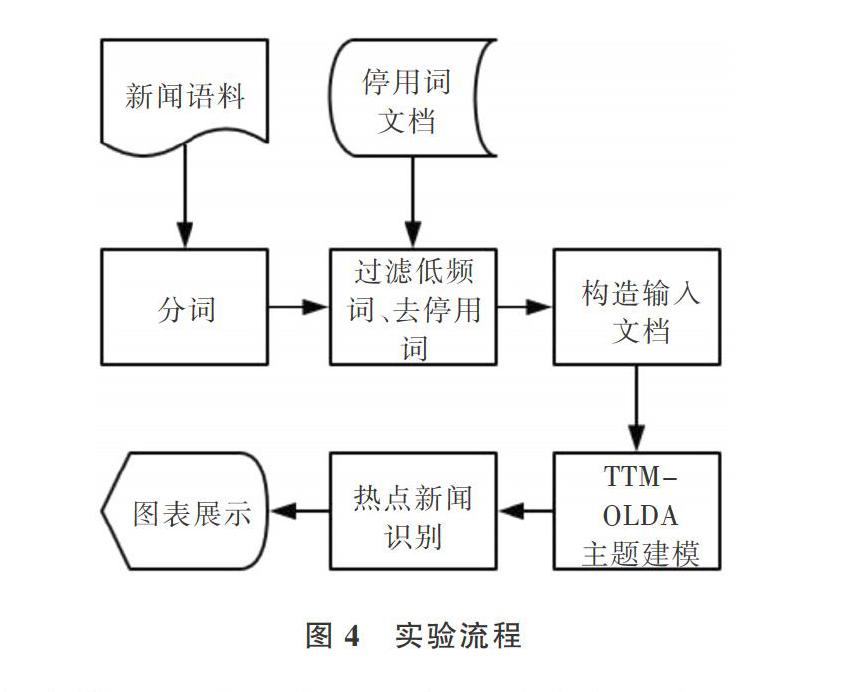
对于数据集选取,话题演化模型并没有一个规范通用的解决方案,这与主题模型本身特性有关。虽然主题模型属于文本聚类领域算法之一,但严格来说它并没有将一个语料库的文本按类别“完全”分离,而是一种软聚类或模糊聚类方法。为了关注重大新闻事件的走向,本文选取近两个月( 2019.1-2019.2)某新闻网站中互联网版块新闻作为训练语料库,着重关注近期网络热点话题,如“互联网大裁员”等几个较热门的新闻话题作为观测对象,通过TTM-OLDA模型分析话题的演化,在内容演化和流行热度两方面对其进行模拟。TTM-OLDA模型的实验流程如图4所示。
语言模型的衡量方法一般可分为实用方法和理论方法,实用方法直接对模型在实际应用中的表现作出评价,简单直观,但是不能从客观角度作出评价,缺乏针对性。因此,本文选择比较客观的理论方法衡量TTM-OLDA的表现。对于文本聚类方法,由于使用的测试数据集没有分类标签,无法判断模型训练结果与真实情况之间的差异,因此使用困惑度perplexity衡量主题模型的好坏,困惑度公式如下:
其中,D表示由M篇文档组成的训练数据集,p(wm)为模型在第m篇文档的似然函数[17]。似然值越大,困惑度越小,模型的泛化性能越好。
训练数据集包含2个月的新闻数据,考虑到主题建模需要,本文以周为单位划分时间窗口,即共8个时间窗口,平均每个窗口新闻条数为320条。实验选取基于Gibbs的OLDA模型作为对照,在困惑度与建模耗时两方面分别比较,结果如图5、圖6所示。
2018年下半年开始,各大互联网企业轮番上演人员结构优化,从而引发了一场裁员大潮,本文选取该热点话题作为观测对象,持续追踪其话题内容即热度变化,实验结果见图7。
4 结语
对于当前话题演化模型中普遍存在的迭代次数多、时效性低以及模型还原话题不够真实等问题[18-21],本文基于在线主题模型OLDA,提出了在线流行话题模型TTM-OL-DA,以话题内容向量与流行因子对流行新闻话题内容与热度变化进行衡量。实验结果表明,TTM-OLDA在模型困惑度、时效性上均领先于原始OLDA算法,证明该模型在新闻话题演化建模上的准确性和时效性。由于本文主要关注新闻领域话题演化和热度变化,没有考虑新闻本身的阅读量等流行因素,因此下一步研究将引入新闻初始流行程度,对比更多的新闻数据来源,改善话题演化模型,以适应更多的话题演化建模场景。
参考文献:
[1]DAVID M,BLEI, ANDREWY. et al. Latent Dirichlet allocation [J].Journal of Machine Learning Research. 2003(3):993-1022.
[2] 楚克明,李芳.基于LDA模型的新闻话题的演化[J].计算机应用与软件,2011,28(4):4-7,26.
[3]ALSUMAIT L,BARBARA D. DOMENICONI C.On-Iine LDA: adap-tive topic models of mining text streams with applications to topic de-tection and tracking[C].Proceeding of the 8thIEEE International Con-ference on Data Mining, 2008: 3-12.
[4]胡艳丽,白亮,张维明.一种话题演化建模与分析方法[J].自动化学报,2012,38( 10):1690-1697.
[5] 崔凯,周斌,贾焰,等.一种基于LDA的在线主题演化挖掘模型[J].计算机科学,2010,37( 11):156-159,193.
[6]CHASE CEIGLE.lnference methods for latent dirichlet allocation[ EB/OL]. http: //times.cs.uiuc.edu/cocour/5 lOfl 8/notes/lda-survey.pdf.
[7] 陈兴蜀,高悦,江浩,等.基于OLDA的热点话题演化跟踪模型[J].华南理工大学学报:自然科学版,2016,44(5):130-136.
[8] 姚兆旭.基于WSO-LDA的微博话题“主题+观点”词条抽取算法研究[D].南京:南京航空航天大学,2017.
[9] 刘小军.基于LDA模型和AP聚类算法的主题演化研究[D].合肥:合肥工业大学,2016.
[10]袁胜文,基于LDA的中文科技文献话题演化研究[D].郑州:河南工业大学,2015.
[11] 张卫春.基于主题模型的汽车评论话题演化研究[D].合肥:合肥工业大学,2017.
[12]林萍,黄卫东.基于LDA模型的网络突发事件话题演化路径研究[J].情报科学,2014,32( 10):20-23.
[13]乔善增.基于种子文档和统计模型的话题演化研究[D].济南:山东大学,2014.
[14]章建.基于上下文的话题和话题关系的演化研究[D].上海:上海交通大学,2013.
[15] 方莹,黄河燕,辛欣,等.面向动态主题数的话题演化分析[J].中文信息学报,2014,28(3):142-149.
[16] 刘忠,茆诗松.分组数据的Baves分析-Cibbs抽样方法[J].应用概率统计,1997(2):211-216。
[17] HEINRICH G.Parameter estimation for text analysis[ EB/OL]. http: llwww.arbylon.net/publications/text-est.pdf.
[18] 王子涵.一种基于社交媒体的突发事件话题演化分析系统研究[c].中国计算机学会第32次全国计算机安全学术交流会论文集.2017.
[19]李慧,王丽婷.基于话题标签的微博热点话题演化研究[J].情报科学,2019,37(1):30-36.
[20] 陈婷,曲霏,陈福集.基于时间片划分的舆情话题演化模型研究[J].华中师范大学学报:自然科学版,2015,49(6):890-894.
[21] 周未東.一种基于LDA中文微博舆情演化分析方法[D].哈尔滨:哈尔滨工程大学,2017.
(责任编辑:杜能铜)
基金项目:中国传媒大学青年理工科规划项目( 3132018XNC1804,3132018XNC1837)
作者简介:戴长松(1994-),男,中国传媒大学协同创新中心互联网信息研究院硕士研究生,研究方向为文本聚类;王永滨(1963-),男,博士,中国传媒大学计算机与网络空间安全学院、智能融媒体教育部重点实验室教授、博士生导师,研究方向为网络新媒体技术;王琦(1982-),男,博士,中国传媒大学协同创新中心互联网信息研究院副教授、硕士生导师,研究方向为智能媒体与信息技术。本文通讯作者:王琦。
